Was ist ein Dateisystem? Laut dem frühen Linux-Mitarbeiter und Autor Robert Love ist „ein Dateisystem ein hierarchischer Speicher von Daten, der einer bestimmten Struktur folgt“. Diese Beschreibung gilt jedoch gleichermaßen für VFAT (Virtual File Allocation Table), Git und Cassandra (eine NoSQL-Datenbank). Was zeichnet also ein Dateisystem aus?
Grundlagen des Dateisystems
Der Linux-Kernel erfordert, dass eine Entität, die ein Dateisystem sein soll, auch open() implementieren muss , read() und write() Methoden für persistente Objekte, denen Namen zugeordnet sind. Aus Sicht der objektorientierten Programmierung behandelt der Kernel das generische Dateisystem als abstrakte Schnittstelle, und diese drei großen Funktionen sind „virtuell“ ohne Standarddefinition. Dementsprechend wird die standardmäßige Dateisystemimplementierung des Kernels als virtuelles Dateisystem (VFS) bezeichnet.
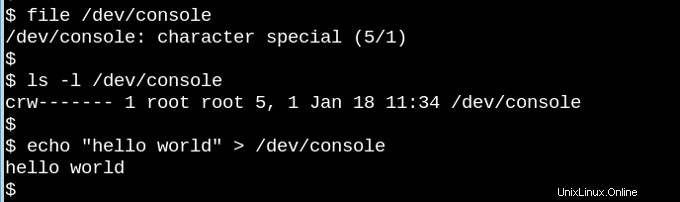
VFS liegt der berühmten Beobachtung zugrunde, dass in Unix-ähnlichen Systemen „alles eine Datei ist“. Überlegen Sie, wie seltsam es ist, dass die kleine Demo oben das Zeichengerät /dev/console enthält funktioniert tatsächlich. Das Bild zeigt eine interaktive Bash-Sitzung auf einem virtuellen Fernschreiber (tty). Durch das Senden einer Zeichenfolge an das virtuelle Konsolengerät wird diese auf dem virtuellen Bildschirm angezeigt. VFS hat andere, noch seltsamere Eigenschaften. Beispielsweise kann in ihnen gesucht werden.
Weitere Linux-Ressourcen
- Spickzettel für Linux-Befehle
- Spickzettel für fortgeschrittene Linux-Befehle
- Kostenloser Online-Kurs:RHEL Technical Overview
- Spickzettel für Linux-Netzwerke
- SELinux-Spickzettel
- Spickzettel für allgemeine Linux-Befehle
- Was sind Linux-Container?
- Unsere neuesten Linux-Artikel
Die vertrauten Dateisysteme wie ext4, NFS und /proc bieten alle Definitionen der drei großen Funktionen in einer C-Datenstruktur namens file_operations. Darüber hinaus erweitern und überschreiben bestimmte Dateisysteme die VFS-Funktionen auf die bekannte objektorientierte Weise. Wie Robert Love betont, ermöglicht die Abstraktion von VFS Linux-Benutzern, unbeschwert Dateien von und zu fremden Betriebssystemen oder abstrakten Entitäten wie Pipes zu kopieren, ohne sich Gedanken über ihr internes Datenformat machen zu müssen. Im Auftrag des Userspace kann ein Prozess über einen Systemaufruf mit der read()-Methode eines Dateisystems aus einer Datei in die Datenstrukturen des Kernels kopieren und dann die write()-Methode einer anderen Art von Dateisystem verwenden, um die Daten auszugeben.
Die Funktionsdefinitionen, die zum VFS-Basistyp selbst gehören, befinden sich in den fs/*.c-Dateien im Kernel-Quelltext, während die Unterverzeichnisse von fs/ die spezifischen Dateisysteme enthalten. Der Kernel enthält auch Dateisystem-ähnliche Einheiten wie cgroups, /dev und tmpfs, die früh im Boot-Prozess benötigt werden und daher im init/-Unterverzeichnis des Kernels definiert sind. Beachten Sie, dass cgroups, /dev und tmpfs nicht die drei großen Funktionen von file_operations aufrufen, sondern stattdessen direkt aus dem Speicher lesen und in ihn schreiben.
Das folgende Diagramm zeigt grob, wie Userspace auf verschiedene Arten von Dateisystemen zugreift, die üblicherweise auf Linux-Systemen bereitgestellt werden. Nicht dargestellt sind Konstrukte wie Pipes, dmesg und POSIX-Clocks, die ebenfalls struct file_operations implementieren und deren Zugriffe daher über die VFS-Schicht laufen.
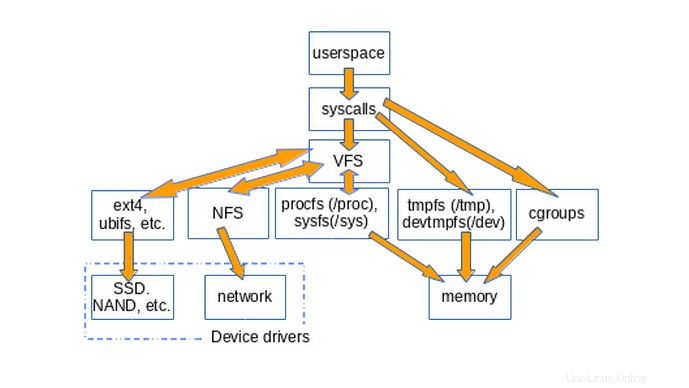
Die Existenz von VFS fördert die Wiederverwendung von Code, da die mit Dateisystemen verbundenen grundlegenden Methoden nicht von jedem Dateisystemtyp neu implementiert werden müssen. Die Wiederverwendung von Code ist eine weithin anerkannte bewährte Vorgehensweise im Software-Engineering! Leider, wenn der wiederverwendete Code schwerwiegende Fehler einführt, dann leiden alle Implementierungen, die die gemeinsamen Methoden erben, darunter.
/tmp:Ein einfacher Tipp
Ein einfacher Weg, um herauszufinden, welche VFSs auf einem System vorhanden sind, ist die Eingabe von mount | grep -v sd | grep -v :/ , das alle gemounteten Dateisysteme auflistet, die sich nicht auf einer Festplatte befinden und auf den meisten Computern nicht NFS sind. Einer der aufgelisteten VFS-Mounts wird sicherlich /tmp sein, richtig?

Warum ist es nicht ratsam, /tmp zu speichern? Weil die Dateien in /tmp temporär (!) sind und Speichergeräte langsamer sind als der Arbeitsspeicher, wo tmpfs erstellt werden. Außerdem unterliegen physikalische Geräte einem stärkeren Verschleiß durch häufiges Schreiben als Speicher. Schließlich können Dateien in /tmp vertrauliche Informationen enthalten, daher ist es ein Feature, dass sie bei jedem Neustart verschwinden.
Leider erstellen Installationsskripte für einige Linux-Distributionen standardmäßig immer noch /tmp auf einem Speichergerät. Verzweifeln Sie nicht, sollte dies bei Ihrem System der Fall sein. Befolgen Sie die einfachen Anweisungen im immer ausgezeichneten Arch-Wiki, um das Problem zu beheben, und denken Sie daran, dass der tmpfs zugewiesene Speicher nicht für andere Zwecke verfügbar ist. Mit anderen Worten, einem System mit einem gigantischen tmpfs mit großen Dateien kann der Arbeitsspeicher ausgehen und es kann abstürzen. Noch ein Tipp:Achten Sie beim Bearbeiten der Datei /etc/fstab darauf, diese mit einem Zeilenumbruch zu beenden, da Ihr System sonst nicht bootet. (Rate mal, woher ich das weiß.)
/proc und /sys
Neben /tmp sind die VFS, mit denen die meisten Linux-Benutzer am vertrautesten sind, /proc und /sys. (/dev ist auf Shared Memory angewiesen und hat keine file_operations). Warum zwei Geschmacksrichtungen? Sehen wir uns das genauer an.
Der procfs bietet einen Schnappschuss des momentanen Zustands des Kernels und der Prozesse, die er für den Userspace steuert. In /proc veröffentlicht der Kernel Informationen über die von ihm bereitgestellten Funktionen wie Interrupts, virtuellen Speicher und den Scheduler. Darüber hinaus ist /proc/sys der Ort, an dem die Einstellungen, die über den Befehl sysctl konfigurierbar sind, für den Benutzerbereich zugänglich sind. Status und Statistiken zu einzelnen Prozessen werden in /proc/
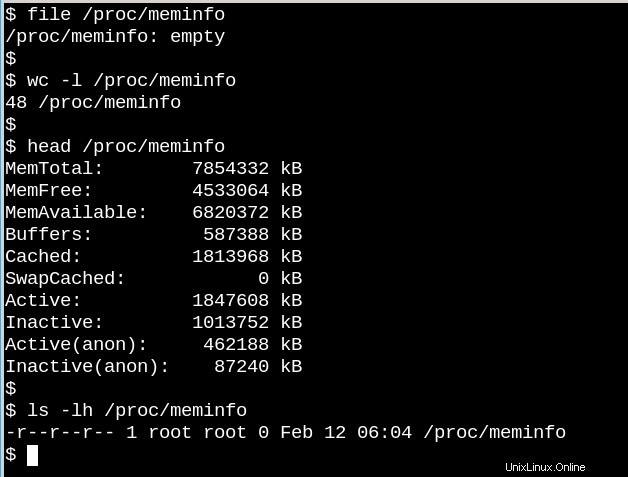
Das Verhalten von /proc-Dateien verdeutlicht, wie unterschiedlich Dateisysteme auf der Festplatte VFS sein können. Einerseits enthält /proc/meminfo die Informationen, die der Befehl free präsentiert . Andererseits ist es auch leer! Wie kann das sein? Die Situation erinnert an einen berühmten Artikel des Physikers N. David Mermin von der Cornell University aus dem Jahr 1985 mit dem Titel „Ist der Mond da, wenn niemand hinschaut? Realität und die Quantentheorie“. Die Wahrheit ist, dass der Kernel Statistiken über den Speicher sammelt, wenn ein Prozess sie von /proc anfordert, und das gibt es tatsächlich nichts in den Dateien in /proc, wenn niemand hinschaut. Wie Mermin sagte:„Es ist eine grundlegende Quantenlehre, dass eine Messung im Allgemeinen keinen bereits bestehenden Wert der gemessenen Eigenschaft offenbart.“ (Die Antwort auf die Frage nach dem Mond bleibt als Übung übrig.)

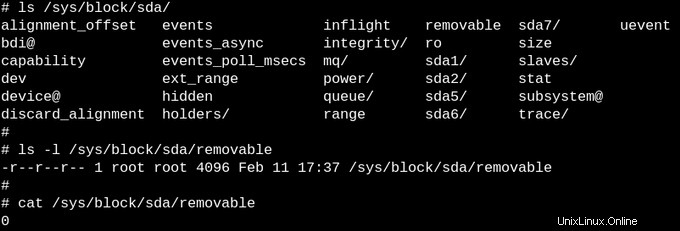
Die scheinbare Leere von procfs macht Sinn, da die dort verfügbaren Informationen dynamisch sind. Anders verhält es sich mit sysfs. Vergleichen wir, wie viele Dateien mit einer Größe von mindestens einem Byte in /proc im Vergleich zu /sys vorhanden sind.
Procfs hat genau eine, nämlich die exportierte Kernel-Konfiguration, was eine Ausnahme darstellt, da sie nur einmal pro Boot generiert werden muss. Auf der anderen Seite hat /sys viele größere Dateien, von denen die meisten eine Speicherseite umfassen. Typischerweise enthalten sysfs-Dateien genau eine Zahl oder einen String, im Gegensatz zu Informationstabellen, die durch das Lesen von Dateien wie /proc/meminfo.
erzeugt werdenDer Zweck von sysfs besteht darin, die lesbaren und beschreibbaren Eigenschaften dessen, was der Kernel "kobjects" nennt, dem Userspace zugänglich zu machen. Der einzige Zweck von Kobjects ist das Zählen von Referenzen:Wenn die letzte Referenz auf ein Kobject gelöscht wird, fordert das System die damit verbundenen Ressourcen zurück. Dennoch stellt /sys den größten Teil der berühmten „stabilen ABI zum Userspace“ des Kernels dar, die niemand jemals und unter keinen Umständen „brechen“ darf. Das bedeutet nicht, dass die Dateien in sysfs statisch sind, was der Referenzzählung flüchtiger Objekte widersprechen würde.
Die stabile ABI des Kernels schränkt stattdessen ein, was kann in /sys erscheinen, nicht das, was zu einem bestimmten Zeitpunkt tatsächlich vorhanden ist. Das Auflisten der Berechtigungen für Dateien in sysfs vermittelt eine Vorstellung davon, wie die konfigurierbaren, einstellbaren Parameter von Geräten, Modulen, Dateisystemen usw. gesetzt oder gelesen werden können. Die Logik erzwingt die Schlussfolgerung, dass procfs auch Teil der stabilen ABI des Kernels ist, obwohl die Dokumentation des Kernels dies nicht explizit angibt.
Snooping auf VFS mit eBPF- und bcc-Tools
Der einfachste Weg, um zu lernen, wie der Kernel sysfs-Dateien verwaltet, besteht darin, ihn in Aktion zu beobachten, und der einfachste Weg, auf ARM64 oder x86_64 zuzusehen, ist die Verwendung von eBPF. eBPF (Extended Berkeley Packet Filter) besteht aus einer virtuellen Maschine, die innerhalb des Kernels läuft und die privilegierte Benutzer über die Befehlszeile abfragen können. Die Kernelquelle teilt dem Leser mit, was der Kernel kann tun; Das Ausführen von eBPF-Tools auf einem gebooteten System zeigt stattdessen, was der Kernel tatsächlich macht .
Glücklicherweise ist der Einstieg in eBPF ziemlich einfach über die bcc-Tools, die als Pakete von großen Linux-Distributionen erhältlich sind und von Brendan Gregg ausführlich dokumentiert wurden. Die bcc-Tools sind Python-Skripte mit kleinen eingebetteten C-Schnipseln, was bedeutet, dass jeder, der mit einer der beiden Sprachen vertraut ist, sie leicht ändern kann. Bei dieser Zählung gibt es 80 Python-Skripte in bcc/tools, was es sehr wahrscheinlich macht, dass ein Systemadministrator oder Entwickler ein vorhandenes Skript findet, das für seine/ihre Bedürfnisse relevant ist.
Um eine sehr grobe Vorstellung davon zu bekommen, welche Arbeit VFSs auf einem laufenden System leisten, versuchen Sie es mit dem einfachen vfscount oder vfsstat, die zeigen, dass jede Sekunde Dutzende von Aufrufen an vfs_open() und seine Freunde erfolgen.
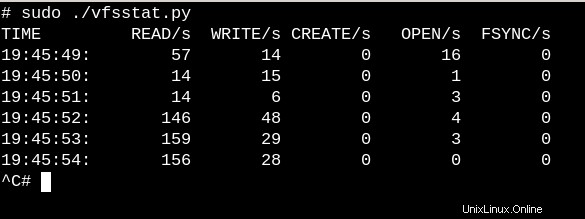
Sehen wir uns als weniger triviales Beispiel an, was in sysfs passiert, wenn ein USB-Stick in ein laufendes System eingesteckt wird.
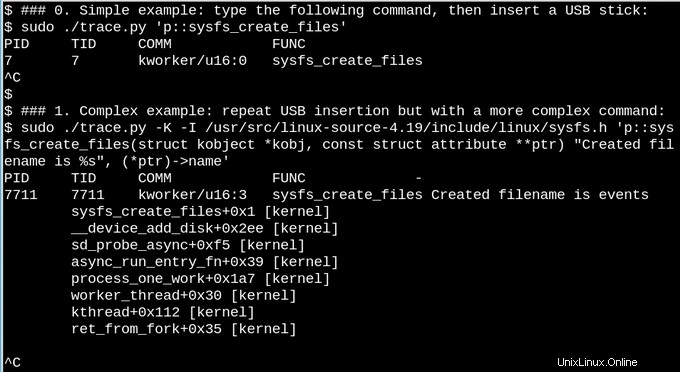
Im ersten einfachen Beispiel oben gibt das bcc-Tools-Skript „trace.py“ eine Meldung aus, wenn der Befehl „sysfs_create_files()“ ausgeführt wird. Wir sehen, dass sysfs_create_files() von einem kworker-Thread als Reaktion auf das Einstecken des USB-Sticks gestartet wurde, aber welche Datei wurde erstellt? Das zweite Beispiel veranschaulicht die volle Leistungsfähigkeit von eBPF. Hier gibt trace.py den Kernel-Backtrace (Option -K) plus den Namen der Datei aus, die von sysfs_create_files() erstellt wurde. Das Snippet in den einfachen Anführungszeichen ist C-Quellcode, einschließlich einer leicht erkennbaren Formatzeichenfolge, die das bereitgestellte Python-Skript dazu veranlasst, einen LLVM-Just-in-Time-Compiler zu kompilieren und innerhalb einer virtuellen Maschine im Kernel auszuführen. Die vollständige Signatur der Funktion sysfs_create_files() muss im zweiten Befehl wiedergegeben werden, damit der Formatstring auf einen der Parameter verweisen kann. Fehler in diesem C-Snippet führen zu erkennbaren C-Compiler-Fehlern. Wenn zum Beispiel das -I Wenn der Parameter weggelassen wird, lautet das Ergebnis „BPF-Text konnte nicht kompiliert werden“. Entwickler, die entweder mit C oder Python vertraut sind, werden feststellen, dass die bcc-Tools einfach zu erweitern und zu modifizieren sind.
Wenn der USB-Stick eingesteckt wird, erscheint der Kernel-Backtrace, der zeigt, dass PID 7711 ein kworker-Thread ist, der eine Datei namens „events“ in sysfs erstellt hat. Ein entsprechender Aufruf mit sysfs_remove_files() zeigt, dass das Entfernen des USB-Sticks ein Entfernen der Ereignisdatei zur Folge hat, ganz im Sinne der Referenzzählung. Das Beobachten von sysfs_create_link() mit eBPF während des Einsteckens des USB-Sticks (nicht gezeigt) zeigt, dass nicht weniger als 48 symbolische Links erstellt werden.
Was ist überhaupt der Zweck der Ereignisdatei? Die Verwendung von cscope zum Suchen der Funktion __device_add_disk() zeigt, dass sie disk_add_events() aufruft und entweder „media_change“ oder „eject_request“ in die Ereignisdatei geschrieben werden kann. Hier informiert die Blockschicht des Kernels den Userspace über das Erscheinen und Verschwinden der „Festplatte“. Überlegen Sie, wie informativ diese Methode zur Untersuchung der Funktionsweise des Einsteckens eines USB-Sticks im Vergleich zu dem Versuch ist, den Vorgang ausschließlich anhand der Quelle herauszufinden.
Nur-Lese-Root-Dateisysteme machen eingebettete Geräte möglich
Sicherlich fährt niemand einen Server oder ein Desktop-System herunter, indem er den Netzstecker zieht. Wieso den? Weil gemountete Dateisysteme auf den physischen Speichergeräten möglicherweise ausstehende Schreibvorgänge haben und die Datenstrukturen, die ihren Zustand aufzeichnen, möglicherweise nicht mehr mit dem synchron sind, was auf den Speicher geschrieben wird. In diesem Fall müssen Systembesitzer beim nächsten Booten warten, bis das Dateisystem-Wiederherstellungstool fsck ausgeführt wird, und im schlimmsten Fall verlieren sie sogar Daten.
Kenner werden jedoch gehört haben, dass viele IoT- und eingebettete Geräte wie Router, Thermostate und Autos jetzt Linux ausführen. Vielen dieser Geräte fehlt fast vollständig eine Benutzeroberfläche, und es gibt keine Möglichkeit, sie sauber zu "unbooten". Ziehen Sie in Betracht, ein Auto mit leerer Batterie zu starten, wenn die Stromversorgung der unter Linux laufenden Haupteinheit wiederholt auf und ab geht. Wie kommt es, dass das System ohne langes fsck bootet, wenn der Motor endlich anläuft? Die Antwort ist, dass eingebettete Geräte auf ein schreibgeschütztes Root-Dateisystem (kurz ro-rootfs) angewiesen sind.
Ein ro-rootfs bietet viele Vorteile, die weniger offensichtlich sind als die Unbestechlichkeit. Einer ist, dass Malware nicht in /usr oder /lib schreiben kann, wenn kein Linux-Prozess dort schreiben kann. Ein weiterer Grund ist, dass ein weitgehend unveränderliches Dateisystem für den Außendienst von Remote-Geräten entscheidend ist, da das Support-Personal über lokale Systeme verfügt, die nominell mit denen im Außendienst identisch sind. Der vielleicht wichtigste (aber auch subtilste) Vorteil ist, dass ro-rootfs Entwickler dazu zwingt, während der Entwurfsphase eines Projekts zu entscheiden, welche Systemobjekte unveränderlich sein sollen. Der Umgang mit ro-rootfs kann oft unbequem oder sogar schmerzhaft sein, wie es bei konstanten Variablen in Programmiersprachen oft der Fall ist, aber die Vorteile machen den zusätzlichen Overhead leicht wett.
Das Erstellen eines schreibgeschützten Rootfs erfordert einige zusätzliche Anstrengungen für Embedded-Entwickler, und hier kommt VFS ins Spiel. Linux benötigt Dateien in /var, um beschreibbar zu sein, und außerdem werden viele beliebte Anwendungen, die auf Embedded-Systemen ausgeführt werden, versuchen, eine Konfiguration zu erstellen dot-Dateien in $HOME. Eine Lösung für Konfigurationsdateien im Home-Verzeichnis besteht normalerweise darin, sie vorab zu generieren und in die rootfs zu integrieren. Für /var besteht ein Ansatz darin, es auf einer separaten beschreibbaren Partition einzuhängen, während / selbst als schreibgeschützt eingehängt wird. Die Verwendung von Bindungs- oder Overlay-Mounts ist eine weitere beliebte Alternative.
Bindungs- und Overlay-Mounts und ihre Verwendung durch Container
Laufen man mount ist der beste Ort, um mehr über Bind- und Overlay-Mounts zu erfahren, die Embedded-Entwicklern und Systemadministratoren die Möglichkeit geben, ein Dateisystem an einem Pfad zu erstellen und es dann Anwendungen an einem zweiten bereitzustellen. Für eingebettete Systeme bedeutet dies, dass es möglich ist, die Dateien in /var auf einem nicht beschreibbaren Flash-Gerät zu speichern, aber beim Booten einen Pfad in einem tmpfs auf den /var-Pfad zu überlagern oder einzubinden, damit Anwendungen dort nach Herzenslust kritzeln können Freude. Beim nächsten Einschalten sind die Änderungen in /var verschwunden. Overlay-Mounts stellen eine Vereinigung zwischen dem tmpfs und dem zugrunde liegenden Dateisystem bereit und ermöglichen scheinbare Änderungen an einer vorhandenen Datei in einem ro-rootfs, während bind-Mounts dazu führen können, dass neue leere tmpfs-Verzeichnisse als beschreibbar in ro-rootfs-Pfads angezeigt werden. Während overlayfs ein richtiger Dateisystemtyp ist, werden Bind-Mounts durch die VFS-Namespace-Einrichtung implementiert.
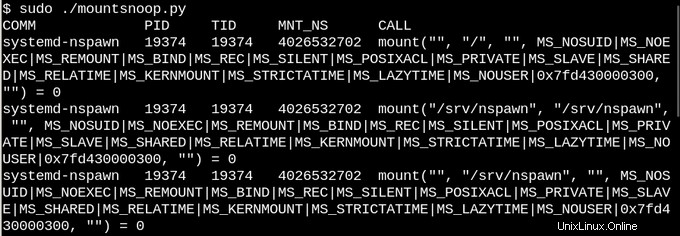
Basierend auf der Beschreibung von Overlay- und Bind-Mounts wird niemand überrascht sein, dass Linux-Container sie stark nutzen. Lassen Sie uns ausspionieren, was passiert, wenn wir systemd-nspawn verwenden, um einen Container zu starten, indem wir das mountsnoop-Tool von bcc ausführen:

Und mal sehen, was passiert ist:
Hier stellt systemd-nspawn dem Container ausgewählte Dateien in den procfs und sysfs des Hosts unter Pfaden in seinen rootfs zur Verfügung. Neben dem MS_BIND-Flag, das das Bind-Mounting setzt, bestimmen einige der anderen Flags, die der "mount"-Systemaufruf aufruft, die Beziehung zwischen Änderungen im Host-Namensraum und im Container. Zum Beispiel kann der Bind-Mount je nach Aufruf entweder Änderungen in /proc und /sys an den Container weitergeben oder sie verstecken.
Zusammenfassung
Das Verständnis von Linux-Interna kann eine unmögliche Aufgabe sein, da der Kernel selbst eine gigantische Menge an Code enthält, abgesehen von Linux-Userspace-Anwendungen und der Systemaufrufschnittstelle in C-Bibliotheken wie glibc. Eine Möglichkeit, Fortschritte zu erzielen, besteht darin, den Quellcode eines Kernel-Subsystems zu lesen, wobei der Schwerpunkt auf dem Verständnis der Systemaufrufe und -header für den Benutzerbereich sowie der wichtigsten internen Kernel-Schnittstellen liegt, die hier durch die Tabelle file_operations veranschaulicht werden. Die Dateioperationen sind das, was "Alles ist eine Datei" tatsächlich funktioniert, daher ist es besonders befriedigend, sie in den Griff zu bekommen. Die Kernel-C-Quelldateien im fs/-Verzeichnis der obersten Ebene stellen die Implementierung virtueller Dateisysteme dar, die die Shim-Schicht darstellen, die eine breite und relativ einfache Interoperabilität gängiger Dateisysteme und Speichergeräte ermöglicht. Bind- und Overlay-Mounts über Linux-Namespaces sind die VFS-Magie, die Container und schreibgeschützte Root-Dateisysteme möglich macht. In Kombination mit einer Untersuchung des Quellcodes machen die eBPF-Kernel-Funktion und ihre bcc-Schnittstelle das Untersuchen des Kernels einfacher als je zuvor.
Vielen Dank an Akkana Peck und Michael Eager für Kommentare und Korrekturen.
Alison Chaiken wird auf der 17. jährlichen Southern California Linux Expo (SCaLE 17x) vom 7. bis 10. März in Pasadena, Kalifornien virtuelle Dateisysteme vorstellen:Warum wir sie brauchen und wie sie funktionieren.