Wenn Sie Linux für die normale Arbeit oder die Entwicklung und Bereitstellung von Software verwenden, müssen Sie auf den grep-Befehl gestoßen sein.
In diesem erklärenden Artikel erkläre ich Ihnen, was der grep-Befehl ist und wie er funktioniert.
Was ist grep?
Grep ist ein Befehlszeilendienstprogramm in Unix- und Linux-Systemen. Es wird verwendet, um Suchmuster im Inhalt einer bestimmten Datei zu finden.
Mit seinem ungewöhnlichen Namen haben Sie vielleicht schon erraten, dass grep ein Akronym ist. Dies ist zumindest teilweise richtig, aber es hängt davon ab, wen Sie fragen.
Seriösen Quellen zufolge leitet sich der Name tatsächlich von einem Befehl in einem UNIX-Texteditor namens ed ab. Wobei die Eingabe g/re/p führte eine globale (g) Suche nach einem regulären Ausdruck (re) durch und gab anschließend alle übereinstimmenden Zeilen aus (p).
Der grep-Befehl macht das, was die g/re/p-Befehle im Editor gemacht haben. Es führt eine globale Suche nach einem regulären Ausdruck durch und gibt ihn aus. Es ist viel schneller beim Durchsuchen großer Dateien.

Dies ist die offizielle Erzählung, aber Sie können sie auch als G beschrieben sehen lobales R zB E Ausdruck (P Prozessor | P arser | P Drucker). Ehrlich gesagt tut es all das.
Die interessante Geschichte hinter der Erstellung von grep
Ken Thompson hat einige unglaubliche Beiträge zur Informatik geleistet. Er half bei der Entwicklung von Unix, machte seinen modularen Ansatz populär und schrieb viele seiner Programme, einschließlich grep.
Thompson hat grep entwickelt, um einen seiner Kollegen bei Bell Labs zu unterstützen. Das Ziel dieses Wissenschaftlers war es, sprachliche Muster zu untersuchen, um die Autoren (einschließlich Alexander Hamilton) der Federalist Papers zu identifizieren. Dieses umfangreiche Werk war eine Sammlung von 85 anonymen Artikeln und Essays, die zur Verteidigung der Verfassung der Vereinigten Staaten verfasst wurden. Da diese Artikel jedoch anonym waren, versuchte der Wissenschaftler, die Autoren anhand sprachlicher Muster zu identifizieren.
Der ursprüngliche Unix-Texteditor, ed, (ebenfalls von Thompson erstellt) war aufgrund der damaligen Hardwarebeschränkungen nicht in der Lage, eine so große Textmenge zu durchsuchen. Daher hat Thompson die Suchfunktion in ein eigenständiges Dienstprogramm umgewandelt, das unabhängig vom ed-Editor ist.
Wenn Sie darüber nachdenken, bedeutet das, dass Alexander Hamilton technisch bei der Erstellung von grep geholfen hat. Fühlen Sie sich frei, diese lustige Tatsache mit Ihren Freunden auf Ihrer Hamilton-Uhrenparty zu teilen. 🤓
Was ist noch mal ein regulärer Ausdruck?
Ein regulärer Ausdruck (oder Regex) kann man sich wie eine Suchanfrage vorstellen. Reguläre Ausdrücke werden verwendet, um Text zu identifizieren, abzugleichen oder anderweitig zu verwalten.
Regex kann jedoch viel mehr als eine Stichwortsuche. Es kann verwendet werden, um jede erdenkliche Art von Muster zu finden. Durch die Verwendung von Metazeichen können Muster leichter gefunden werden. Diese Sonderzeichen, die dieses Suchwerkzeug viel leistungsfähiger machen.

Es sollte beachtet werden, dass grep nur ein Werkzeug ist, das Regex verwendet. Es gibt ähnliche Funktionen in allen Tools, aber Metazeichen und Syntax können variieren. Das bedeutet, dass es wichtig ist, die Regeln für Ihren speziellen Regex-Prozessor zu kennen.
Ein praktisches Beispiel für grep:Abgleich von Telefonnummern
Dieses Tool kann sowohl für Neulinge als auch für erfahrene Linux-Benutzer einschüchternd sein. Leider kann selbst ein relativ einfaches Muster wie eine Telefonnummer zu einer "beängstigend" aussehenden Regex-Zeichenfolge führen.
Ich möchte Ihnen versichern, dass Sie nicht in Panik geraten müssen, wenn Sie solche Ausdrücke sehen. Sobald Sie sich mit den Grundlagen von Regex vertraut gemacht haben, kann dies eine neue Welt voller Möglichkeiten für Ihre Datenverarbeitung eröffnen.
Kultureller Hinweis :In diesem Beispiel werden US-Konventionen (NANP) für Telefonnummern verwendet. Dies sind 10-stellige IDs, die in eine Vorwahl (3 Ziffern) und eine eindeutige 7-stellige Kombination unterteilt sind, wobei die ersten 3 Ziffern einem zentralen Telekommunikationsbüro entsprechen (als Präfix bekannt) und die letzten 4 als Leitung bezeichnet werden Anzahl. Das Muster ist also AAA-PPP-LLLL.
Ich habe eine Datei namens phone.txt erstellt und 4 gängige Variationen derselben Telefonnummer aufgeschrieben. Ich werde grep verwenden, um das Zahlenmuster unabhängig vom Format zu erkennen.
Ich habe auch eine Zeile hinzugefügt, die nicht dem Ausdruck entspricht, der als Steuerelement verwendet werden soll. Die letzte Zeile 555!123!1234 ist kein standardmäßiges Telefonnummernmuster und wird nicht vom grep-Ausdruck zurückgegeben.
Inhalt von phone.txt Dateien sind:
example@unixlinux.online:~$ cat phone.txt
5551231234
555 123 1234
555-123-1234
(555)-123-1234
555!123!1234
Um die Telefonnummern zu "grep", werde ich meine Regex mit Metazeichen schreiben, um die relevanten Daten zu isolieren und zu ignorieren, was ich nicht brauche.
Der vollständige Befehl sieht folgendermaßen aus:
example@unixlinux.online:~$ grep '\(([0-9]\{3\})\|[0-9]\{3\}\)[ -]\?[0-9]\{3\}[ -]\?[0-9]\{4\}' phone.txt
Sieht ein bisschen heftig aus, oder? Lassen Sie es uns in Teile aufteilen, um eine bessere Vorstellung davon zu bekommen, was passiert.
Regex verstehen, ein Segment nach dem anderen
Trennen wir zunächst den Abschnitt der RegEx, der nach der „Vorwahl“ in der Telefonnummer sucht.
Ein ähnliches Muster wird teilweise wiederholt, um auch den Rest der Ziffern zu erhalten. Es ist wichtig zu beachten, dass die Vorwahl manchmal in Klammern eingeschlossen ist, also müssen Sie dies mit dem Ausdruck hier berücksichtigen.
Die Logik des gesamten Vorwahlabschnitts ist in einem Satz runder Klammern mit Escapezeichen gekapselt. Sie können sehen, dass mein Code mit \( beginnt und endet mit \) .
Wenn Sie die eckigen Klammern [0-9] verwenden , lassen Sie grep wissen, dass Sie nach einer Zahl zwischen 0 und 9 suchen. In ähnlicher Weise könnten Sie [a-z] verwenden Buchstaben des Alphabets entsprechen.
Die Zahl in den geschweiften Klammern {3\} , bedeutet, dass das Element in den eckigen Klammern genau dreimal gefunden wird.
Immer noch verwirrt? Lassen Sie sich nicht stressen. Sie werden dieses Beispiel auf verschiedene Weise betrachten, damit Sie sich sicher fühlen, weiter voranzukommen.
Lassen Sie uns versuchen, die Logik des Vorwahlabschnitts in Pseudocode zu betrachten. Ich habe jedes Segment des Ausdrucks isoliert.
Pseudocode des Area Code RegEx
- \(
- (3-stellige Zahl)
- |
- Dreistellige Zahl
- \)
Wenn Sie es so sehen, wird die Regex hoffentlich einfacher. Im Klartext sucht man nach 3-stelligen Zahlen. Jede Ziffer könnte 0-9 sein, und es kann oder geben darf nicht in Klammern um die Vorwahl stehen.
Dann gibt es da noch diesen seltsamen Teil am Ende unseres ersten Abschnitts.
- [ -]\?
Was bedeutet das? Der \? Symbol bedeutet "übereinstimmung mit null oder einem der vorangehenden Zeichen". Hier bezieht sich das auf das, was in unseren eckigen Klammern [ -] steht .
Mit anderen Worten, es kann einen Bindestrich geben oder auch nicht, der auf die Ziffern folgt.
Vorwahl
Lassen Sie uns nun denselben Block mit dem eigentlichen Code neu erstellen. Dann füge ich die anderen Teile des Ausdrucks hinzu.
- \(
- ([0-9]\{3\})
- |
- [0-9]\{3\}
- \)
- [ -]\?
Präfix
Um das Telefonnummernmuster zu vervollständigen, können Sie einfach einen Teil Ihres vorhandenen Codes neu verwenden.
[0-9]\{3\}[ -]\?
Sie müssen sich nicht um die Klammern kümmern, die das Präfix umgeben, aber Sie können immer noch einen - haben oder auch nicht zwischen dem Präfix und den Leitungsziffern der Telefonnummer.
Zeilennummern
Für den letzten Abschnitt der Telefonnummer müssen wir nicht nach anderen Zeichen suchen, aber Sie müssen den Ausdruck aktualisieren, um die zusätzliche Ziffer widerzuspiegeln.
[0-9]\{4\}
Das ist es. Stellen wir nun sicher, dass der Ausdruck in Anführungszeichen gesetzt wird, um unerwartetes Verhalten zu minimieren.
Hier ist noch einmal der vollständige Ausdruck
example@unixlinux.online:~$ grep '\(([0-9]\{3\})\|[0-9]\{3\}\)[ -]\?[0-9]\{3\}[ -]\?[0-9]\{4\}' phone.txt
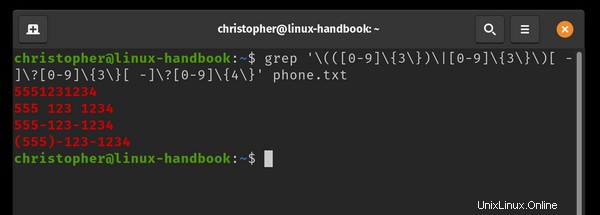
Sie sehen, dass die Ergebnisse farblich hervorgehoben sind. Dies ist möglicherweise nicht das Standardverhalten Ihrer Linux-Distribution.
Bonus-Tipp
Wenn Sie möchten, dass Ihre Ergebnisse hervorgehoben werden, können Sie --color=auto hinzufügen zu deinem Befehl. Sie könnten dies auch als Alias zu Ihrem Shell-Profil hinzufügen, sodass jedes Mal, wenn Sie grep eingeben es läuft als grep --color=auto .
Ich hoffe, Sie haben den grep-Befehl jetzt besser verstanden. Ich habe nur ein Beispiel gezeigt, um die Dinge zu erklären. Bei Interesse können Sie sich diesen Artikel mit weiteren praktischen Beispielen für den grep-Befehl ansehen.
Machen Sie Ihren Vorschlag zum Artikel, indem Sie einen Kommentar hinterlassen.