Apache Spark ist ein kostenloses Open-Source-Cluster-Computing-Framework, das für Analysen, maschinelles Lernen und Graphenverarbeitung großer Datenmengen verwendet wird. Spark verfügt über mehr als 80 High-Level-Operatoren, mit denen Sie parallele Apps erstellen und interaktiv über die Scala-, Python-, R- und SQL-Shells verwenden können. Es ist eine blitzschnelle In-Memory-Datenverarbeitungs-Engine, die speziell für Data Science entwickelt wurde. Es bietet eine Vielzahl von Funktionen, darunter Geschwindigkeit, Fehlertoleranz, Echtzeit-Stream-Verarbeitung, In-Memory-Computing, erweiterte Analysen und vieles mehr.
In diesem Tutorial zeigen wir Ihnen, wie Sie Apache Spark auf einem Debian 10-Server installieren.
Voraussetzungen
- Ein Server mit Debian 10 und 2 GB RAM.
- Auf Ihrem Server ist ein Root-Passwort konfiguriert.
Erste Schritte
Bevor Sie beginnen, wird empfohlen, Ihren Server auf die neueste Version zu aktualisieren. Sie können es mit dem folgenden Befehl aktualisieren:
apt-get update -y
apt-get upgrade -y
Sobald Ihr Server aktualisiert ist, starten Sie ihn neu, um die Änderungen zu implementieren.
Installieren Sie Java
Apache Spark ist in der Java-Sprache geschrieben. Sie müssen also Java auf Ihrem System installieren. Standardmäßig ist die neueste Version von Java im Standard-Repository von Debian 10 verfügbar. Sie können es mit dem folgenden Befehl installieren:
apt-get install default-jdk -y
Überprüfen Sie nach der Installation von Java die installierte Version von Java mit dem folgenden Befehl:
java --version
Sie sollten die folgende Ausgabe erhalten:
openjdk 11.0.5 2019-10-15 OpenJDK Runtime Environment (build 11.0.5+10-post-Debian-1deb10u1) OpenJDK 64-Bit Server VM (build 11.0.5+10-post-Debian-1deb10u1, mixed mode, sharing)
Apache Spark herunterladen
Zunächst müssen Sie die neueste Version von Apache Spark von der offiziellen Website herunterladen. Zum Zeitpunkt der Erstellung dieses Artikels ist die neueste Version von Apache Spark 3.0. Sie können es mit dem folgenden Befehl in das /opt-Verzeichnis herunterladen:
cd /opt
wget http://apachemirror.wuchna.com/spark/spark-3.0.0-preview2/spark-3.0.0-preview2-bin-hadoop2.7.tgz
Sobald der Download abgeschlossen ist, extrahieren Sie die heruntergeladene Datei mit dem folgenden Befehl:
tar -xvzf spark-3.0.0-preview2-bin-hadoop2.7.tgz
Als nächstes benennen Sie das extrahierte Verzeichnis wie unten gezeigt in Spark um:
mv spark-3.0.0-preview2-bin-hadoop2.7 spark
Als Nächstes müssen Sie die Umgebung für Spark festlegen. Sie können dies tun, indem Sie die Datei ~/.bashrc bearbeiten:
nano ~/.bashrc
Fügen Sie am Ende der Datei die folgenden Zeilen hinzu:
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
Speichern und schließen Sie die Datei, wenn Sie fertig sind. Aktivieren Sie dann die Umgebung mit dem folgenden Befehl:
source ~/.bashrc
Starten Sie den Masterserver
Sie können nun den Master-Server mit folgendem Befehl starten:
start-master.sh
Sie sollten die folgende Ausgabe erhalten:
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-debian10.out
Standardmäßig überwacht Apache Spark den Port 8080. Sie können dies mit dem folgenden Befehl überprüfen:
netstat -ant | grep 8080
Ausgabe:
tcp6 0 0 :::8080 :::* LISTEN
Öffnen Sie nun Ihren Webbrowser und geben Sie die URL http://Server-IP-Adresse:8080 ein. Sie sollten die folgende Seite sehen:
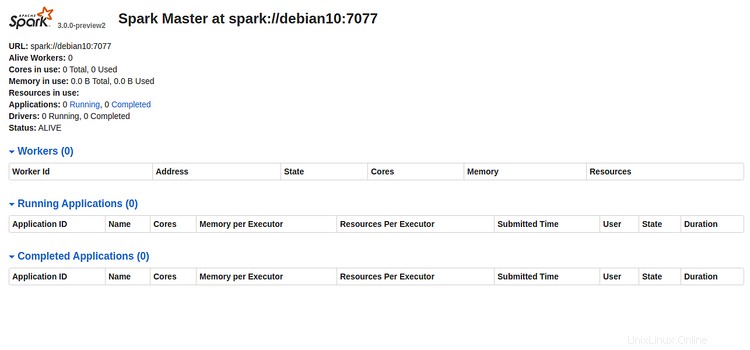
Bitte notieren Sie sich die Spark-URL "spark://debian10:7077 " aus dem obigen Bild. Dies wird verwendet, um den Spark-Worker-Prozess zu starten.
Spark-Arbeitsprozess starten
Jetzt können Sie den Spark-Arbeitsprozess mit dem folgenden Befehl starten:
start-slave.sh spark://debian10:7077
Sie sollten die folgende Ausgabe erhalten:
starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.worker.Worker-1-debian10.out
Auf Spark-Shell zugreifen
Spark Shell ist eine interaktive Umgebung, die eine einfache Möglichkeit bietet, die API zu erlernen und Daten interaktiv zu analysieren. Sie können mit dem folgenden Befehl auf die Spark-Shell zugreifen:
spark-shell
Sie sollten die folgende Ausgabe sehen:
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by org.apache.spark.unsafe.Platform (file:/opt/spark/jars/spark-unsafe_2.12-3.0.0-preview2.jar) to constructor java.nio.DirectByteBuffer(long,int)
WARNING: Please consider reporting this to the maintainers of org.apache.spark.unsafe.Platform
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
19/12/29 15:53:11 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://debian10:4040
Spark context available as 'sc' (master = local[*], app id = local-1577634806690).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.0.0-preview2
/_/
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 11.0.5)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
Hier erfahren Sie, wie Sie Apache Spark schnell und bequem optimal nutzen können.
Wenn Sie den Spark Master- und Slave-Server stoppen möchten, führen Sie die folgenden Befehle aus:
stop-slave.sh
stop-master.sh
Das war es fürs Erste, Sie haben Apache Spark erfolgreich auf dem Debian 10-Server installiert. Weitere Informationen finden Sie in der offiziellen Spark-Dokumentation unter Spark Doc.