Hier sehen wir, wie Apache Spark auf Ubuntu 20.04 oder 18.04 installiert wird, die Befehle gelten für Linux Mint, Debian und andere ähnliche Linux-Systeme.
Apache Spark ist ein universelles Datenverarbeitungstool, das als Datenverarbeitungs-Engine bezeichnet wird. Wird von Data Engineers und Data Scientists verwendet, um extrem schnelle Datenabfragen für große Datenmengen im Terabyte-Bereich durchzuführen. Es ist ein Framework für Cluster-basierte Berechnungen, das mit dem klassischen Hadoop Map/Reduce konkurriert, indem es den im Cluster verfügbaren Arbeitsspeicher für eine schnellere Ausführung von Jobs nutzt.
Darüber hinaus bietet Spark auch die Möglichkeit, die Daten per SQL zu steuern, per Streaming in (nahezu) Echtzeit zu verarbeiten und stellt eine eigene Graph-Datenbank sowie eine Machine-Learning-Bibliothek zur Verfügung. Das Framework bietet hierfür In-Memory-Technologien, d.h. es kann Anfragen und Daten direkt im Hauptspeicher der Cluster-Knoten ablegen.
Apache Spark ist ideal, um große Datenmengen schnell zu verarbeiten. Das Programmiermodell von Spark basiert auf Resilient Distributed Datasets (RDD), einer Sammlungsklasse, die in einem Cluster verteilt arbeitet. Diese Open-Source-Plattform unterstützt eine Vielzahl von Programmiersprachen wie Java, Scala, Python und R.
Schritte für die Installation von Apache Spark auf Ubuntu 20.04
Die hier angegebenen Schritte können für andere Ubuntu-Versionen wie 21.04/18.04 verwendet werden, einschließlich Linux Mint, Debian und ähnlichen Linux.
1. Java mit anderen Abhängigkeiten installieren
Hier installieren wir die neueste verfügbare Version von Java, die von Apache Spark zusammen mit einigen anderen Dingen benötigt wird – Git und Scala, um seine Fähigkeiten zu erweitern.
sudo apt install default-jdk scala git
2. Laden Sie Apache Spark auf Ubuntu 20.04
herunter
Besuchen Sie jetzt die offizielle Spark-Website und laden Sie die neueste verfügbare Version herunter. Beim Schreiben dieses Tutorials war die neueste Version jedoch 3.1.2. Daher laden wir hier dasselbe herunter, falls es anders ist, wenn Sie die Spark-Installation auf Ihrem Ubuntu-System durchführen, machen Sie das. Kopieren Sie einfach den Download-Link dieses Tools und verwenden Sie es mit wget oder direkt auf Ihr System herunterladen.
wget https://downloads.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
3. Extrahieren Sie Spark nach /opt
Um sicherzustellen, dass wir den extrahierten Ordner nicht versehentlich löschen, legen wir ihn an einem sicheren Ort ab, z. B. /opt Verzeichnis.
sudo mkdir /opt/spark
sudo tar -xf spark*.tgz -C /opt/spark --strip-component 1
Ändern Sie auch die Berechtigung des Ordners, damit Spark darin schreiben kann.
sudo chmod -R 777 /opt/spark
4. Spark-Ordner zum Systempfad hinzufügen
Nun, da wir die Datei nach /opt verschoben haben Verzeichnis, um den Spark-Befehl im Terminal auszuführen, müssen wir jedes Mal den gesamten Pfad angeben, was ärgerlich ist. Um dies zu lösen, konfigurieren wir Umgebungsvariablen für Spark durch Hinzufügen seiner Home-Pfade zu einer Profil-/Bashrc-Datei des Systems. Dadurch können wir seine Befehle von überall im Terminal ausführen, unabhängig davon, in welchem Verzeichnis wir uns befinden.
echo "export SPARK_HOME=/opt/spark" >> ~/.bashrc echo "export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin" >> ~/.bashrc echo "export PYSPARK_PYTHON=/usr/bin/python3" >> ~/.bashrc
Shell neu laden:
source ~/.bashrc
5. Starten Sie den Apache Spark-Masterserver auf Ubuntu
Da wir die Variablenumgebung bereits für Spark konfiguriert haben, starten wir jetzt seinen eigenständigen Master-Server, indem wir sein Skript ausführen:
start-master.sh
Spark Master-Web-UI und Listen-Port ändern (optional, nur bei Bedarf verwenden)
Wenn Sie einen benutzerdefinierten Port verwenden möchten, können Sie die unten angegebenen Optionen oder Argumente verwenden.
–port – Port, auf dem der Dienst lauschen soll (Standard:7077 für Master, random für Worker)
–webui-port – Port für Web-UI (Standard:8080 für Master, 8081 für Worker)
Beispiel – Ich möchte die Spark-Web-UI auf 8082 ausführen und Port 7072 überwachen lassen, dann lautet der Befehl zum Starten wie folgt:
start-master.sh --port 7072 --webui-port 8082
6. Zugriff auf Spark Master (spark://Ubuntu:7077) – Webinterface
Greifen wir nun auf die Weboberfläche des Spark-Masterservers zu, der unter der Portnummer 8080 ausgeführt wird . Öffnen Sie also in Ihrem Browser http://127.0.0.1:8080 .
Unser Master läuft unter spark://Ubuntu :7077, wobei Ubuntu ist der Hostname des Systems und könnte in Ihrem Fall anders sein.
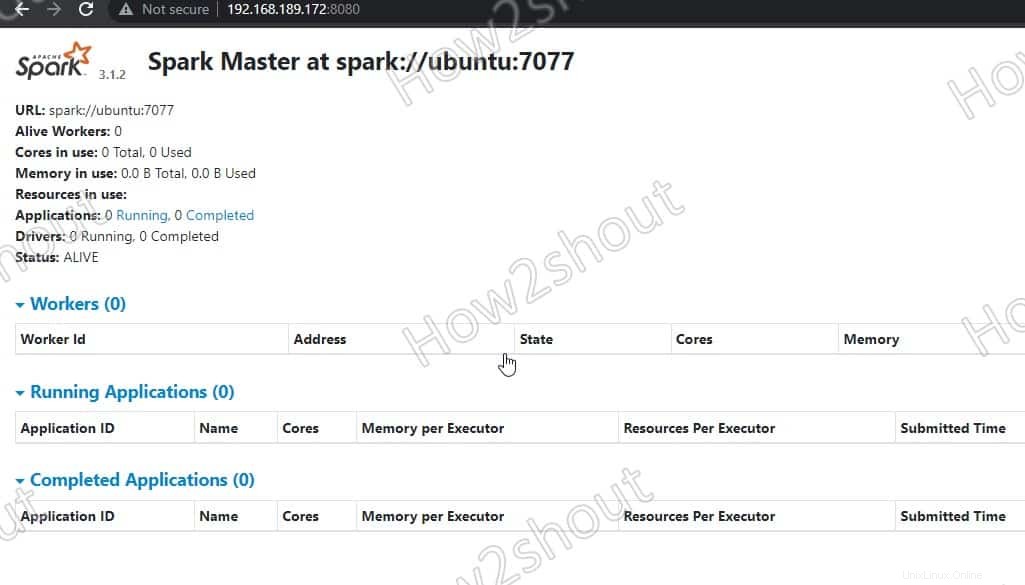
Wenn Sie einen CLI-Server verwenden und den Browser des anderen Systems verwenden möchten, das auf die Server-IP-Adresse zugreifen kann, öffnen Sie dafür zuerst 8080 in der Firewall. Dadurch können Sie remote auf die Spark-Weboberfläche unter – http://your-server-ip-addres:8080 zugreifen
sudo ufw allow 8080
7. Führen Sie das Slave-Worker-Skript aus
Um den Spark-Slave-Worker auszuführen, müssen wir sein Skript initiieren, das in dem Verzeichnis verfügbar ist, das wir in /opt kopiert haben . Die Befehlssyntax lautet:
Befehlssyntax:
start-worker.sh spark://hostname:port
Ändern Sie im obigen Befehl den Hostnamen und Port . Wenn Sie Ihren Hostnamen nicht kennen, geben Sie einfach hostname ein im Endgerät. Wobei der Standardport von master auf 7077 läuft, können Sie im obigen Screenshot sehen .
Da unser Hostname also ubuntu ist, lautet der Befehl wie folgt:
start-worker.sh spark://ubuntu:7077
Aktualisieren Sie die Weboberfläche und Sie sehen die Arbeiter-ID und die Menge an Speicher zugeordnet:
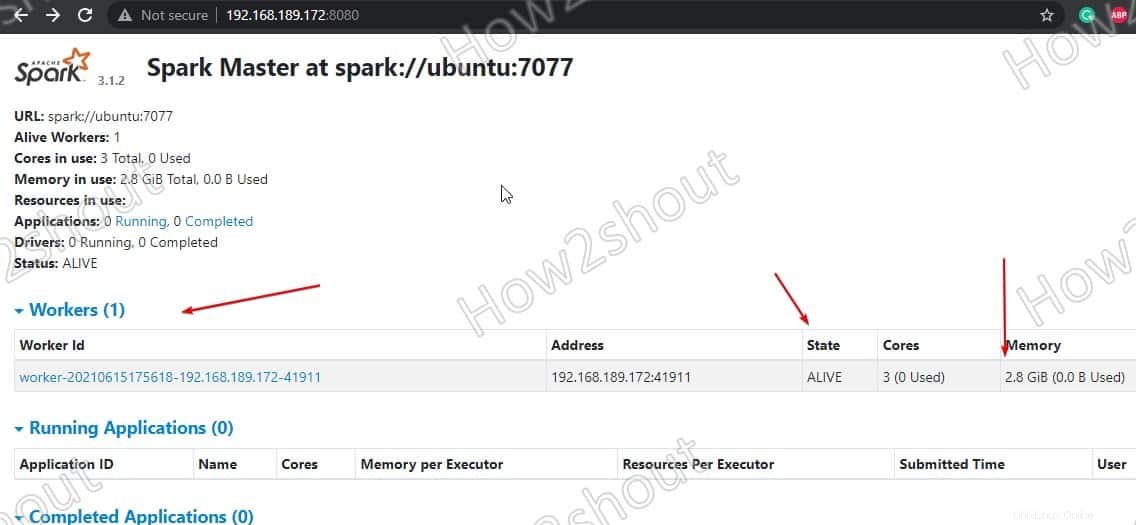
Wenn Sie möchten, können Sie den Arbeitsspeicher/RAM ändern, der dem Worker zugewiesen ist. Dazu müssen Sie den Worker mit der Menge an RAM neu starten, die Sie ihm zur Verfügung stellen möchten.
stop-worker.sh start-worker.sh -m 212M spark://ubuntu:7077
Spark-Shell verwenden
Diejenigen, die die Spark-Shell verwenden möchten, um mit der Programmierung zu beginnen, können darauf zugreifen, indem sie direkt Folgendes eingeben:
spark-shell
Um die unterstützten Optionen anzuzeigen, geben Sie :help ein und um die Shell zu verlassen, verwenden Sie – :quite
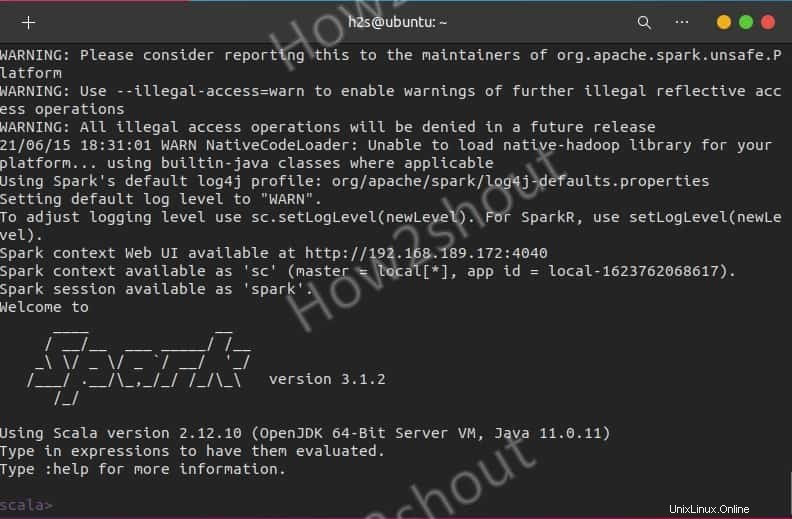
Um mit der Python-Shell anstelle von Scala zu beginnen, verwenden Sie:
pyspark
Befehle zum Starten und Stoppen des Servers
Wenn Sie Master/Worker starten oder stoppen möchten Instanzen, verwenden Sie dann die entsprechenden Skripte:
stop-master.sh stop-worker.sh
Auf einmal aufhören
stop-all.sh
Oder alle auf einmal starten:
start-all.sh
Abschlussgedanken:
Auf diese Weise können wir Apache Spark unter Ubuntu Linux installieren und verwenden. Weitere Informationen finden Sie in der offiziellen Dokumentation . Allerdings ist Spark im Vergleich zu Hadoop noch relativ jung, sodass man mit einigen Ecken und Kanten rechnen muss. Es hat sich jedoch bereits vielfach in der Praxis bewährt und ermöglicht durch die schnelle Ausführung von Jobs und das Caching von Daten neue Use Cases im Bereich Big oder Fast Data. Und schließlich bietet es eine einheitliche API für Tools, die sonst im Hadoop-Umfeld separat betrieben und betrieben werden müssten.