Einführung
Die Notwendigkeit, Big Data zu erfassen und zu verarbeiten, ist die Hauptantriebskraft für die Popularität von NoSQL-Datenbanken. Die gespeicherten Daten müssen jederzeit, von jedem Ort und auf jedem Gerät zugänglich sein. Eine Möglichkeit, der wachsenden Nachfrage gerecht zu werden, besteht darin, zu skalieren und einen größeren Server zu kaufen. Es ist jedoch effizienter, horizontal zu skalieren und einen Cluster von On-Demand-Servern zu verwenden.
Das relationale Datenbankmodell ist für ein verteiltes System, das sich über mehrere Maschinen erstreckt, nicht gut geeignet. NoSQL-Datenbanken bieten eine praktikable Lösung, indem sie sich auf Leistung und Verfügbarkeit konzentrieren und gleichzeitig einen Teil der Konsistenz opfern, die normalerweise mit relationalen Datenbanken identifiziert wird.
Neben der Beantwortung der Frage „Was ist NoSQL “, verwendet dieses Tutorial einfache Beispiele, um grundlegende NoSQL-Konzepte, -Features und -Typen hervorzuheben .

Was ist NoSQL? (NoSQL-Definition)
NoSQL (Not SQL oder Not Only SQL) ist ein Oberbegriff für Datenbanken, die nicht von einem relationalen Modell abhängen. Die Daten müssen weder ein strenges Schema noch die übliche SQL-Tabellenstruktur haben. Am häufigsten werden die Daten als Schlüssel-Wert-Paare, JSON-Dokumente, Diagramme aggregiert oderBreitspaltentabellen.
Durch die Verwendung von NoSQL-Datenbanken können Sie riesige Mengen an unstrukturierten Daten gleich beim Eingang speichern und zu einem späteren Zeitpunkt strukturieren. Wie erwartet führt dies zu viel besserem Durchsatz, Lese-/Schreibgeschwindigkeiten und ermöglicht Ihnen, Server horizontal zu skalieren.
Nicht relationale Datenbanken bringen, wenn sie in der richtigen Anwendungsfallumgebung eingesetzt werden, erhebliche Vorteile in Bezug auf Leistung und Flexibilität. Das Anwenden eines Schemas am Dateneingangspunkt bedeutet jedoch auch, dass es schwieriger ist, NoSQL-Datenbanken abzufragen, die Datenkonsistenz aufrechtzuerhalten und Beziehungen zwischen Datensätzen herzustellen.
So funktioniert NoSQL
Die Grundidee hinter NoSQL besteht darin, die Datenbankleistung für horizontale Skalierung, große Datenmengen und geringe Latenz zu optimieren, indem auf einige Einschränkungen der Datenkonsistenz verzichtet wird, die in RDBMS vorhanden sind. Statt starrer Datenmodelle wie Tabellen, Spalten oder Zeilen bieten NoSQL-Datenbanken flexible Modelle. In Anwendungsfällen, die keine relationale Konsistenz erfordern, tragen diese Modelle dazu bei, dass NoSQLs eine bessere Leistung erbringen als relationale Datenbanken.
Funktionen von NoSQL-Datenbanken
NoSQL-Datenbanken sind strukturell vielfältig und bieten verschiedene Datenspeichermodelle. Es gibt jedoch mehrere gemeinsame Attribute, die NoSQL von relationalen Datenbanken unterscheiden.
Schema beim Lesen
Mit einer NoSQL-Datenbank können Sie Daten speichern, bevor Sie eine Struktur anwenden oder Schema .
Das Schema wird vom Anwendungscode nur angewendet, wenn er auf Daten zugreift. Dieser Vorgang wird oft als Schema beim Lesen bezeichnet . Da Daten nicht im Voraus strukturiert werden, können NoSQL-Datenbanken immense Datenmengen erheblich schneller schreiben und lesen als eine relationale Datenbank.
NoSQL vs. relationale Datenbanken
Im Gegensatz dazu strukturiert ein relationales SQL-Modell eingehende Daten, bevor sie in eine Datenbank geschrieben werden. Vordefinierte Schemadesigns werden verwendet, um alle möglichen Datentypen im Voraus zu klassifizieren. Das Schema wird allgemein angewendet, da Daten in Tabellen, Spalten und Zeilen strukturiert und gespeichert werden.
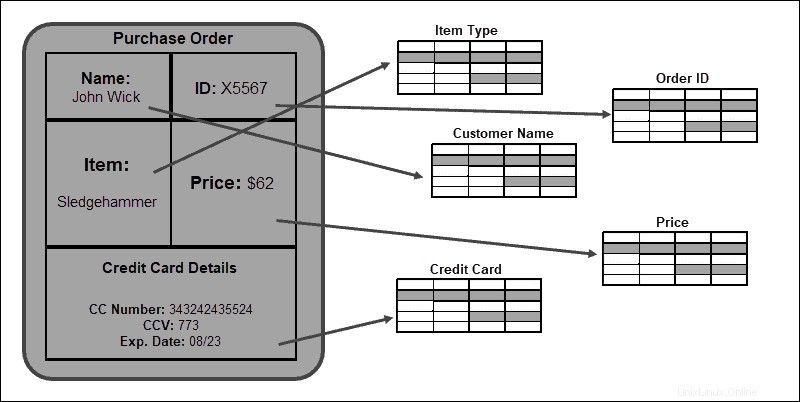
Die streng tabellarische Struktur ist von Vorteil, wenn Sie Beziehungen zwischen Tabellen und Datenbankelementen herstellen möchten. Durch die Einhaltung dieses Schemas wird die Konsistenz und Integrität der Daten gewährleistet.
Nicht relationales Datenmodell
NoSQL-Datenbanken stellen keine Beziehungen zwischen einzelnen Datensätzen her. Ein Datensatz wird normalerweise als einzelnes JSON-Dokument gespeichert und über mehrere Knoten in einem Cluster repliziert.
Wir verwenden ein einfaches Beispiel mit Daten über Musikbands. In einem nicht relationalen Modell die BandID , Bandname , Land , Genre , Label , AlbumID , Albumname, undVeröffentlichungsdatum Attribute werden in einem einzigen Radiohead gespeichert dokumentieren. Wenn Sie das Veröffentlichungsdatum des Radiohead-Albums suchen, OK Computer , die Antwort ist blitzschnell. Die Abfrage liefert viel schneller Ergebnisse, da sie Informationen nicht aus mehreren Tabellen abrufen muss (wie in relationalen Datenbanken), sondern aus einem einzigen Eintrag.
Die aggregierten Daten in einem Datensatz können nicht mit den aggregierten Daten in einem anderen Datensatz in Beziehung gesetzt werden. Jeder relevante Datensatz in der Datenbank muss aktualisiert werden, wenn Sie ein Attribut wie einen Streaming-Dienst hinzufügen möchten. NoSQL-Datenbanken eignen sich daher am besten für große Datenmengen, die nicht nachträglich strukturiert oder verknüpft werden müssen.
BASE vs. ACID
Muss eine Datenbank einen Vorgang abbrechen und die Datenkonsistenz im Falle eines Netzwerkausfalls sicherstellen? Oder sollten Datenbanken Dateninkonsistenzen riskieren, um Hochverfügbarkeit zu gewährleisten?
Der Hauptfokus von NoSQL liegt darauf, die Verfügbarkeit aufrechtzuerhalten, indem letztendlich Konsistenz geboten wird. Eventuelle Konsistenz ist Teil der BASE-Semantik. BASE gibt an, dass einmal geschriebene Daten schließlich zum Lesen erscheinen. Ohne starke Garantien haben Sie nur eine begrenzte Wahrscheinlichkeit, den aktuellen Stand zu kennen, da er möglicherweise noch nicht konvergiert ist. Wenn das System funktioniert und Sie nach einer gegebenen Reihe von Eingaben lange genug warten, werden Sie schließlich den wahren Zustand der Datenbank kennen.
Der Nachteil ist, dass Daten möglicherweise nicht bestehen bleiben, nachdem Konflikte beigelegt wurden. Ein Lesevorgang erhält möglicherweise für einen unbekannten Zeitraum nicht den letzten Schreibvorgang. Ein Facebook-Beitrag, der einige Minuten lang nicht angezeigt wird, ist akzeptabel, aber eine Finanztransaktion nicht sofort sehen zu können, ist ein erhebliches Problem.
SÄURE
- A Tomizität. Von einer Operation sind nur die angegebenen Daten betroffen.
- C Beständigkeit. Jede Operation versetzt die Datenbank von einem konsistenten Zustand in einen anderen konsistenten Zustand.
- Ich lösung. Ein Vorgang wirkt sich nicht auf andere gleichzeitige Vorgänge aus.
- D Haltbarkeit. Die Daten gehen nach einer erfolgreichen Transaktion nicht verloren.
BASIS
- B AsischA verfügbar. Schreib- und Leseoperationen sind so weit wie möglich verfügbar, jedoch ohne strenge Garantien.
- S Staat. Ohne Garantien wissen wir es nicht, haben aber die Erwartung, dass die Daten schließlich konsistent werden.
- E Endgültige Konsistenz. Wenn das System voll funktionsfähig ist und ein ausreichend langer Zeitraum vergangen ist, werden wir schließlich den wahren Zustand der Datenbank kennen.
Relationale Datenbanken konzentrieren sich auf Konsistenz als das wichtigere Merkmal, das beibehalten werden muss. Die Konsistenz Die Eigenschaft einer Datenbank stellt sicher, dass, wenn Sie einen Datensatz in eine Datenbank schreiben und diesen Datensatz dann sofort anfordern, Sie ihn garantiert sehen. Der Satz von ACID-Eigenschaften, der von relationalen Datenbanken angewendet wird, bedeutet, dass Sie nach dem Schreiben von Daten vollständige Konsistenz beim Lesen haben.
Erfahren Sie mehr über die beiden beliebtesten Datenbank-Transaktionsmodelle und ihre Unterschiede im Artikel ACID vs. BASE.
Horizontale Skalierung
Unternehmen haben effektive Wege gefunden, um aus Daten Kapital zu schlagen. Das schnelle Wachstum des Volumens, der Geschwindigkeit und der Vielfalt dieser Daten hat zu einer Flut von NoSQL-Datenbanken geführt.
Große Websites und Online-Plattformen mussten einige der Einschränkungen relationaler Datenbanken überwinden, wie z. B. Lese-/Schreibgeschwindigkeiten und die Notwendigkeit, Daten im Voraus zu normalisieren. Eine wesentliche Einschränkung ist die Inflexibilität des relationalen Modells wenn es um die Skalierung geht. In einem relationalen Modell werden Daten normalerweise nicht partitioniert oder getrennt. Stattdessen ist es auf einen einzelnen Knoten konzentriert, und Datenbanken können nur skaliert werden, indem die Leistung vorhandener Hardware erhöht wird.
NoSQL-Datenbanken sind für die effiziente Ausführung auf verteilten Systemen konzipiert die schnell horizontal skalieren. Ein verteiltes System hat den zusätzlichen Vorteil einer konstant hohen Verfügbarkeit. Mehrere Kopien eines Datensatzes werden über Server und Racks hinweg aufbewahrt, und ein Hardwareausfall beeinträchtigt die Datenverfügbarkeit nicht. Sie können problemlos Standardhardware anstelle teurer High-End-Server verwenden, um die steigende Datenlast zu bewältigen.
Arten von NoSQL-Datenbanken
Nichtrelationale Datenbankmodelle können grob in vier Kategorien eingeteilt werden.
- Ein Schlüsselwertspeicher ermöglicht es Ihnen, jede Art von Daten unter einem eindeutigen Schlüssel zu speichern.
- Eine Dokumentendatenbank verwendet einen ähnlichen Ansatz, indem verschiedene Datentypen in einem einzigen JSON- oder XML-Dokument zusammengefasst werden.
- Spaltenbasiert Basen speichern Daten unter einer Spalte Ihrer Wahl.
- Graphdatenbanken legen Kanten und Eigenschaften für Knoten fest, die Datenelemente darstellen.
Schlüsselwertdatenbanken
Schlüsselwertdatenbanken, manchmal auch als Schlüsselwertspeicher bezeichnet, verwenden das einfachste Datenmodell – die Paarung eines Schlüssels und eines Werts. Eine Anwendung ruft den Wert mithilfe des eindeutigen Schlüssels ab.
Der Wert kann eine beliebige Datenstruktur oder einen beliebigen Datentyp enthalten. Es liegt an der Anwendung, die versucht, auf die Daten zuzugreifen, um den Inhalt zu verstehen.
Beispiele für Schlüsselwertdatenbanken sind Redis, Riak , Aerospike und Oracle NoSQL .
Spaltenbasierte Datenbanken
Spaltenbasierte Datenbanken konzentrieren sich auf die Effizienz von Leseoperationen. Wenn Sie schnell mehrere Spalten mehrerer Zeilen lesen müssen, ist es sinnvoll, Daten in Gruppen von Spalten (d. h. Spaltenfamilien) zu organisieren.
Die Modellstruktur besteht aus einer Zeilenkennung das die aggregierten Daten und das Zeilenaggregat definiert, das aus detaillierteren Werten der sekundären Ebene (d. h. Spalten) besteht ).
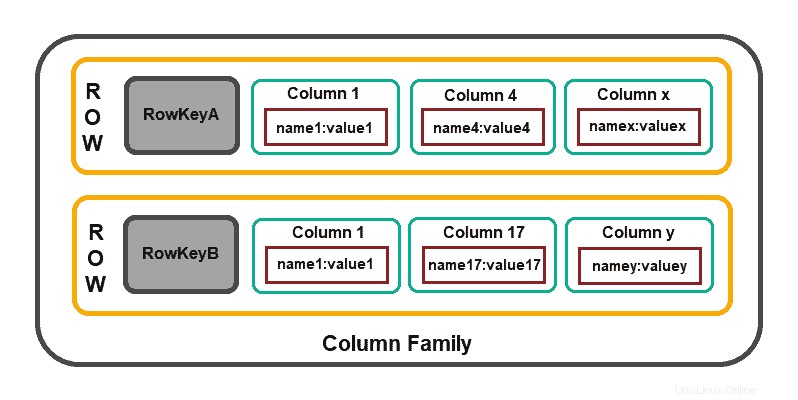
Kassandra , HBase , Amazon DynamoDB und Clickhouse , sind einige der weit verbreiteten spaltenbasierten Lösungen.
Dokumentendatenbanken
Dokumentdatenbanken speichern teilweise strukturierte Daten in Dokumenten unter Verwendung von JSON, BSON, XML oder anderen Formaten. Die Daten im Dokument sind halbstrukturiert, um mehr Flexibilität bei Abfragen zu bieten. Im Gegensatz zu einfachen Schlüsselwertspeichern muss der Benutzer nicht den gesamten Datensatz abrufen, sondern nur den relevanten Teil des Dokuments.

Webbasierte Dokumente, Benutzerkommentare und Web-Publishing-Apps profitieren alle von diesem Datenmodell. Berühmte dokumentbasierte NoSQLs sind MongoDB , OrientDB , Apache-CouchDB und MarkLogic .
Graph-Datenbanken
Graphdatenbanken organisieren Daten in Knoten, wobei Kanten Beziehungen zwischen diesen Datenknoten herstellen.
Dieses Datenspeichermodell hat sich in Anwendungen als nützlich erwiesen, die Beziehungen betonen, wie Social-Media-Plattformen, Kundenbeziehungssoftware und Reise- und Reservierungssysteme.
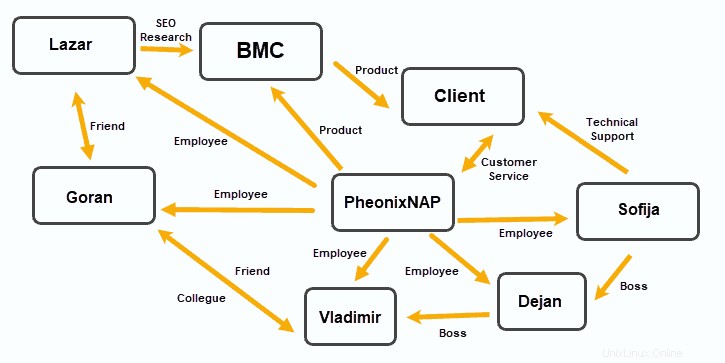
Dokumentbasierte OrientDB und MarkLogic können als Graphdatenbanken fungieren. JanusGraph , RedisGraph und Neo4j sind beliebte graphbasierte Lösungen.
NoSQL-Vorteile
- Leistung – NoSQL-Datenbanken bieten eine bessere Leistung in den Anwendungsfällen, die sich mit Daten befassen, die nicht stark relational sind. Ein NoSQL erwartet ein denormalisiertes Schema und optimiert die Lesevorgänge entsprechend.
- Flexibilität – Das dynamische Schema von NoSQL erleichtert die Speicherung unstrukturierter Daten auf optimale Weise für einen bestimmten Fall. Es ermöglicht die Erstellung von Dokumenten, ohne deren Struktur zu definieren.
- Skalierbarkeit – Während es möglich ist, RDBMS vertikal zu skalieren, indem der Arbeitsspeicher, die Speicherkapazität oder die Rechenleistung der Maschine aktualisiert werden, bietet NoSQL den zusätzlichen Vorteil der horizontalen Skalierung. Dies bedeutet, dass es möglich ist, eine Zunahme des Datenverkehrs zu bewältigen, indem die Datenbank mit zusätzlichen Servern aktualisiert wird.
Wann sollte NoSQL verwendet werden?
Der Versuch, eine einzige Datenbanklösung für alle möglichen Szenarien anzuwenden, ist keine gute Idee. Die verschiedenen Datenbanktypen, die in diesem Artikel behandelt werden, sind darauf ausgelegt, spezifische Datenprobleme zu lösen. Dies ist nicht auf NoSQL-Datenbanken beschränkt. Sogar relationale Datenbanken haben Schwierigkeiten, verschiedene Datentypen in einem strengen Schema zu standardisieren.
Das Innenleben relationaler Datenbanken ist gut dokumentiert und vorhersagbar. Die SQL-Sprache und der Satz von Tools, die mit relationaler Technologie erstellt wurden, sind allgegenwärtig, und erfahrene Mitarbeiter stehen jederzeit zur Verfügung. Das relationale Datenbankmodell ermöglicht es Ihnen, auf viele verschiedene und kreative Arten auf Daten zuzugreifen, ohne durch die Art der Datenspeicherung eingeschränkt zu sein.
Große Daten
Big Data und der Wert, so viel davon wie technisch möglich zu erfassen, sind keine geeignete Arbeitslast für das relationale Modell. Eine NoSQL-Datenbank, die kein strenges Schema verwendet, ist eine ausgezeichnete Wahl, um große Mengen sortierter und unstrukturierter Daten zu speichern.
Softwareentwicklung
Die Anwendungsentwicklung hat enorm von NoSQL-Datenbanken profitiert. Viele wertvolle Entwicklerstunden wurden verschwendet, um Daten zwischen In-Memory-Datenstrukturen und einer relationalen Datenbank abzubilden. Eine NoSQL-Datenbank bedeutet, dass Sie Ihr Modell erstellen, das auf die Anforderungen der darauf zugreifenden Anwendung zugeschnitten ist, und möglicherweise den erforderlichen Codierungsaufwand reduzieren.
Wenn eine Datenbank kein Schema hat, bedeutet dies, dass die Anwendung, die auf die Daten zugreift, eines haben muss. Dies kann schnell zu einem Problem werden, wenn mehr als eine Anwendung, die unabhängig voneinander entwickelt wurde, auf dieselbe Datenbank zugreifen muss.
Inkonsistenzen bei Lesevorgängen werden schließlich behoben, aber der Mangel an Konsistenz bei Schreibvorgängen ist ein ernstes Problem. Dieses Problem wird häufig gelöst, indem alle Datenbankinteraktionen auf eine einzige Anwendung beschränkt und diese mithilfe von Webdiensten in andere Anwendungen integriert werden. Diese Lösung passt gut zum allgemeinen Trend, Webdienste für Integrationszwecke zu verwenden.