
In diesem Tutorial zeigen wir Ihnen, wie Sie Apache Spark unter Debian 11 installieren. Für diejenigen unter Ihnen, die es nicht wussten, Apache Spark ist ein kostenloses Open-Source-Universalprogramm Framework für Clustered Computing. Es ist speziell auf Geschwindigkeit ausgelegt und wird beim maschinellen Lernen verwendet, um die Verarbeitung zu komplexen SQL-Abfragen zu streamen. Es unterstützt mehrere APIs für Streaming, Graphverarbeitung, einschließlich Java, Python, Scala und R. Spark ist meistens darin installiert Hadoop-Cluster, aber Sie können Spark auch im Standalone-Modus installieren und konfigurieren.
Dieser Artikel geht davon aus, dass Sie zumindest über Grundkenntnisse in Linux verfügen, wissen, wie man die Shell verwendet, und vor allem, dass Sie Ihre Website auf Ihrem eigenen VPS hosten. Die Installation ist recht einfach und setzt Sie voraus im Root-Konto ausgeführt werden, wenn nicht, müssen Sie möglicherweise 'sudo hinzufügen ‘ zu den Befehlen, um Root-Rechte zu erhalten. Ich zeige Ihnen Schritt für Schritt die Installation von Apache Spark auf einem Debian 11 (Bullseye).
Voraussetzungen
- Ein Server, auf dem eines der folgenden Betriebssysteme ausgeführt wird:Debian 11 (Bullseye).
- Es wird empfohlen, dass Sie eine neue Betriebssysteminstallation verwenden, um potenziellen Problemen vorzubeugen.
- Ein
non-root sudo useroder Zugriff auf denroot user. Wir empfehlen, alsnon-root sudo userzu agieren , da Sie Ihr System beschädigen können, wenn Sie als Root nicht aufpassen.
Installieren Sie Apache Spark auf Debian 11 Bullseye
Schritt 1. Bevor wir Software installieren, ist es wichtig sicherzustellen, dass Ihr System auf dem neuesten Stand ist, indem Sie das folgende apt ausführen Befehle im Terminal:
sudo apt update sudo apt upgrade
Schritt 2. Java installieren.
Führen Sie den folgenden Befehl unten aus, um Java und andere Abhängigkeiten zu installieren:
sudo apt install default-jdk scala git
Überprüfen Sie die Java-Installation mit dem folgenden Befehl:
java --version
Schritt 3. Apache Spark unter Debian 11 installieren.
Jetzt laden wir die neueste Version von Apache Spark von der offiziellen Seite mit wget herunter Befehl:
wget https://dlcdn.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
Extrahieren Sie als Nächstes die heruntergeladene Datei:
tar -xvzf spark-3.1.2-bin-hadoop3.2.tgz mv spark-3.1.2-bin-hadoop3.2/ /opt/spark
Bearbeiten Sie danach die ~/.bashrc Datei und fügen Sie die Spark-Pfadvariable hinzu:
nano ~/.bashrc
Fügen Sie die folgende Zeile hinzu:
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
Speichern und schließen Sie die Datei und aktivieren Sie dann die Spark-Umgebungsvariable mit dem folgenden Befehl:
source ~/.bashrc
Schritt 3. Starten Sie Apache Spark Master Server.
An diesem Punkt ist Apache Spark installiert. Lassen Sie uns nun seinen eigenständigen Master-Server starten, indem Sie sein Skript ausführen:
start-master.sh
Standardmäßig lauscht Apache Spark auf Port 8080. Sie können dies mit dem folgenden Befehl überprüfen:
ss -tunelp | grep 8080
Schritt 4. Zugriff auf die Apache Spark-Weboberfläche.
Nach erfolgreicher Konfiguration greifen Sie nun über die URL http://your-server-ip-address:8080 auf die Apache Spark-Weboberfläche zu . Sie sollten den Apache Spark Master- und Slave-Dienst auf dem folgenden Bildschirm sehen:
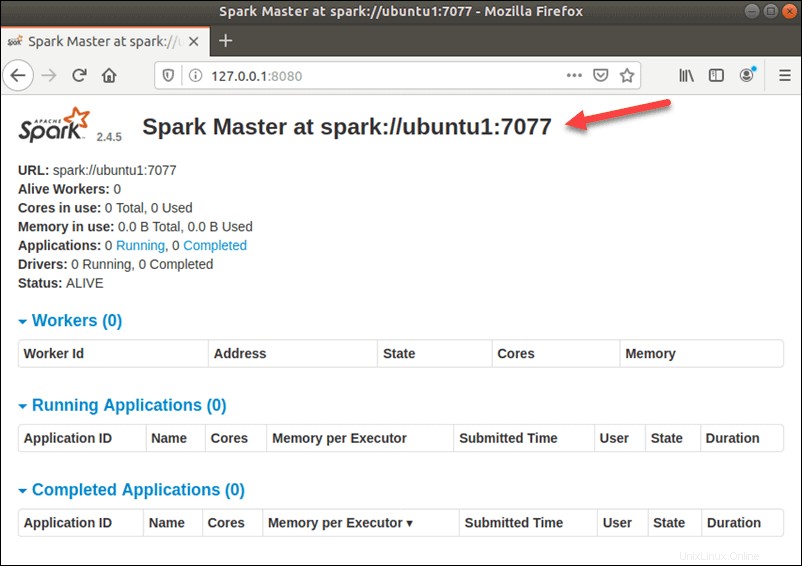
In diesem Einzelserver-Standalone-Setup starten wir einen Slave-Server zusammen mit dem Master-Server. Die start-slave.sh Der Befehl wird verwendet, um den Spark-Worker-Prozess zu starten:
start-slave.sh spark://ubuntu1:7077
Jetzt, da ein Worker betriebsbereit ist und ausgeführt wird, sollten Sie ihn in der Liste sehen, wenn Sie die Web-Benutzeroberfläche von Spark Master neu laden:
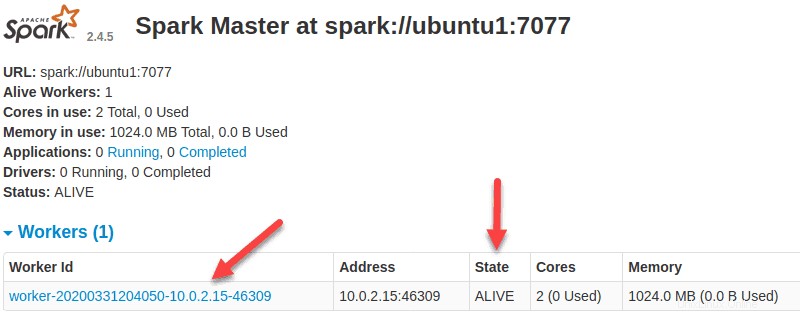
Wenn Sie die Konfiguration abgeschlossen haben, starten Sie den Master- und den Slave-Server und testen Sie, ob die Spark-Shell funktioniert:
spark-shell
Sie erhalten die folgende Oberfläche:
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 11.0.12)
Type in expressions to have them evaluated.
Type :help for more information.
scala> Herzlichen Glückwunsch! Sie haben Apache Spark erfolgreich installiert. Vielen Dank, dass Sie dieses Tutorial zur Installation der neuesten Version von Apache Spark auf Debian 11 Bullseye verwendet haben. Für zusätzliche Hilfe oder nützliche Informationen empfehlen wir Ihnen, die offizielle Apache Spark-Website.