Einführung
Datenverarbeitungs-Frameworks wie Apache Hadoop und Spark haben die Entwicklung von Big Data vorangetrieben. Ihre Fähigkeit, riesige Datenmengen aus verschiedenen Datenströmen zu sammeln, ist unglaublich, sie benötigen jedoch ein Data Warehouse, um alle Daten zu analysieren, zu verwalten und abzufragen.
Möchten Sie mehr darüber erfahren, was Data Warehouses sind und woraus sie bestehen?
Dieser Artikel erklärt die Data-Warehouse-Architektur und die Rolle jeder Komponente im System.
Was ist ein Data Warehouse?
Ein Data Warehouse (DW oder DWH) ist ein komplexes System, das historische und kumulative Daten speichert, die für Prognosen, Berichte und Datenanalysen verwendet werden. Es umfasst das Sammeln, Bereinigen und Transformieren von Daten aus verschiedenen Datenströmen und das Laden in Fakten-/Dimensionstabellen.
Ein Data Warehouse stellt eine subjektorientierte, integrierte, zeitvariante und nichtflüchtige Struktur von Daten dar.
Das DWH konzentriert sich auf das Thema und nicht auf den Betrieb und integriert Daten aus mehreren Quellen, wodurch der Benutzer eine einzige Informationsquelle in einem konsistenten Format erhält. Da es nicht flüchtig ist, zeichnet es alle Datenänderungen als neue Einträge auf, ohne seinen vorherigen Zustand zu löschen. Diese Funktion ist eng mit der Zeitvarianz verbunden, da sie historische Daten aufzeichnet, sodass Sie Änderungen im Laufe der Zeit untersuchen können.
All diese Eigenschaften helfen Unternehmen dabei, Analyseberichte zu erstellen, die zum Untersuchen von Änderungen und Trends erforderlich sind.
Data-Warehouse-Architektur
Es gibt drei Möglichkeiten, wie Sie ein Data-Warehouse-System aufbauen können. Diese Ansätze werden nach der Anzahl der Schichten in der Architektur klassifiziert. Daher können Sie Folgendes haben:
- Einschichtige Architektur
- Zweischichtige Architektur
- Dreischichtige Architektur
Single-Tier-Data-Warehouse-Architektur
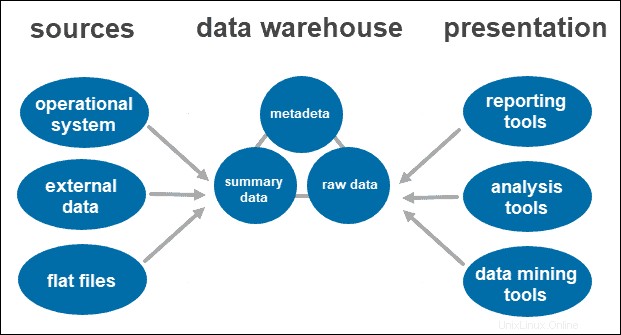
Die Single-Tier-Architektur ist kein häufig praktizierter Ansatz. Das Hauptziel einer solchen Architektur ist das Entfernen von Redundanzen durch Minimieren der gespeicherten Datenmenge.
Sein Hauptnachteil ist, dass es keine Komponente hat, die analytische und transaktionale Verarbeitung trennt.
Zweistufige Data-Warehouse-Architektur
Eine zweischichtige Architektur umfasst einen Staging-Bereich für alle Datenquellen vor der Data-Warehouse-Schicht. Indem Sie einen Staging-Bereich zwischen den Quellen und dem Speicher-Repository hinzufügen, stellen Sie sicher, dass alle in das Warehouse geladenen Daten bereinigt und im geeigneten Format vorliegen.
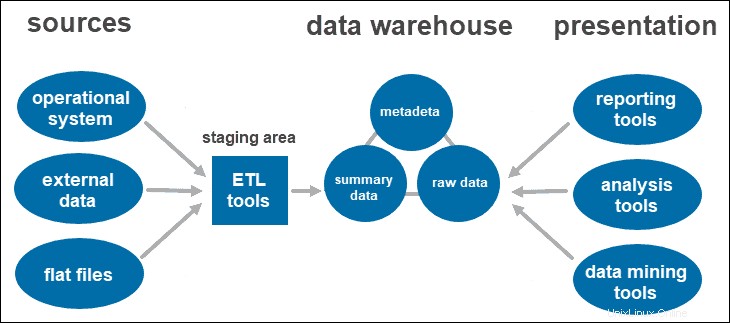
Dieser Ansatz hat bestimmte Netzwerkbeschränkungen. Außerdem können Sie es nicht erweitern, um eine größere Anzahl von Benutzern zu unterstützen.
Dreistufige Data-Warehouse-Architektur
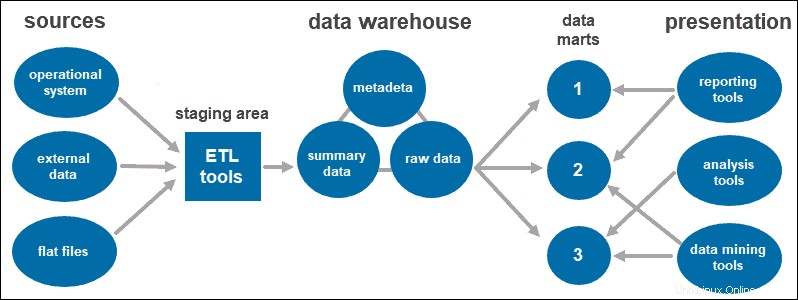
Der dreistufige Ansatz ist die am weitesten verbreitete Architektur für Data-Warehouse-Systeme.
Im Wesentlichen besteht es aus drei Ebenen:
- Die unterste Stufe ist die Datenbank des Warehouses, in die die bereinigten und transformierten Daten geladen werden.
- Die mittlere Stufe ist die Anwendungsschicht, die eine abstrahierte Ansicht der Datenbank bietet. Es ordnet die Daten an, um sie besser für die Analyse geeignet zu machen. Dies geschieht mit einem OLAP-Server, der nach dem ROLAP- oder MOLAP-Modell implementiert ist.
- Die Spitze Hier greift der Benutzer auf die Daten zu und interagiert mit ihnen. Es stellt die Front-End-Client-Schicht dar. Sie können Reporting-Tools, Abfrage-, Analyse- oder Data-Mining-Tools verwenden.
Data Warehouse-Komponenten
Bei den oben beschriebenen Architekturen stellen Sie fest, dass sich einige Komponenten überschneiden, während andere nur von der Anzahl der Schichten abhängig sind.
Nachfolgend finden Sie einige der wichtigsten Data-Warehouse-Komponenten und ihre Rollen im System.
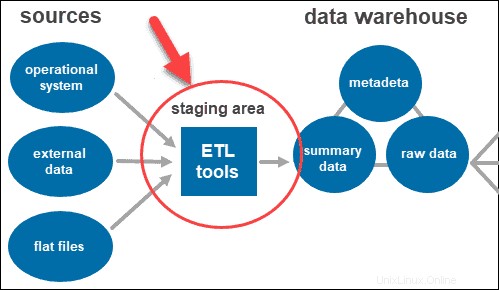
ETL-Tools
ETL steht für Extrakt , Transformieren , und Laden . Die Staging-Schicht verwendet ETL-Tools um die benötigten Daten aus verschiedenen Formaten zu extrahieren und die Qualität zu prüfen, bevor sie in das Data Warehouse geladen werden.
Die Daten aus der Datenquellenschicht können in verschiedenen Formaten vorliegen. Bevor alle aus mehreren Quellen gesammelten Daten in einer einzigen Datenbank zusammengeführt werden, muss das System die Informationen bereinigen und organisieren.
Die Datenbank
Die wichtigste Komponente und das Herz jeder Architektur ist die Datenbank. Im Warehouse werden die Daten gespeichert und abgerufen.
Beim Erstellen des Data-Warehouse-Systems müssen Sie zunächst entscheiden, welche Art von Datenbank Sie verwenden möchten.
Es gibt vier Arten von Datenbanken, aus denen Sie wählen können:
- Relationale Datenbanken (zeilenzentrierte Datenbanken).
- Analytics-Datenbanken (entwickelt, um Analysen aufrechtzuerhalten und zu verwalten).
- Data-Warehouse-Anwendungen (Software zur Datenverwaltung und Hardware zur Speicherung von Daten, die von Drittanbietern angeboten werden).
- Cloud-basierte Datenbanken (in der Cloud gehostet).
Daten
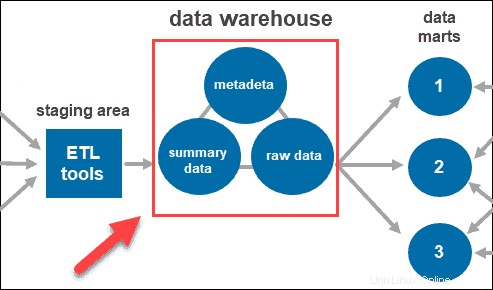
Nachdem das System die Daten bereinigt und organisiert hat, speichert es sie im Data Warehouse. Das Data Warehouse stellt das zentrale Repository dar, in dem Metadaten, Zusammenfassungsdaten und Rohdaten aus jeder Quelle gespeichert werden.
- Metadaten sind die Informationen, die die Daten definieren. Seine Hauptaufgabe besteht darin, die Arbeit mit Dateninstanzen zu vereinfachen. Es ermöglicht Datenanalysten, die erforderlichen Daten zu klassifizieren, zu lokalisieren und Abfragen zu leiten.
- Zusammenfassungsdaten wird vom Lagerverwalter generiert. Es wird aktualisiert, wenn neue Daten in das Warehouse geladen werden. Diese Komponente kann leicht oder stark zusammengefasste Daten enthalten. Seine Hauptaufgabe besteht darin, die Abfrageleistung zu beschleunigen.
- Rohdaten ist das eigentliche Laden von Daten in das Repository, das noch nicht verarbeitet wurde. Die Daten in ihrer Rohform machen sie für die weitere Verarbeitung und Analyse zugänglich.
Auf Tools zugreifen
Benutzer interagieren mit den gesammelten Informationen über verschiedene Tools und Technologien. Sie können die Daten analysieren, Einblicke gewinnen und Berichte erstellen.
Einige der verwendeten Tools sind:
- Berichtstools. Sie spielen eine entscheidende Rolle, um zu verstehen, wie es Ihrem Unternehmen geht und was als Nächstes getan werden sollte. Zu den Berichtstools gehören Visualisierungen wie Grafiken und Diagramme, die zeigen, wie sich Daten im Laufe der Zeit ändern.
- OLAP-Tools. Online-Analyseverarbeitungswerkzeuge, mit denen Benutzer mehrdimensionale Daten aus mehreren Perspektiven analysieren können. Diese Tools bieten eine schnelle Verarbeitung und wertvolle Analysen. Sie extrahieren Daten aus zahlreichen relationalen Datensätzen und reorganisieren sie in einem multidimensionalen Format.
- Data-Mining-Tools. Untersuchen Sie Datensätze, um Muster innerhalb des Lagers und die Korrelation zwischen ihnen zu finden. Data Mining hilft auch dabei, Beziehungen herzustellen, wenn multidimensionale Daten analysiert werden.
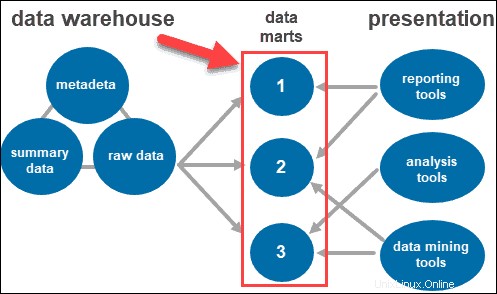
Data Marts
Data Marts ermöglichen es Ihnen, mehrere Gruppen innerhalb des Systems zu haben, indem Sie die Daten im Warehouse in Kategorien segmentieren. Es partitioniert Daten und produziert sie für eine bestimmte Benutzergruppe.
Beispielsweise können Sie Data Marts verwenden, um Informationen nach Abteilungen innerhalb des Unternehmens zu kategorisieren.
Best Practices für Data Warehouses
Das Entwerfen eines Data Warehouse beruht auf dem Verständnis der Geschäftslogik Ihres individuellen Anwendungsfalls.
Die Anforderungen variieren, aber es gibt Best Practices für Data Warehouses, die Sie befolgen sollten:
- Erstellen Sie ein Datenmodell. Beginnen Sie damit, die Geschäftslogik der Organisation zu identifizieren. Verstehen Sie, welche Daten für das Unternehmen von entscheidender Bedeutung sind und wie sie durch das Data Warehouse fließen.
- Entscheiden Sie sich für einen bekannten Data-Warehouse-Architekturstandard. Ein Datenmodell bietet einen Rahmen und eine Reihe von Best Practices, die beim Entwerfen der Architektur oder Beheben von Problemen befolgt werden können. Zu den gängigen Architekturstandards gehören 3NF, Data Vault-Modellierung und Star-Schema.
- Erstellen Sie ein Datenflussdiagramm. Dokumentieren Sie, wie Daten durch das System fließen. Wissen, wie sich das auf Ihre Anforderungen und Geschäftslogik bezieht.
- Eine einzige Quelle der Wahrheit haben. Beim Umgang mit so vielen Daten muss eine Organisation eine einzige Quelle der Wahrheit haben. Konsolidieren Sie Daten in einem einzigen Repository.
- Automatisierung verwenden. Automatisierungstools helfen beim Umgang mit riesigen Datenmengen.
- Freigabe von Metadaten zulassen. Entwerfen Sie eine Architektur, die die gemeinsame Nutzung von Metadaten zwischen Data-Warehouse-Komponenten erleichtert.
- Codierungsstandards durchsetzen. Codierungsstandards gewährleisten Systemeffizienz.