Einführung
Heute haben wir viele kostenlose Lösungen für die Big-Data-Verarbeitung. Viele Unternehmen bieten auch spezielle Unternehmensfunktionen an, um die Open-Source-Plattformen zu ergänzen.
Der Trend begann 1999 mit der Entwicklung von Apache Lucene. Das Framework wurde bald Open Source und führte zur Entwicklung von Hadoop. Zwei der beliebtesten Big Data-Verarbeitungsframeworks, die heute verwendet werden, sind Open Source – Apache Hadoop und Apache Spark.
Es stellt sich immer die Frage, welches Framework verwendet werden soll, Hadoop oder Spark.
In diesem Artikel lernen Sie die Hauptunterschiede zwischen Hadoop und Spark und wann Sie sich für das eine oder das andere entscheiden oder sie zusammen verwenden sollten.

Hinweis :Bevor wir in den direkten Vergleich zwischen Hadoop und Spark eintauchen, werfen wir einen kurzen Blick auf diese beiden Frameworks.
Was ist Hadoop?
Apache Hadoop ist eine Plattform, die große Datenmengen verteilt verarbeitet. Das Framework verwendet MapReduce um die Daten in Blöcke aufzuteilen und die Chunks Knoten in einem Cluster zuzuweisen. MapReduce verarbeitet die Daten dann parallel auf jedem Knoten, um eine eindeutige Ausgabe zu erzeugen.
Jede Maschine in einem Cluster speichert und verarbeitet Daten. Hadoop speichert die Daten mithilfe von HDFS auf Festplatten . Die Software bietet nahtlose Skalierbarkeitsoptionen. Sie können mit nur einem Computer beginnen und dann auf Tausende erweitern, indem Sie jede Art von Unternehmens- oder Standardhardware hinzufügen.
Das Hadoop-Ökosystem ist hochgradig fehlertolerant. Hadoop ist nicht auf Hardware angewiesen, um eine hohe Verfügbarkeit zu erreichen. Im Kern ist Hadoop darauf ausgelegt, auf der Anwendungsebene nach Fehlern zu suchen. Durch die Replikation von Daten über einen Cluster hinweg kann das Framework die fehlenden Teile von einem anderen Standort aus erstellen, wenn ein Hardwareteil ausfällt.
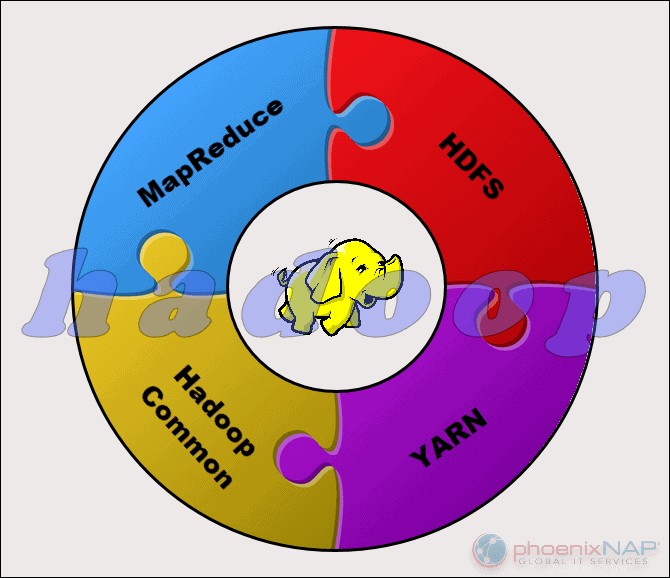
Das Apache Hadoop-Projekt besteht aus vier Hauptmodulen:
- HDFS – Verteiltes Hadoop-Dateisystem. Dies ist das Dateisystem, das die Speicherung großer Datensätze in einem Hadoop-Cluster verwaltet. HDFS kann sowohl strukturierte als auch unstrukturierte Daten verarbeiten. Die Speicherhardware kann von beliebigen HDDs für Verbraucher bis hin zu Laufwerken für Unternehmen reichen.
- MapReduce. Die Verarbeitungskomponente des Hadoop-Ökosystems. Es weist die Datenfragmente aus dem HDFS separaten Zuordnungsaufgaben im Cluster zu. MapReduce verarbeitet die Chunks parallel, um die Teile zum gewünschten Ergebnis zu kombinieren.
- GARN. Noch ein weiterer Verhandlungspartner für Ressourcen. Verantwortlich für die Verwaltung von Computerressourcen und die Auftragsplanung.
- Hadoop Common. Der Satz gemeinsamer Bibliotheken und Dienstprogramme, von denen andere Module abhängen. Ein anderer Name für dieses Modul ist Hadoop Core, da es Unterstützung für alle anderen Hadoop-Komponenten bereitstellt.
Die Natur von Hadoop macht es für jeden zugänglich, der es braucht. Die Open-Source-Community ist groß und hat den Weg zu einer barrierefreien Big-Data-Verarbeitung geebnet.
Was ist Spark?
Apache Spark ist ein Open-Source-Tool. Dieses Framework kann in einem eigenständigen Modus oder auf einem Cloud- oder Cluster-Manager wie Apache Mesos und anderen Plattformen ausgeführt werden. Es ist auf schnelle Leistung ausgelegt und verwendet RAM zum Zwischenspeichern und Verarbeiten von Daten.
Spark führt verschiedene Arten von Big-Data-Workloads aus. Dazu gehören MapReduce-ähnliche Stapelverarbeitung sowie Echtzeit-Stream-Verarbeitung, maschinelles Lernen, Diagrammberechnung und interaktive Abfragen. Mit benutzerfreundlichen High-Level-APIs kann Spark in viele verschiedene Bibliotheken integriert werden, einschließlich PyTorch und TensorFlow. Um den Unterschied zwischen diesen beiden Bibliotheken zu erfahren, lesen Sie unseren Artikel über PyTorch vs. TensorFlow.
Die Spark-Engine wurde entwickelt, um die Effizienz von MapReduce zu verbessern und seine Vorteile beizubehalten. Obwohl Spark kein eigenes Dateisystem hat, kann es auf Daten auf vielen verschiedenen Speicherlösungen zugreifen. Die von Spark verwendete Datenstruktur heißt Resilient Distributed Dataset , oder RDD.
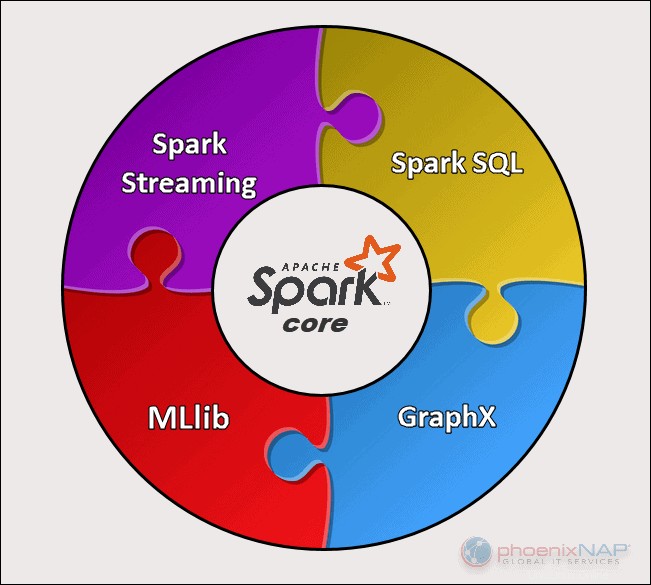
Es gibt fünf Hauptkomponenten von Apache Spark:
- Apache Spark Core . Die Basis des gesamten Projekts. Spark Core ist für notwendige Funktionen wie Scheduling, Task-Dispatching, Eingabe- und Ausgabeoperationen, Fehlerbehebung usw. verantwortlich. Andere Funktionalitäten bauen darauf auf.
- Spark-Streaming. Diese Komponente ermöglicht die Verarbeitung von Live-Datenströmen. Daten können aus vielen verschiedenen Quellen stammen, darunter Kafka, Kinesis, Flume usw.
- Spark-SQL . Spark verwendet diese Komponente, um Informationen über die strukturierten Daten und deren Verarbeitung zu sammeln.
- Machine Learning Library (MLlib) . Diese Bibliothek besteht aus vielen maschinellen Lernalgorithmen. Das Ziel von MLlib ist die Skalierbarkeit und die Zugänglichkeit des maschinellen Lernens.
- GraphX . Eine Reihe von APIs, die zur Erleichterung von Graphanalyseaufgaben verwendet werden.
Hauptunterschiede zwischen Hadoop und Spark
In den folgenden Abschnitten werden die wichtigsten Unterschiede und Gemeinsamkeiten zwischen den beiden Frameworks beschrieben. Wir werden Hadoop vs. Spark aus verschiedenen Blickwinkeln betrachten.
Einige davon sind Kosten , Leistung , Sicherheit , und Benutzerfreundlichkeit .
Die folgende Tabelle gibt einen Überblick über die Schlussfolgerungen der folgenden Abschnitte.
Hadoop- und Spark-Vergleich
| Kategorie für den Vergleich | Hadoop | Funke |
| Leistung | Langsamere Leistung, verwendet Festplatten zur Speicherung und hängt von der Lese- und Schreibgeschwindigkeit der Festplatte ab. | Schnelle In-Memory-Leistung mit reduzierten Lese- und Schreibvorgängen auf der Festplatte. |
| Kosten | Eine Open-Source-Plattform, die weniger teuer im Betrieb ist. Verwendet erschwingliche Consumer-Hardware. Es ist einfacher, ausgebildete Hadoop-Experten zu finden. | Eine Open-Source-Plattform, die jedoch zur Berechnung auf Speicher angewiesen ist, was die laufenden Kosten erheblich erhöht. |
| Datenverarbeitung | Am besten für Stapelverarbeitung. Verwendet MapReduce, um ein großes Dataset für parallele Analysen auf einen Cluster aufzuteilen. | Geeignet für iterative und Live-Stream-Datenanalyse. Funktioniert mit RDDs und DAGs, um Operationen auszuführen. |
| Fehlertoleranz | Ein hochgradig fehlertolerantes System. Repliziert die Daten über die Knoten hinweg und verwendet sie im Falle eines Problems. | Verfolgt den RDD-Blockerstellungsprozess und kann dann einen Datensatz neu erstellen, wenn eine Partition ausfällt. Spark kann auch einen DAG verwenden, um Daten über Knoten hinweg neu zu erstellen. |
| Skalierbarkeit | Leicht skalierbar durch Hinzufügen von Knoten und Festplatten für die Speicherung. Unterstützt Zehntausende von Knoten ohne bekanntes Limit. | Etwas schwieriger zu skalieren, da es für Berechnungen auf RAM angewiesen ist. Unterstützt Tausende von Knoten in einem Cluster. |
| Sicherheit | Extrem sicher. Unterstützt LDAP, ACLs, Kerberos, SLAs usw. | Nicht sicher. Standardmäßig ist die Sicherheit ausgeschaltet. Verlässt sich auf die Integration mit Hadoop, um das erforderliche Sicherheitsniveau zu erreichen. |
| Benutzerfreundlichkeit und Sprachunterstützung | Schwieriger zu verwenden mit weniger unterstützten Sprachen. Verwendet Java oder Python für MapReduce-Apps. | Benutzerfreundlicher. Ermöglicht den interaktiven Shell-Modus. APIs können in Java, Scala, R, Python, Spark SQL geschrieben werden. |
| Maschinelles Lernen | Langsamer als Spark. Datenfragmente können zu groß sein und Engpässe verursachen. Mahout ist die Hauptbibliothek. | Viel schneller mit In-Memory-Verarbeitung. Verwendet MLlib für Berechnungen. |
| Zeitplanung und Ressourcenverwaltung | Verwendet externe Lösungen. YARN ist die häufigste Option für die Ressourcenverwaltung. Oozie ist für die Arbeitsablaufplanung verfügbar. | Verfügt über integrierte Tools für die Ressourcenzuweisung, Planung und Überwachung. |
Leistung
Wenn wir uns Hadoop vs. Spark im Hinblick darauf ansehen, wie sie Daten verarbeiten , erscheint es vielleicht nicht selbstverständlich, die Leistung der beiden Frameworks zu vergleichen. Dennoch können wir eine Grenze ziehen und uns ein klares Bild davon machen, welches Tool schneller ist.
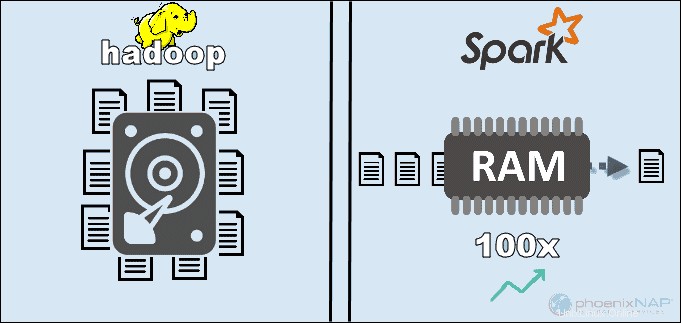
Durch den Zugriff auf die lokal auf HDFS gespeicherten Daten steigert Hadoop die Gesamtleistung. Es passt jedoch nicht zur In-Memory-Verarbeitung von Spark. Laut den Behauptungen von Apache scheint Spark bei der Verwendung von RAM für die Berechnung 100-mal schneller zu sein als Hadoop mit MapReduce.
Die Dominanz blieb beim Sortieren der Daten auf Disketten. Spark war dreimal schneller und benötigte zehnmal weniger Knoten, um 100 TB Daten auf HDFS zu verarbeiten. Diese Benchmark reichte aus, um 2014 den Weltrekord aufzustellen.
Der Hauptgrund für diese Vormachtstellung von Spark ist, dass es keine Zwischendaten auf Festplatten liest und schreibt, sondern RAM verwendet. Hadoop speichert Daten aus vielen verschiedenen Quellen und verarbeitet die Daten dann stapelweise mit MapReduce.
All dies kann Spark als absoluten Gewinner positionieren. Wenn die Datenmenge jedoch größer ist als der verfügbare Arbeitsspeicher, ist Hadoop die logischere Wahl. Ein weiterer zu berücksichtigender Punkt sind die Kosten für den Betrieb dieser Systeme.
Kosten
Vergleicht man Hadoop mit Spark unter Berücksichtigung der Kosten, müssen wir tiefer graben als nur den Preis der Software. Beide Plattformen sind Open Source und völlig kostenlos. Dennoch müssen die Infrastruktur-, Wartungs- und Entwicklungskosten berücksichtigt werden, um ungefähre Gesamtbetriebskosten (TCO) zu erhalten.
Der wichtigste Faktor in der Kostenkategorie ist die zugrunde liegende Hardware, die Sie zum Ausführen dieser Tools benötigen. Da Hadoop auf jede Art von Festplattenspeicher angewiesen ist für die Datenverarbeitung sind die Betriebskosten relativ gering.
Andererseits ist Spark von In-Memory-Berechnungen abhängig für Echtzeit-Datenverarbeitung. Das Hochfahren von Knoten mit viel RAM erhöht also die Betriebskosten erheblich.
Ein weiteres Anliegen ist die Anwendungsentwicklung. Hadoop gibt es schon länger als Spark und es ist weniger schwierig, Softwareentwickler zu finden.
Die obigen Punkte deuten darauf hin, dass die Hadoop-Infrastruktur kostengünstiger ist . Obwohl diese Aussage richtig ist, müssen wir daran erinnern, dass Spark Daten viel schneller verarbeitet. Daher ist eine geringere Anzahl von Maschinen erforderlich, um dieselbe Aufgabe auszuführen.
Datenverarbeitung
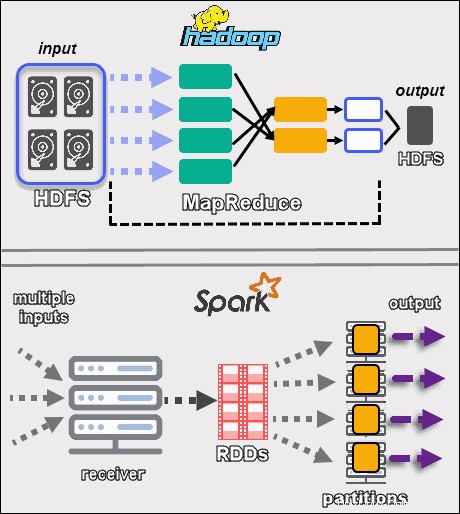
Die beiden Frameworks verarbeiten Daten auf ganz unterschiedliche Weise . Obwohl sowohl Hadoop mit MapReduce als auch Spark mit RDDs Daten in einer verteilten Umgebung verarbeiten, ist Hadoop besser für die Stapelverarbeitung geeignet. Im Gegensatz dazu glänzt Spark mit Echtzeitverarbeitung.
Das Ziel von Hadoop ist es, Daten auf Festplatten zu speichern und sie dann parallel in Stapeln in einer verteilten Umgebung zu analysieren. MapReduce benötigt nicht viel RAM, um große Datenmengen zu verarbeiten. Hadoop ist für die Speicherung auf alltägliche Hardware angewiesen und eignet sich am besten für die lineare Datenverarbeitung.
Apache Spark arbeitet mitstabilen verteilten Datensätzen (RDDs ). Ein RDD ist ein verteilter Satz von Elementen, die in Partitionen auf Knoten im gesamten Cluster gespeichert sind. Die Größe eines RDD ist normalerweise zu groß, um von einem Knoten verarbeitet zu werden. Daher partitioniert Spark die RDDs auf die nächstgelegenen Knoten und führt die Vorgänge parallel aus. Das System verfolgt alle auf einem RDD ausgeführten Aktionen mithilfe eines gerichteten azyklischen Graphen (DAG ).
Mit den In-Memory-Berechnungen und High-Level-APIs verarbeitet Spark effektiv Live-Streams unstrukturierter Daten. Darüber hinaus werden die Daten in einer vordefinierten Anzahl von Partitionen gespeichert. Ein Knoten kann beliebig viele Partitionen haben, aber eine Partition kann nicht auf einen anderen Knoten erweitert werden.
Fehlertoleranz
Apropos Hadoop vs. Spark in der Kategorie Fehlertoleranz:Wir können sagen, dass beide ein respektables Maß an Fehlerbehandlung bieten . Außerdem können wir sagen, dass die Herangehensweise an die Fehlertoleranz unterschiedlich ist.
Hadoop hat Fehlertoleranz als Grundlage seines Betriebs. Es repliziert Daten viele Male über die Knoten hinweg. Falls ein Problem auftritt, nimmt das System die Arbeit wieder auf, indem es die fehlenden Blöcke von anderen Standorten erstellt. Die Master-Knoten verfolgen den Status aller Slave-Knoten. Wenn schließlich ein Slave-Knoten nicht auf Pings von einem Master antwortet, weist der Master die ausstehenden Jobs einem anderen Slave-Knoten zu.
Spark verwendet RDD-Blöcke, um Fehlertoleranz zu erreichen. Das System verfolgt, wie der unveränderliche Datensatz erstellt wird. Dann kann es den Prozess neu starten, wenn es ein Problem gibt. Spark kann Daten in einem Cluster mithilfe der DAG-Verfolgung der Workflows neu erstellen. Diese Datenstruktur ermöglicht es Spark, Fehler in einem Ökosystem mit verteilter Datenverarbeitung zu behandeln.
Skalierbarkeit
Die Grenze zwischen Hadoop und Spark verschwimmt in diesem Abschnitt. Hadoop verwendet HDFS, um mit Big Data umzugehen. Wenn das Datenvolumen schnell wächst, kann Hadoop schnell skalieren, um der Nachfrage gerecht zu werden. Da Spark kein eigenes Dateisystem hat, muss es sich auf HDFS verlassen, wenn die Datenmenge zu groß ist, um sie zu verarbeiten.
Die Cluster können einfach erweitert und die Rechenleistung erhöht werden, indem weitere Server zum Netzwerk hinzugefügt werden. Infolgedessen kann die Anzahl der Knoten in beiden Frameworks Tausende erreichen. Es gibt keine feste Begrenzung dafür, wie viele Server Sie zu jedem Cluster hinzufügen und wie viele Daten Sie verarbeiten können.
Einige der bestätigten Zahlen beinhalten 8000 Maschinen in einer Spark-Umgebung mit Petabyte an Daten. Wenn man von Hadoop-Clustern spricht, sind sie dafür bekannt, Zehntausende von Maschinen zu beherbergen und fast ein Exabyte an Daten.
Benutzerfreundlichkeit und Programmiersprachenunterstützung
Spark ist vielleicht das neuere Framework mit nicht so vielen verfügbaren Experten wie Hadoop, ist aber bekanntermaßen benutzerfreundlicher. Im Gegensatz dazu bietet Spark Unterstützung für mehrere Sprachen neben der Muttersprache (Scala):Java, Python, R und Spark SQL. Dadurch können Entwickler die von ihnen bevorzugte Programmiersprache verwenden.
Das Hadoop-Framework basiert auf Java . Die beiden Hauptsprachen zum Schreiben von MapReduce-Code sind Java oder Python. Hadoop hat keinen interaktiven Modus, um Benutzern zu helfen. Es lässt sich jedoch in Pig- und Hive-Tools integrieren, um das Schreiben komplexer MapReduce-Programme zu erleichtern.
Neben der Unterstützung für APIs in mehreren Sprachen gewinnt Spark im Bereich Benutzerfreundlichkeit mit seinem interaktiven Modus. Sie können die Spark-Shell verwenden, um Daten interaktiv mit Scala oder Python zu analysieren. Die Shell bietet sofortiges Feedback zu Abfragen, wodurch Spark einfacher zu verwenden ist als Hadoop MapReduce.
Eine andere Sache, die Spark die Oberhand gibt, ist, dass Programmierer gegebenenfalls vorhandenen Code wiederverwenden können. Auf diese Weise können Entwickler die Anwendungsentwicklungszeit verkürzen. Historische und Stream-Daten können kombiniert werden, um diesen Prozess noch effektiver zu machen.
Sicherheit
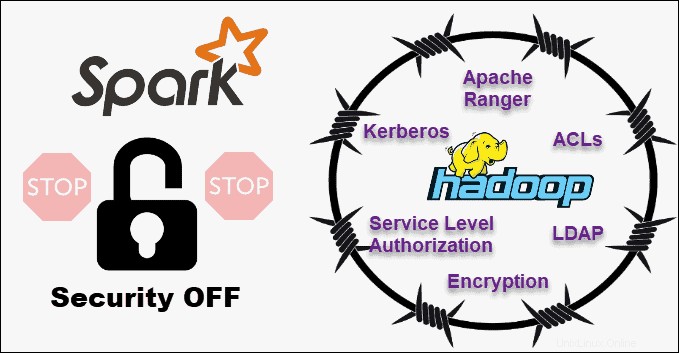
Beim Vergleich von Hadoop- und Spark-Sicherheit lassen wir gleich die Katze aus dem Sack – Hadoop ist der klare Sieger . Vor allem ist die Sicherheit von Spark standardmäßig deaktiviert. Das bedeutet, dass Ihr Setup ungeschützt ist, wenn Sie dieses Problem nicht angehen.
Sie können die Sicherheit von Spark verbessern, indem Sie die Authentifizierung über Shared Secret oder Ereignisprotokollierung einführen. Für Produktions-Workloads reicht das jedoch nicht aus.
Im Gegensatz dazu arbeitet Hadoop mit mehreren Authentifizierungs- und Zugriffskontrollmethoden. Am schwierigsten zu implementieren ist die Kerberos-Authentifizierung. Wenn Kerberos zu viel ist, unterstützt Hadoop auch Ranger , LDAP , ACLs , Verschlüsselung zwischen Knoten , Standard-Dateiberechtigungen auf HDFS und Autorisierung auf Serviceebene .
Spark kann jedoch durch die Integration mit Hadoop ein angemessenes Sicherheitsniveau erreichen . Auf diese Weise kann Spark alle Methoden verwenden, die Hadoop und HDFS zur Verfügung stehen. Wenn Spark auf YARN ausgeführt wird, können Sie außerdem die Vorteile anderer oben erwähnter Authentifizierungsmethoden nutzen.
Maschinelles Lernen
Maschinelles Lernen ist ein iterativer Prozess, der am besten mit In-Memory-Computing funktioniert. Aus diesem Grund hat sich Spark als schnellere Lösung erwiesen in diesem Bereich.
Der Grund dafür ist, dass Hadoop MapReduce Jobs in parallele Aufgaben aufteilt, die für maschinelle Lernalgorithmen möglicherweise zu groß sind. Dieser Prozess führt zu E/A-Leistungsproblemen in diesen Hadoop-Anwendungen.
Die Mahout-Bibliothek ist die wichtigste Plattform für maschinelles Lernen in Hadoop-Clustern. Mahout verlässt sich auf MapReduce, um Clustering, Klassifizierung und Empfehlung durchzuführen. Samsara hat begonnen, dieses Projekt zu ersetzen.
Spark wird mit einer Standardbibliothek für maschinelles Lernen, MLlib, geliefert. Diese Bibliothek führt iterative In-Memory-ML-Berechnungen durch. Es enthält Tools zur Durchführung von Regression, Klassifizierung, Persistenz, Pipeline-Konstruktion, Bewertung und vielem mehr.
Spark mit MLlib erwies sich in einer festplattenbasierten Hadoop-Umgebung als neunmal schneller als Apache Mahout. Wenn Sie effizientere Ergebnisse als das, was Hadoop bietet, benötigen, ist Spark die bessere Wahl für maschinelles Lernen.
Zeitplanung und Ressourcenverwaltung
Hadoop hat keinen eingebauten Planer. Es verwendet externe Lösungen für das Ressourcenmanagement und die Terminplanung. Mit RessourcenManager und NodeManager , YARN ist für die Ressourcenverwaltung in einem Hadoop-Cluster verantwortlich. Eines der verfügbaren Tools zum Planen von Workflows ist Oozie.
YARN befasst sich nicht mit der Zustandsverwaltung einzelner Anwendungen. Es weist nur verfügbare Rechenleistung zu.
Hadoop MapReduce funktioniert mit Plug-ins wie CapacityScheduler und FairScheduler . Diese Scheduler stellen sicher, dass Anwendungen die erforderlichen Ressourcen nach Bedarf erhalten, während die Effizienz eines Clusters erhalten bleibt. Der FairScheduler gibt den Anwendungen die erforderlichen Ressourcen und behält dabei im Auge, dass am Ende alle Anwendungen die gleiche Ressourcenzuteilung erhalten.
Spark hingegen hat diese Funktionen eingebaut. Der DAG-Scheduler ist für die Aufteilung der Operatoren in Phasen verantwortlich. Jede Phase hat mehrere Aufgaben, die DAG plant und Spark ausführen muss.
Spark Scheduler und Block Manager führen Job- und Aufgabenplanung, Überwachung und Ressourcenverteilung in einem Cluster durch.
Anwendungsfälle von Hadoop im Vergleich zu Spark
Wenn wir Hadoop im Vergleich zu Spark in den oben aufgeführten Abschnitten betrachten, können wir einige Anwendungsfälle für jedes Framework extrahieren.
Hadoop-Anwendungsfälle umfassen:
- Verarbeitung großer Datensätze in Umgebungen, in denen die Datengröße den verfügbaren Speicher übersteigt.
- Aufbau einer Datenanalyseinfrastruktur mit begrenztem Budget.
- Abschluss von Aufträgen, bei denen keine sofortigen Ergebnisse erforderlich sind und Zeit kein limitierender Faktor ist.
- Stapelverarbeitung mit Aufgaben, die Lese- und Schreibvorgänge auf der Festplatte ausnutzen.
- Analyse historischer und archivierter Daten.
Mit Spark können wir die folgenden Anwendungsfälle trennen, in denen es Hadoop übertrifft:
- Die Analyse von Echtzeit-Stream-Daten.
- Wenn es auf die Zeit ankommt, liefert Spark schnelle Ergebnisse mit In-Memory-Berechnungen.
- Umgang mit den Ketten paralleler Operationen unter Verwendung iterativer Algorithmen.
- Graph-parallele Verarbeitung zur Modellierung der Daten.
- Alle Anwendungen für maschinelles Lernen.
Hinweis :Wenn Sie Ihre Entscheidung getroffen haben, können Sie unserem Leitfaden zur Installation von Hadoop auf Ubuntu oder zur Installation von Spark auf Ubuntu folgen. Wenn Sie mit Windows 10 arbeiten, lesen Sie How to Install Spark on Windows 10.
Hadoop oder Spark?
Hadoop und Spark sind Technologien für den Umgang mit Big Data. Abgesehen davon sind sie ziemlich unterschiedliche Frameworks in der Art und Weise, wie sie Daten verwalten und verarbeiten.
Gemäß den vorherigen Abschnitten in diesem Artikel scheint Spark der klare Gewinner zu sein. Auch wenn dies bis zu einem gewissen Grad zutreffen mag, sind sie in Wirklichkeit nicht dazu geschaffen, miteinander zu konkurrieren, sondern sich zu ergänzen.
Natürlich gibt es Anwendungsfälle, bei denen das eine oder andere Framework die logischere Wahl ist, wie wir bereits weiter oben in diesem Artikel aufgeführt haben. In den meisten anderen Anwendungen arbeiten Hadoop und Spark am besten zusammen . Als Nachfolger ist Spark nicht hier, um Hadoop zu ersetzen, sondern um seine Funktionen zu nutzen, um ein neues, verbessertes Ökosystem zu schaffen.
Durch die Kombination der beiden kann Spark die fehlenden Funktionen nutzen, z. B. ein Dateisystem. Hadoop speichert eine riesige Datenmenge mit erschwinglicher Hardware und führt später Analysen durch, während Spark Echtzeitverarbeitung zur Verarbeitung eingehender Daten bietet. Ohne Hadoop könnten Geschäftsanwendungen wichtige historische Daten verpassen, die Spark nicht verarbeitet.
In dieser kooperativen Umgebung nutzt Spark auch die Sicherheits- und Ressourcenverwaltungsvorteile von Hadoop. Mit YARN sind Spark-Clustering und Datenverwaltung viel einfacher. Sie können Spark-Workloads automatisch mit allen verfügbaren Ressourcen ausführen.
Diese Zusammenarbeit liefert die besten Ergebnisse bei der rückwirkenden Analyse von Transaktionsdaten, erweiterten Analysen und der IoT-Datenverarbeitung. Alle diese Anwendungsfälle sind in einer Umgebung möglich.
Die Entwickler von Hadoop und Spark wollten die beiden Plattformen kompatibel machen und optimale Ergebnisse erzielen passend für alle geschäftlichen Anforderungen.