Einführung
Cassandra ist eine verteilte Open-Source-Datenbanksoftware zur Handhabung von NoSQL-Datenbanken. Diese Software verwendet CQL (Cassandra Query Language) als Basis für die Kommunikation. CQL speichert Daten in Tabellen, die in einer Reihe von Zeilen mit Spalten angeordnet sind, die Schlüssel-Wert-Paare enthalten.
CQL-Tabellen sind in Cassandra in Datencontainern gruppiert, die als Keyspaces bezeichnet werden. In einem Schlüsselraum gespeicherte Daten stehen in keinem Zusammenhang mit anderen Daten im Cluster. Sie können also Tabellen für mehrere verschiedene Zwecke in separaten Schlüsselräumen in einem Cluster haben, und die Daten stimmen nicht überein.
In diesem Handbuch lernen Sie, wie Sie eine Cassandra-Tabelle für verschiedene Zwecke erstellen und wie Sie Tabellen mit der Cassandra-Shell ändern, löschen oder kürzen.

Voraussetzungen
- Cassandra-Datenbanksoftware auf Ihrem System installiert
- Zugriff auf ein Terminal- oder Befehlszeilentool zum Laden von cqlsh
- Ein Benutzer mit den erforderlichen Berechtigungen um die Befehle auszuführen
Schlüsselraum für Cassandra-Tabelle auswählen
Bevor Sie mit dem Hinzufügen einer Tabelle beginnen, müssen Sie den Schlüsselraum bestimmen, in dem Sie Ihre Tabelle erstellen möchten . Dafür gibt es zwei Möglichkeiten.
Option 1:Der USE-Befehl
Führen Sie USE aus Befehl, um einen Schlüsselraum auszuwählen, für den alle Ihre Befehle gelten. Geben Sie dazu in der cqlsh-Shell Folgendes ein:
USE keyspace_name;Dann können Sie mit dem Hinzufügen von Tabellen beginnen.
Option 2:Geben Sie den Schlüsselraumnamen in der Abfrage an
Die zweite Möglichkeit besteht darin, den Schlüsselraumnamen in der Abfrage für die Tabellenerstellung anzugeben. Der erste Teil des Befehls vor Spaltennamen und Optionen sieht folgendermaßen aus:
CREATE TABLE keyspace_name.table_nameAuf diese Weise erstellen Sie sofort eine Tabelle in dem von Ihnen definierten Schlüsselraum.
Grundlegende Syntax zum Erstellen von Cassandra-Tabellen
Das Erstellen von Tabellen mit CQL ähnelt SQL-Abfragen. In diesem Abschnitt zeigen wir Ihnen die grundlegende Syntax zum Erstellen von Tabellen in Cassandra.
Die grundlegende Syntax zum Erstellen einer Tabelle sieht folgendermaßen aus:
CREATE TABLE tableName (
columnName1 dataType,
columnName2 dataType,
columnName2 datatype
PRIMARY KEY (columnName)
);
Optional können Sie mit WITH zusätzliche Tabelleneigenschaften und -werte definieren :
WITH propertyName=propertyValue;Verwenden Sie es beispielsweise, um zu definieren, wie die Daten auf der Festplatte gespeichert werden sollen oder ob eine Komprimierung verwendet werden soll.
Cassandra-Primärschlüsseltypen
Jede Tabelle in Cassandra muss einen Primärschlüssel haben, der eine Zeile eindeutig macht. Mit Primärschlüsseln bestimmen Sie, welcher Knoten die Daten speichert und wie er sie partitioniert.
Es gibt zwei Arten von Primärschlüsseln:
- Einfacher Primärschlüssel . Enthält nur einen Spaltennamen als Partitionsschlüssel, um zu bestimmen, auf welchen Knoten die Daten gespeichert werden.
- Zusammengesetzter Primärschlüssel. Verwendet einen Partitionierungsschlüssel und mehrere Clustering-Spalten, um zu definieren, wo die Daten gespeichert und wie sie auf einer Partition sortiert werden.
- Zusammengesetzter Partitionsschlüssel. In diesem Fall gibt es mehrere Spalten, die bestimmen, wo Daten gespeichert werden. Auf diese Weise können Sie Daten in kleinere Teile aufteilen, um sie auf mehrere Partitionen zu verteilen, um Hotspots zu vermeiden.
So erstellen Sie eine Cassandra-Tabelle
In den folgenden Abschnitten wird erläutert, wie Sie Tabellen mit verschiedenen Arten von Primärschlüsseln erstellen. Wählen Sie zunächst einen Schlüsselraum aus, in dem Sie eine Tabelle erstellen möchten. In unserem Fall:
USE businesinfo;Jede Tabelle enthält Spalten und einen Cassandra-Datentyp für jeden Eintrag.
Tabelle mit einfachem Primärschlüssel erstellen
Das erste Beispiel ist eine einfache Tabelle mit Lieferanten. Die ID ist für jeden Lieferanten eindeutig und dient als Primärschlüssel.
Die CQL-Abfrage sieht folgendermaßen aus:
CREATE TABLE suppliers (
supp_id int PRIMARY KEY,
supp_city text,
supp_email text,
supp_fee int,
supp_name text,
supp_phone int
);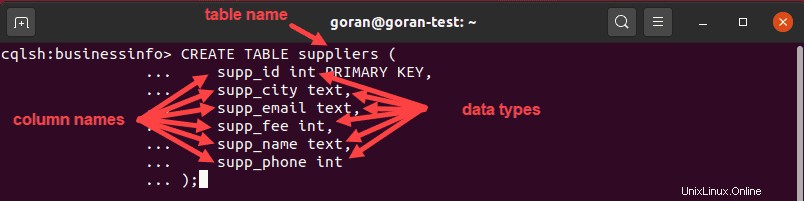
Diese Abfrage hat eine Tabelle mit dem Namen supplier erstellt mit supp_id als Primärschlüssel für die Tabelle. Wenn Sie einen einfachen Primärschlüssel mit dem Spaltennamen als Partitionsschlüssel verwenden, können Sie ihn entweder am Anfang der Abfrage (neben der Spalte, die als Primärschlüssel dienen soll) oder ganz unten platzieren und dann den Spaltennamen angeben :
CREATE TABLE suppliers (
supp_id int,
supp_city text,
supp_email text,
supp_fee int,
supp_name text,
supp_phone int
PRIMARY KEY(supp_id)
);Um zu sehen, ob sich die Tabelle im Schlüsselraum befindet, geben Sie Folgendes ein:
DESCRIBE TABLES;Die Ausgabe listet alle Tabellen in diesem Schlüsselraum zusammen mit der von Ihnen erstellten auf.

Um den Inhalt der Tabellen anzuzeigen, geben Sie ein:
SELECT * FROM suppliers;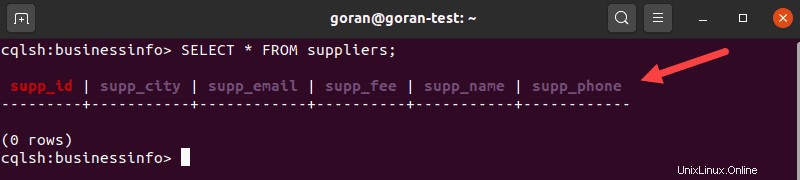
Die Ausgabe zeigt alle Spalten, die beim Erstellen einer Tabelle definiert wurden.
Eine andere Möglichkeit, die Details einer Tabelle anzuzeigen, ist die Verwendung von DESCRIBE und geben Sie einen Tabellennamen an:
DESCRIBE suppliers;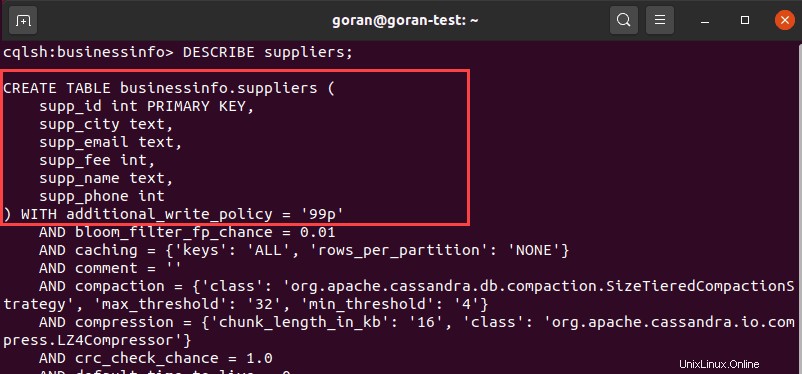
Die Ausgabe zeigt die Spalten und die Standardeinstellungen für die Tabelle an.
Tabelle mit zusammengesetztem Primärschlüssel erstellen
Um Abfragen durchzuführen und die Ergebnisse in einer bestimmten Reihenfolge sortiert zu erhalten, erstellen Sie eine Tabelle mit einem zusammengesetzten Primärschlüssel.
Erstellen Sie beispielsweise eine Tabelle für Lieferanten und alle Produkte, die sie anbieten. Da die Produkte möglicherweise nicht für jeden Lieferanten eindeutig sind, müssen Sie dem Primärschlüssel eine oder mehrere Clustering-Spalten hinzufügen, um ihn eindeutig zu machen.
Das Tabellenschema sieht folgendermaßen aus:
CREATE TABLE suppliers_by_product (
supp_product text,
supp_id int,
supp_product_quantity text,
PRIMARY KEY(supp_product, supp_id)
);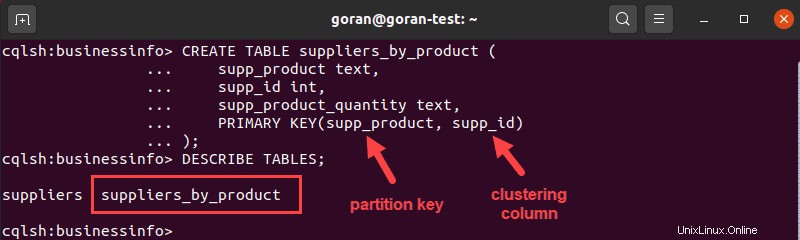
In diesem Fall haben wir supp_product verwendet und supp_id um einen eindeutigen zusammengesetzten Schlüssel zu erstellen. Hier der erste Eintrag in der brackets supp_product ist der Partitionsschlüssel. Es bestimmt, wo die Daten gespeichert werden, dh wie das System die Daten partitioniert.
Der nächste Eintrag ist die Clustering-Spalte, die bestimmt, wie Cassandra die Daten sortiert, in unserem Fall nach supp_id .
Das obige Bild zeigt, dass die Tabelle erfolgreich erstellt wurde. Um die Tabellendetails zu überprüfen, führen Sie DESCRIBE TABLE aus Abfrage für die neue Tabelle:
DESCRIBE TABLE suppliers_by_product;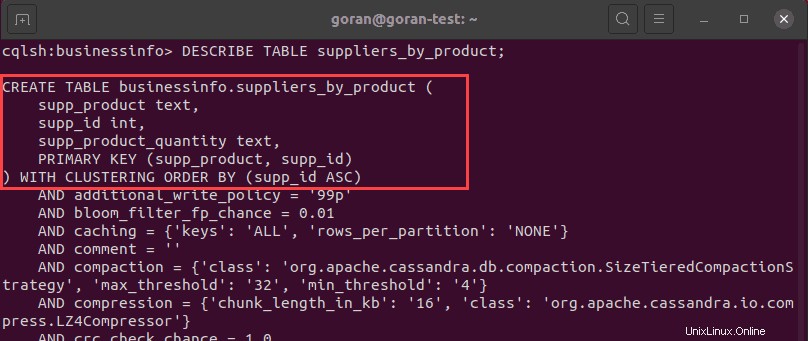
Die Standardeinstellung für die Clustering-Reihenfolge ist aufsteigend (ASC). Sie können auf absteigend (DESC) wechseln, indem Sie nach dem Primärschlüssel die folgende Anweisung hinzufügen:
WITH CLUSTERING ORDER BY (supp_id DESC);Wir haben eine Clusterspalte nach dem Partitionsschlüssel angegeben. Falls Sie die Daten nach zwei Spalten sortieren müssen, fügen Sie eine weitere Spalte innerhalb der Primärschlüsselklammern hinzu.
Tabellen mit zusammengesetztem Partitionsschlüssel erstellen
Das Erstellen einer Tabelle mit einem zusammengesetzten Partitionsschlüssel ist hilfreich, wenn ein Knoten eine große Datenmenge speichert und Sie die Last auf mehrere Knoten verteilen möchten.
Definieren Sie in diesem Fall einen Primärschlüssel mit einem Partitionsschlüssel, der aus mehreren Spalten besteht. Sie müssen doppelte Klammern verwenden. Fügen Sie dann wie zuvor Clustering-Spalten hinzu, um einen eindeutigen Primärschlüssel zu erstellen.
Zum Beispiel:
CREATE TABLE suppliers_by_product_type (
supp_product_consume text,
supp_product_stock text,
supp_id int,
supp_name text,
PRIMARY KEY((supp_product_consume, supp_product_stock), supp_id)
);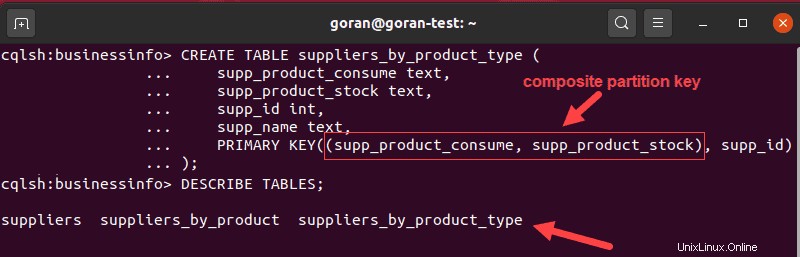
Im obigen Beispiel haben wir die Daten in zwei Kategorien unterteilt, Verbrauchsprodukte des Lieferanten und vorrätige Produkte, und die Daten mithilfe eines zusammengesetzten Partitionsschlüssels verteilt.
Wenn Sie stattdessen einen zusammengesetzten Primärschlüssel mit einem einfachen Partitionsschlüssel und mehreren Clustering-Spalten verwenden, würde ein Knoten alle nach mehreren Spalten sortierten Daten verarbeiten.
Cassandra Drop Table
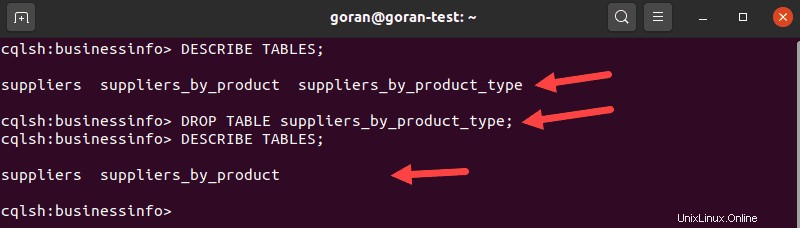
Um eine Tabelle in Cassandra zu löschen, verwenden Sie DROP TABLE Erklärung. Geben Sie Folgendes ein, um eine zu löschende Tabelle auszuwählen:
DESCRIBE TABLES;Suchen Sie die Tabelle, die Sie löschen möchten. Verwenden Sie den Namen der Tabelle, um sie zu entfernen:
DROP TABLE suppliers_by_product_type;
Führen Sie DESCRIBE TABLES aus erneut abfragen, um zu bestätigen, dass Sie die Tabelle erfolgreich gelöscht haben.
Cassandra Alter Tisch
Mit Cassandra CQL können Sie Spalten zu einer Tabelle hinzufügen oder daraus entfernen. Verwenden Sie ALTER TABLE Befehl, um Änderungen an einer Tabelle vorzunehmen.
Eine Spalte zu einer Tabelle hinzufügen
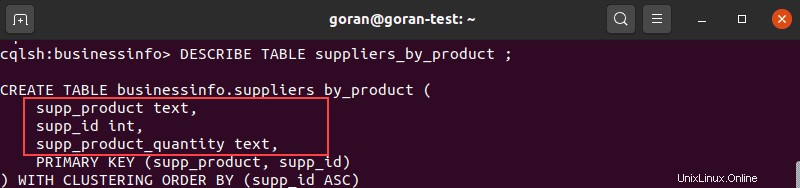
Bevor Sie einer Tabelle eine Spalte hinzufügen, sollten Sie sich den Inhalt der Tabelle ansehen, um sicherzustellen, dass der Spaltenname noch nicht existiert.
Verwenden Sie nach der Überprüfung ALTER TABLE Abfrage in diesem Format, um eine Spalte hinzuzufügen:
ALTER TABLE suppliers_by_product
ADD supp_name text;Beschreiben Sie die Tabelle, um zu bestätigen, dass die Spalte in der Liste erscheint.
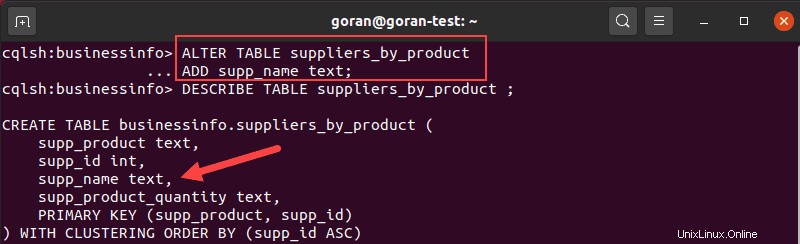
Eine Spalte aus einer Tabelle löschen
Ähnlich wie beim Hinzufügen einer Spalte können Sie eine Spalte aus einer Tabelle löschen. Suchen Sie die Spalte, die Sie entfernen möchten, mithilfe von DESCRIBE TABLES Abfrage.
Geben Sie dann ein:
ALTER TABLE suppliers_by_product
DROP supp_product_quantity;Cassandra-Tabelle abschneiden
Wenn Sie keine ganze Tabelle löschen möchten, aber alle Zeilen entfernen müssen, verwenden Sie TRUNCATE Befehl.
Zum Beispiel, um alle Zeilen aus der Tabelle Lieferanten zu löschen , geben Sie ein:
TRUNCATE suppliers;
Verwenden Sie SELECT, um zu überprüfen, ob Ihre Tabelle keine Zeilen mehr enthält Aussage.
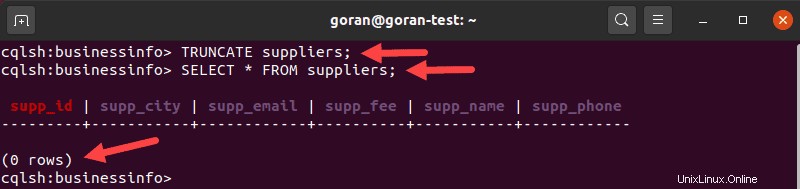
Sobald Sie eine Tabelle kürzen, sind die Änderungen dauerhaft, seien Sie also vorsichtig, wenn Sie diese Abfrage verwenden.