
In diesem Tutorial zeigen wir Ihnen, wie Sie Apache Hadoop auf CentOS 7 installieren. Für diejenigen unter Ihnen, die es nicht wussten, Apache Hadoop ist ein in Java geschriebenes Open-Source-Software-Framework verteilte Speicher- und Verteilungsprozesse verarbeitet es sehr große Datensätze, indem es sie auf Computercluster verteilt Anstatt sich auf Hardware zu verlassen, um eine hohe Verfügbarkeit bereitzustellen, ist die Bibliothek selbst so konzipiert, dass sie Fehler auf der Anwendungsebene erkennt und behandelt und so eine hohe Leistung erbringt -verfügbarer Dienst auf einem Cluster von Computern, von denen jeder fehleranfällig sein kann.
In diesem Artikel wird davon ausgegangen, dass Sie zumindest über Grundkenntnisse in Linux verfügen, wissen, wie man die Shell verwendet, und vor allem, dass Sie Ihre Website auf Ihrem eigenen VPS hosten. Die Installation ist recht einfach. Das werde ich tun zeigen Ihnen die schrittweise Installation von Apache Hadoop auf CentOS 7.
Voraussetzungen
- Ein Server, auf dem eines der folgenden Betriebssysteme ausgeführt wird:CentOS 7.
- Es wird empfohlen, dass Sie eine neue Betriebssysteminstallation verwenden, um potenziellen Problemen vorzubeugen.
- SSH-Zugriff auf den Server (oder öffnen Sie einfach das Terminal, wenn Sie sich auf einem Desktop befinden).
- Ein
non-root sudo useroder Zugriff auf denroot user. Wir empfehlen, alsnon-root sudo userzu agieren , da Sie Ihr System beschädigen können, wenn Sie als Root nicht aufpassen.
Installieren Sie Apache Hadoop auf CentOS 7
Schritt 1. Installieren Sie Java.
Da Hadoop auf Java basiert, stellen Sie sicher, dass Sie Java JDK auf dem System installiert haben. Wenn Sie Java nicht auf Ihrem System installiert haben, verwenden Sie den folgenden Link um es zuerst zu installieren.
- Installieren Sie Java JDK 8 auf CentOS 7
root@idroot.us ~# java -version java version "1.8.0_45" Java(TM) SE Runtime Environment (build 1.8.0_45-b14) Java HotSpot(TM) 64-Bit Server VM (build 25.45-b02, mixed mode)
Schritt 2. Installieren Sie Apache Hadoop.
Es wird empfohlen, einen normalen Benutzer zu erstellen, um Apache Hadoop zu konfigurieren, erstellen Sie einen Benutzer mit dem folgenden Befehl:
useradd hadoop passwd hadoop
Nach dem Erstellen eines Benutzers ist es auch erforderlich, schlüsselbasiertes ssh zu seinem eigenen Konto einzurichten. Führen Sie dazu die folgenden Befehle aus:
su - hadoop ssh-keygen -t rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys
Laden Sie die neueste stabile Version von Apache Hadoop herunter. Zum Zeitpunkt der Erstellung dieses Artikels ist es Version 2.7.0:
wget http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.7.0/hadoop-2.7.0.tar.gz tar xzf hadoop-2.7.0.tar.gz mv hadoop-2.7.0 hadoop
Schritt 3. Apache Hadoop konfigurieren.
Setup-Umgebungsvariablen, die von Hadoop verwendet werden. Bearbeiten Sie die ~/.bashrc-Datei und hängen Sie die folgenden Werte am Ende der Datei an:
export HADOOP_HOME=/home/hadoop/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
Umgebungsvariablen auf die aktuell laufende Sitzung anwenden:
source ~/.bashrc
Bearbeiten Sie nun $HADOOP_HOME/etc/hadoop/hadoop-env.sh Datei und legen Sie die Umgebungsvariable JAVA_HOME fest:
export JAVA_HOME=/usr/jdk1.8.0_45/
Hadoop hat viele Konfigurationsdateien, die gemäß den Anforderungen Ihrer Hadoop-Infrastruktur konfiguriert werden müssen. Beginnen wir mit der Konfiguration mit einem einfachen Hadoop-Cluster-Setup mit einem einzigen Knoten:
cd $HADOOP_HOME/etc/hadoop
Bearbeiten Sie core-site.xml :
<configuration> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> </property> </configuration>
Bearbeiten Sie hdfs-site.xml :
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.name.dir</name> <value>file:///home/hadoop/hadoopdata/hdfs/namenode</value> </property> <property> <name>dfs.data.dir</name> <value>file:///home/hadoop/hadoopdata/hdfs/datanode</value> </property> </configuration>
Bearbeiten Sie mapred-site.xml :
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
Bearbeiten Sie yarn-site.xml :
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> </configuration>
Formatieren Sie nun namenode mit folgendem Befehl, vergessen Sie nicht, das Speicherverzeichnis zu überprüfen:
hdfs namenode -format
Starten Sie alle Hadoop-Dienste mit dem folgenden Befehl:
cd $HADOOP_HOME/sbin/ start-dfs.sh start-yarn.sh
Um zu überprüfen, ob alle Dienste ordnungsgemäß gestartet wurden, verwenden Sie ‘jps ‘Befehl:
jps
Schritt 4. Zugriff auf Apache Hadoop.
Apache Hadoop ist standardmäßig auf HTTP-Port 8088 und Port 50070 verfügbar. Öffnen Sie Ihren bevorzugten Browser und navigieren Sie zu http://your-domain.com:50070 oder http://server-ip:50070 . Wenn Sie eine Firewall verwenden, öffnen Sie bitte die Ports 8088 und 50070, um den Zugriff auf das Control Panel zu ermöglichen.
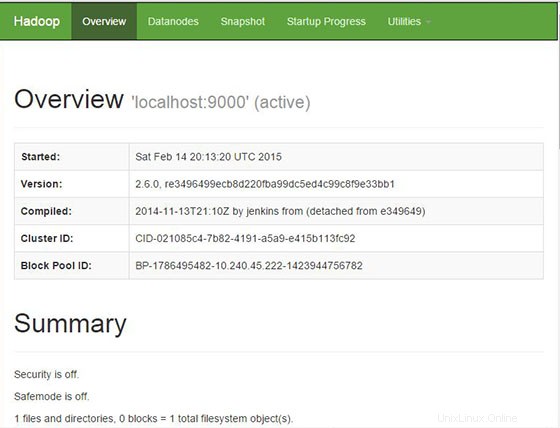
Greifen Sie jetzt auf Port 8088 zu, um Informationen über den Cluster und alle Anwendungen zu erhalten:
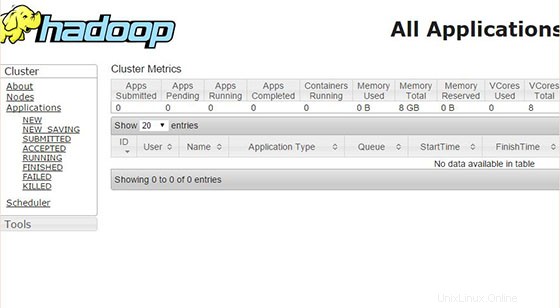
Herzlichen Glückwunsch! Sie haben Apache Hadoop erfolgreich installiert. Vielen Dank, dass Sie dieses Tutorial zur Installation von Apache Hadoop auf einem CentOS 7-System verwendet haben. Für zusätzliche Hilfe oder nützliche Informationen empfehlen wir Ihnen, die offizielle Apache Hadoop-Website zu besuchen.