Hadoop ist ein kostenloses, Open-Source- und Java-basiertes Software-Framework, das für die Speicherung und Verarbeitung großer Datensätze auf Computerclustern verwendet wird. Es verwendet HDFS, um seine Daten zu speichern und diese Daten mit MapReduce zu verarbeiten. Es ist ein Ökosystem von Big-Data-Tools, die hauptsächlich für Data Mining und maschinelles Lernen verwendet werden.
Apache Hadoop 3.3 enthält spürbare Verbesserungen und viele Fehlerbehebungen gegenüber den vorherigen Versionen. Es besteht aus vier Hauptkomponenten wie Hadoop Common, HDFS, YARN und MapReduce.
Dieses Tutorial erklärt Ihnen, wie Sie Apache Hadoop auf einem Ubuntu 20.04 LTS Linux-System installieren und konfigurieren.
Schritt 1 – Java installieren
Hadoop ist in Java geschrieben und unterstützt nur Java Version 8. Hadoop Version 3.3 und neuere Versionen unterstützen auch Java 11 Runtime sowie Java 8.
Sie können OpenJDK 11 aus den standardmäßigen apt-Repositories installieren:
sudo apt updatesudo apt install openjdk-11-jdk
Überprüfen Sie nach der Installation die installierte Version von Java mit dem folgenden Befehl:
java -version
Sie sollten die folgende Ausgabe erhalten:
openjdk version "11.0.11" 2021-04-20 OpenJDK Runtime Environment (build 11.0.11+9-Ubuntu-0ubuntu2.20.04) OpenJDK 64-Bit Server VM (build 11.0.11+9-Ubuntu-0ubuntu2.20.04, mixed mode, sharing)
Schritt 2 – Erstellen Sie einen Hadoop-Benutzer
Aus Sicherheitsgründen empfiehlt es sich, einen separaten Benutzer zum Ausführen von Hadoop zu erstellen.
Führen Sie den folgenden Befehl aus, um einen neuen Benutzer mit dem Namen hadoop zu erstellen:
sudo adduser hadoop
Geben Sie das neue Passwort ein und bestätigen Sie es wie unten gezeigt:
Adding user `hadoop' ...
Adding new group `hadoop' (1002) ...
Adding new user `hadoop' (1002) with group `hadoop' ...
Creating home directory `/home/hadoop' ...
Copying files from `/etc/skel' ...
New password:
Retype new password:
passwd: password updated successfully
Changing the user information for hadoop
Enter the new value, or press ENTER for the default
Full Name []:
Room Number []:
Work Phone []:
Home Phone []:
Other []:
Is the information correct? [Y/n] y
Schritt 3 – SSH-schlüsselbasierte Authentifizierung konfigurieren
Als Nächstes müssen Sie die passwortlose SSH-Authentifizierung für das lokale System konfigurieren.
Ändern Sie zuerst den Benutzer mit dem folgenden Befehl in hadoop:
su - hadoop
Führen Sie als Nächstes den folgenden Befehl aus, um öffentliche und private Schlüsselpaare zu generieren:
ssh-keygen -t rsa
Sie werden aufgefordert, den Dateinamen einzugeben. Drücken Sie einfach die Eingabetaste, um den Vorgang abzuschließen:
Generating public/private rsa key pair. Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): Created directory '/home/hadoop/.ssh'. Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/hadoop/.ssh/id_rsa Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub The key fingerprint is: SHA256:QSa2syeISwP0hD+UXxxi0j9MSOrjKDGIbkfbM3ejyIk [email protected] The key's randomart image is: +---[RSA 3072]----+ | ..o++=.+ | |..oo++.O | |. oo. B . | |o..+ o * . | |= ++o o S | |.++o+ o | |.+.+ + . o | |o . o * o . | | E + . | +----[SHA256]-----+
Hängen Sie als Nächstes die generierten öffentlichen Schlüssel aus id_rsa.pub an „authorized_keys“ an und legen Sie die richtige Berechtigung fest:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keyschmod 640 ~/.ssh/authorized_keys
Überprüfen Sie als Nächstes die passwortlose SSH-Authentifizierung mit dem folgenden Befehl:
ssh localhost
Sie werden aufgefordert, Hosts zu authentifizieren, indem Sie bekannten Hosts RSA-Schlüssel hinzufügen. Geben Sie yes ein und drücken Sie die Eingabetaste, um den localhost zu authentifizieren:
The authenticity of host 'localhost (127.0.0.1)' can't be established. ECDSA key fingerprint is SHA256:JFqDVbM3zTPhUPgD5oMJ4ClviH6tzIRZ2GD3BdNqGMQ. Are you sure you want to continue connecting (yes/no/[fingerprint])? yes
Schritt 4 – Installation von Hadoop
Ändern Sie zuerst den Benutzer mit dem folgenden Befehl in hadoop:
su - hadoop
Laden Sie als Nächstes die neueste Version von Hadoop mit dem Befehl wget herunter:
wget https://downloads.apache.org/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz
Extrahieren Sie nach dem Herunterladen die heruntergeladene Datei:
tar -xvzf hadoop-3.3.0.tar.gz
Als nächstes benennen Sie das extrahierte Verzeichnis in hadoop:
ummv hadoop-3.3.0 hadoop
Als Nächstes müssen Sie Hadoop- und Java-Umgebungsvariablen auf Ihrem System konfigurieren.
Öffnen Sie die ~/.bashrc Datei in Ihrem bevorzugten Texteditor:
nano ~/.bashrc
Fügen Sie die folgenden Zeilen an die Datei an. Sie können den JAVA_HOME-Speicherort finden, indem Sie dirname $(dirname $(readlink -f $(which java))) command on terminal.
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 export HADOOP_HOME=/home/hadoop/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export HADOOP_YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
Save and close the file. Then, activate the environment variables with the following command:
source ~/.bashrc
Öffnen Sie als Nächstes die Hadoop-Umgebungsvariablendatei:
nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
Legen Sie erneut JAVA_HOME in der Hadoop-Umgebung fest.
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
Speichern und schließen Sie die Datei, wenn Sie fertig sind.
Schritt 5 – Konfigurieren von Hadoop
Zuerst müssen Sie die Verzeichnisse namenode und datanode im Hadoop-Home-Verzeichnis erstellen:
Führen Sie den folgenden Befehl aus, um beide Verzeichnisse zu erstellen:
mkdir -p ~/hadoopdata/hdfs/namenodemkdir -p ~/hadoopdata/hdfs/datanode
Bearbeiten Sie als Nächstes die core-site.xml Datei und aktualisieren Sie sie mit Ihrem System-Hostnamen:
nano $HADOOP_HOME/etc/hadoop/core-site.xml
Ändern Sie den folgenden Namen gemäß Ihrem System-Hostnamen:
XHTML
| 123456 |
Speichern und schließen Sie die Datei. Bearbeiten Sie dann die hdfs-site.xml Datei:
nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml
Ändern Sie den NameNode- und DataNode-Verzeichnispfad wie unten gezeigt:
XHTML
| 1234567891011121314151617 |
Speichern und schließen Sie die Datei. Bearbeiten Sie dann die mapred-site.xml Datei:
nano $HADOOP_HOME/etc/hadoop/mapred-site.xml
Nehmen Sie die folgenden Änderungen vor:
XHTML
| 123456 |
Speichern und schließen Sie die Datei. Bearbeiten Sie dann die yarn-site.xml Datei:
nano $HADOOP_HOME/etc/hadoop/yarn-site.xml
Nehmen Sie die folgenden Änderungen vor:
XHTML
| 123456 |
Speichern und schließen Sie die Datei, wenn Sie fertig sind.
Schritt 6 – Hadoop-Cluster starten
Vor dem Starten des Hadoop-Clusters. Sie müssen den Namenode als Hadoop-Benutzer formatieren.
Führen Sie den folgenden Befehl aus, um den Hadoop-Namenode zu formatieren:
hdfs namenode -format
Sie sollten die folgende Ausgabe erhalten:
2020-11-23 10:31:51,318 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0 2020-11-23 10:31:51,323 INFO namenode.FSImage: FSImageSaver clean checkpoint: txid=0 when meet shutdown. 2020-11-23 10:31:51,323 INFO namenode.NameNode: SHUTDOWN_MSG: /************************************************************ SHUTDOWN_MSG: Shutting down NameNode at hadoop.tecadmin.net/127.0.1.1 ************************************************************/
Führen Sie nach dem Formatieren des Namenode den folgenden Befehl aus, um den Hadoop-Cluster zu starten:
start-dfs.sh
Sobald das HDFS erfolgreich gestartet wurde, sollten Sie die folgende Ausgabe erhalten:
Starting namenodes on [hadoop.tecadmin.com] hadoop.tecadmin.com: Warning: Permanently added 'hadoop.tecadmin.com,fe80::200:2dff:fe3a:26ca%eth0' (ECDSA) to the list of known hosts. Starting datanodes Starting secondary namenodes [hadoop.tecadmin.com]
Starten Sie als Nächstes den YARN-Dienst wie unten gezeigt:
start-yarn.sh
Sie sollten die folgende Ausgabe erhalten:
Starting resourcemanager Starting nodemanagers
Sie können jetzt den Status aller Hadoop-Dienste mit dem jps-Befehl überprüfen:
jps
Sie sollten alle laufenden Dienste in der folgenden Ausgabe sehen:
18194 NameNode 18822 NodeManager 17911 SecondaryNameNode 17720 DataNode 18669 ResourceManager 19151 Jps
Schritt 7 – Firewall anpassen
Hadoop ist jetzt gestartet und überwacht die Ports 9870 und 8088. Als Nächstes müssen Sie diese Ports durch die Firewall zulassen.
Führen Sie den folgenden Befehl aus, um Hadoop-Verbindungen durch die Firewall zuzulassen:
firewall-cmd --permanent --add-port=9870/tcpfirewall-cmd --permanent --add-port=8088/tcp
Laden Sie als Nächstes den Dienst firewalld neu, um die Änderungen zu übernehmen:
firewall-cmd --reload
Schritt 8 – Zugriff auf Hadoop Namenode und Ressourcenmanager
Um auf den Namenode zuzugreifen, öffnen Sie Ihren Webbrowser und besuchen Sie die URL http://your-server-ip:9870. Sie sollten den folgenden Bildschirm sehen:
http://hadoop.tecadmin.net:9870
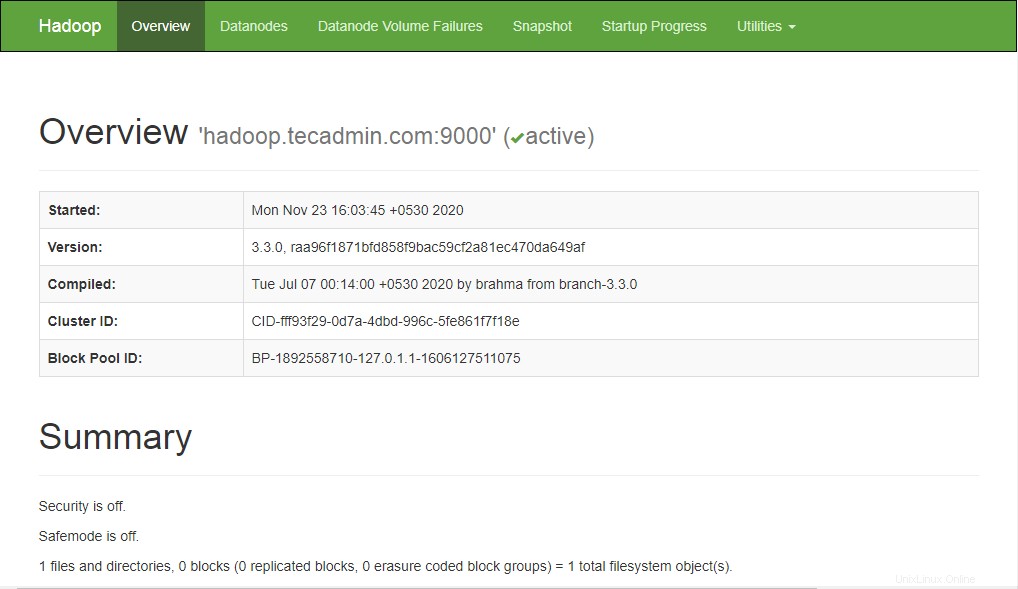
Um auf die Ressourcenverwaltung zuzugreifen, öffnen Sie Ihren Webbrowser und besuchen Sie die URL http://your-server-ip:8088. Sie sollten den folgenden Bildschirm sehen:
http://hadoop.tecadmin.net:8088
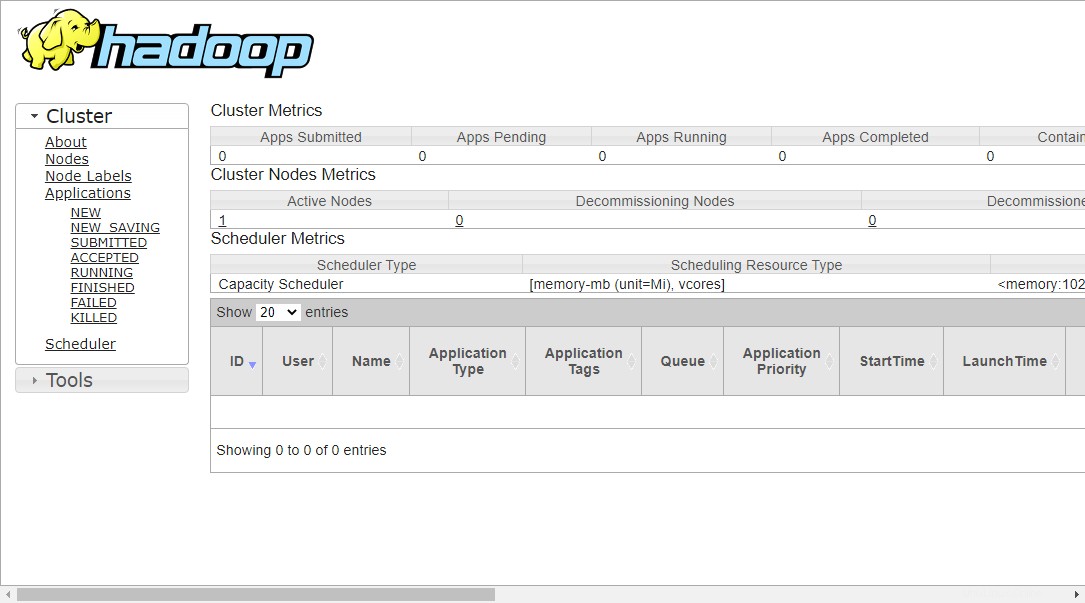
Schritt 9 – Überprüfen Sie den Hadoop-Cluster
An diesem Punkt wird der Hadoop-Cluster installiert und konfiguriert. Als Nächstes erstellen wir einige Verzeichnisse im HDFS-Dateisystem, um Hadoop zu testen.
Lassen Sie uns mit dem folgenden Befehl ein Verzeichnis im HDFS-Dateisystem erstellen:
hdfs dfs -mkdir /test1hdfs dfs -mkdir /logs
Führen Sie als Nächstes den folgenden Befehl aus, um das obige Verzeichnis aufzulisten:
hdfs dfs -ls /
Sie sollten die folgende Ausgabe erhalten:
Found 3 items drwxr-xr-x - hadoop supergroup 0 2020-11-23 10:56 /logs drwxr-xr-x - hadoop supergroup 0 2020-11-23 10:51 /test1
Legen Sie auch einige Dateien im Hadoop-Dateisystem ab. Zum Beispiel Protokolldateien vom Host-Rechner in das Hadoop-Dateisystem stellen.
hdfs dfs -put /var/log/* /logs/
Sie können die obigen Dateien und Verzeichnisse auch in der Hadoop-Namenode-Weboberfläche überprüfen.
Gehen Sie zur Namenode-Weboberfläche, klicken Sie auf Dienstprogramme => Durchsuchen Sie das Dateisystem. Auf dem folgenden Bildschirm sollten Sie Ihre zuvor erstellten Verzeichnisse sehen:
http://hadoop.tecadmin.net:9870/explorer.html
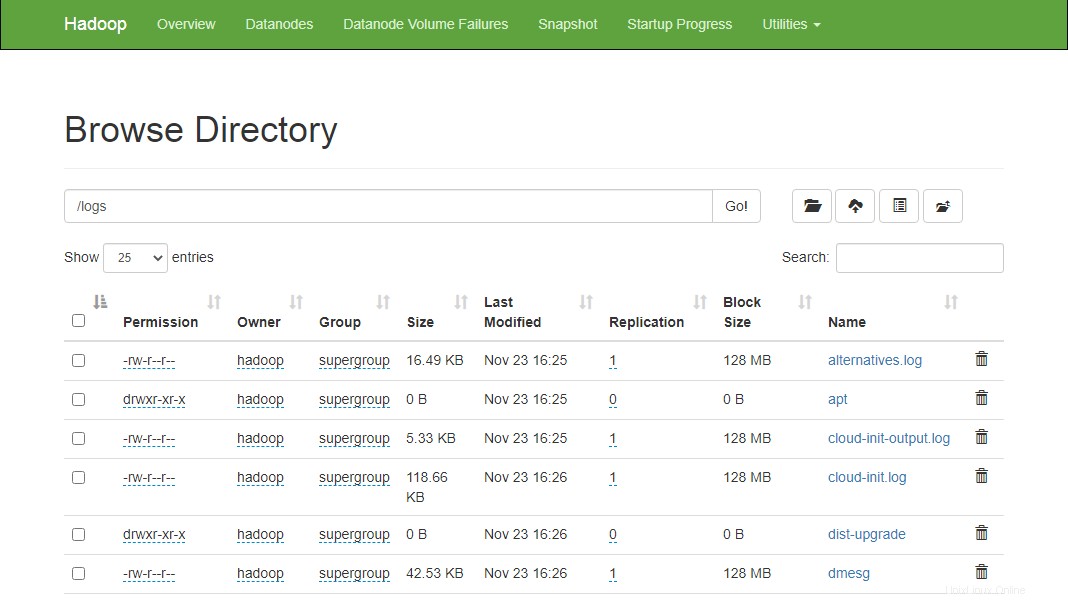
Schritt 10 – Hadoop-Cluster stoppen
Sie können den Hadoop Namenode- und Yarn-Dienst auch jederzeit stoppen, indem Sie stop-dfs.sh ausführen und stop-yarn.sh script als Hadoop-Benutzer.
Um den Hadoop-Namenode-Dienst zu stoppen, führen Sie den folgenden Befehl als Hadoop-Benutzer aus:
stop-dfs.sh
Führen Sie den folgenden Befehl aus, um den Hadoop Resource Manager-Dienst zu stoppen:
stop-yarn.sh
Schlussfolgerung
In diesem Tutorial wurde Ihnen Schritt für Schritt erklärt, wie Sie Hadoop auf einem Ubuntu 20.04-Linux-System installieren und konfigurieren.