Einführung
Apache Spark ist ein Open-Source-Framework, das große Mengen an Stream-Daten aus mehreren Quellen verarbeitet. Spark wird in der verteilten Datenverarbeitung mit Anwendungen für maschinelles Lernen, Datenanalyse und graphenparalleler Verarbeitung verwendet.
Diese Anleitung zeigt Ihnen, wie Sie Apache Spark unter Windows 10 installieren und testen Sie die Installation.

Voraussetzungen
- Ein System mit Windows 10
- Ein Benutzerkonto mit Administratorrechten (erforderlich, um Software zu installieren, Dateiberechtigungen zu ändern und Systempfad zu ändern)
- Eingabeaufforderung oder Powershell
- Ein Tool zum Extrahieren von .tar-Dateien, z. B. 7-Zip
Installieren Sie Apache Spark unter Windows
Die Installation von Apache Spark unter Windows 10 mag für Anfänger kompliziert erscheinen, aber dieses einfache Tutorial wird Sie zum Laufen bringen. Wenn Sie bereits Java 8 und Python 3 installiert haben, können Sie die ersten beiden Schritte überspringen.
Schritt 1:Installieren Sie Java 8
Apache Spark erfordert Java 8. Sie können mit der Eingabeaufforderung überprüfen, ob Java installiert ist.
Öffnen Sie die Befehlszeile, indem Sie auf Start klicken> geben Sie cmd ein> klicken Sie auf Eingabeaufforderung .
Geben Sie den folgenden Befehl in die Eingabeaufforderung ein:
java -versionWenn Java installiert ist, antwortet es mit der folgenden Ausgabe:
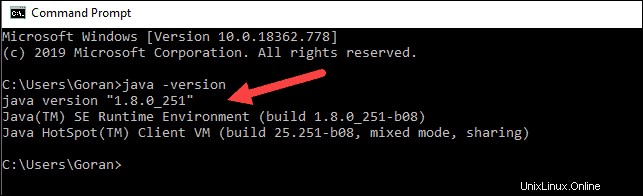
Ihre Version kann anders sein. Die zweite Ziffer ist die Java-Version – in diesem Fall Java 8.
Wenn Sie kein Java installiert haben:
1. Öffnen Sie ein Browserfenster und navigieren Sie zu https://java.com/en/download/.
2. Klicken Sie auf Java-Download Schaltfläche und speichern Sie die Datei an einem Ort Ihrer Wahl.
3. Sobald der Download abgeschlossen ist, doppelklicken Sie auf die Datei, um Java zu installieren.
Schritt 2:Python installieren
1. Um den Python-Paketmanager zu installieren, navigieren Sie in Ihrem Webbrowser zu https://www.python.org/.
2. Bewegen Sie die Maus über den Download Menüoption und klicken Sie auf Python 3.8.3 . 3.8.3 ist die neueste Version zum Zeitpunkt des Schreibens des Artikels.
3. Sobald der Download abgeschlossen ist, führen Sie die Datei aus.
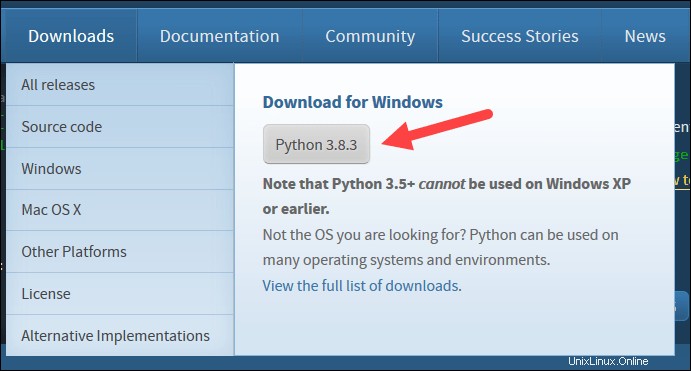
4. Aktivieren Sie im unteren Bereich des ersten Setup-Dialogfelds die Option Python 3.8 zu PATH hinzufügen . Lassen Sie das andere Kontrollkästchen aktiviert.
5. Klicken Sie anschließend auf Installation anpassen .
6. Sie können in diesem Schritt alle Kästchen aktiviert lassen oder die nicht gewünschten Optionen deaktivieren.
7. Klicken Sie auf Weiter .
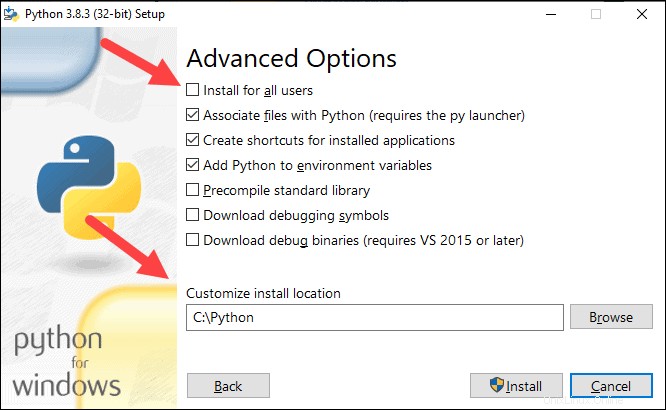
8. Aktivieren Sie das Kontrollkästchen Für alle Benutzer installieren und lassen Sie andere Boxen so wie sie sind.
9. Unter Installationsort anpassen Klicken Sie auf Durchsuchen und navigieren Sie zum Laufwerk C. Fügen Sie einen neuen Ordner hinzu und nennen Sie ihn Python .
10. Wählen Sie diesen Ordner aus und klicken Sie auf OK .
11. Klicken Sie auf Installieren , und lassen Sie die Installation abschließen.
12. Wenn die Installation abgeschlossen ist, klicken Sie auf Pfadlängenbegrenzung deaktivieren Option unten und klicken Sie dann auf Schließen .
13. Wenn Sie eine Eingabeaufforderung geöffnet haben, starten Sie sie neu. Überprüfen Sie die Installation, indem Sie die Version von Python überprüfen:
python --version
Die Ausgabe sollte Python 3.8.3 ausgeben .
Schritt 3:Laden Sie Apache Spark herunter
1. Öffnen Sie einen Browser und navigieren Sie zu https://spark.apache.org/downloads.html.
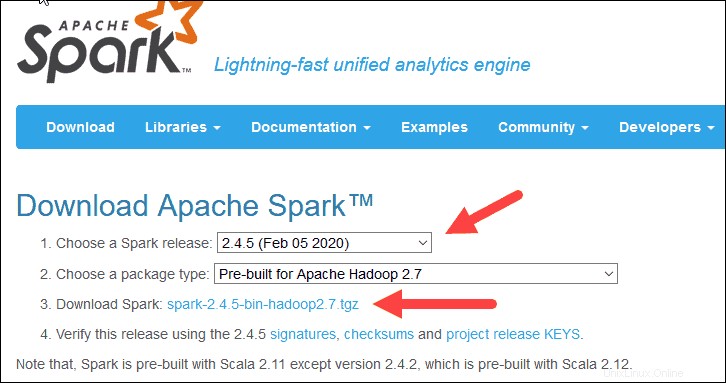
2. Unter Apache Spark herunterladen Überschrift gibt es zwei Dropdown-Menüs. Verwenden Sie die aktuelle Nicht-Vorschauversion.
- In unserem Fall in Spark-Release auswählen Dropdown-Menü wählen Sie 2.4.5 (5. Februar 2020) .
- Im zweiten Dropdown-Menü Wählen Sie einen Pakettyp aus , Belassen Sie die Auswahl Vorgefertigt für Apache Hadoop 2.7 .
3. Klicken Sie auf spark-2.4.5-bin-hadoop2.7.tgz verlinken.
4. Eine Seite mit einer Liste von Mirrors wird geladen, auf der Sie verschiedene Server zum Herunterladen sehen können. Wählen Sie eine aus der Liste aus und speichern Sie die Datei in Ihrem Downloads-Ordner.
Schritt 4:Überprüfen Sie die Spark-Softwaredatei
1. Überprüfen Sie die Integrität Ihres Downloads, indem Sie die Prüfsumme überprüfen der Datei. Dadurch wird sichergestellt, dass Sie mit unveränderter, unbeschädigter Software arbeiten.
2. Navigieren Sie zurück zum Spark-Download Seite und öffnen Sie die Prüfsumme Link, vorzugsweise in einem neuen Tab.
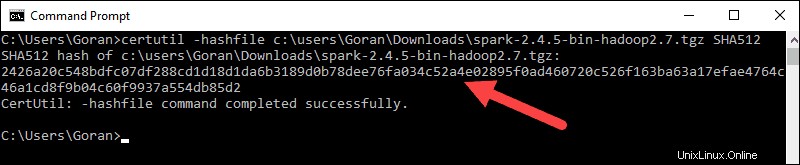
3. Öffnen Sie als Nächstes eine Befehlszeile und geben Sie den folgenden Befehl ein:
certutil -hashfile c:\users\username\Downloads\spark-2.4.5-bin-hadoop2.7.tgz SHA512
4. Ändern Sie den Benutzernamen in Ihren Benutzernamen. Das System zeigt einen langen alphanumerischen Code zusammen mit der Meldung Certutil: -hashfile completed successfully an .
5. Vergleichen Sie den Code mit dem Code, den Sie in einem neuen Browser-Tab geöffnet haben. Wenn sie übereinstimmen, ist Ihre Download-Datei unbeschädigt.
Schritt 5:Apache Spark installieren
Die Installation von Apache Spark umfasst das Extrahieren der heruntergeladenen Datei zum gewünschten Ort.
1. Erstellen Sie einen neuen Ordner namens Spark im Stammverzeichnis Ihres Laufwerks C:. Geben Sie in einer Befehlszeile Folgendes ein:
cd \
mkdir Spark2. Suchen Sie im Explorer nach der heruntergeladenen Spark-Datei.
3. Klicken Sie mit der rechten Maustaste auf die Datei und extrahieren Sie sie nach C:\Spark Verwenden Sie das Tool, das Sie auf Ihrem System haben (z. B. 7-Zip).
4. Jetzt Ihr C:\Spark Ordner hat einen neuen Ordner spark-2.4.5-bin-hadoop2.7 mit den notwendigen Dateien darin.
Schritt 6:Winutils.exe-Datei hinzufügen
Laden Sie die winutils.exe herunter Datei für die zugrunde liegende Hadoop-Version für die von Ihnen heruntergeladene Spark-Installation.
1. Navigieren Sie zu dieser URL https://github.com/cdarlint/winutils und in den bin Suchen Sie winutils.exe , und klicken Sie darauf.
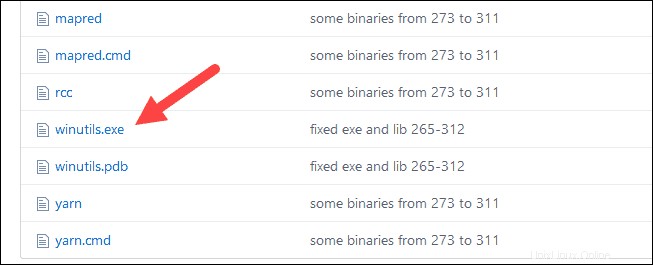
2. Suchen Sie den Download Schaltfläche auf der rechten Seite, um die Datei herunterzuladen.
3. Erstellen Sie jetzt neue Ordner Hadoop und bin auf C:mit Windows Explorer oder der Eingabeaufforderung.
4. Kopieren Sie die Datei winutils.exe aus dem Download-Ordner nach C:\hadoop\bin .
Schritt 7:Umgebungsvariablen konfigurieren
Durch das Konfigurieren von Umgebungsvariablen in Windows werden die Spark- und Hadoop-Speicherorte zu Ihrem System PATH hinzugefügt. Damit können Sie die Spark-Shell direkt von einem Eingabeaufforderungsfenster aus ausführen.
1. Klicken Sie auf Starten und geben Sie Umgebung ein .
2. Wählen Sie das Ergebnis mit der Bezeichnung Systemumgebungsvariablen bearbeiten aus .
3. Ein Dialogfeld „Systemeigenschaften“ wird angezeigt. Klicken Sie unten rechts auf Umgebungsvariablen und klicken Sie dann auf Neu im nächsten Fenster.
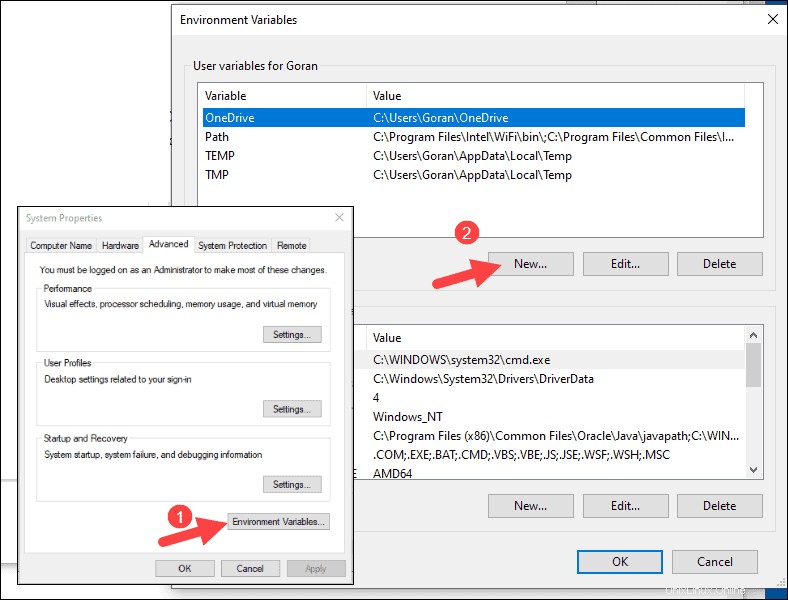
4. Für Variablenname geben Sie SPARK_HOME ein .
5. Für Variablenwert geben Sie C:\Spark\spark-2.4.5-bin-hadoop2.7 ein und klicken Sie auf OK. Wenn Sie den Ordnerpfad geändert haben, verwenden Sie stattdessen diesen.
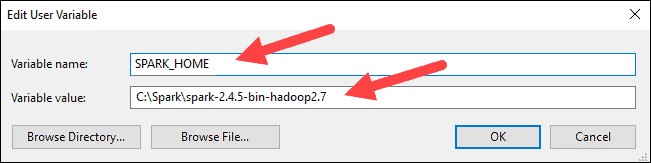
6. Klicken Sie im oberen Feld auf den Pfad Eintrag und klicken Sie dann auf Bearbeiten . Seien Sie vorsichtig beim Bearbeiten des Systempfads. Vermeiden Sie es, Einträge zu löschen, die sich bereits in der Liste befinden.
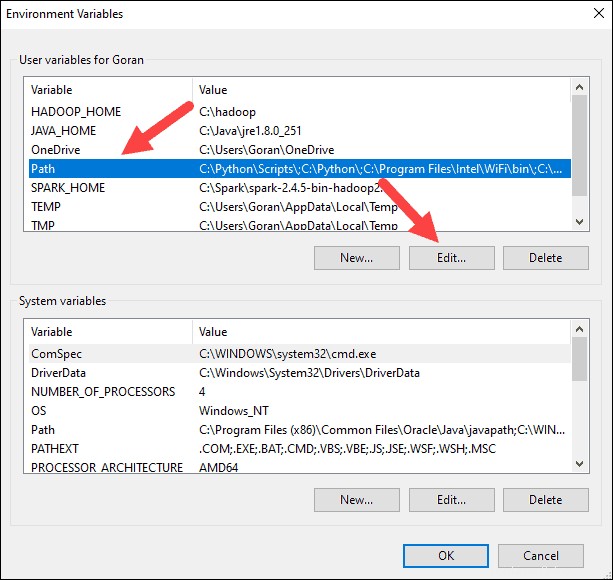
7. Sie sollten links ein Feld mit Einträgen sehen. Klicken Sie rechts auf Neu .
8. Das System hebt eine neue Zeile hervor. Geben Sie den Pfad zum Spark-Ordner C:\Spark\spark-2.4.5-bin-hadoop2.7\bin ein . Wir empfehlen die Verwendung von %SPARK_HOME%\bin um mögliche Probleme mit dem Pfad zu vermeiden.
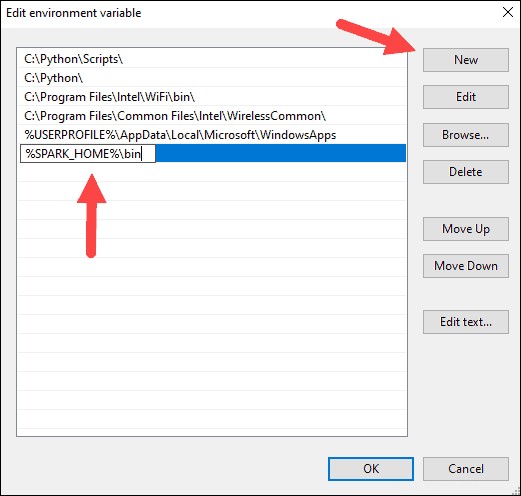
9. Wiederholen Sie diesen Vorgang für Hadoop und Java.
- Für Hadoop lautet der Variablenname HADOOP_HOME und verwenden Sie für den Wert den Pfad des zuvor erstellten Ordners:C:\hadoop. Fügen Sie C:\hadoop\bin hinzu in die Pfadvariable Feld, aber wir empfehlen die Verwendung von %HADOOP_HOME%\bin .
- Für Java lautet der Variablenname JAVA_HOME und verwenden Sie für den Wert den Pfad zu Ihrem Java JDK-Verzeichnis (in unserem Fall ist es C:\Program Files\Java\jdk1.8.0_251 ).
10. Klicken Sie auf OK um alle geöffneten Fenster zu schließen.
Schritt 8:Starten Sie Spark
1. Öffnen Sie ein neues Eingabeaufforderungsfenster mit der rechten Maustaste und Als Administrator ausführen :
2. Um Spark zu starten, geben Sie Folgendes ein:
C:\Spark\spark-2.4.5-bin-hadoop2.7\bin\spark-shell
Wenn Sie den Umgebungspfad festlegen richtig ist, können Sie spark-shell eingeben um Spark zu starten.
3. Das System sollte mehrere Zeilen anzeigen, die den Status der Bewerbung angeben. Möglicherweise erhalten Sie ein Java-Popup. Wählen Sie Zugriff zulassen aus um fortzufahren.
Schließlich erscheint das Spark-Logo und die Eingabeaufforderung zeigt die Scala-Shell an .
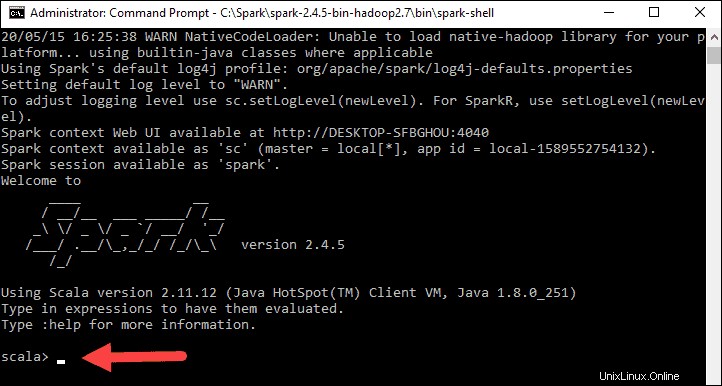
4. Öffnen Sie einen Webbrowser und navigieren Sie zu http://localhost:4040/ .
5. Sie können localhost ersetzen mit dem Namen Ihres Systems.
6. Sie sollten eine Apache Spark-Shell-Webbenutzeroberfläche sehen. Das folgende Beispiel zeigt die Executors Seite.
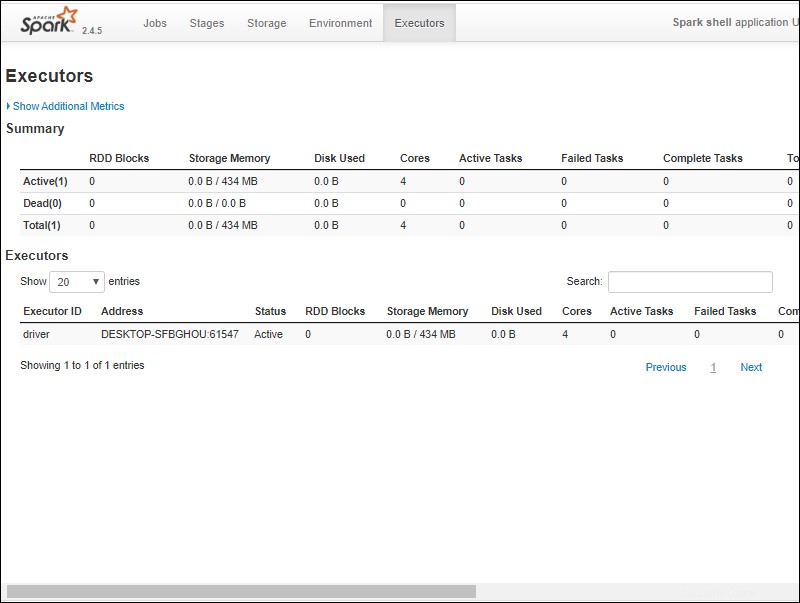
7. Um Spark zu beenden und die Scala-Shell zu schließen, drücken Sie ctrl-d im Eingabeaufforderungsfenster.
Spark testen
In diesem Beispiel starten wir die Spark-Shell und verwenden Scala, um den Inhalt einer Datei zu lesen. Sie können eine vorhandene Datei verwenden, z. B. die README Datei im Spark-Verzeichnis, oder Sie können Ihre eigene erstellen. Wir haben pnaptest erstellt mit etwas Text.
1. Öffnen Sie ein Eingabeaufforderungsfenster und navigieren Sie zu dem Ordner mit der Datei, die Sie verwenden möchten, und starten Sie die Spark-Shell.
2. Geben Sie zunächst eine im Spark-Kontext zu verwendende Variable mit dem Namen der Datei an. Denken Sie daran, die Dateierweiterung hinzuzufügen, falls vorhanden.
val x =sc.textFile("pnaptest")3. Die Ausgabe zeigt, dass ein RDD erstellt wurde. Dann können wir den Dateiinhalt anzeigen, indem wir diesen Befehl verwenden, um eine Aktion aufzurufen:
x.take(11).foreach(println)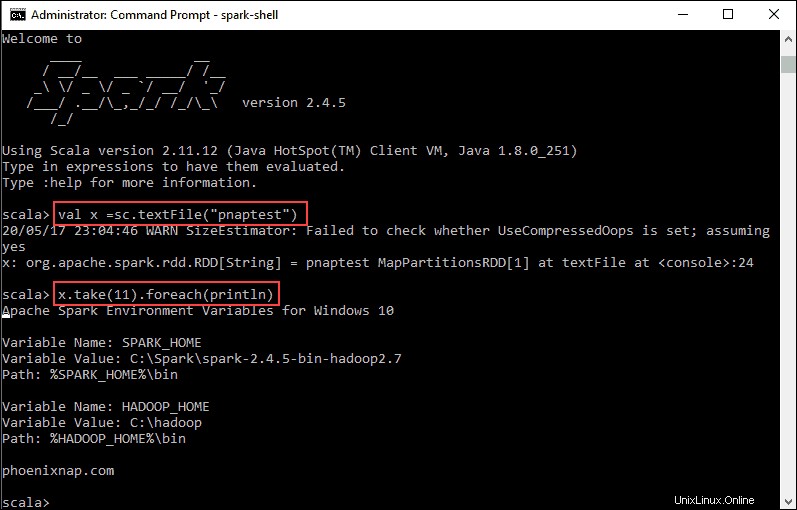
Dieser Befehl weist Spark an, 11 Zeilen aus der angegebenen Datei zu drucken. Um eine Aktion für diese Datei auszuführen (Wert x ), fügen Sie einen weiteren Wert y hinzu , und führen Sie eine Kartentransformation durch.
4. Mit diesem Befehl können Sie beispielsweise die Zeichen rückwärts drucken:
val y = x.map(_.reverse)5. Das System erstellt ein untergeordnetes RDD in Bezug auf das erste. Geben Sie dann an, wie viele Zeilen Sie ab dem Wert y drucken möchten :
y.take(11).foreach(println)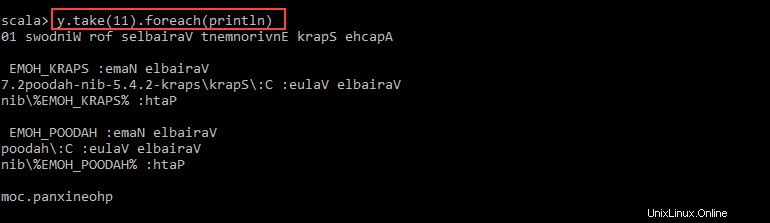
Die Ausgabe gibt 11 Zeilen des pnaptests aus Datei in umgekehrter Reihenfolge.
Wenn Sie fertig sind, verlassen Sie die Shell mit ctrl-d .