Einführung
HDFS (Hadoop Distributed File System) ist eine wichtige Komponente des Apache Hadoop-Projekts. Hadoop ist ein Ökosystem von Software, die zusammenarbeiten, um Ihnen bei der Verwaltung von Big Data zu helfen. Die zwei Hauptelemente von Hadoop sind:
- MapReduce – verantwortlich für die Ausführung von Aufgaben
- HDFS – verantwortlich für die Pflege der Daten
In diesem Artikel sprechen wir über das zweite der beiden Module. Sie werden lernen was HDFS ist, wie es funktioniert und die grundlegende HDFS-Terminologie .

Was ist HDFS?
Hadoop Distributed File System ist ein fehlertolerantes Dateisystem zur Datenspeicherung, das auf handelsüblicher Hardware ausgeführt wird. Es wurde entwickelt, um Herausforderungen zu meistern, die herkömmliche Datenbanken nicht bewältigen konnten. Daher wird sein volles Potenzial nur im Umgang mit Big Data ausgeschöpft.
Die Hauptprobleme, die das Hadoop-Dateisystem lösen musste, waren Geschwindigkeit , Kosten und Zuverlässigkeit .
Was sind die Vorteile von HDFS?
Die Vorteile von HDFS sind in der Tat Lösungen, die das Dateisystem für die zuvor genannten Herausforderungen bereitstellt:
- Es ist schnell. Dank seiner Cluster-Architektur kann es mehr als 2 GB Daten pro Sekunde liefern.
- Es ist kostenlos. HDFS ist eine Open-Source-Software, für die keine Lizenz- oder Supportkosten anfallen.
- Es ist zuverlässig. Das Dateisystem speichert mehrere Kopien von Daten in separaten Systemen, um sicherzustellen, dass sie immer zugänglich sind.
Diese Vorteile sind besonders beim Umgang mit Big Data von Bedeutung und wurden durch die besondere Art und Weise ermöglicht, wie HDFS mit Daten umgeht.
Wie speichert HDFS Daten?
HDFS teilt Dateien in Blöcke und speichert jeden Block auf einem DataNode. Mehrere DataNodes sind mit dem Master-Node im Cluster, dem NameNode, verknüpft. Der Master-Knoten verteilt Kopien dieser Datenblöcke über den Cluster. Es weist den Benutzer auch an, wo er die gewünschten Informationen finden kann.
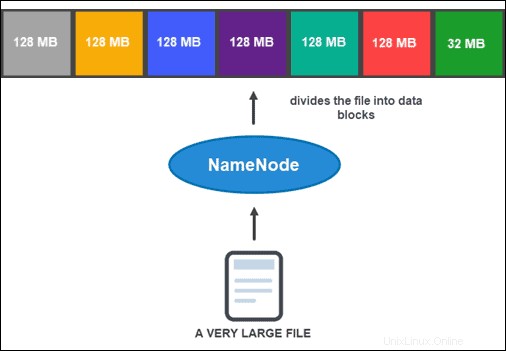
Bevor der NameNode Ihnen jedoch beim Speichern und Verwalten der Daten helfen kann, muss er die Datei zunächst in kleinere, überschaubare Datenblöcke partitionieren. Dieser Vorgang wird Datenblockaufteilung genannt .
Aufteilung von Datenblöcken
Standardmäßig darf ein Block nicht größer als 128 MB sein. Die Anzahl der Blöcke hängt von der Ausgangsgröße der Datei ab. Alle bis auf den letzten Block haben die gleiche Größe (128 MB), während der letzte der Rest der Datei ist.
Beispielsweise wird eine 800-MB-Datei in sieben Datenblöcke aufgeteilt. Sechs der sieben Blöcke sind 128 MB groß, während der siebte Datenblock die restlichen 32 MB umfasst.
Dann wird jeder Block in mehrere Kopien repliziert.
Datenreplikation
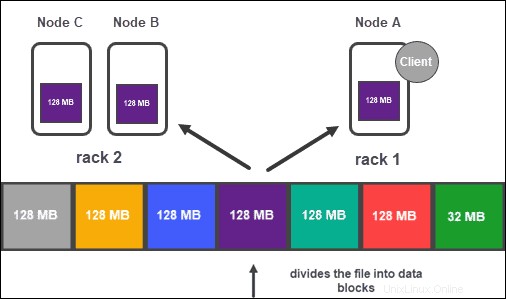
Basierend auf der Konfiguration des Clusters erstellt der NameNode mithilfe der Replikationsmethode eine Reihe von Kopien jedes Datenblocks .
Es wird empfohlen, mindestens drei Replikate zu haben, was auch die Standardeinstellung ist. Der Masterknoten speichert sie auf separaten DataNodes des Clusters. Der Zustand der Knoten wird genau überwacht, um sicherzustellen, dass die Daten immer verfügbar sind.
Um eine hohe Zugänglichkeit, Zuverlässigkeit und Fehlertoleranz zu gewährleisten, empfehlen Entwickler, die drei Replikate mit der folgenden Topologie einzurichten:
- Speichern Sie die erste Replik auf dem Knoten, auf dem sich der Client befindet.
- Speichern Sie dann das zweite Replikat auf einem anderen Gestell.
- Speichern Sie schließlich die dritte Replik auf demselben Rack wie die zweite Replik, aber auf einem anderen Knoten.
HDFS-Architektur:NameNodes und DataNodes
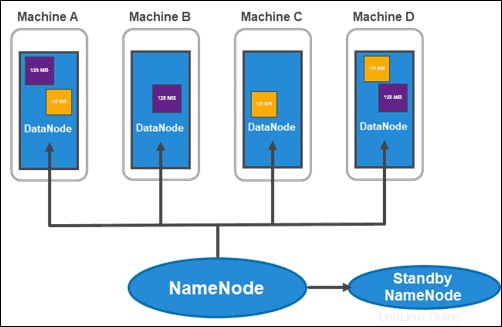
HDFS hat eine Master-Slave-Architektur. Der Masterknoten ist der NameNode , der mehrere Slave-Knoten innerhalb des Clusters verwaltet, bekannt als DataNodes .
NameNodes
Hadoop 2.x führte die Möglichkeit ein, mehrere NameNodes pro Rack zu haben. Diese Neuheit war ziemlich bedeutsam, da ein einziger Master-Knoten mit allen Informationen innerhalb des Clusters eine große Schwachstelle darstellte.
Der übliche Cluster besteht aus zwei NameNodes:
- ein aktiver NameNode
- und einen Standby-NameNode
Während sich der erste mit allen Client-Vorgängen innerhalb des Clusters befasst, bleibt der zweite mit seiner gesamten Arbeit synchronisiert, wenn ein Failover erforderlich ist.
Der aktive NameNode verfolgt die Metadaten jedes Datenblocks und seiner Kopien. Dazu gehören Dateiname, Berechtigung, ID, Speicherort und Anzahl der Replikate. Es speichert alle Informationen in einem fsimage , ein Namespace-Image, das im lokalen Speicher des Dateisystems gespeichert ist. Darüber hinaus verwaltet es Transaktionsprotokolle mit dem Namen EditLogs , die alle am System vorgenommenen Änderungen aufzeichnen.
Der Hauptzweck des Stanby NameNode ist es, das Problem des Single Point of Failure zu lösen. Es liest alle an den EditLogs vorgenommenen Änderungen und wendet sie auf seinen NameSpace an (die Dateien und Verzeichnisse in den Daten). Wenn der Master-Knoten ausfällt, führt der Zookeeper-Dienst das Failover durch, sodass der Standby-Knoten eine aktive Sitzung aufrechterhalten kann.
Datenknoten
DataNodes sind Slave-Daemons, die vom NameNode zugewiesene Datenblöcke speichern. Wie oben erwähnt, stellen die Standardeinstellungen sicher, dass jeder Datenblock drei Kopien hat. Sie können die Anzahl der Replikate ändern, es ist jedoch nicht ratsam, unter drei zu gehen.
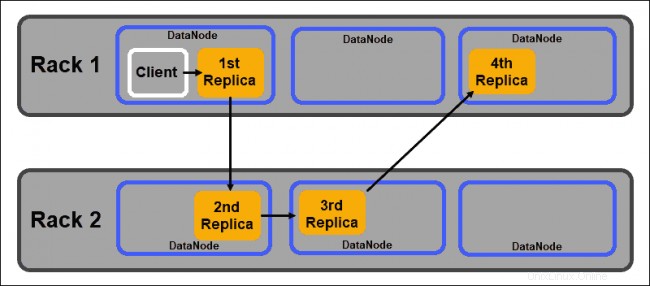
Die Replikate sollten gemäß Hadoops Rack Awareness verteilt werden Richtlinie, die Folgendes feststellt:
- Die Anzahl der Replikate muss größer sein als die Anzahl der Racks.
- Ein DataNode kann nur eine Kopie eines Datenblocks speichern.
- Ein Rack kann nicht mehr als zwei Kopien eines Datenblocks speichern.
Wenn Sie diese Richtlinien befolgen, können Sie:
- Netzwerkbandbreite maximieren.
- Schutz vor Datenverlust.
- Leistung und Zuverlässigkeit verbessern.
Hauptmerkmale von HDFS
Dies sind die Hauptmerkmale des Hadoop Distributed File System:
1. Verwaltet große Datenmengen. HDFS eignet sich hervorragend für die Handhabung großer Datenmengen und bietet eine Lösung, die herkömmliche Dateisysteme nicht bieten könnten. Dies geschieht durch die Aufteilung der Daten in überschaubare Blöcke, die schnelle Verarbeitungszeiten ermöglichen.
2. Rack-bewusst. Es folgt den Richtlinien des Rack-Bewusstseins, die sicherstellen, dass ein System hochverfügbar und effizient ist.
3. Fehlertoleranz. Da Daten über mehrere Racks und Knoten hinweg gespeichert werden, werden sie repliziert. Das bedeutet, dass bei einem Ausfall einer der Maschinen innerhalb eines Clusters eine Kopie dieser Daten von einem anderen Knoten verfügbar ist.
4. Skalierbar. Sie können Ressourcen entsprechend der Größe Ihres Dateisystems skalieren. HDFS umfasst vertikale und horizontale Skalierbarkeitsmechanismen.
HDFS-Nutzung im wirklichen Leben
Unternehmen, die mit großen Datenmengen zu tun haben, migrieren seit langem zu Hadoop, einer der führenden Lösungen für die Verarbeitung von Big Data aufgrund seiner Speicher- und Analysefunktionen.
Finanzdienstleistungen. Das Hadoop Distributed File System wurde entwickelt, um Daten zu unterstützen, von denen erwartet wird, dass sie exponentiell wachsen. Das System ist skalierbar, ohne dass die Gefahr besteht, komplexe Datenverarbeitung zu verlangsamen.
Einzelhandel. Da die Kenntnis Ihrer Kunden eine entscheidende Komponente für den Erfolg in der Einzelhandelsbranche ist, bewahren viele Unternehmen große Mengen an strukturierten und unstrukturierten Kundendaten auf. Sie verwenden Hadoop, um die gesammelten Daten zu verfolgen und zu analysieren, um zukünftige Bestände, Preise, Marketingkampagnen und andere Projekte zu planen.
Telekommunikation. Die Telekommunikationsbranche verwaltet riesige Datenmengen und muss diese im Petabyte-Bereich verarbeiten. Es verwendet Hadoop-Analysen, um Anrufdatensätze, Netzwerkverkehrsanalysen und andere telekommunikationsbezogene Prozesse zu verwalten.
Energiewirtschaft. Die Energiewirtschaft ist ständig auf der Suche nach Möglichkeiten zur Verbesserung der Energieeffizienz. Es stützt sich auf Systeme wie Hadoop und sein Dateisystem, um Verbrauchsmuster und -praktiken zu analysieren und zu verstehen.
Versicherung. Krankenkassen sind auf Datenanalysen angewiesen. Diese Ergebnisse dienen als Grundlage für die Formulierung und Umsetzung von Richtlinien. Für Versicherungsunternehmen ist der Einblick in die Kundenhistorie von unschätzbarem Wert. Die Fähigkeit, eine leicht zugängliche Datenbank zu verwalten, während sie kontinuierlich wächst, ist der Grund, warum sich so viele an Apache Hadoop gewandt haben.