Einführung
Datenbank mit mehreren Modellen Verwaltungssysteme vereinen mehrere Datenbanksysteme zu einem. Anstatt mit zahlreichen Modellen zu arbeiten und Wege zu finden, sie miteinander zu integrieren, bieten Multi-Modell-Datenbanken eine einzige Engine für verschiedene Datenbanktypen.
Dieser Artikel gibt einen detaillierten Überblick über Datenbanken mit mehreren Modellen.

Was ist eine Multi-Model-Datenbank?
Eine Multi-Modell-Datenbank ist ein Verwaltungssystem, das mehrere Datenbanktypen kombiniert mit einem einzelnen Backend. Die meisten Datenbankverwaltungssysteme unterstützen nur ein einziges Datenbankmodell. Andererseits speichern, fragen und indizieren Multi-Modell-Datenbanken Daten aus verschiedenen Modellen.
Datenbanken mit mehreren Modellen bieten die Modellierungsvorteile der polyglotten Persistenz ohne Wege finden zu müssen, verschiedene Modelle zu kombinieren. Der flexible Ansatz ermöglicht die Speicherung von Daten auf unterschiedliche Weise. Das Ergebnis ist:
- Agile und flexible Programmierung.
- Reduzierte Datenredundanz.
Beispielsweise ist es mit Graphdatenbanken viel einfacher, Beziehungen zwischen Datenpunkten zu untersuchen oder ein Empfehlungssystem aufzubauen. Andererseits helfen relationale Datenbanken dabei, Beziehungen zwischen Datenspalten zu definieren.
Eine wichtige Funktion von Datenbanken mit mehreren Modellen ist die Fähigkeit, Daten von einem Format in ein anderes umzuwandeln. Beispielsweise werden Daten im JSON-Format schnell in XML umgewandelt. Das Konvertieren von Datenformaten bietet zusätzliche Agilität und erleichtert die Erfüllung spezifischer Projektanforderungen.
Anwendungsbeispiele für Datenbanken mit mehreren Modellen
Anwendungsfälle helfen dabei, eine Vorstellung davon zu vermitteln, wie Multi-Modell-Datenbanken funktionieren. Die Analyse praktischer Beispiele bietet einen besseren Einblick, wie mehrere Modelle in einem System zusammenarbeiten.
Speichern und Verwalten mehrerer Datenquellen
Ein typisches IT-System verwendet verschiedene Datenquellen. Die gespeicherten Informationen liegen nicht immer im gleichen Format oder in der gleichen Datenbank vor. Mehrere Formate schaffen ein komplexes System, das es schwierig macht, Daten zu pflegen und zu durchsuchen.
Das Speichern von Daten in einer Multi-Modell-Datenbank erleichtert die Verwaltung. Alles befindet sich in einer Datenbank, was den Zeitaufwand für das Speichern und Verwalten von Daten aus verschiedenen Quellen reduziert.
Modellfunktionen erweitern
Datenbanken mit mehreren Modellen bieten Erweiterungen zwischen Modellen. Funktionen einiger Modelle tragen dazu bei, die Mängel anderer Modelle auszugleichen.
Beispielsweise ist das Abfragen von Daten im JSON-Format mithilfe von SQL-Abfragen einfach. Die ursprüngliche Datenquelle muss nicht angepasst werden. Die Erweiterbarkeit reduziert die Datenverarbeitungszeit und beseitigt die Notwendigkeit von Systemen zum Extrahieren, Transformieren und Laden (ETL).
Hybride Datenumgebungen
Eine typische Datenumgebung trennt Betriebsdaten von Analysedaten. Die Daten für die Analyse müssen transformiert und an einem anderen Ort als die Betriebsdaten gespeichert werden.
Die Informationen werden dupliziert, wodurch die Datenqualität abnimmt. Ebenso verursacht der abgetrennte Raum einen Wartungsaufwand. Beide Datenbanken benötigen eine Richtlinienverwaltung sowie eine Sicherungsverwaltung.
Eine Datenbank mit mehreren Modellen bietet einen hybriden Ansatz für die Datenspeicherung. Ein einheitlicher Daten-Hub zum Speichern von Transaktions- und Extrahieren von Analysedaten ist einfacher zu warten.
Datenzentralisierung
Daten innerhalb einer Organisation haben Barrieren. Obwohl Einschränkungen bestehen müssen, verhindert dieser Ansatz die Verwendung von Informationen innerhalb eines Unternehmens.
Datenbanken mit mehreren Modellen speichern Daten unverändert, ohne dass Transformationen erforderlich sind. Die Datenzentralisierung bietet wertvolle Einblicke in vorhandene Daten sowie die Möglichkeit, neue Anwendungsfälle zu erstellen.
Big Data durchsuchen
Hadoop ist außergewöhnlich darin, große Mengen unterschiedlicher Daten über verschiedene Modelle hinweg zu verarbeiten. Der Hauptgrund ist die Geschwindigkeit beim Empfangen, Verarbeiten und Speichern verschiedener Daten. Was Hadoop jedoch fehlt, ist ein effizienter Suchmechanismus.
Durch die Nutzung der Hadoop-Rechenleistung und die Kombination mit der Stärke von Datenbanksuchen mit mehreren Modellen entsteht ein robustes System. Der Prozess der Arbeit mit Daten wird skalierbar und robust für Big-Data-Aufgaben.
Vor- und Nachteile von Datenbanken mit mehreren Modellen
Datenbanken mit mehreren Modellen haben Vor- und Nachteile. Die Tabelle liefert die Zusammenfassung:
| Vorteile | Nachteile |
|---|---|
| Daten konsistent | Komplex |
| Agil | Entwicklung |
| ACID-konform | Modellierungstechniken fehlen |
| Geeignet für komplexe Projekte | Nicht geeignet für einfache Projekte |
Das Datenbankmodell funktioniert hauptsächlich in Unternehmensumgebungen, in denen viele Daten vorhanden sind. Unterschiedliche Branchen nutzen die Daten für unterschiedliche Aufgaben. Eine bereits etablierte und spezialisierte polyglotte Persistenzstruktur wird jedoch den Mangel an Funktionen in Multimodell-Datenbanken bemerken.
Vorteile
Die Vorteile der Verwendung von Datenbanken mit mehreren Modellen sind:
- Datenkonsistenz zwischen den Modellen aufgrund eines einzigen Back-Ends.
- Verschiedene Datentypen auf einer Plattform bieten eine agile Umgebung.
- Fehlertolerant durch ACID-Konformität.
- Geeignet für komplexe Projekte, die mehrere Datenansichten erfordern.
Nachteile
Einige Nachteile der Verwendung von Datenbanken mit mehreren Modellen sind:
- Datenbanksysteme mit mehreren Modellen sind schwierig zu handhaben und kompliziert.
- Das Datenbankmodell befindet sich noch in der Entwicklung und ist noch nicht richtig ausgereift.
- Es gibt nur eine begrenzte Verfügbarkeit verschiedener Modellierungstechniken.
- Nicht geeignet für einfachere Systeme oder Projekte.
Was sind die besten Multi-Modell-Datenbanken?
Auf dem Markt sind viele verschiedene Multimodell-Datenbanktypen erhältlich. Das einzige Unterscheidungsmerkmal ist die Unterstützung mehrerer Modelle in einer unterstützten Engine.
Einige Datenbanken überlagern mehrere Modelle auf der Engine durch Komponenten. Diese Arten von Datenbanken sind jedoch keine echten Multi-Modell-Datenbanken.
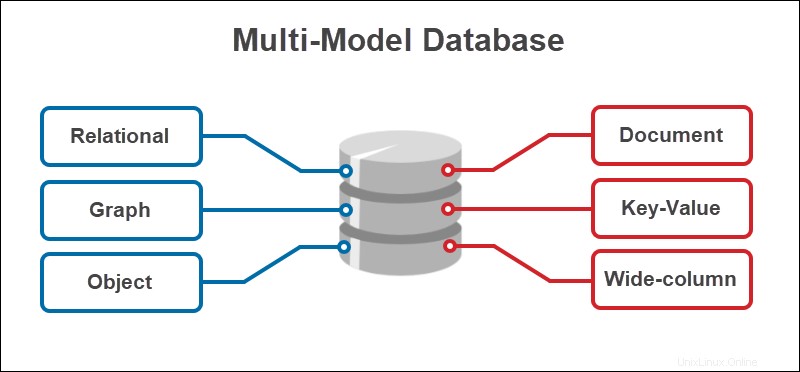
Ein weiterer entscheidender Unterschied zwischen Datenbanken sind die verfügbaren Modellierungstechniken. Dieser Aspekt ist wesentlich, um den Nutzen der verfügbaren Daten zu maximieren.
MarkLogic-Server
MarkLogic-Server ist eine NoSQL-Datenbank mit mehreren Modellen, die als XLM-Speicher begann und sich weiterentwickelte, um mehrere Datenformate zu speichern, wie zum Beispiel:
- Dokument
- Grafik
- Text
- Räumlich
- Schlüsselwert
- Relational
Die Datenbank ist vielseitig, effizient und sicher. Die Funktionen von Mark Logic Server sind:
- Sicherheit und Governance . Integrierte Governance für Daten- und Benutzersicherheit.
- ACID-konform . Starke Datenkonsistenz durch ACID-Compliance.
- Erweiterte Suche . Eine integrierte Suchmaschine mit semantischer Suche, die den Zugriff auf Daten ermöglicht.
- BI und Analytik . Anpassbare Analyse- und Business-Intelligence-Tools sind leicht verfügbar.
- Eingebettetes maschinelles Lernen . Intelligente automatisierte Datenpflege durch eingebettete Algorithmen für maschinelles Lernen, die einen schnelleren Datenzugriff ermöglichen.
- Fehlertolerant und robust . Mark Logic Server verfügt über Hochverfügbarkeits- und Notfallwiederherstellungssysteme, um Unterbrechungen zu vermeiden.
- Hybrid-Cloud-Unterstützung . Die Datenbank ermöglicht eine selbstverwaltete Bereitstellung durch Hybrid-Cloud-Lösungen.
ArangoDB
ArangoDB ist ein natives Multi-Modell-Datenbanksystem. Die unterstützten Datenformate sind:
- Dokument
- Grafik
- Schlüsselwert
Die Datenbank ruft Daten ab und modifiziert sie über eine einheitliche Abfragesprache, AQL. Einige der anderen bemerkenswerten Funktionen sind:
- Erweiterte Verknüpfungen . Ermöglicht das Zusammenführen von Daten mit flexiblen Abfragen, wodurch die Datenredundanz verringert wird.
- Transaktionen . Ausführen von Abfragen für mehrere Dokumente mit verfügbarer Isolation und Transaktionskonsistenz.
- Sharding . Die synchrone Replikation durch Sharding trägt dazu bei, die interne Clusterkommunikation zu reduzieren, die Leistung zu verbessern und die Verbindungsgeschwindigkeit zu verbessern.
- Replikation. Die Replikation stellt eine verteilte Datenbank innerhalb eines Rechenzentrums bereit.
- Multithreading. Die Datenbank nutzt mehrere Kerne durch Multithreading.
OrientDB
OrientDB ist eine in Java geschriebene Open-Source-NoSQL-Datenbank mit mehreren Modellen. Die Datenbank unterstützt die folgenden Modelle:
- Dokument
- Grafik
- Schlüsselwert
- Objekt
- Räumlich
OrientDB war die erste, die mehrere Modelle auf Kernebene enthielt. Die Datenbank verfügt über viele einzigartige Funktionen, von denen einige sind:
- SQL-Unterstützung . Abfragen in SQL werden unterstützt, was Programmierern den Wechsel von relationalen Modellen erleichtert.
- ACID-konform . Die Datenbank ist vollständig transaktional und bietet Zuverlässigkeit.
- Verteilt . Volle Unterstützung für Multi-Master-Replikation über verschiedene dedizierte Server hinweg.
- Teleportierbar . Ermöglicht den schnellen Import relationaler Datenbanken.