Einführung
Ein Spark DataFrame ist eine integrierte Datenstruktur mit einer benutzerfreundlichen API zur Vereinfachung der verteilten Big-Data-Verarbeitung. DataFrame ist für allgemeine Programmiersprachen wie Java, Python und Scala verfügbar.
Es ist eine Erweiterung der Spark-RDD-API, die dafür optimiert ist, Code effizienter zu schreiben und gleichzeitig leistungsstark zu bleiben.
In diesem Artikel wird erläutert, was Spark DataFrame ist, welche Funktionen es gibt und wie Spark DataFrame beim Sammeln von Daten verwendet wird.

Voraussetzungen
- Spark installiert und konfiguriert (Folgen Sie unserer Anleitung:So installieren Sie Spark unter Ubuntu, So installieren Sie Spark unter Windows 10).
- Eine Umgebung, die für die Verwendung von Spark in Java, Python oder Scala konfiguriert ist (dieses Handbuch verwendet Python).
Was ist ein DataFrame?
Ein DataFrame ist eine Programmierabstraktion im Spark-SQL-Modul. DataFrames ähneln relationalen Datenbanktabellen oder Excel-Tabellen mit Kopfzeilen:Die Daten befinden sich in Zeilen und Spalten unterschiedlicher Datentypen.
Die Verarbeitung erfolgt mithilfe komplexer benutzerdefinierter Funktionen und bekannter Datenbearbeitungsfunktionen wie Sortieren, Verbinden, Gruppieren usw.
Die Informationen für verteilte Daten sind in Schemata strukturiert . Jede Spalte in einem DataFrame enthält die Spalte name , Datentyp, und nullable Eigenschaften. Wenn nullable auf true gesetzt ist , akzeptiert eine Spalte null auch Eigenschaften.

Wie funktioniert ein DataFrame?
Die DataFrame-API ist Teil des Spark-SQL-Moduls. Die API bietet eine einfache Möglichkeit, mit Daten innerhalb des Spark SQL-Frameworks zu arbeiten und gleichzeitig in Allzwecksprachen wie Java, Python und Scala zu integrieren.
Während es Ähnlichkeiten mit Python Pandas und R-Datenrahmen gibt, macht Spark etwas anderes. Diese API ist maßgeschneidert für die Integration mit umfangreichen Daten für Data Science und maschinelles Lernen und bietet zahlreiche Optimierungen.
Spark DataFrames sind über mehrere Cluster verteilbar und mit Catalyst optimiert. Der Catalyst-Optimierer nimmt Abfragen (einschließlich auf DataFrames angewendete SQL-Befehle) und erstellt einen optimalen parallelen Berechnungsplan.
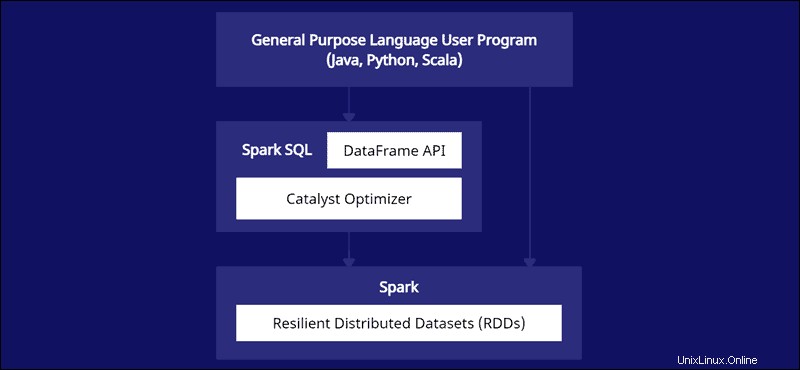
Wenn Sie Erfahrung mit Python- und R-Datenrahmen haben, kommt Ihnen der Spark DataFrame-Code bekannt vor. Wenn Sie andererseits Spark RDDs (Resilient Distributed Dataset) verwenden, bietet die Information über die Datenstruktur Optimierungsmöglichkeiten.
Die Entwickler von Spark haben DataFrames entwickelt, um Big-Data-Herausforderungen auf die effizienteste Weise zu bewältigen. Entwickler können die Leistungsfähigkeit von Distributed Computing mit vertrauten, aber optimierten APIs nutzen.
Funktionen von Spark DataFrames
Spark DataFrame bietet viele wertvolle Funktionen:
- Unterstützung für verschiedene Datenformate wie Hive, CSV, XML, JSON, RDDs, Cassandra, Parquet usw.
- Unterstützung für die Integration mit verschiedenen Big-Data-Tools.
- Die Fähigkeit, Kilobytes an Daten auf kleineren Maschinen und Petabytes auf Clustern zu verarbeiten.
- Catalyst-Optimierer für effiziente Datenverarbeitung in mehreren Sprachen.
- Strukturierte Datenverarbeitung durch schematische Datenansicht.
- Benutzerdefinierte Speicherverwaltung, um Überlastung zu reduzieren und die Leistung im Vergleich zu RDDs zu verbessern.
- APIs für Java, R, Python und Spark.
Wie erstellt man einen Spark DataFrame?
Es gibt mehrere Methoden zum Erstellen eines Spark DataFrame. Hier ist ein Beispiel dafür, wie Sie eines in Python mit der Jupyter-Notebook-Umgebung erstellen:
1. Initialisieren und erstellen Sie eine API-Sitzung:
#Add pyspark to sys.path and initialize
import findspark
findspark.init()
#Load the DataFrame API session into Spark and create a session
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()2. Spielzeugdaten als Liste von Wörterbüchern erstellen:
#Generate toy data using a dictionary list
data = [{"Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
{"Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
{"Category": 'C', "ID": 3, "Value": 10.99, "Truth": None},
{"Category": 'E', "ID": 4, "Value": 33.87, "Truth": True}
]
3. Erstellen Sie den DataFrame mit createDataFrame Funktion und übergeben Sie die data Liste:
#Create a DataFrame from the data list
df = spark.createDataFrame(data)4. Drucken Sie das Schema und die Tabelle aus, um den erstellten DataFrame anzuzeigen:
#Print the schema and view the DataFrame in table format
df.printSchema()
df.show()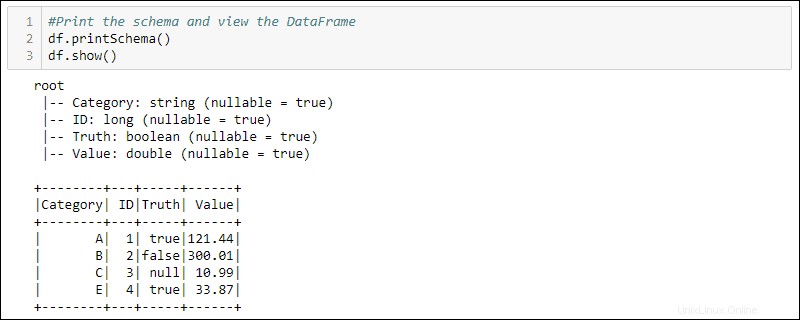
Verwendung von DataFrames
Die in einem DataFrame gespeicherten strukturierten Daten bieten zwei Manipulationsmethoden
- Domain-spezifische Sprache verwenden
- Verwenden von SQL-Abfragen.
Die nächsten beiden Methoden verwenden den DataFrame aus dem vorherigen Beispiel, um alle Zeilen auszuwählen, in denen die Spalte „Truth“ auf „true“ gesetzt ist, und sortieren die Daten nach der Spalte „Value“.
Methode 1:Verwendung domänenspezifischer Abfragen
Python bietet integrierte Methoden zum Filtern und Sortieren der Daten. Wählen Sie die spezifische Spalte mit df.<column name> aus :
df.filter(df.Truth == True).sort(df.Value).show()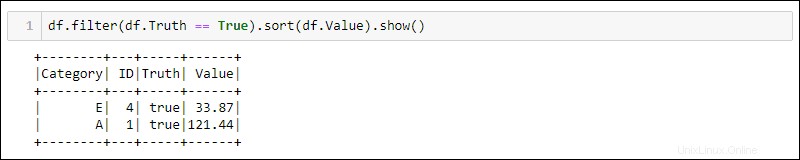
Methode 2:Verwenden von SQL-Abfragen
Um SQL-Abfragen mit dem DataFrame zu verwenden, erstellen Sie eine Ansicht mit createOrReplaceTempView integrierte Methode und führen Sie die SQL-Abfrage mit spark.sql aus Methode:
df.createOrReplaceTempView('table')
spark.sql('''SELECT * FROM table WHERE Truth=true ORDER BY Value ASC''')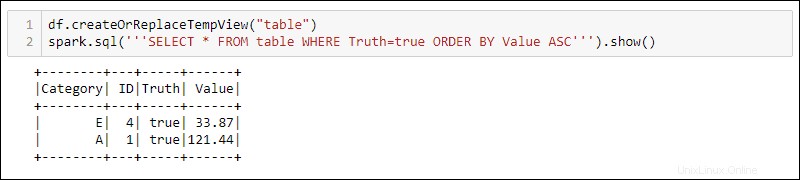
Die Ausgabe zeigt die SQL-Abfrageergebnisse, die auf die temporäre Ansicht des DataFrame angewendet wurden. Dies ermöglicht das Erstellen mehrerer Ansichten und Abfragen über dieselben Daten für eine komplexe Datenverarbeitung.