Einführung
Apache Storm und Spark sind Plattformen für Big-Data-Verarbeitung, die mit Echtzeit-Datenströmen arbeiten. Der Hauptunterschied zwischen den beiden Technologien liegt in der Art und Weise, wie sie mit der Datenverarbeitung umgehen. Storm parallelisiert Aufgabenberechnungen, während Spark Datenberechnungen parallelisiert. Es gibt jedoch andere grundlegende Unterschiede zwischen den APIs.
Dieser Artikel bietet einen ausführlichen Vergleich zwischen Apache Storm und Spark Streaming.

Storm vs. Spark:Definitionen
Apache-Sturm ist ein Echtzeit-Stream-Verarbeitungs-Framework. Der Dreizack Die Abstraktionsschicht bietet Storm eine alternative Schnittstelle, die Echtzeit-Analysevorgänge hinzufügt.
Andererseits Apache Spark ist ein allgemeines Analyse-Framework für große Datenmengen. Die Spark-Streaming-API steht neben anderen Analysetools innerhalb des Frameworks zum Streamen von Daten nahezu in Echtzeit zur Verfügung.
Storm vs. Spark:Vergleich
Sowohl Storm als auch Spark sind kostenlos nutzbare Open-Source-Apache-Projekte mit einer ähnlichen Absicht. In der folgenden Tabelle sind die Hauptunterschiede zwischen den beiden Technologien aufgeführt:
| Sturm | Spark | |
|---|---|---|
| Programmiersprachen | Mehrsprachige Integration | Unterstützung für Python, R, Java, Scala |
| Verarbeitungsmodell | Stream-Verarbeitung mit Micro-Batching verfügbar über Trident | Batch-Verarbeitung mit Micro-Batching verfügbar über Streaming |
| Primitive | Tuple-Stream Tuple-Batch Partition | DStream |
| Zuverlässigkeit | Genau einmal (Dreizack) Mindestens einmal Höchstens einmal | Genau einmal |
| Fehlertoleranz | Automatischer Neustart durch den Supervisor-Prozess | Worker-Neustart durch Ressourcenmanager |
| Staatsverwaltung | Unterstützt durch Trident | Unterstützt durch Streaming |
| Benutzerfreundlichkeit | Schwieriger zu bedienen und einzusetzen | Einfacher zu verwalten und bereitzustellen |
Programmiersprachen
Die Verfügbarkeit der Integration mit anderen Programmiersprachen ist einer der wichtigsten Faktoren bei der Wahl zwischen Storm und Spark und einer der Hauptunterschiede zwischen den beiden Technologien.
Sturm
Storm ist mehrsprachig Feature, wodurch es für praktisch jede Programmiersprache verfügbar ist. Die Trident-API für Streaming und Verarbeitung ist kompatibel mit:
- Java
- Clojure
- Skala
Funke
Spark bietet High-Level-Streaming-APIs für die folgenden Sprachen:
- Java
- Skala
- Python
Einige erweiterte Funktionen, wie z. B. Streaming aus benutzerdefinierten Quellen, sind für Python nicht verfügbar. Streaming von fortgeschrittenen externen Quellen wie Kafka oder Kinesis ist jedoch für alle drei Sprachen verfügbar.
Verarbeitungsmodell
Das Verarbeitungsmodell definiert, wie das Datenstreaming aktualisiert wird. Die Informationen werden auf eine der folgenden Arten verarbeitet:
- Jeweils ein Datensatz.
- In diskretisierten Stapeln.
Sturm
Das Verarbeitungsmodell von Core Storm arbeitet direkt mit Tupel-Streams, jeweils ein Datensatz , was es zu einer echten Echtzeit-Streaming-Technologie macht. Die Trident-API fügt die Option hinzu, Mikro-Batches zu verwenden .
Funke
Das Spark-Verarbeitungsmodell unterteilt Daten in Batches , Gruppieren der Datensätze vor der weiteren Verarbeitung. Die Spark Streaming API bietet die Möglichkeit, Daten in Mikro-Batches aufzuteilen .
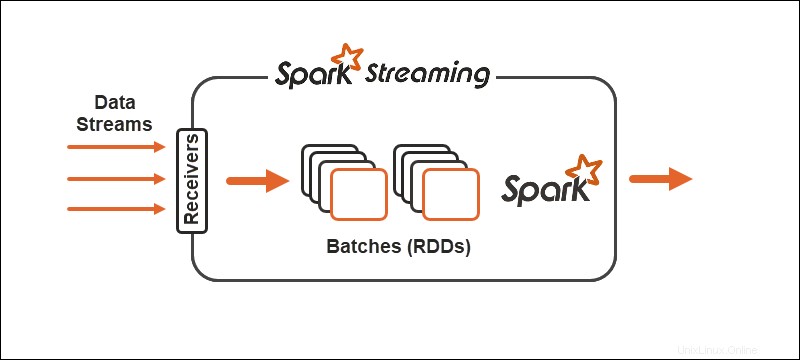
Primitive
Primitive stellen die Grundbausteine beider Technologien und die Art und Weise dar, wie Transformationsvorgänge an den Daten ausgeführt werden.
Sturm
Core Storm arbeitet mit Tuple-Streams , während Trident mit Tuple-Batches arbeitet und Partitionen . Die Trident-API arbeitet mit Sammlungen auf ähnliche Weise wie High-Level-Abstraktionen für Hadoop. Die Hauptelemente von Storm sind:
- Ausgüsse die einen Echtzeit-Stream aus einer Quelle generieren.
- Schrauben die Datenverarbeitung durchführen und Persistenz halten.
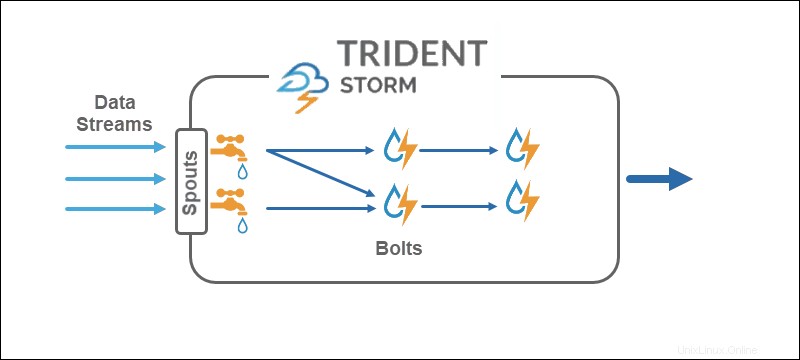
In der Trident-Topologie werden Operationen in Bolts gruppiert. Gruppieren nach, Joins, Aggregationen, Ausführungsfunktionen und Filter sind für isolierte Batches und über verschiedene Sammlungen hinweg verfügbar. Die Aggregation speichert dauerhaft im Arbeitsspeicher, unterstützt durch HDFS oder in einem anderen Speicher wie Cassandra.
Funke
Mit Spark Streaming teilt sich der kontinuierliche Datenstrom in diskretisierte Streams auf (DStreams), eine Folge von Resilient Distributed Databases (RDD).
Spark erlaubt zwei allgemeine Typen von Operatoren für Primitive:
1. Stream-Transformationsoperatoren wo ein DStream in einen anderen DStream umgewandelt wird.
2. Ausgabeoperatoren helfen, Informationen in externe Systeme zu schreiben.
Zuverlässigkeit
Zuverlässigkeit bezieht sich auf die Zusicherung der Datenlieferung. Es gibt drei Mögliche Garantien im Umgang mit der Zuverlässigkeit des Datenstreamings:
- Mindestens einmal . Daten werden einmal geliefert, wobei auch mehrere Lieferungen möglich sind.
- Höchstens einmal . Daten werden nur einmal geliefert, und alle Duplikate fallen weg. Es besteht die Möglichkeit, dass Daten nicht ankommen.
- Genau einmal . Daten werden einmal geliefert, ohne Verluste oder Duplikate. Die Garantieoption ist für Datenstreaming optimal, wenn auch schwer zu erreichen.
Sturm
Storm ist flexibel, wenn es um die Zuverlässigkeit des Datenstreamings geht. Im Kern mindestens einmal und höchstens einmal Optionen sind möglich. Zusammen mit der Trident-API sind alle drei Konfigurationen verfügbar .
Funke
Spark versucht, den optimalen Weg zu gehen, indem er sich auf das genau-einmal konzentriert Daten-Streaming-Konfiguration. Wenn ein Arbeiter oder Fahrer ausfällt, mindestens einmal Semantik gilt.
Fehlertoleranz
Die Fehlertoleranz definiert das Verhalten der Streaming-Technologien im Fehlerfall. Sowohl Spark als auch Storm sind auf ähnlichem Niveau fehlertolerant.
Funke
Im Falle eines Worker-Ausfalls startet Spark Worker über den Ressourcen-Manager wie YARN neu. Bei einem Treiberfehler wird ein Datenprüfpunkt für die Wiederherstellung verwendet.
Sturm
Wenn ein Prozess in Storm oder Trident fehlschlägt, übernimmt der überwachende Prozess den Neustart automatisch. ZooKeeper spielt eine entscheidende Rolle bei der Zustandswiederherstellung und -verwaltung.
Zustandsverwaltung
Sowohl Spark Streaming als auch Storm Trident verfügen über integrierte Zustandsverwaltungstechnologien. Die Verfolgung von Zuständen trägt zur Fehlertoleranz sowie zur einmaligen Liefergarantie bei.
Benutzerfreundlichkeit und Entwicklung
Benutzerfreundlichkeit und Entwicklung hängen davon ab, wie gut die Technologie dokumentiert ist und wie einfach es ist, die Streams zu bedienen.
Funke
Spark lässt sich einfacher bereitstellen und aus den beiden Technologien entwickeln. Streaming ist gut dokumentiert und wird auf Spark-Clustern bereitgestellt. Stream-Jobs sind mit Batch-Jobs austauschbar.
Sturm
Storm ist etwas schwieriger zu konfigurieren und zu entwickeln, da es eine Abhängigkeit vom ZooKeeper-Cluster enthält. Der Vorteil bei der Nutzung von Storm liegt in der Mehrsprachigkeit.
Storm vs. Spark:Wie wählt man?
Die Wahl zwischen Storm und Spark hängt vom Projekt sowie von den verfügbaren Technologien ab. Einer der Hauptfaktoren ist die Programmiersprache und die Garantien für die Zuverlässigkeit der Datenlieferung.
Obwohl es Unterschiede zwischen den beiden Datenströmen und -verarbeitungen gibt, besteht der beste Weg darin, beide Technologien zu testen, um zu sehen, was für Sie und den vorliegenden Datenstrom am besten funktioniert.