Einführung
Alle großen Branchen implementieren Apache Hadoop als Standard-Framework für die Verarbeitung und Speicherung von Big Data. Hadoop ist für den Einsatz in einem Netzwerk mit Hunderten oder sogar Tausenden von dedizierten Servern konzipiert. Alle diese Maschinen arbeiten zusammen, um die enorme Menge und Vielfalt der eingehenden Datensätze zu bewältigen.
Die Bereitstellung von Hadoop-Diensten auf einem einzelnen Knoten ist eine großartige Möglichkeit, sich mit grundlegenden Hadoop-Befehlen und -Konzepten vertraut zu machen.
Dieser leicht verständliche Leitfaden hilft Ihnen bei der Installation von Hadoop auf Ubuntu 18.04 oder Ubuntu 20.04.

Voraussetzungen
- Zugriff auf ein Terminalfenster/eine Befehlszeile
- Sudo oder root Privilegien auf lokalen /Remote-Rechnern
Installieren Sie OpenJDK auf Ubuntu
Das Hadoop-Framework ist in Java geschrieben, und seine Dienste erfordern eine kompatible Java Runtime Environment (JRE) und ein Java Development Kit (JDK). Verwenden Sie den folgenden Befehl, um Ihr System zu aktualisieren, bevor Sie eine neue Installation starten:
sudo apt updateIm Moment unterstützt Apache Hadoop 3.x Java 8 vollständig . Das OpenJDK 8-Paket in Ubuntu enthält sowohl die Laufzeitumgebung als auch das Entwicklungskit.
Geben Sie den folgenden Befehl in Ihr Terminal ein, um OpenJDK 8 zu installieren:
sudo apt install openjdk-8-jdk -yDie Java-Version von OpenJDK oder Oracle kann beeinflussen, wie Elemente eines Hadoop-Ökosystems interagieren. Um eine bestimmte Java-Version zu installieren, lesen Sie unsere ausführliche Anleitung zur Installation von Java unter Ubuntu.
Überprüfen Sie nach Abschluss des Installationsvorgangs die aktuelle Java-Version:
java -version; javac -versionDie Ausgabe informiert Sie darüber, welche Java-Edition verwendet wird.

Einen Nicht-Root-Benutzer für die Hadoop-Umgebung einrichten
Es ist ratsam, speziell für die Hadoop-Umgebung einen Nicht-Root-Benutzer zu erstellen. Ein eindeutiger Benutzer verbessert die Sicherheit und hilft Ihnen, Ihren Cluster effizienter zu verwalten. Um das reibungslose Funktionieren der Hadoop-Dienste zu gewährleisten, sollte der Benutzer die Möglichkeit haben, eine passwortlose SSH-Verbindung mit dem localhost herzustellen.
Installieren Sie OpenSSH auf Ubuntu
Installieren Sie den OpenSSH-Server und -Client mit dem folgenden Befehl:
sudo apt install openssh-server openssh-client -yIm Beispiel unten bestätigt die Ausgabe, dass die neueste Version bereits installiert ist.

Wenn Sie OpenSSH zum ersten Mal installiert haben, nutzen Sie diese Gelegenheit, um diese wichtigen SSH-Sicherheitsempfehlungen umzusetzen.
Hadoop-Benutzer erstellen
Verwenden Sie den adduser Befehl zum Erstellen eines neuen Hadoop-Benutzers:
sudo adduser hdoopDer Benutzername lautet in diesem Beispiel hdoop . Es steht Ihnen frei, jeden Benutzernamen und jedes Passwort zu verwenden, die Sie für richtig halten. Wechseln Sie zum neu erstellten Benutzer und geben Sie das entsprechende Passwort ein:
su - hdoopDer Benutzer muss jetzt in der Lage sein, sich per SSH mit dem localhost zu verbinden, ohne zur Eingabe eines Passworts aufgefordert zu werden.
Kennwortloses SSH für Hadoop-Benutzer aktivieren
Generieren Sie ein SSH-Schlüsselpaar und definieren Sie den Ort, an dem gespeichert werden soll:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsaDas System fährt mit der Generierung und Speicherung des SSH-Schlüsselpaars fort.
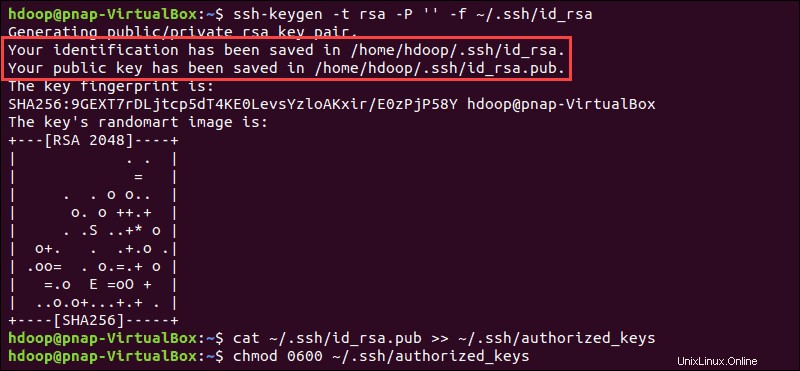
Verwenden Sie die cat Befehl zum Speichern des öffentlichen Schlüssels als authorized_keys im ssh Verzeichnis:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
Legen Sie die Berechtigungen für Ihren Benutzer mit chmod fest Befehl:
chmod 0600 ~/.ssh/authorized_keysDer neue Benutzer kann jetzt SSH verwenden, ohne jedes Mal ein Passwort eingeben zu müssen. Vergewissern Sie sich, dass alles richtig eingerichtet ist, indem Sie hdoop verwenden Benutzer zu SSH zu localhost:
ssh localhostNach einer ersten Aufforderung kann der Hadoop-Benutzer nun nahtlos eine SSH-Verbindung zum localhost herstellen.
Hadoop unter Ubuntu herunterladen und installieren
Besuchen Sie die offizielle Apache Hadoop-Projektseite und wählen Sie die Version von Hadoop aus, die Sie implementieren möchten.
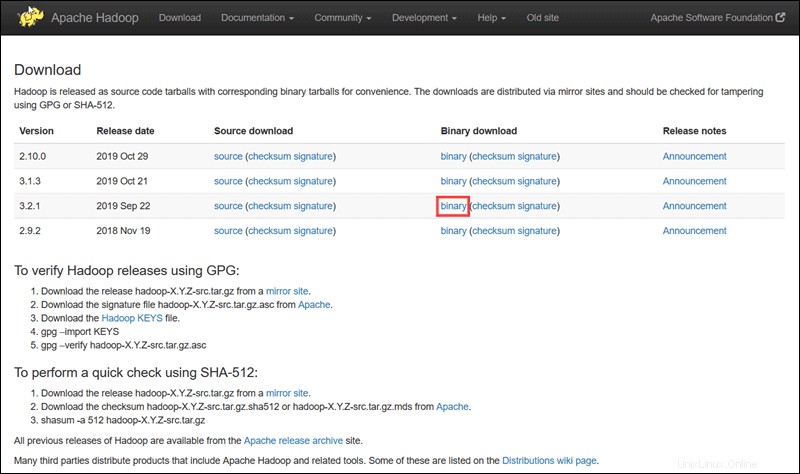
Die in diesem Tutorial beschriebenen Schritte verwenden den binären Download für Hadoop Version 3.2.1 .
Wählen Sie Ihre bevorzugte Option aus und Sie erhalten einen Mirror-Link, über den Sie das Hadoop-Tar-Paket herunterladen können .
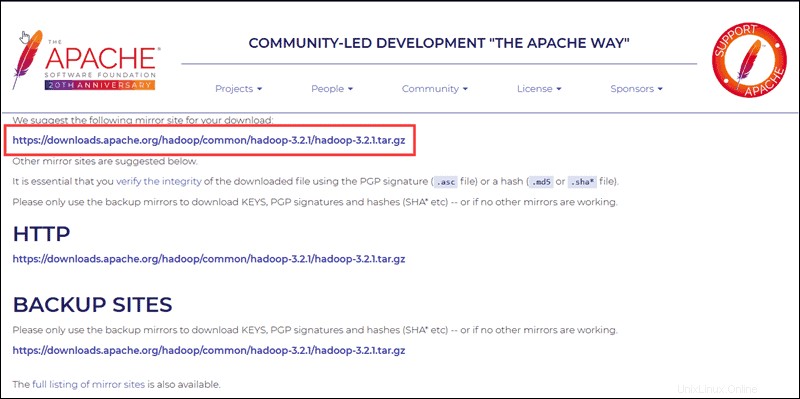
Verwenden Sie den bereitgestellten Mirror-Link und laden Sie das Hadoop-Paket mit wget herunter Befehl:
wget https://downloads.apache.org/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz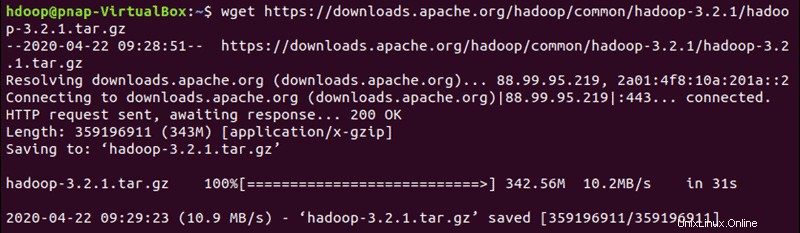
Extrahieren Sie nach Abschluss des Downloads die Dateien, um die Hadoop-Installation zu starten:
tar xzf hadoop-3.2.1.tar.gzDie Hadoop-Binärdateien befinden sich jetzt in hadoop-3.2.1 Verzeichnis.
Einzelknoten-Hadoop-Bereitstellung (Pseudo-Verteilter Modus)
Hadoop zeichnet sich aus, wenn es in einem vollständig verteilten Modus bereitgestellt wird auf einem großen Cluster vernetzter Server. Wenn Sie jedoch neu bei Hadoop sind und grundlegende Befehle ausprobieren oder Anwendungen testen möchten, können Sie Hadoop auf einem einzelnen Knoten konfigurieren.
Dieses Setup wird auch als pseudoverteilter Modus bezeichnet , ermöglicht es jedem Hadoop-Daemon, als einzelner Java-Prozess ausgeführt zu werden. Eine Hadoop-Umgebung wird durch Bearbeiten einer Reihe von Konfigurationsdateien konfiguriert:
- bashrc
- hadoop-env.sh
- core-site.xml
- hdfs-site.xml
- mapred-site-xml
- yarn-site.xml
Hadoop-Umgebungsvariablen konfigurieren (bashrc)
Bearbeiten Sie die .bashrc Shell-Konfigurationsdatei mit einem Texteditor Ihrer Wahl (wir verwenden nano):
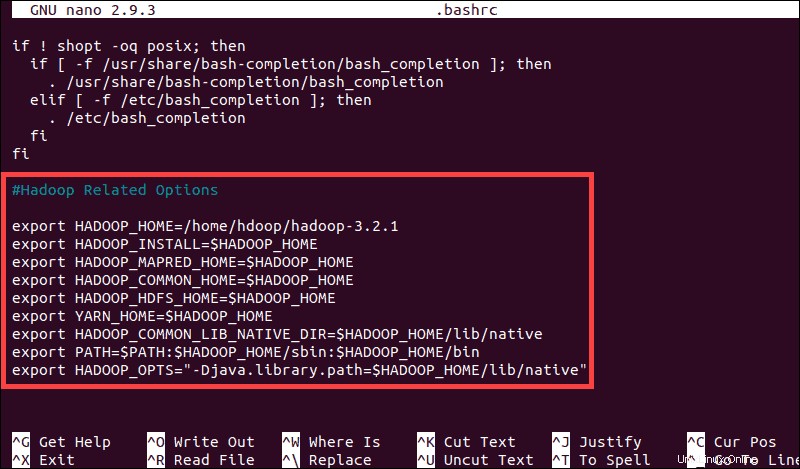
sudo nano .bashrcDefinieren Sie die Hadoop-Umgebungsvariablen, indem Sie den folgenden Inhalt am Ende der Datei hinzufügen:
#Hadoop Related Options
export HADOOP_HOME=/home/hdoop/hadoop-3.2.1
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS"-Djava.library.path=$HADOOP_HOME/lib/nativ"
Nachdem Sie die Variablen hinzugefügt haben, speichern und beenden Sie die .bashrc Datei.
Es ist wichtig, die Änderungen mit dem folgenden Befehl auf die aktuelle Ausführungsumgebung anzuwenden:
source ~/.bashrcHadoop-env.sh-Datei bearbeiten
Die hadoop-env.sh dient als Masterdatei zum Konfigurieren von YARN-, HDFS-, MapReduce- und Hadoop-bezogenen Projekteinstellungen.
Beim Einrichten eines Hadoop-Clusters mit einem Knoten müssen Sie festlegen, welche Java-Implementierung verwendet werden soll. Verwenden Sie das zuvor erstellte $HADOOP_HOME Variable für den Zugriff auf hadoop-env.sh Datei:
sudo nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
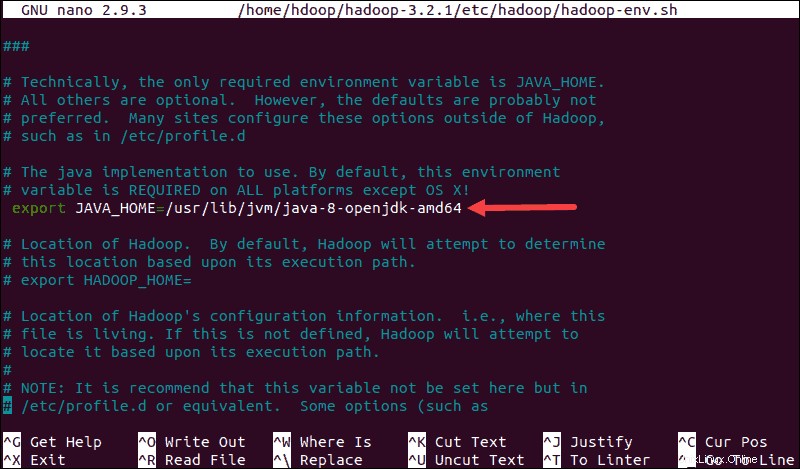
Entkommentieren Sie $JAVA_HOME -Variable (d. h. entfernen Sie die # Zeichen) und fügen Sie den vollständigen Pfad zur OpenJDK-Installation auf Ihrem System hinzu. Wenn Sie die gleiche Version wie im ersten Teil dieses Tutorials installiert haben, fügen Sie die folgende Zeile hinzu:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64Der Pfad muss mit dem Speicherort der Java-Installation auf Ihrem System übereinstimmen.
Wenn Sie Hilfe benötigen, um den richtigen Java-Pfad zu finden, führen Sie den folgenden Befehl in Ihrem Terminalfenster aus:
which javacDie resultierende Ausgabe liefert den Pfad zum Java-Binärverzeichnis.

Verwenden Sie den bereitgestellten Pfad, um das OpenJDK-Verzeichnis mit dem folgenden Befehl zu finden:
readlink -f /usr/bin/javac
Der Pfadabschnitt kurz vor /bin/javac Verzeichnis muss dem $JAVA_HOME zugewiesen werden Variable.

core-site.xml-Datei bearbeiten
Die core-site.xml Datei definiert HDFS- und Hadoop-Core-Eigenschaften.
Um Hadoop in einem pseudoverteilten Modus einzurichten, müssen Sie die URL angeben für Ihren NameNode und das temporäre Verzeichnis, das Hadoop für den Zuordnungs- und Reduzierungsprozess verwendet.
Öffnen Sie die core-site.xml Datei in einem Texteditor:
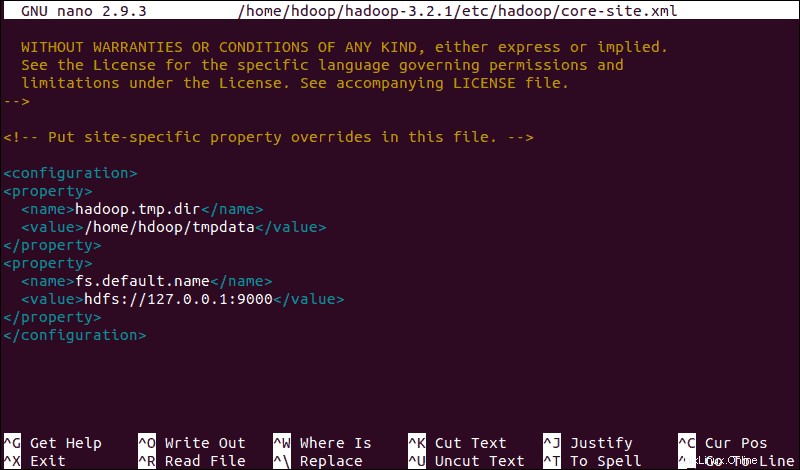
sudo nano $HADOOP_HOME/etc/hadoop/core-site.xmlFügen Sie die folgende Konfiguration hinzu, um die Standardwerte für das temporäre Verzeichnis zu überschreiben, und fügen Sie Ihre HDFS-URL hinzu, um die Standardeinstellung des lokalen Dateisystems zu ersetzen:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hdoop/tmpdata</value>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://127.0.0.1:9000</value>
</property>
</configuration>Dieses Beispiel verwendet für das lokale System spezifische Werte. Sie sollten Werte verwenden, die Ihren Systemanforderungen entsprechen. Die Daten müssen während des gesamten Konfigurationsprozesses konsistent sein.
Vergessen Sie nicht, ein Linux-Verzeichnis an dem Ort zu erstellen, den Sie für Ihre temporären Daten angegeben haben.
HDFS-Site.xml-Datei bearbeiten
Die Eigenschaften in der hdfs-site.xml Datei bestimmen den Speicherort zum Speichern von Knotenmetadaten, fsimage-Datei und Bearbeitungsprotokolldatei. Konfigurieren Sie die Datei, indem Sie den NameNode definieren und DataNode-Speicherverzeichnisse .
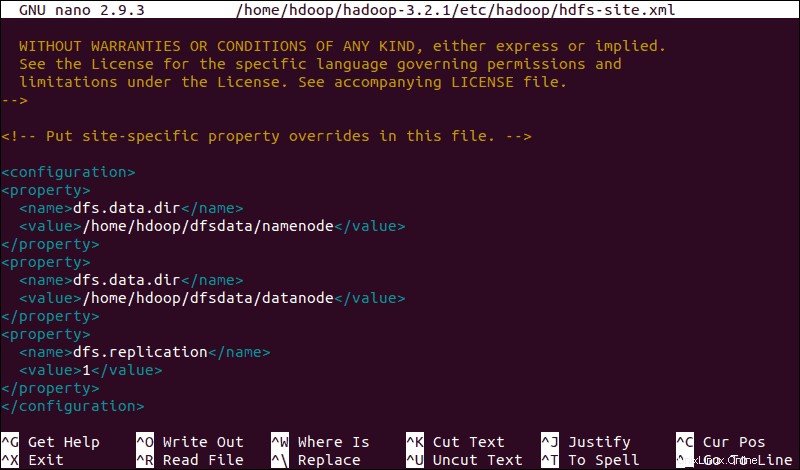
Darüber hinaus wird die standardmäßige dfs.replication Wert von 3 muss in 1 geändert werden um dem Single-Node-Setup zu entsprechen.
Verwenden Sie den folgenden Befehl, um die hdfs-site.xml zu öffnen Datei zum Bearbeiten:
sudo nano $HADOOP_HOME/etc/hadoop/hdfs-site.xmlFügen Sie der Datei die folgende Konfiguration hinzu und passen Sie bei Bedarf die Verzeichnisse NameNode und DataNode an Ihre benutzerdefinierten Speicherorte an:
<configuration>
<property>
<name>dfs.data.dir</name>
<value>/home/hdoop/dfsdata/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hdoop/dfsdata/datanode</value>
</property>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
Erstellen Sie bei Bedarf die spezifischen Verzeichnisse, die Sie für dfs.data.dir definiert haben Wert.
mapred-site.xml-Datei bearbeiten
Verwenden Sie den folgenden Befehl, um auf die mapred-site.xml zuzugreifen Datei und MapReduce-Werte definieren :
sudo nano $HADOOP_HOME/etc/hadoop/mapred-site.xml
Fügen Sie die folgende Konfiguration hinzu, um den standardmäßigen Namenswert des MapReduce-Frameworks in yarn zu ändern :
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>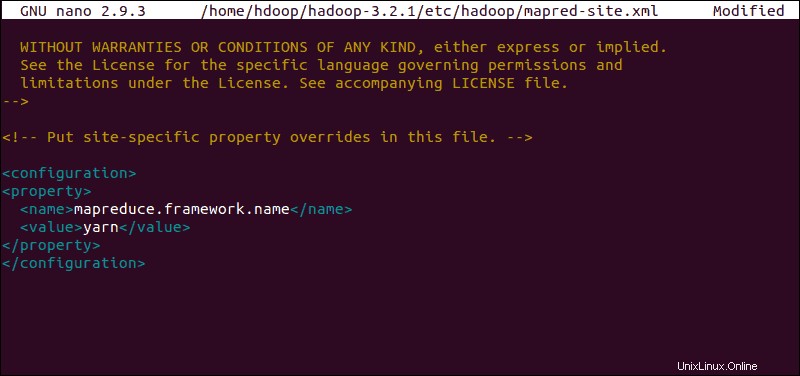
Yarn-Site.xml-Datei bearbeiten
Die yarn-site.xml Datei wird verwendet, um Einstellungen zu definieren, die für YARN relevant sind . Es enthält Konfigurationen für Node Manager, Resource Manager, Container und Anwendungsmaster .
Öffnen Sie die yarn-site.xml Datei in einem Texteditor:
sudo nano $HADOOP_HOME/etc/hadoop/yarn-site.xmlHängen Sie die folgende Konfiguration an die Datei an:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>127.0.0.1</value>
</property>
<property>
<name>yarn.acl.enable</name>
<value>0</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PERPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
</configuration>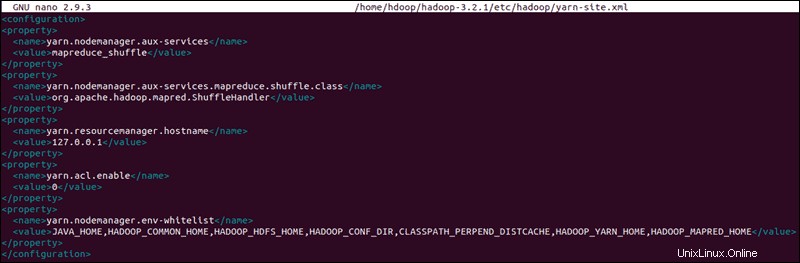
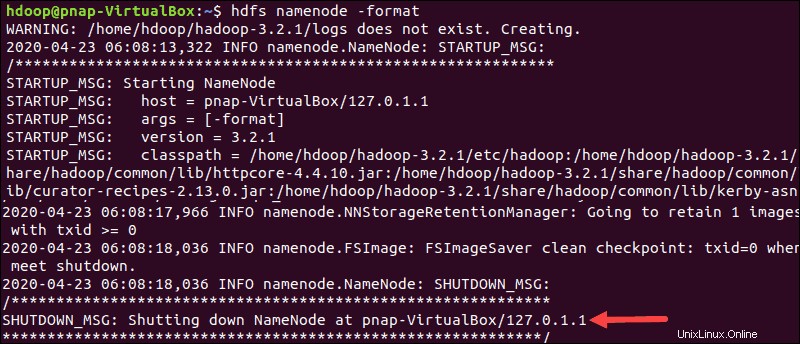
HDFS-NameNode formatieren
Es ist wichtig, den NameNode zu formatieren vor dem ersten Start von Hadoop-Diensten:
hdfs namenode -formatDie Shutdown-Benachrichtigung zeigt das Ende des NameNode-Formatierungsprozesses an.
Hadoop-Cluster starten
Navigieren Sie zu hadoop-3.2.1/sbin Verzeichnis und führen Sie die folgenden Befehle aus, um NameNode und DataNode zu starten:
./start-dfs.shDas System benötigt einen Moment, um die erforderlichen Knoten zu initiieren.

Sobald der Namensknoten, die Datenknoten und der sekundäre Namensknoten betriebsbereit sind, starten Sie die YARN-Ressource und die Knotenmanager, indem Sie Folgendes eingeben:
./start-yarn.shWie beim vorherigen Befehl informiert Sie die Ausgabe darüber, dass die Prozesse gestartet werden.

Geben Sie diesen einfachen Befehl ein, um zu prüfen, ob alle Daemons aktiv sind und als Java-Prozesse ausgeführt werden:
jpsWenn alles wie vorgesehen funktioniert, enthält die resultierende Liste der laufenden Java-Prozesse alle HDFS- und YARN-Daemons.

Zugriff auf die Hadoop-Benutzeroberfläche über den Browser
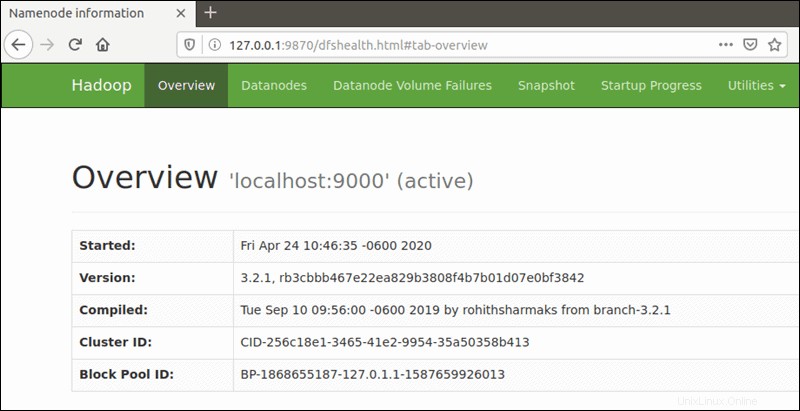
Verwenden Sie Ihren bevorzugten Browser und navigieren Sie zu Ihrer Localhost-URL oder -IP. Die Standardportnummer 9870 gibt Ihnen Zugriff auf die Benutzeroberfläche von Hadoop NameNode:
http://localhost:9870Die NameNode-Benutzeroberfläche bietet einen umfassenden Überblick über den gesamten Cluster.
Der Standardport 9864 wird verwendet, um direkt von Ihrem Browser aus auf einzelne DataNodes zuzugreifen:
http://localhost:9864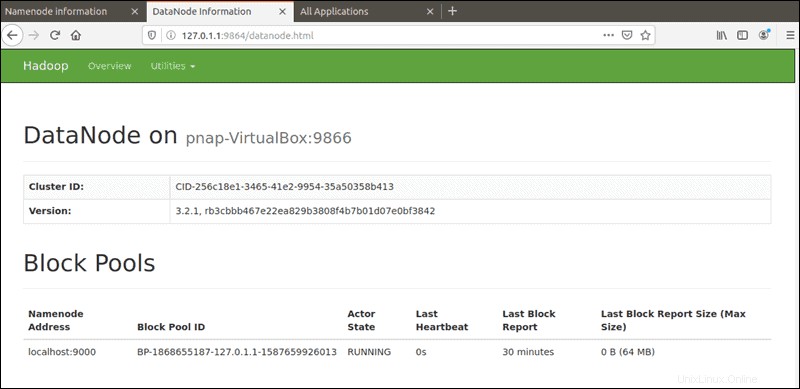
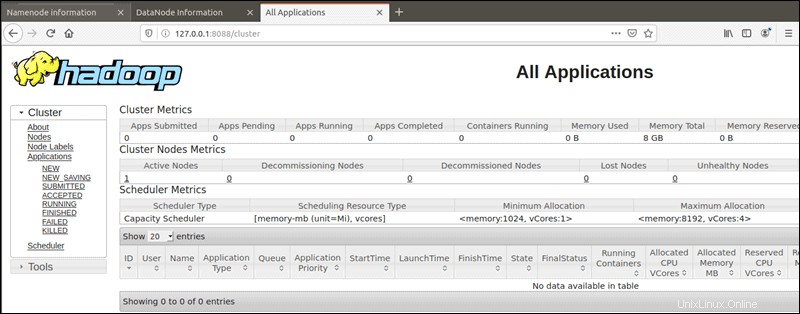
Auf den YARN-Ressourcenmanager kann über Port 8088 zugegriffen werden :
http://localhost:8088Der Ressourcenmanager ist ein unschätzbares Tool, mit dem Sie alle laufenden Prozesse in Ihrem Hadoop-Cluster überwachen können.