In diesem Tutorial lernen wir, wie man einen Hadoop-Cluster mit mehreren Knoten unter Ubuntu 16.04 einrichtet. Ein Hadoop-Cluster mit mehr als einem Datenknoten ist ein Hadoop-Cluster mit mehreren Knoten, daher ist es das Ziel dieses Tutorials, zwei Datenknoten zum Laufen zu bringen.
1) Voraussetzungen
- Ubuntu 16.04
- Hadoop-2.7.3
- Java 7
- SSH
Für dieses Tutorial habe ich zwei Ubuntu 16.04 Systeme, ich nenne sie Master und Sklave System läuft auf jedem System ein Datenknoten.
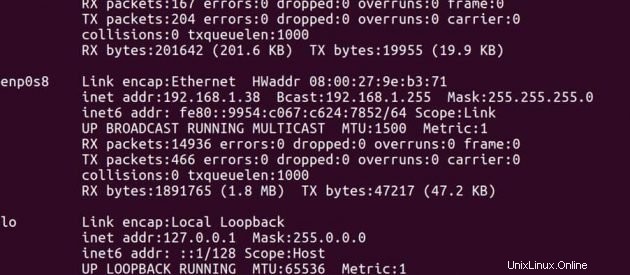
IP-Adresse von Master -> 192.168.1.37
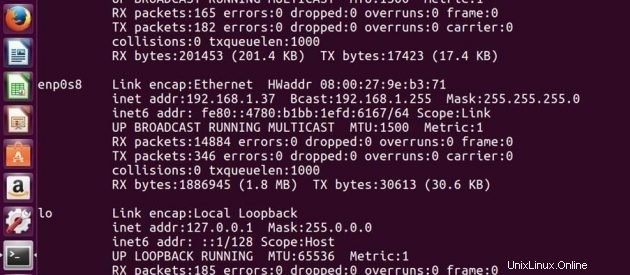
IP-Adresse von Slave -> 192.168.1.38
Auf Meister
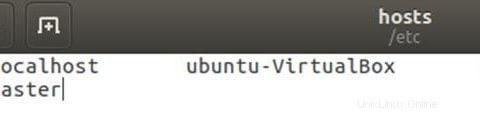
Hostdatei mit Master- und Slave-IP-Adresse bearbeiten.
sudo gedit /etc/hostsBearbeiten Sie die Datei wie unten, Sie können andere Zeilen in der Datei entfernen. Speichern Sie die Datei nach der Bearbeitung und schließen Sie sie.

Auf Sklave
Hostdatei mit Master- und Slave-IP-Adresse bearbeiten.
sudo gedit /etc/hostsBearbeiten Sie die Datei wie unten, Sie können andere Zeilen in der Datei entfernen. Speichern Sie die Datei nach der Bearbeitung und schließen Sie sie.
2) Java-Installation
Bevor Sie Hadoop einrichten, müssen Sie Java auf Ihren Systemen installiert haben. Installieren Sie Open JDK 7 auf beiden Ubuntu-Rechnern mit den folgenden Befehlen.
sudo add-apt-repository ppa:openjdk-r/ppasudo apt-get updatedo apt-get install openjdk-7-jdk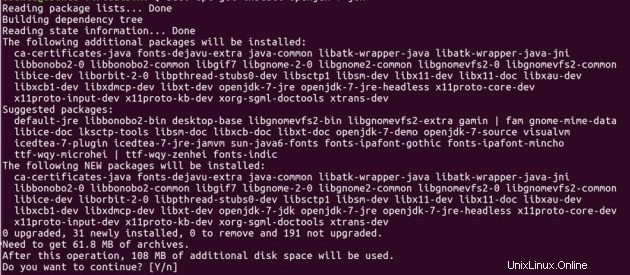
Führen Sie den folgenden Befehl aus, um zu sehen, ob Java auf Ihrem System installiert wurde.
java -version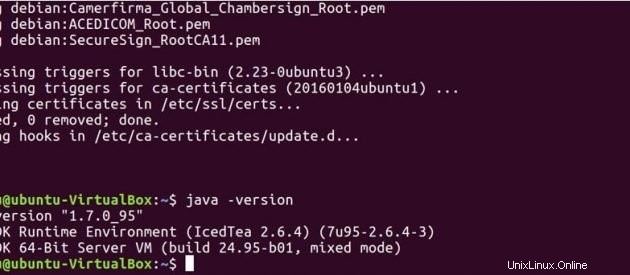
Standardmäßig wird Java unter /usr/lib/jvm/ gespeichert Verzeichnis.
ls /usr/lib/jvm
Legen Sie den Java-Pfad in .bashrc fest Datei.
sudo gedit .bashrcexport JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64
export PATH=$PATH:/usr/lib/jvm/java-7-openjdk-amd64/bin
Führen Sie den folgenden Befehl aus, um die in der .bashrc-Datei vorgenommenen Änderungen zu aktualisieren.
source .bashrc3) SSH
Hadoop benötigt SSH-Zugriff, um seine Knoten zu verwalten, daher müssen wir SSH sowohl auf Master- als auch auf Slave-Systemen installieren.
sudo apt-get install openssh-server</pre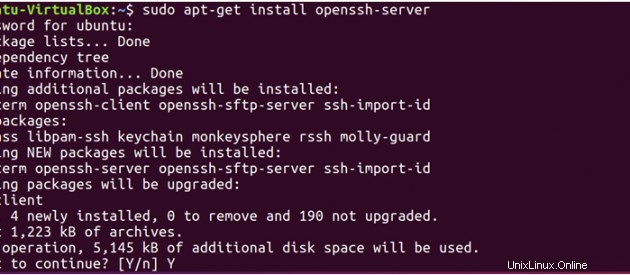
Now, we have to generate an SSH key on master machine. When it asks you to enter a file name to save the key, do not give any name, just press enter.
ssh-keygen -t rsa -P ""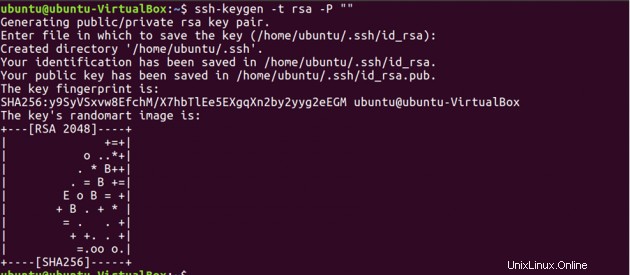
Zweitens müssen Sie mit diesem neu erstellten Schlüssel den SSH-Zugriff auf Ihren Master-Computer aktivieren.
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
Testen Sie nun die SSH-Einrichtung, indem Sie sich mit Ihrem lokalen Computer verbinden.
ssh localhost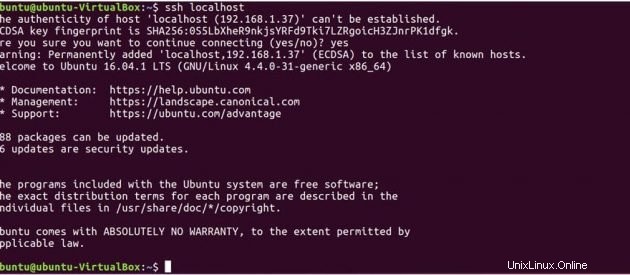
Führen Sie nun den folgenden Befehl aus, um den auf dem Master generierten öffentlichen Schlüssel an den Slave zu senden.
ssh-copy-id -i $HOME/.ssh/id_rsa.pub ubuntu@slave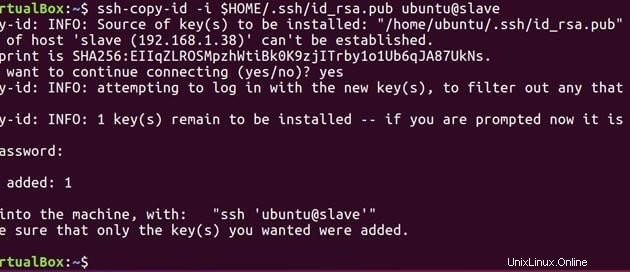
Jetzt, da sowohl Master als auch Slave den öffentlichen Schlüssel haben, können Sie auch Master mit Master und Master mit Slave verbinden.
ssh master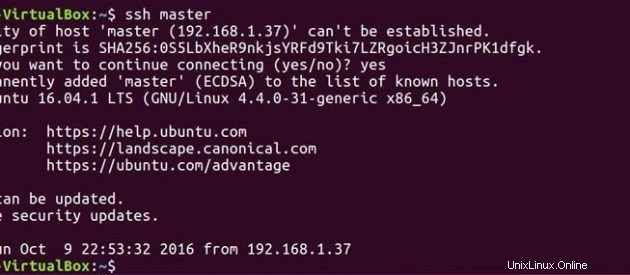
ssh slave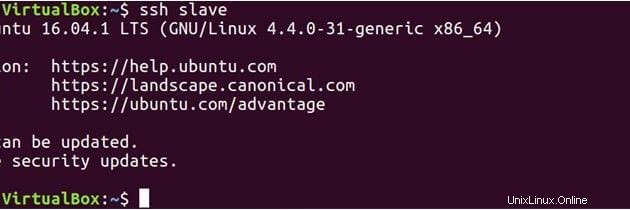
Auf Meister
Bearbeiten Sie die Masterdatei wie folgt.
sudo gedit hadoop-2.7.3/etc/hadoop/masters
Bearbeiten Sie die Slaves-Datei wie folgt.
sudo gedit hadoop-2.7.3/etc/hadoop/slaves
Auf Sklave
Bearbeiten Sie die Masterdatei wie folgt.
sudo gedit hadoop-2.7.3/etc/hadoop/masters4) Hadoop-Installation
Jetzt haben wir unser Java- und SSH-Setup fertig. Wir können loslegen und Hadoop auf beiden Systemen installieren. Verwenden Sie den folgenden Link, um das Hadoop-Paket herunterzuladen. Ich verwende die neueste stabile Version hadoop 2.7.3
http://hadoop.apache.org/releases.html
Auf Meister
Der folgende Befehl lädt hadoop-2.7.3 herunter tar-Datei.
wget https://archive.apache.org/dist/hadoop/core/hadoop-2.7.3/hadoop-2.7.3.tar.gz
lsEntpacken Sie die Datei
tar -xvf hadoop-2.7.3.tar.gz
ls
Bestätigen Sie, dass Hadoop auf Ihrem System installiert wurde.
cd hadoop-2.7.3/
bin/hadoop-2.7.3/
Bevor wir Konfigurationen für Hadoop festlegen, werden wir die folgenden Umgebungsvariablen in der .bashrc-Datei festlegen.
cd
sudo gedit .bashrcHadoop-Umgebungsvariablen
# Set Hadoop-related environment variables
export HADOOP_HOME=$HOME/hadoop-2.7.3
export HADOOP_CONF_DIR=$HOME/hadoop-2.7.3/etc/hadoop
export HADOOP_MAPRED_HOME=$HOME/hadoop-2.7.3
export HADOOP_COMMON_HOME=$HOME/hadoop-2.7.3
export HADOOP_HDFS_HOME=$HOME/hadoop-2.7.3
export YARN_HOME=$HOME/hadoop-2.7.3
# Add Hadoop bin/ directory to PATH
export PATH=$PATH:$HOME/hadoop-2.7.3/bin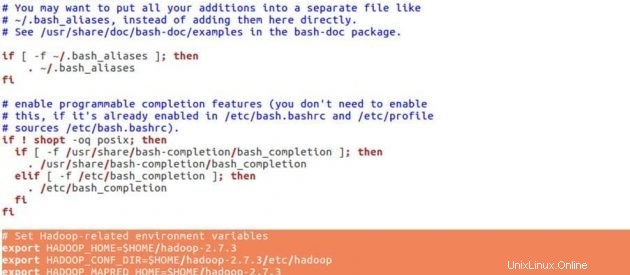
Fügen Sie die folgenden Zeilen am Ende Ihrer .bashrc ein Datei, speichern Sie die Datei und schließen Sie sie.
source .bashrcKonfigurieren Sie JAVA_HOME in ‘hadoop-env.sh’ . Diese Datei gibt Umgebungsvariablen an, die sich auf das JDK auswirken, das von Apache Hadoop 2.7.3-Daemons verwendet wird, die von den Hadoop-Startskripts gestartet werden:
cd hadoop-2.7.3/etc/hadoop/sudo gedit hadoop-env.sh
Export JAVA_HOME=/usr/lib/jvm/java-7-openjdk-amd64

Stellen Sie den Java-Pfad wie oben gezeigt ein, speichern Sie die Datei und schließen Sie sie.
Jetzt erstellen wir NameNode und DataNode Verzeichnisse.
cd
mkdir -p $HADOOP_HOME/hadoop2_data/hdfs/namenode
mkdir -p $HADOOP_HOME/hadoop2_data/hdfs/datanode
Hadoop verfügt über viele Konfigurationsdateien, die gemäß den Anforderungen Ihrer Hadoop-Infrastruktur konfiguriert werden müssen. Lassen Sie uns die Hadoop-Konfigurationsdateien einzeln konfigurieren.
cd hadoop-2.7.3/etc/hadoop/
sudo gedit core-site.xmlCore-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
</configuration>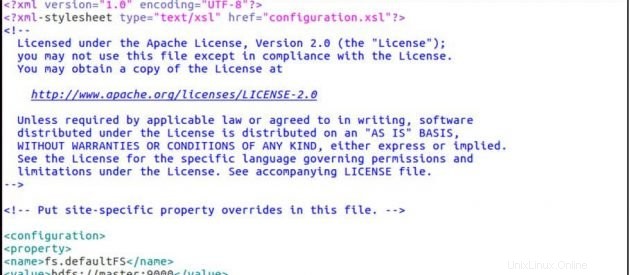
sudo gedit hdfs-site.xmlhdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/ubuntu/hadoop-2.7.3/hadoop2_data/hdfs/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/ubuntu/hadoop-2.7.3/hadoop2_data/hdfs/datanode</value>
</property>
</configuration>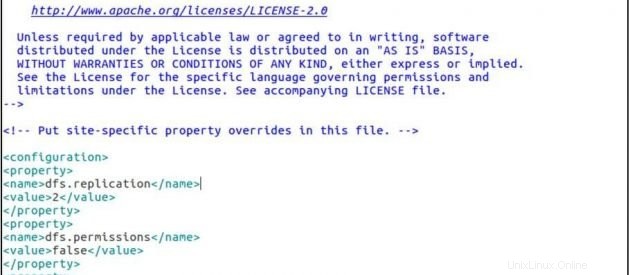
sudo gedit yarn-site.xmlyarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
cp mapred-site.xml.template mapred-site.xml
sudo gedit mapred-site.xmlmapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>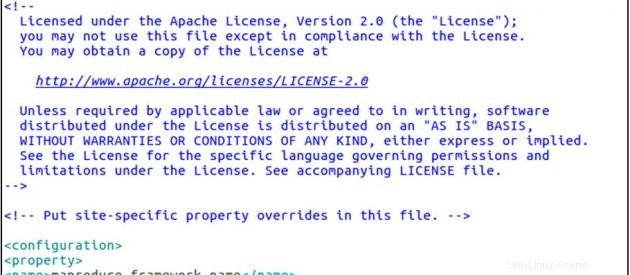
Befolgen Sie nun die gleichen Hadoop-Installations- und Konfigurationsschritte auch auf dem Slave-Computer. Nachdem Sie Hadoop auf beiden Systemen installiert und konfiguriert haben, müssen Sie beim Starten Ihres Hadoop-Clusters zuerst formatieren das hadoop-Dateisystem , das auf den lokalen Dateisystemen Ihres Clusters implementiert wird. Dies ist bei der erstmaligen Hadoop-Installation erforderlich. Formatieren Sie kein laufendes Hadoop-Dateisystem, dadurch werden alle Ihre HDFS-Daten gelöscht.
Auf Meister
cd
cd hadoop-2.7.3/bin
hadoop namenode -format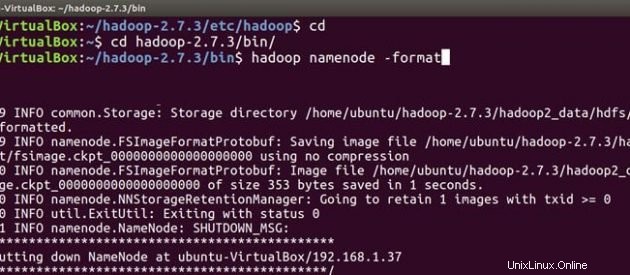
Wir sind jetzt bereit, die Hadoop-Daemons zu starten, d. h. NameNode, DataNode, ResourceManager und NodeManager auf unserem Apache Hadoop Cluster.
cd ..Führen Sie nun den folgenden Befehl aus, um NameNode auf dem Master-Computer und DataNodes auf Master und Slave zu starten.
sbin/start-dfs.sh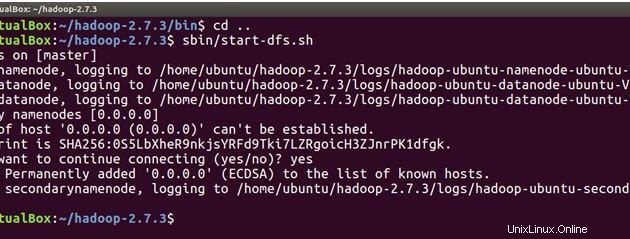
Der folgende Befehl startet YARN-Daemons, ResourceManager wird auf Master ausgeführt und NodeManagers werden auf Master und Slave ausgeführt.
sbin/start-yarn.sh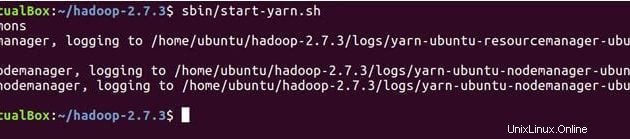
Überprüfen Sie mit JPS (Java Process Monitoring Tool), ob alle Dienste korrekt gestartet wurden. sowohl auf dem Master- als auch auf dem Slave-Rechner.
Unten sind die Daemons aufgeführt, die auf dem Master-Rechner laufen.
jps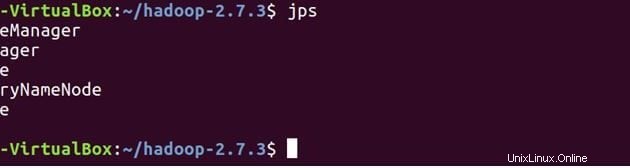
Auf Sklave
Sie werden sehen, dass DataNode und NodeManager auch auf dem Slave-Rechner laufen.
jps
Öffnen Sie nun Ihren Mozilla-Browser auf dem Master-Rechner und gehen Sie zur folgenden URL
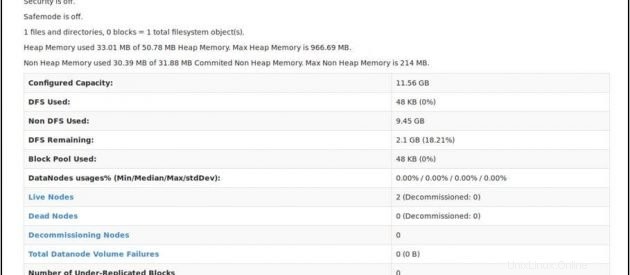
Überprüfen Sie den NameNode-Status:http://master:50070/dfshealth.html
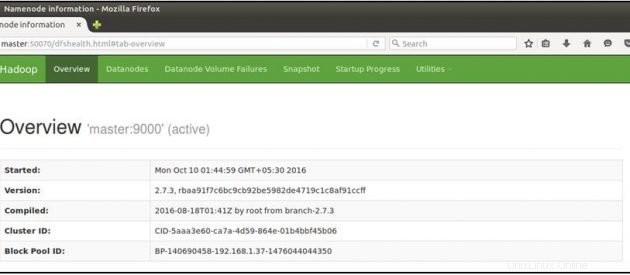
Wenn Sie '2' sehen in Live-Knoten , das bedeutet 2 DataNodes sind betriebsbereit und Sie haben erfolgreich einen Hadoop-Culster mit mehreren Knoten eingerichtet.
Schlussfolgerung
Sie können Ihrem Hadoop-Cluster weitere Knoten hinzufügen. Sie müssen lediglich die neue Slave-Knoten-IP zur Slave-Datei auf dem Master hinzufügen, den SSH-Schlüssel auf den neuen Slave-Knoten kopieren, die Master-IP in die Master-Datei auf dem neuen Slave-Knoten einfügen und dann neu starten Hadoop-Dienste. Herzliche Glückwünsche!! Sie haben erfolgreich einen Hadoop-Cluster mit mehreren Knoten eingerichtet.