Apache Spark ist ein kostenloser, quelloffener, universeller und verteilter Rechenrahmen, der erstellt wurde, um schnellere Rechenergebnisse zu liefern. Es unterstützt mehrere APIs für Streaming, Grafikverarbeitung, einschließlich Java, Python, Scala und R. Im Allgemeinen kann Apache Spark in Hadoop-Clustern verwendet werden, aber Sie können es auch im Standalone-Modus installieren.
In diesem Tutorial zeigen wir Ihnen, wie Sie das Apache Spark-Framework unter Debian 11 installieren.
Voraussetzungen
- Ein Server mit Debian 11.
- Auf dem Server ist ein Root-Passwort konfiguriert.
Installieren Sie Java
Apache Spark ist in Java geschrieben. Daher muss Java auf Ihrem System installiert sein. Wenn es nicht installiert ist, können Sie es mit dem folgenden Befehl installieren:
apt-get install default-jdk curl -y
Überprüfen Sie nach der Installation von Java die Java-Version mit dem folgenden Befehl:
java --version
Sie sollten die folgende Ausgabe erhalten:
openjdk 11.0.12 2021-07-20 OpenJDK Runtime Environment (build 11.0.12+7-post-Debian-2) OpenJDK 64-Bit Server VM (build 11.0.12+7-post-Debian-2, mixed mode, sharing)
Installieren Sie Apache Spark
Zum Zeitpunkt der Erstellung dieses Tutorials ist die neueste Version von Apache Spark 3.1.2. Sie können es mit dem folgenden Befehl herunterladen:
wget https://dlcdn.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
Sobald der Download abgeschlossen ist, extrahieren Sie die heruntergeladene Datei mit dem folgenden Befehl:
tar -xvzf spark-3.1.2-bin-hadoop3.2.tgz
Verschieben Sie als Nächstes das extrahierte Verzeichnis mit dem folgenden Befehl nach /opt:
mv spark-3.1.2-bin-hadoop3.2/ /opt/spark
Bearbeiten Sie als Nächstes die Datei ~/.bashrc und fügen Sie die Spark-Pfadvariable hinzu:
nano ~/.bashrc
Fügen Sie die folgenden Zeilen hinzu:
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
Speichern und schließen Sie die Datei und aktivieren Sie dann die Spark-Umgebungsvariable mit dem folgenden Befehl:
source ~/.bashrc
Apache Spark starten
Sie können jetzt den folgenden Befehl ausführen, um den Spark-Masterdienst zu starten:
start-master.sh
Sie sollten die folgende Ausgabe erhalten:
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-debian11.out
Standardmäßig überwacht Apache Spark Port 8080. Sie können dies mit dem folgenden Befehl überprüfen:
ss -tunelp | grep 8080
Sie erhalten die folgende Ausgabe:
tcp LISTEN 0 1 *:8080 *:* users:(("java",pid=24356,fd=296)) ino:47523 sk:b cgroup:/user.slice/user-0.slice/session-1.scope v6only:0 <->
Starten Sie als Nächstes den Apache Spark-Arbeitsprozess mit dem folgenden Befehl:
start-slave.sh spark://your-server-ip:7077
Greifen Sie auf die Web-Benutzeroberfläche von Apache Spark zu
Sie können jetzt über die URL http://your-server-ip:8080 auf die Apache Spark-Weboberfläche zugreifen . Sie sollten den Apache Spark Master- und Slave-Dienst auf dem folgenden Bildschirm sehen:
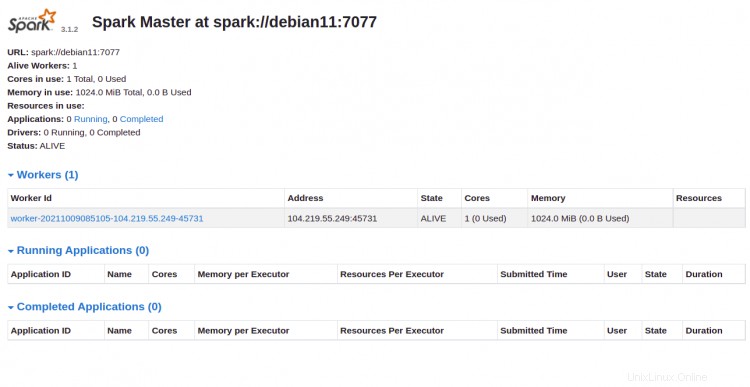
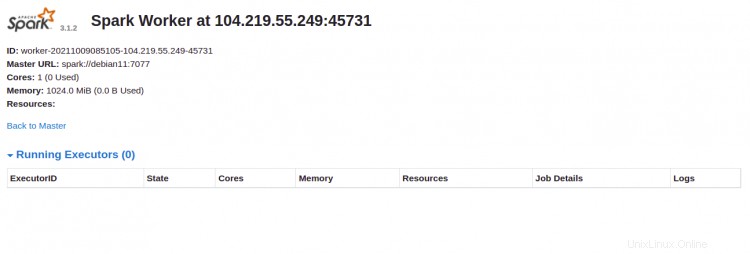
Klicken Sie auf den Arbeiter Ich würde. Sie sollten die detaillierten Informationen Ihres Arbeiters auf dem folgenden Bildschirm sehen:
Apache Spark über die Befehlszeile verbinden
Wenn Sie über die Befehlsshell eine Verbindung zu Spark herstellen möchten, führen Sie die folgenden Befehle aus:
spark-shell
Sobald Sie verbunden sind, erhalten Sie die folgende Schnittstelle:
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 11.0.12)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
Wenn Sie Python in Spark verwenden möchten. Sie können das Befehlszeilenprogramm pyspark verwenden.
Installieren Sie zuerst die Python-Version 2 mit dem folgenden Befehl:
apt-get install python -y
Nach der Installation können Sie den Spark mit dem folgenden Befehl verbinden:
pyspark
Sobald die Verbindung hergestellt ist, sollten Sie die folgende Ausgabe erhalten:
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Python version 3.9.2 (default, Feb 28 2021 17:03:44)
Spark context Web UI available at http://debian11:4040
Spark context available as 'sc' (master = local[*], app id = local-1633769632964).
SparkSession available as 'spark'.
>>>
Master und Slave stoppen
Stoppen Sie zuerst den Slave-Prozess mit dem folgenden Befehl:
stop-slave.sh
Sie erhalten die folgende Ausgabe:
stopping org.apache.spark.deploy.worker.Worker
Stoppen Sie als Nächstes den Master-Prozess mit dem folgenden Befehl:
stop-master.sh
Sie erhalten die folgende Ausgabe:
stopping org.apache.spark.deploy.master.Master
Schlussfolgerung
Herzliche Glückwünsche! Sie haben Apache Spark erfolgreich auf Debian 11 installiert. Sie können jetzt Apache Spark in Ihrer Organisation verwenden, um große Datensätze zu verarbeiten