Einführung
Apache Hadoop ist ein außergewöhnlich erfolgreiches Framework, das es schafft, die vielen Herausforderungen von Big Data zu lösen. Diese effiziente Lösung verteilt Speicher- und Verarbeitungsleistung auf Tausende von Knoten innerhalb eines Clusters. Eine vollständig entwickelte Hadoop-Plattform umfasst eine Sammlung von Tools, die das zentrale Hadoop-Framework verbessern und es ihm ermöglichen, alle Hindernisse zu überwinden.
Die zugrunde liegende Architektur und die Rolle der vielen verfügbaren Tools in einem Hadoop-Ökosystem können sich für Neueinsteiger als kompliziert erweisen.
Dieser Artikel verwendet zahlreiche Diagramme und einfache Beschreibungen, um Ihnen dabei zu helfen, das aufregende Ökosystem von Apache Hadoop zu erkunden.

Überblick über die Hadoop-Architektur
Big Data mit seinem immensen Volumen und seinen unterschiedlichen Datenstrukturen hat traditionelle Netzwerk-Frameworks und -Tools überwältigt. Die Verwendung von Hochleistungshardware und spezialisierten Servern kann helfen, aber sie sind unflexibel und mit einem beträchtlichen Preisschild verbunden.
Hadoop schafft es, riesige Datenmengen zu verarbeiten und zu speichern, indem es miteinander verbundene, erschwingliche Standardhardware verwendet. Hunderte oder sogar Tausende von kostengünstigen dedizierten Servern, die zusammenarbeiten, um Daten innerhalb eines einzigen Ökosystems zu speichern und zu verarbeiten.
Das Hadoop Distributed File System (HDFS), YARN und MapReduce sind das Herzstück dieses Ökosystems. HDFS ist eine Reihe von Protokollen, die zum Speichern großer Datenmengen verwendet werden, während MapReduce die eingehenden Daten effizient verarbeitet.
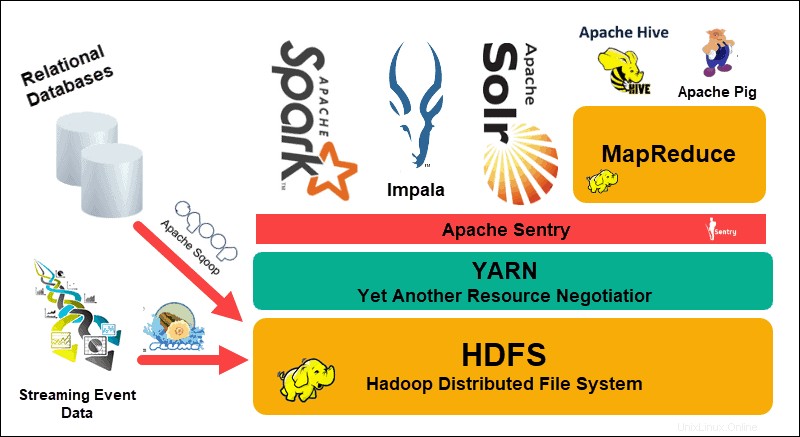
Ein Hadoop-Cluster besteht aus einem oder mehreren Master-Knoten und vielen weiteren sogenannten Slave-Knoten. HDFS und MapReduce bilden eine flexible Grundlage, die durch Hinzufügen zusätzlicher Knoten linear skaliert werden kann. Die Komplexität von Big Data bedeutet jedoch, dass es immer Raum für Verbesserungen gibt.
Yet Another Resource Negotiator (YARN) wurde erstellt, um die Ressourcenverwaltung und Planungsprozesse in einem Hadoop-Cluster zu verbessern. Die Einführung von YARN mit seiner generischen Schnittstelle öffnete die Tür für andere Datenverarbeitungstools, die in das Hadoop-Ökosystem integriert werden sollten.
Eine lebendige Entwicklergemeinschaft hat seitdem zahlreiche Open-Source-Apache-Projekte zur Ergänzung von Hadoop erstellt. Viele dieser Lösungen haben einprägsame und kreative Namen wie Apache Hive, Impala, Pig, Sqoop, Spark und Flume. Diese Tools erfassen und verarbeiten verschiedene Datentypen. Sie bieten außerdem benutzerfreundliche Schnittstellen, Messaging-Dienste und verbessern die Cluster-Verarbeitungsgeschwindigkeit.
Ein erweiterter Software-Stack mit HDFS, YARN und MapReduce im Kern macht Hadoop zur idealen Lösung für die Verarbeitung von Big Data.
Die Ebenen der Hadoop-Architektur verstehen
Die Aufteilung der Elemente verteilter Systeme in funktionale Schichten trägt zur Rationalisierung der Datenverwaltung und -entwicklung bei. Entwickler können an Frameworks arbeiten, ohne andere Prozesse im breiteren Ökosystem negativ zu beeinflussen.
Hadoop kann in vier (4) verschiedene Schichten unterteilt werden.
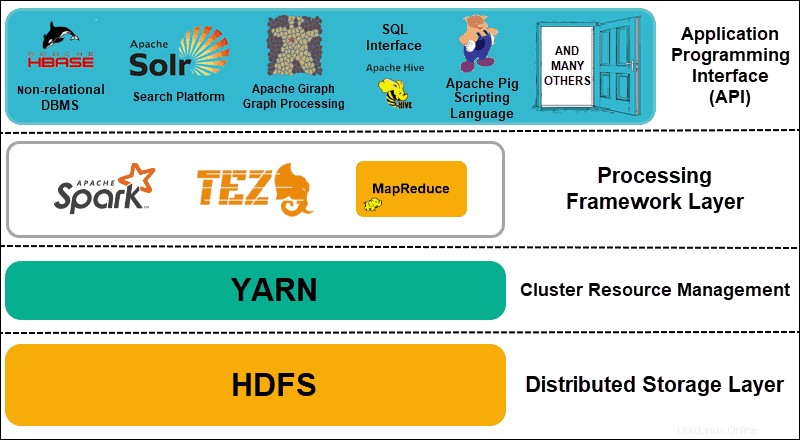
1. Verteilte Speicherschicht
Jeder Knoten in einem Hadoop-Cluster hat seinen eigenen Speicherplatz, Arbeitsspeicher, Bandbreite und Verarbeitung. Die eingehenden Daten werden in einzelne Datenblöcke aufgeteilt, die dann in der verteilten HDFS-Speicherschicht gespeichert werden. HDFS geht davon aus, dass jedes Festplattenlaufwerk und jeder Slave-Knoten innerhalb des Clusters unzuverlässig ist. Als Vorsichtsmaßnahme speichert HDFS drei Kopien jedes Datensatzes im gesamten Cluster. Der HDFS-Masterknoten (NameNode ) speichert die Metadaten für den einzelnen Datenblock und alle seine Kopien.
2. Cluster-Ressourcenverwaltung
Hadoop muss Knoten perfekt koordinieren, damit unzählige Anwendungen und Benutzer ihre Ressourcen effektiv teilen. Zunächst übernahm MapReduce sowohl das Ressourcenmanagement als auch die Datenverarbeitung. YARN trennt diese beiden Funktionen. Als De-facto-Ressourcenverwaltungstool für Hadoop ist YARN nun in der Lage, Ressourcen verschiedenen Frameworks zuzuweisen, die für Hadoop geschrieben wurden. Dazu gehören Projekte wie Apache Pig, Hive, Giraph, Zookeeper sowie MapReduce selbst.
3. Verarbeitungs-Framework-Schicht
Die Verarbeitungsschicht besteht aus Frameworks, die in den Cluster eingehende Datensätze analysieren und verarbeiten. Die strukturierten und unstrukturierten Datensätze werden abgebildet, gemischt, sortiert, zusammengeführt und in kleinere handhabbare Datenblöcke reduziert. Diese Vorgänge werden auf mehrere Knoten so nah wie möglich an den Servern verteilt, auf denen sich die Daten befinden. Berechnungs-Frameworks wie Spark, Storm, Tez ermöglichen jetzt Echtzeitverarbeitung, interaktive Abfrageverarbeitung und andere Programmieroptionen, die der MapReduce-Engine helfen und HDFS viel effizienter nutzen.
4. Anwendungsprogrammierschnittstelle
Die Einführung von YARN in Hadoop 2 hat zur Schaffung neuer Verarbeitungs-Frameworks und APIs geführt. Big Data breitet sich weiter aus und die Vielfalt der Tools muss diesem Wachstum folgen. Projekte, die sich auf Suchplattformen, Datenstreaming, benutzerfreundliche Schnittstellen, Programmiersprachen, Messaging, Failover und Sicherheit konzentrieren, sind allesamt ein komplexer Bestandteil eines umfassenden Hadoop-Ökosystems.
HDFS erklärt
Das Hadoop Distributed File System (HDFS) ist von Natur aus fehlertolerant. Daten werden in einzelnen Datenblöcken in drei separaten Kopien über mehrere Knoten und Server-Racks hinweg gespeichert. Wenn ein Knoten oder sogar ein ganzes Rack ausfällt, sind die Auswirkungen auf das Gesamtsystem vernachlässigbar.
Datenknoten Datenblöcke verarbeiten und speichern, während NameNodes Verwalten Sie die vielen DataNodes, verwalten Sie Datenblock-Metadaten und steuern Sie den Client-Zugriff.
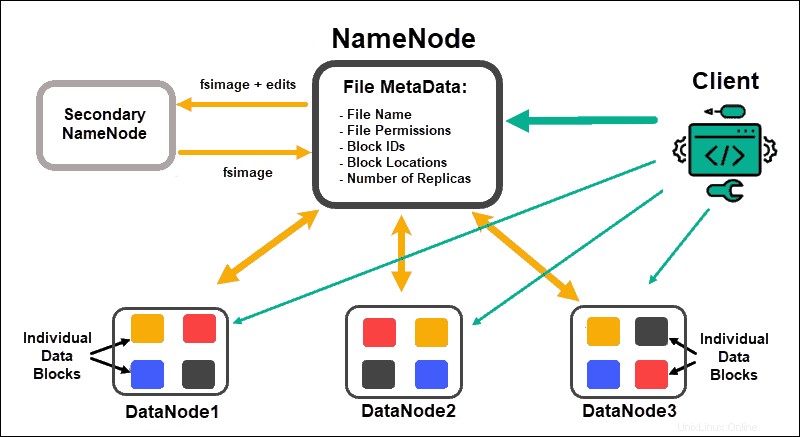
NameNode
Zunächst werden Daten in abstrakte Datenblöcke zerlegt. Die Dateimetadaten für diese Blöcke, die den Dateinamen, Dateiberechtigungen, IDs, Speicherorte und die Anzahl der Replikate enthalten, werden in einem fsimage im lokalen Speicher von NameNode gespeichert.
Sollte ein NameNode ausfallen, wäre HDFS nicht in der Lage, einen der Datensätze zu finden, die über die DataNodes verteilt sind. Dadurch wird der NameNode zum Single Point of Failure für den gesamten Cluster. Diese Schwachstelle wird durch die Implementierung eines Secondary NameNode oder eines Standby NameNode behoben.
Sekundärer Namensknoten
Der Secondary NameNode diente in frühen Hadoop-Versionen als primäre Backup-Lösung. Der sekundäre NameNode lädt von Zeit zu Zeit die aktuelle fsimage-Instanz herunter und bearbeitet Protokolle vom NameNode und führt sie zusammen. Das bearbeitete fsimage kann dann abgerufen und im primären NameNode wiederhergestellt werden.
Das Failover ist kein automatisierter Prozess, da ein Administrator die Daten vom sekundären NameNode manuell wiederherstellen müsste.
Standby-NameNode
Die Hochverfügbarkeit Die Funktion wurde in Hadoop 2.0 und nachfolgenden Versionen eingeführt, um Ausfallzeiten im Falle eines NameNode-Fehlers zu vermeiden. Mit dieser Funktion können Sie zwei NameNodes verwalten, die auf separaten dedizierten Master-Knoten laufen.
Der Standby-NameNode ist ein automatisiertes Failover, falls ein aktiver NameNode nicht mehr verfügbar ist. Der Standby-NameNode führt zusätzlich den Check-Pointing-Prozess durch. Aufgrund dieser Eigenschaft sind der sekundäre und der Standby-NameNode nicht kompatibel. Ein Hadoop-Cluster kann entweder das eine oder das andere verwalten.
Tierpfleger
Zookeeper ist ein leichtes Tool, das Hochverfügbarkeit und Redundanz unterstützt. Ein Standby-NameNode hält eine aktive Sitzung mit dem Zookeeper-Daemon aufrecht.
Wenn ein aktiver NameNode ins Stocken gerät, erkennt der Zookeeper-Daemon den Fehler und führt den Failover-Prozess zu einem neuen NameNode durch. Verwenden Sie Zookeeper, um Failover zu automatisieren und die Auswirkungen zu minimieren, die ein NameNode-Ausfall auf den Cluster haben kann.
Datenknoten
Jeder DataNode in einem Cluster verwendet einen Hintergrundprozess, um die einzelnen Datenblöcke auf Slave-Servern zu speichern.
Standardmäßig speichert HDFS drei Kopien jedes Datenblocks auf separaten DataNodes. Der NameNode verwendet eine Rack-bewusste Platzierungsrichtlinie. Das bedeutet, dass sich die DataNodes, die die Datenblock-Replikate enthalten, nicht alle auf demselben Server-Rack befinden können.
Ein DataNode kommuniziert und akzeptiert Anweisungen von dem NameNode ungefähr zwanzigmal pro Minute. Außerdem meldet es einmal pro Stunde den Status und Zustand der Datenblöcke, die sich auf diesem Knoten befinden. Basierend auf den bereitgestellten Informationen kann der NameNode den DataNode auffordern, zusätzliche Kopien zu erstellen, sie zu entfernen oder die Anzahl der auf dem Knoten vorhandenen Datenblöcke zu verringern.
Rack-Aware-Platzierungsrichtlinie
Eines der Hauptziele eines verteilten Speichersystems wie HDFS ist die Aufrechterhaltung einer hohen Verfügbarkeit und Replikation. Daher müssen Datenblöcke nicht nur auf verschiedene DataNodes verteilt werden, sondern auch auf Knoten, die sich auf verschiedenen Server-Racks befinden.
Dadurch wird sichergestellt, dass der Ausfall eines ganzen Racks nicht alle Datenreproduktionen beendet. Der HDFS-NameNode verwaltet eine Standardrichtlinie für die Platzierung von Replikaten, die Racks unterstützt:
- Die erste Datenblockreplik wird auf demselben Knoten wie der Client platziert.
- Das zweite Replikat wird automatisch auf einem zufälligen DataNode in einem anderen Rack platziert.
- Das dritte Replikat wird in einem separaten DataNode im selben Rack wie das zweite Replikat platziert.
- Alle zusätzlichen Replikate werden auf zufälligen DataNodes im gesamten Cluster gespeichert.
Diese Rack-Platzierungsrichtlinie verwaltet nur eine Reproduktion pro Knoten und legt ein Limit von zwei Reproduktionen pro Server-Rack fest.
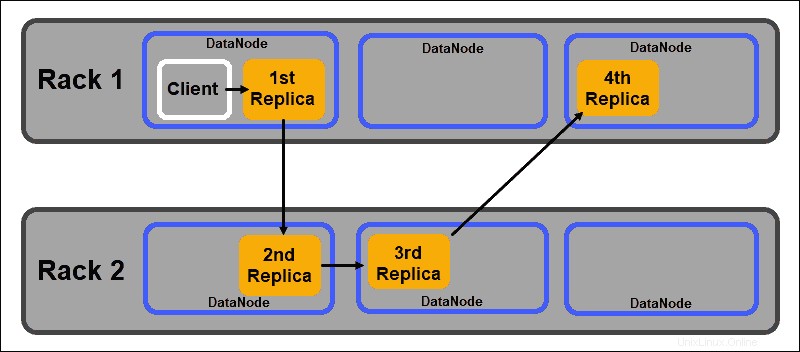
Rack-Ausfälle sind viel seltener als Knotenausfälle. HDFS gewährleistet eine hohe Zuverlässigkeit, indem es immer mindestens eine Datenblockreplik in einem DataNode auf einem anderen Rack speichert.
GARN erklärt
YARN (Yet Another Resource Negotiator) ist die Standard-Clusterverwaltungsressource für Hadoop 2 und Hadoop 3. In früheren Hadoop-Versionen wurde MapReduce verwendet, um sowohl die Datenverarbeitung als auch die Ressourcenzuweisung durchzuführen. Im Laufe der Zeit führte die Notwendigkeit, Verarbeitung und Ressourcenverwaltung aufzuteilen, zur Entwicklung von YARN.
Die Ressourcenzuweisungsrolle von YARN platziert es zwischen der Speicherschicht, dargestellt durch HDFS, und der MapReduce-Verarbeitungs-Engine. YARN bietet auch eine generische Schnittstelle, mit der Sie neue Verarbeitungsmaschinen für verschiedene Datentypen implementieren können.
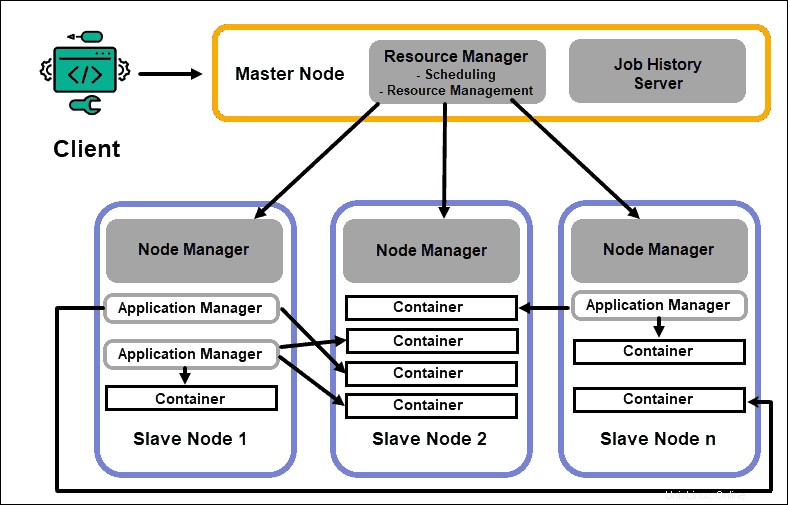
Ressourcenmanager
Der Daemon ResourceManager (RM) steuert alle Verarbeitungsressourcen in einem Hadoop-Cluster. Sein Hauptzweck besteht darin, einzelnen Anwendungen, die sich auf den Slave-Knoten befinden, Ressourcen zuzuweisen. Es behält einen globalen Überblick über die laufenden und geplanten Prozesse, bearbeitet Ressourcenanfragen und plant und weist Ressourcen entsprechend zu. Der ResourceManager ist für das Hadoop-Framework von entscheidender Bedeutung und sollte auf einem dedizierten Master-Knoten ausgeführt werden.
Der einzige Fokus von RM liegt auf der Planung von Workloads. Im Gegensatz zu MapReduce hat es kein Interesse an Failovern oder einzelnen Verarbeitungsaufgaben. Diese Aufgabentrennung in YARN macht Hadoop von Natur aus skalierbar und macht es zu einer voll entwickelten Computerplattform.
NodeManager
Jeder Slave-Knoten hat einen NodeManager-Verarbeitungsdienst und einen DataNode-Speicherdienst. Zusammen bilden sie das Rückgrat eines verteilten Hadoop-Systems.
Der DataNode ist, wie bereits erwähnt, ein Element von HDFS und wird vom NameNode gesteuert. Der NodeManager fungiert auf ähnliche Weise als Slave des ResourceManager. Die Hauptfunktion des NodeManager-Daemons besteht darin, Verarbeitungsressourcendaten auf seinem Slave-Knoten zu verfolgen und regelmäßige Berichte an den ResourceManager zu senden.
Container
Verarbeitungsressourcen in einem Hadoop-Cluster werden immer in Containern bereitgestellt. Ein Container hat Arbeitsspeicher, Systemdateien und Verarbeitungsraum.
Eine Containerbereitstellung ist generisch und kann jede angeforderte benutzerdefinierte Ressource auf jedem System ausführen. Wenn eine angeforderte Menge an Cluster-Ressourcen innerhalb der akzeptablen Grenzen liegt, genehmigt und plant der RM die Bereitstellung dieses Containers.
Die Container-Prozesse auf einem Slave-Knoten werden zunächst vom NodeManager auf diesem spezifischen Slave-Knoten bereitgestellt, überwacht und nachverfolgt.
Anwendungsmaster
Jeder Container auf einem Slave-Knoten hat seinen dedizierten Application Master. Anwendungsmaster werden ebenfalls in einem Container bereitgestellt. Sogar MapReduce hat einen Application Master, der Map- und Reduce-Aufgaben ausführt.
Solange er aktiv ist, sendet ein Application Master Nachrichten über seinen aktuellen Status und den Status der Anwendung, die er überwacht, an den Ressourcenmanager. Basierend auf den bereitgestellten Informationen plant der Ressourcenmanager zusätzliche Ressourcen oder weist sie an anderer Stelle im Cluster zu, wenn sie nicht mehr benötigt werden.
Der Application Master überwacht den gesamten Lebenszyklus einer Anwendung, von der Anforderung der benötigten Container vom RM bis zur Übermittlung von Container-Lease-Anfragen an den NodeManager.
JobHistory-Server
Der JobHistory-Server ermöglicht es Benutzern, Informationen über Bewerbungen abzurufen, die ihre Tätigkeit abgeschlossen haben. Die REST-API bietet Interoperabilität und kann Benutzer dynamisch über aktuelle und abgeschlossene Jobs informieren, die von dem betreffenden Server bereitgestellt werden.
Wie funktioniert YARN?
Ein grundlegender Workflow für die Bereitstellung in YARN beginnt, wenn eine Client-Anwendung eine Anfrage an den ResourceManager sendet.
- Der RessourcenManager weist einen NodeManager an um einen Anwendungsmaster zu starten für diese Anfrage, die dann in einem Container gestartet wird.
- Der neu erstellte Application Master registriert sich beim RM . Der Anwendungs-Master fährt fort, den HDFS-Namensknoten zu kontaktieren und bestimmt den Ort der benötigten Datenblöcke und berechnet die Kartenmenge und reduziert die Aufgaben, die zur Verarbeitung der Daten erforderlich sind.
- Der Anwendungsmaster fordert dann die benötigten Ressourcen vom RM an und kommuniziert weiterhin den Ressourcenbedarf während des gesamten Lebenszyklus des Behälters.
- Der RM plant die Ressourcen zusammen mit den Anfragen von allen anderen Application Masters und stellt ihre Anfragen in eine Warteschlange. Wenn Ressourcen verfügbar werden, stellt der RM sie dem Anwendungs-Master auf einem bestimmten Slave-Knoten zur Verfügung.
- Der Anwendungsmanager kontaktiert den NodeManager für diesen Slave-Knoten und fordert ihn auf, einen Container zu erstellen, indem er Variablen, Authentifizierungstoken und die Befehlszeichenfolge für den Prozess bereitstellt. Basierend auf dieser Anfrage erstellt der NodeManager erstellt und startet den Container .
- Der Anwendungsmanager überwacht dann den Prozess und reagiert im Fehlerfall mit einem Neustart des Prozesses auf dem nächsten freien Steckplatz. Wenn es nach vier verschiedenen Versuchen fehlschlägt, schlägt der gesamte Job fehl. Während dieses Prozesses antwortet der Anwendungsmanager auf Client-Statusanfragen.
Sobald alle Aufgaben abgeschlossen sind, sendet der Anwendungs-Master das Ergebnis an die Client-Anwendung, informiert den RM, dass die Anwendung ihre Aufgabe abgeschlossen hat, meldet sich selbst beim Ressourcen-Manager ab und fährt sich selbst herunter.
Der RM kann den NameNode auch anweisen, einen bestimmten Container während des Prozesses zu beenden, falls sich die Verarbeitungspriorität ändert.
MapReduce erklärt
MapReduce ist ein Programmieralgorithmus, der über den Hadoop-Cluster verteilte Daten verarbeitet. Wie bei jedem Prozess in Hadoop fordert der ResourceManager nach dem Start eines MapReduce-Jobs einen Application Master an, um den Lebenszyklus des MapReduce-Jobs zu verwalten und zu überwachen.
Der Application Master lokalisiert die erforderlichen Datenblöcke basierend auf den Informationen, die auf dem NameNode gespeichert sind. Das AM informiert auch den ResourceManager, einen MapReduce-Job auf demselben Knoten zu starten, auf dem sich die Datenblöcke befinden. Wann immer möglich, werden Daten lokal auf den Slave-Knoten verarbeitet, um die Bandbreitennutzung zu reduzieren und die Cluster-Effizienz zu verbessern.
Die Eingabedaten werden abgebildet, gemischt und dann zu einem aggregierten Ergebnis reduziert. Die Ausgabe des MapReduce-Jobs wird in HDFS gespeichert und repliziert.
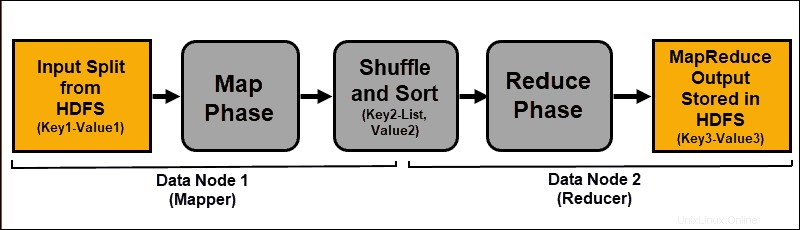
Die Hadoop-Server, die die Zuordnungs- und Reduzierungsaufgaben ausführen, werden häufig als Mapper bezeichnet und Reduzierer .
Der ResourceManager entscheidet, wie viele Mapper verwendet werden. Diese Entscheidung hängt von der Größe der verarbeiteten Daten und dem auf jedem Mapper-Server verfügbaren Speicherblock ab.
Kartenphase
Der Zuordnungsprozess nimmt einzelne logische Ausdrücke der in den HDFS-Datenblöcken gespeicherten Daten auf. Diese Ausdrücke können sich über mehrere Datenblöcke erstrecken und werden als Eingabeaufteilungen bezeichnet . Eingabeaufteilungen werden als Schlüssel-Wert-Paare in den Mapping-Prozess eingeführt .
Eine Mapper-Aufgabe durchläuft jedes Schlüssel-Wert-Paar und erstellt einen neuen Satz von Schlüssel-Wert-Paaren, die sich von den ursprünglichen Eingabedaten unterscheiden. Das vollständige Sortiment aller Schlüssel-Wert-Paare stellt die Ausgabe der Mapper-Aufgabe dar.
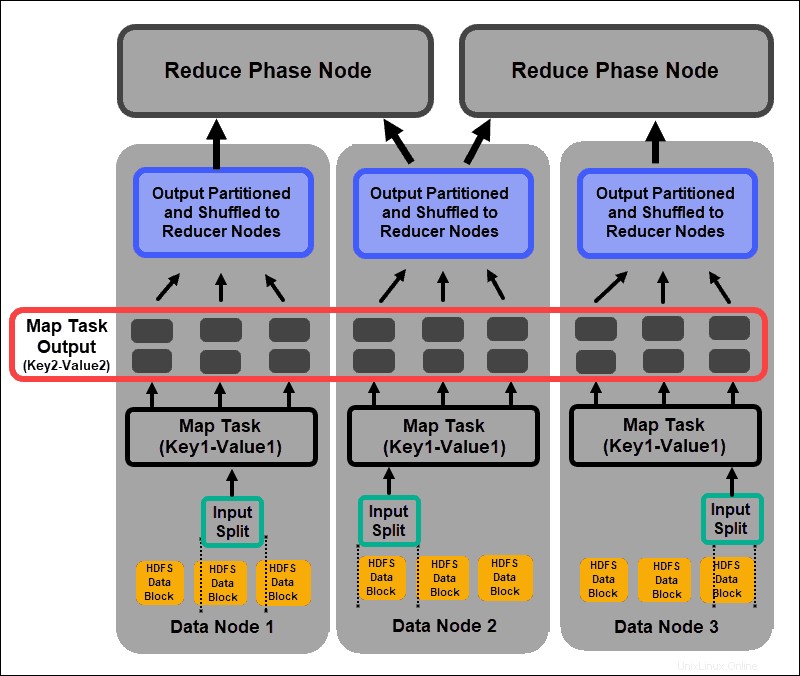
Basierend auf dem Schlüssel von jedem Paar werden die Daten gruppiert, partitioniert und zu den Reducer-Knoten gemischt.
Misch- und Sortierphase
Mischen ist ein Prozess, bei dem die Ergebnisse aller Map-Tasks in die Reducer-Knoten kopiert werden. Das Kopieren der Map-Task-Ausgabe ist der einzige Datenaustausch zwischen Knoten während des gesamten MapReduce-Jobs.
Die Ausgabe einer Map-Aufgabe muss arrangiert werden, um die Effizienz der Reduzierphase zu verbessern. Die abgebildeten Schlüssel-Wert-Paare, die von den Mapper-Knoten gemischt werden, werden nach Schlüssel mit entsprechenden Werten angeordnet. Eine Reduzierungsphase beginnt, nachdem die Eingabe sortiert wurde per Schlüssel in einer einzigen Eingabedatei.
Die Phasen Mischen und Sortieren laufen parallel. Auch wenn die Map-Ausgaben von den Mapper-Knoten abgerufen werden, werden sie auf den Reducer-Knoten gruppiert und sortiert.
Reduzierungsphase
Die Map-Ausgaben werden gemischt und in eine einzelne Reduce-Eingabedatei sortiert, die sich auf dem Reducer-Knoten befindet. Eine Reduce-Funktion verwendet die Eingabedatei, um die Werte basierend auf den entsprechenden zugeordneten Schlüsseln zu aggregieren. Die Ausgabe des Reduzierungsprozesses ist ein neues Schlüssel-Wert-Paar. Dieses Ergebnis stellt die Ausgabe des gesamten MapReduce-Jobs dar und wird standardmäßig in HDFS gespeichert.
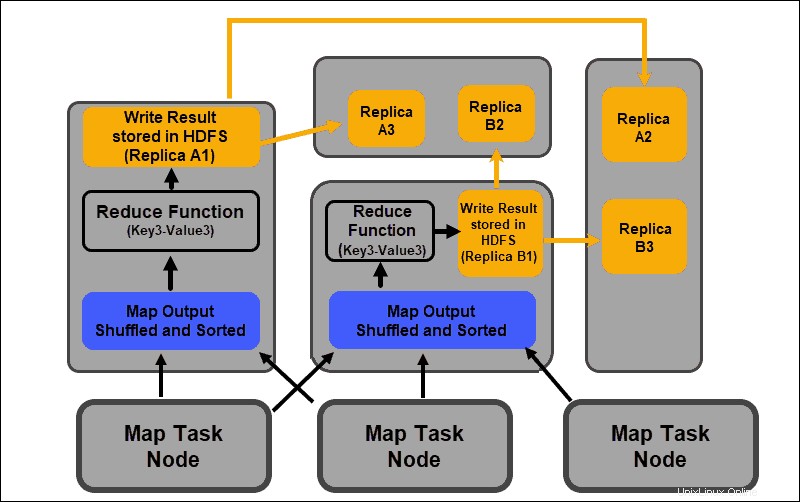
Alle Reduktionsaufgaben finden gleichzeitig statt und arbeiten unabhängig voneinander. Ein Reduzieren-Task ist ebenfalls optional.
Es kann Fälle geben, in denen das Ergebnis einer Zuordnungsaufgabe das gewünschte Ergebnis ist und es nicht erforderlich ist, einen einzelnen Ausgabewert zu erzeugen.
Best Practices für die Bereitstellung von Hadoop
Im folgenden Abschnitt wird erläutert, wie Ihnen die zugrunde liegende Hardware, Benutzerberechtigungen und die Pflege eines ausgewogenen und zuverlässigen Clusters dabei helfen können, mehr aus Ihrem Hadoop-Ökosystem herauszuholen.
Hadoop-Benutzerberechtigungen anpassen
Das Kerberos-Netzwerkprotokoll ist das wichtigste Autorisierungssystem in Hadoop. Es stellt sicher, dass nur verifizierte Knoten und Benutzer Zugriff auf den Cluster haben und innerhalb des Clusters arbeiten.
Nachdem Sie ein Kerberos Key Distribution Center installiert und konfiguriert haben, müssen Sie mehrere Änderungen an den Hadoop-Konfigurationsdateien vornehmen. Die Hadoop core-site.xml Datei definiert Parameter für den gesamten Hadoop-Cluster. Legen Sie hadoop.security.authentication fest -Parameter innerhalb der core-site.xml zu kerberos . Dieselbe Eigenschaft muss auf true gesetzt werden um die Dienstautorisierung zu aktivieren.
Zugriffskontrolllisten in der hadoop-policy-xml Datei kann auch bearbeitet werden, um bestimmten Benutzern unterschiedliche Zugriffsebenen zu gewähren. Mit einfachen Befehlszeilentools kann es schwierig sein, ein Gleichgewicht zwischen den erforderlichen Benutzerberechtigungen und der Vergabe zu vieler Berechtigungen zu finden.
Es ist eine gute Idee, zusätzliche Sicherheits-Frameworks wie Apache zu verwenden Ranger oder Apache Sentry . Diese Tools helfen Ihnen, alle sicherheitsrelevanten Aufgaben von einer zentralen, benutzerfreundlichen Umgebung aus zu verwalten. Verwenden Sie sie, um bestimmte Berechtigungen für Aufgaben und Benutzer bereitzustellen, während Sie die vollständige Kontrolle über den Prozess behalten.
Ausgeglichener Hadoop-Cluster
Ein verteiltes System wie Hadoop ist eine dynamische Umgebung. Das Hinzufügen neuer Knoten oder das Entfernen alter Knoten kann zu einem vorübergehenden Ungleichgewicht innerhalb eines Clusters führen. Datenblöcke können zu wenig repliziert werden.
Ihr Ziel ist es, Daten so konsistent wie möglich über die Slave-Knoten in einem Cluster zu verteilen. Verwenden Sie das Hadoop-Cluster-Balancing-Dienstprogramm, um vordefinierte Einstellungen zu ändern. Definieren Sie Ihre Ausgleichsrichtlinie mit dem hdfs balancer Befehl. Mit diesem Befehl und seinen Optionen können Sie die Kapazitätsschwellenwerte für Knoten ändern.
Die Standardblockgröße ab Hadoop 2.x beträgt 128 MB. Hadoop ermöglicht es einem Benutzer, diese Einstellung zu ändern. Erwägen Sie, die Standarddatenblockgröße zu ändern, wenn Sie große Datenmengen verarbeiten. Andernfalls könnte die Anzahl der gestarteten Jobs Ihren Cluster überfordern.
Wenn Sie die Datenblockgröße erhöhen, wird die Eingabe für die Zuordnungsaufgabe größer und es werden weniger Zuordnungsaufgaben gestartet. Dies wiederum bedeutet, dass die Shuffle-Phase einen viel besseren Durchsatz hat, wenn Daten an den Reducer-Knoten übertragen werden. Diese einfache Anpassung kann die Zeit verkürzen, die zum Abschließen eines MapReduce-Jobs benötigt wird.
Skalieren von Hadoop (Hardware)
Der NameNode ist ein wichtiges Element Ihres Hadoop-Clusters. Binden Sie so viele Verarbeitungskerne wie möglich für diesen Knoten ein. Die Menge an RAM definiert, wie viele Daten aus dem Speicher des Knotens gelesen werden. Wenn Sie die Ihrem Master-Knoten zur Verfügung stehenden Ressourcen überfordern, schränken Sie die Wachstumsfähigkeit Ihres Clusters ein.
Redundante Netzteile sollten immer für den Master Node reserviert werden. Versuchen Sie, keine redundanten Netzteile und wertvolle Hardware-Ressourcen für Datenknoten zu verwenden. Sie sind ein wichtiger Bestandteil eines Hadoop-Ökosystems, jedoch entbehrlich. Erschwingliche dedizierte Server mit Zwischenverarbeitungsfunktionen sind ideal für Datenknoten, da sie weniger Strom verbrauchen und weniger Wärme erzeugen.
Die Skalierungsfähigkeiten von Hadoop sind die wichtigste treibende Kraft hinter seiner weit verbreiteten Implementierung. Es ist notwendig, immer genügend Platz für die Erweiterung Ihres Clusters zu haben. Das schnelle Hinzufügen neuer Knoten oder Speicherplatz erfordert zusätzliche Energie, Netzwerk und Kühlung. All dies kann sich als sehr schwierig erweisen, ohne das wahrscheinliche zukünftige Wachstum sorgfältig zu planen.
Skalieren von Hadoop (Software)
Neue Hadoop-Projekte werden regelmäßig entwickelt und bestehende werden mit erweiterten Funktionen verbessert.
Sogar ältere Tools werden aktualisiert, damit sie von einem Hadoop-Ökosystem profitieren können. Halten Sie immer Ausschau nach neuen Entwicklungen an dieser Front. Die Vielfalt und das Volumen der eingehenden Datensätze erfordern die Einführung zusätzlicher Frameworks.
Die Implementierung eines neuen benutzerfreundlichen Tools kann ein technisches Dilemma schneller lösen als der Versuch, eine benutzerdefinierte Lösung zu erstellen. Scheuen Sie sich nicht vor bereits entwickelten kommerziellen Quick Fixes. Der Markt ist mit Anbietern gesättigt, die Hadoop-as-a-Service oder maßgeschneiderte eigenständige Tools anbieten.
Datenzuverlässigkeit und Fehlertoleranz
Herzschlag ist ein wiederkehrendes TCP-Handshake-Signal. DataNodes, die sich auf jedem Slave-Server befinden, senden kontinuierlich einen Heartbeat an den NameNode, der sich auf dem Master-Server befindet. Der standardmäßige Heartbeat-Zeitrahmen beträgt drei Sekunden. Wenn der NameNode länger als zehn Minuten kein Signal empfängt, schreibt er den DataNode ab und seine Datenblöcke werden automatisch auf anderen Knoten geplant.
Verringern Sie nicht die Heartbeat-Frequenz, um die Belastung des NameNode zu verringern. Selbst in extrem großen Clustern ist es entscheidend, NameNodes „informiert“ zu halten. Ohne einen regelmäßigen und häufigen Heartbeat-Zufluss wird der NameNode stark behindert und kann den Cluster nicht so effektiv steuern.
Um schwerwiegende Folgen von Fehlern zu vermeiden, behalten Sie die standardmäßigen Rack-Awareness-Einstellungen bei und speichern Sie Kopien von Datenblöcken über Server-Racks hinweg. Wenn Sie ein Server-Rack verlieren, bleiben die anderen Repliken erhalten, und die Auswirkungen auf die Datenverarbeitung sind minimal.