Wenn Sie Daten haben, die nicht für eine relationale Datenbank geeignet sind, suchen Sie wahrscheinlich nach einer NoSQL-Lösung. NoSQL-Optionen sind vielfältig, Aerospike, MongoDB, Redis und viele andere versuchen, Big-Data-Probleme auf unterschiedliche Weise zu lösen. In diesem Artikel konzentrieren wir uns auf die Replikation mit cassandra. Diese Datenbank hat den Namen eigentlich aus der griechischen Mythologie, Kassandra war die Seherin, die die Zukunft immer richtig vorhergesagt hat, aber alle haben ihr nicht geglaubt. Die Ersteller dieser Datenbank sagen also voraus, dass NoSQL in Zukunft die relationalen Datenbanken ersetzen wird, aber sie erwarten nicht, dass RDBMS-Leute ihnen glauben.
Anforderungen
Um diesem Artikel zu folgen, sollten Sie 3 Knoten nacheinander mit unserem vorherigen Cassandra-Setup-Leitfaden eingerichtet haben. Sie sollten alle drei Knoten betriebsbereit haben und drei Terminalfenster mit jeweils einer SSH-Sitzung. Danach beginnen wir damit, die Cassandra-Knoten zu einem Cluster zu verbinden.
Aufbau eines Clusters
Als Cassandra-Benutzer angemeldet, müssen Sie die Cassandra-Konfiguration in jedem der drei Knoten bearbeiten. Die Datei heißt cassandra.yaml
nano ~/conf/cassandra.yamlDies muss auf allen 3 Servern konfiguriert werden. Die Samenlinie kann in einen Server eingegeben und dann kopiert werden, aber IP-Adressen von jedem Server müssen echt eingegeben werden.
cluster_name: 'Test Cluster'
seed_provider:
- class_name: org.apache.cassandra.locator.SimpleSeedProvider
parameters:
- seeds: "your-server-ip,your-server-ip-2,your-server-ip-3"
listen_address: your-server-ip
rpc_address: your-server-ipUm Entpoint Snitch einzurichten, fügen Sie diesen Oneliner in alle drei Knoten ein:
sed -i 's/endpoint_snitch: SimpleSnitch/endpoint_snitch: GossipingPropertyFileSnitch/g' ~/conf/cassandra.yamlUnd verwenden Sie diesen Befehl, um die Bootstrap-Zeile an das Ende der Datei anzuhängen.
echo 'auto_bootstrap: false' >> ~/conf/cassandra.yamlDer von uns eingerichtete Snitch hat einen inkompatiblen Rechenzentrumsnamen, dc1 anstelle von datacenter1, also können wir das auf allen drei Knoten beheben:
sed -i 's/dc=dc1/dc=datacenter1/g' ~/conf/cassandra-rackdc.propertiesStarten Sie bei Bedarf alle drei Knoten neu, und danach sollte der Status von sh bin/nodetool etwa so aussehen:
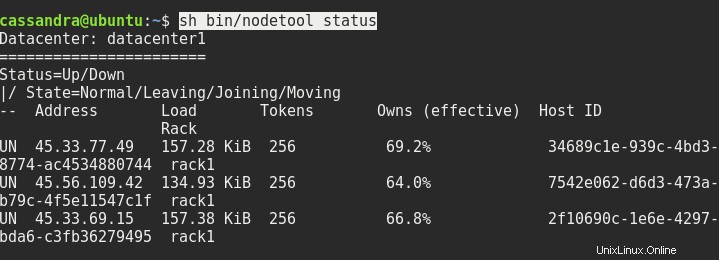
Als nächstes müssen wir eine Verbindung zur Konsole von einem der Knoten zum anderen Knoten herstellen. Wir müssen die Adresse des Servers und Port 9042 nach cqlsh wie folgt eingeben:
cqlsh ip.addr.of.node 9042Die lokale Host-Anmeldung nur mit cqlsh funktioniert nicht.
Replikationseinrichtung
Wenn Sie sich fragen, warum wir die Standard-Snitch-Konfiguration geändert haben, werde ich es jetzt erklären. Bei Cassandra gibt es im Allgemeinen zwei Replikationsstrategien. SimpleStrategy und NetworkTopologyStrategy. Der erste verwendet den Standard-Schnatz, der zweite den von uns eingestellten Schnatz. Wir brauchen diese fortschrittliche Strategie, wenn wir eine einfache Skalierung des Clusters haben wollen. Mit dieser Strategie können Sie weitere Knoten in einem anderen Rechenzentrum hinzufügen und den Cluster über die ganze Welt verteilen.
In der cqlsh-Konsole müssen wir also Folgendes eingeben:
CREATE KEYSPACE linoxide WITH replication = {'class': 'NetworkTopologyStrategy', 'datacenter1' : 3};Es wird einen neuen Schlüsselraum namens linoxide erstellen, wobei die Replikation mit NetworkTopologyStrategy festgelegt ist, und es werden 3 Replikate in datacenter1 erstellt.
Ok, dann sehen wir uns an, was wir geschaffen haben. Der Befehl ist fett, Rest wird ausgegeben.
SELECT * FROM system_schema.keyspaces;
keyspace_name | durable_writes | replication
--------------------+----------------+---------------------------------------------------------------------------------------
linoxide | True | {'class': 'org.apache.cassandra.locator.NetworkTopologyStrategy', 'datacenter1': '3'}
system_auth | True | {'class': 'org.apache.cassandra.locator.SimpleStrategy', 'replication_factor': '1'}
system_schema | True | {'class': 'org.apache.cassandra.locator.LocalStrategy'}
system_distributed | True | {'class': 'org.apache.cassandra.locator.SimpleStrategy', 'replication_factor': '3'}
system | True | {'class': 'org.apache.cassandra.locator.LocalStrategy'}
system_traces | True | {'class': 'org.apache.cassandra.locator.SimpleStrategy', 'replication_factor': '2'}Beenden wir cqlsh und führen Sie den nodetool-Befehl erneut aus, um die Änderungen im Cluster zu sehen.
nodetool status
Datacenter: datacenter1
=======================
Status=Up/Down
|/ State=Normal/Leaving/Joining/Moving
-- Address Load Tokens Owns (effective) Host ID Rack
UN 45.33.77.49 250.7 KiB 256 100.0% 34689c1e-939c-4bd3-8774-ac4534880744 rack1
UN 45.56.109.42 188.02 KiB 256 100.0% 7542e062-d6d3-473a-b79c-4f5e11547c1f rack1
UN 45.33.69.15 236.58 KiB 256 100.0% 2f10690c-1e6e-4297-bda6-c3fb36279495 rack1Beachten Sie, dass jeder Knoten jetzt über 100 % der Daten verfügt, gegenüber 66 % zuvor. Das liegt an dem von uns eingestellten Replikationsfaktor 3, wir haben jetzt eine Kopie der Daten auf jedem Knoten.
Schlussfolgerung
Dort haben wir also den Cassandra-Cluster mit Replikation eingerichtet. Von hier aus können Sie weitere Knoten, Racks und Rechenzentren hinzufügen, Sie können beliebige Datenmengen importieren und den Replikationsfaktor in allen oder einigen Rechenzentren ändern. Informationen dazu finden Sie in der offiziellen Cassandra-Dokumentation. Ich hoffe, dass dieser Leitfaden Ihnen geholfen hat, in die Zukunft der Datenbanktechnologie einzutauchen, und dass Sie sich entschieden haben, Cassandra zu glauben. Vielen Dank fürs Lesen und einen schönen Tag noch.