
In diesem Tutorial zeigen wir Ihnen, wie Sie Apache Spark auf einem CentOS 7-Server installieren. Für diejenigen unter Ihnen, die es nicht wussten, Apache Spark ist ein schnelles und universelles Cluster-Computing-System . Es bietet High-Level-APIs in Java, Scala und Python sowie eine optimierte Engine, die Gesamtausführungsdiagramme unterstützt. Es unterstützt auch eine Vielzahl von High-Level-Tools, darunter Spark SQL für SQL und strukturierte Informationsverarbeitung, MLlib für Maschinen Learning, GraphX für die Grafikverarbeitung und Spark Streaming.
Dieser Artikel geht davon aus, dass Sie zumindest über Grundkenntnisse in Linux verfügen, wissen, wie man die Shell verwendet, und vor allem, dass Sie Ihre Website auf Ihrem eigenen VPS hosten. Die Installation ist recht einfach und setzt Sie voraus im Root-Konto ausgeführt werden, wenn nicht, müssen Sie möglicherweise 'sudo hinzufügen ‘ zu den Befehlen, um Root-Rechte zu erhalten. Ich zeige Ihnen Schritt für Schritt die Installation von Apache Spark auf dem CentOS 7-Server.
Installieren Sie Apache Spark auf CentOS 7
Schritt 1. Beginnen wir zunächst damit, sicherzustellen, dass Ihr System auf dem neuesten Stand ist.
yum clean all yum -y install epel-release yum -y update
Schritt 2. Java installieren.
Installieren von Java für die erforderliche Installation von Apache-Spark:
yum install java -y
Überprüfen Sie nach der Installation die Java-Version:
java -version
Schritt 3. Scala installieren.
Spark installiert Scala während des Installationsvorgangs, also müssen wir nur sicherstellen, dass Java und Python vorhanden sind:
wget http://www.scala-lang.org/files/archive/scala-2.10.1.tgz tar xvf scala-2.10.1.tgz sudo mv scala-2.10.1 /usr/lib sudo ln -s /usr/lib/scala-2.10.1 /usr/lib/scala export PATH=$PATH:/usr/lib/scala/bin
Überprüfen Sie nach der Installation die Scala-Version:
scala -version
Schritt 4. Apache Spark installieren.
Installieren Sie Apache Spark mit dem folgenden Befehl:
wget http://www-eu.apache.org/dist/spark/spark-2.2.1/spark-2.2.1-bin-hadoop2.7.tgz tar -xzf spark-2.2.1-bin-hadoop2.7.tgz export SPARK_HOME=$HOME/spark-2.2.1-bin-hadoop2.7 export PATH=$PATH:$SPARK_HOME/bin
Richten Sie einige Umgebungsvariablen ein, bevor Sie Spark starten:
echo 'export PATH=$PATH:/usr/lib/scala/bin' >> .bash_profile echo 'export SPARK_HOME=$HOME/spark-2.2.1-bin-hadoop2.6' >> .bash_profile echo 'export PATH=$PATH:$SPARK_HOME/bin' >> .bash_profile
Der eigenständige Spark-Cluster kann manuell gestartet werden, d. h. durch Ausführen des Startskripts auf jedem Knoten oder einfach mithilfe der verfügbaren Startskripts. Zum Testen können wir Master- und Slave-Daemons ausführen auf demselben Rechner:
./sbin/start-master.sh
Schritt 5. Firewall für Apache Spark konfigurieren.
firewall-cmd --permanent --zone=public --add-port=6066/tcp firewall-cmd --permanent --zone=public --add-port=7077/tcp firewall-cmd --permanent --zone=public --add-port=8080-8081/tcp firewall-cmd --reload
Schritt 6. Zugriff auf Apache Spark.
Apache Spark ist standardmäßig auf HTTP-Port 7077 verfügbar. Öffnen Sie Ihren bevorzugten Browser und navigieren Sie zu http://yourdomain.com:7077 oder http://your-server-ip:7077 und führen Sie die erforderlichen Schritte aus, um die Installation abzuschließen.
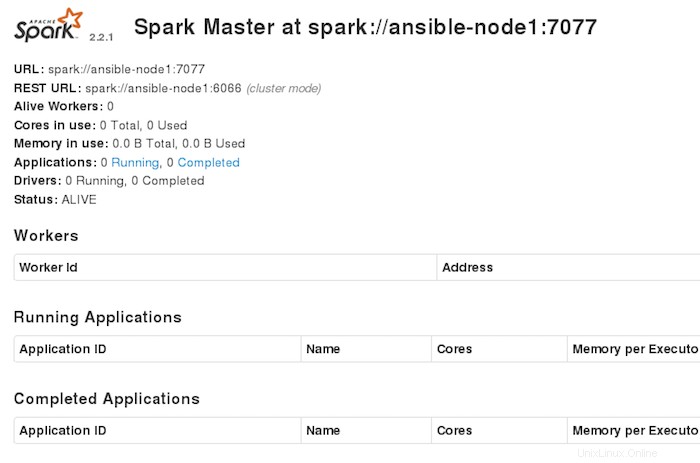
Herzlichen Glückwunsch! Sie haben Apache Spark erfolgreich auf CentOS 7 installiert. Vielen Dank, dass Sie dieses Tutorial zur Installation von Apache Spark auf CentOS 7-Systemen verwendet haben. Für zusätzliche Hilfe oder nützliche Informationen empfehlen wir Ihnen, die offizielle Apache Spark-Website.