Elasticsearch ist eine Open-Source-Analyse und eine Suchmaschine. Es ist eine erweiterte Suchmaschine für Server und Websites. Oder, in normalen Worten, Elasticsearch ist eine Art Datenbank mit einigen JSON-Dateien, die aus einer großen Menge von Datenindexen suchen können. Wenn Sie einen Datenserver, Webserver oder eine Website besitzen, können Sie die Elasticsearch-Engine auf Ihrem System installieren und konfigurieren, um die Datenbankparameter zu finden. Elasticsearch kann mit Linux-Servern und -Systemen installiert und konfiguriert werden, um Daten zu sortieren, die Suchergebnisse zu verbessern und Suchparameter zu filtern. Grundsätzlich können Sie die Elasticsearch-Engine auf Ihrem Server verwenden, um alle möglichen Dinge zum Erstellen einer robusten Suchmaschine zu tun.
So funktioniert Elasticsearch
Elasticsearch antwortet mit einfachen HTTP-Anforderungen und hält die Datenbank auf dem neuesten Stand, sodass ihr keine Abfrage entgeht. Sie können eine Abfrage ausführen und Ihre Daten aus der Datenbank über die Elasticsearch-Engine analysieren. Sie können Elasticsearch sowohl auf neuen als auch auf bestehenden Servern installieren; Ihre Daten werden bei Suchanfragen nicht dupliziert.
Elasticsearch arbeitet mit einem Application Performance Management (APM)-Tool zum Sammeln von Indexdaten, Metadaten und anderen Datenfeldern aus der Quelldatenbank. Es ermöglicht auch API-Unterstützung für eine bessere Leistung.
Mit Elasticsearch können Sie ein Kreisdiagramm und andere grafische Darstellungen Ihrer Daten erstellen. Es ist keine Business Intelligence, analysiert aber Daten ziemlich gut. Sie können die CPU- und Speicherauslastung ermitteln, Anomalien erkennen und Daten über Elasticsearch auf einem Linux-System speichern.
Installieren Sie Elasticsearch unter Linux
Elasticsearch ist in Java geschrieben, daher müsste Java auf Ihrem Linux-System installiert sein, um Elasticsearch auf Ihrem System zu installieren. Es ermöglicht die API-Integration, sodass Sie es in verschiedenen Webanwendungen verwenden können. Sie können Elasticsearch auf einem Linux-System installieren und mit einem vorhandenen Apache- oder Nginx-Server konfigurieren. In diesem Beitrag erfahren Sie, wie Sie Elastic Search auf einem Linux-System installieren und verwenden können.
1. Installieren Sie Elasticsearch unter Ubuntu/Debian Linux
Die Installation von Elasticsearch auf einem Debian-basierten Linux-System ist keine komplizierte Aufgabe; Es ist einfach und unkompliziert. Sie müssen einige grundlegende Terminalbefehle kennen und das Root-Recht auf Ihrem System haben. Die folgenden Schritte führen Sie durch die Installation von Elasticsearch auf Ubuntu- und anderen Debian-Linux-Rechnern.
Schritt 1:Installieren Sie Java für Elasticsearch
Elasticsearch erfordert Java, um die Webbibliotheksfunktionen auf einem Linux-System zu konfigurieren. Wenn auf Ihrem System Java nicht installiert ist, können Sie den folgenden Terminalbefehl auf Ihrer Shell ausführen, um Java zu installieren.
sudo apt install openjdk-11-jre-headless
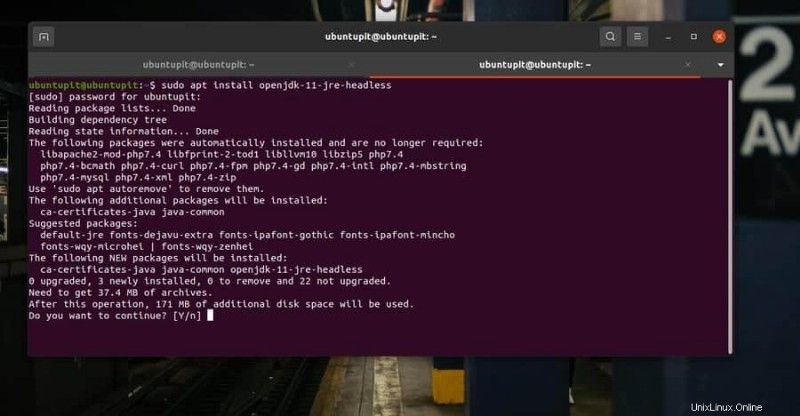
Wenn die Java-Installation abgeschlossen ist, vergessen Sie nicht, die Java-Version zu überprüfen, um sicherzustellen, dass sie korrekt installiert ist.
java -version
Schritt 2:GPG-Schlüssel für Elasticsearch unter Debian Linux hinzufügen
Für eine mühelose Installation von Elasticsearch müssen Sie den GPG-Schlüssel (Gnu Privacy Guard) von Elasticsearch zu Ihrem Linux-System hinzufügen. Führen Sie den folgenden cURL-Befehl auf Ihrer Terminal-Shell aus, um den GPG-Schlüssel hinzuzufügen.
curl -fsSL https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
Für Dedina-Distributionen ist Elasticsearch im Linux-Repository verfügbar. Sie müssen es zu Ihrem System-Repository hinzufügen. Sie können den folgenden echo-Befehl ausführen, um Elasticsearch zum Repository Ihres Systems hinzuzufügen.
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.list
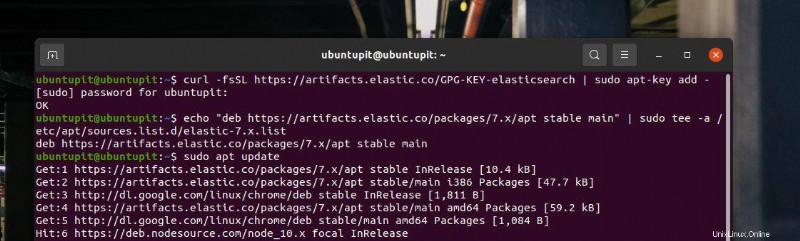
Wenn der echo-Befehl endet, aktualisieren Sie Ihr System-Repository und prüfen Sie, ob es zu Ihrer Software hinzugefügt wurde. Sie finden Ihr System-Repository auf der Registerkarte „Andere Software“ im Tool „Software &Updates“.
sudo apt-get update
Schritt 3:Installieren Sie Elasticsearch auf Debian/Ubuntu
Nach dem Hinzufügen des GPG-Schlüssels und dem Aktualisieren des Repositorys ist die Installation von Elasticsearch jetzt eine Sache weniger Klicks. Sie können jetzt den folgenden aptitude-Befehl auf Ihrer Terminal-Shell mit Root-Rechten ausführen, um Elasticsearch auf Ihrem Debian-System zu installieren.
sudo apt install elasticsearch
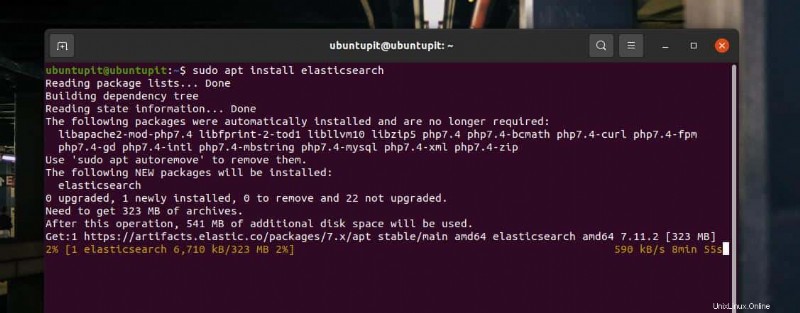
2. Elasticsearch auf Fedora Workstation installieren
Wenn Sie ein Fedora-Linux-System verwenden, führen Sie die folgenden Schritte zur Installation von Elasticsearch auf Ihrem Computer. Ich habe die folgenden Schritte auf meiner Fedora-Workstation getestet; die Schritte wären auch auf anderen Red Hat-basierten Systemen ausführbar.
Schritt 1:Java auf Fedora Workstation installieren
Wie ich bereits erwähnt habe, erfordert die Installation von Elasticsearch Java; Zuerst installieren wir Java auf unserem System. Wenn Sie Java bereits auf Ihrem System installiert haben, können Sie die Installation überspringen. Um sicherzustellen, ob Java installiert ist oder nicht, können Sie einen schnellen Versionsprüfungsbefehl auf der Terminal-Shell ausführen.
java -version
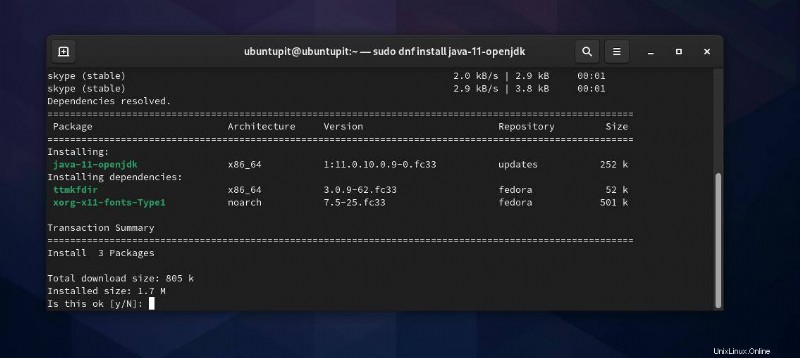
Wenn Sie im Gegenzug keine Java-Version sehen, können Sie jetzt den folgenden DNF-Befehl ausführen, um sie auf Ihrem Fedora-Linux zu installieren.
sudo dnf install java-11-openjdk
Schritt 2:Gnu Privacy Guard für Elasticsearch hinzufügen
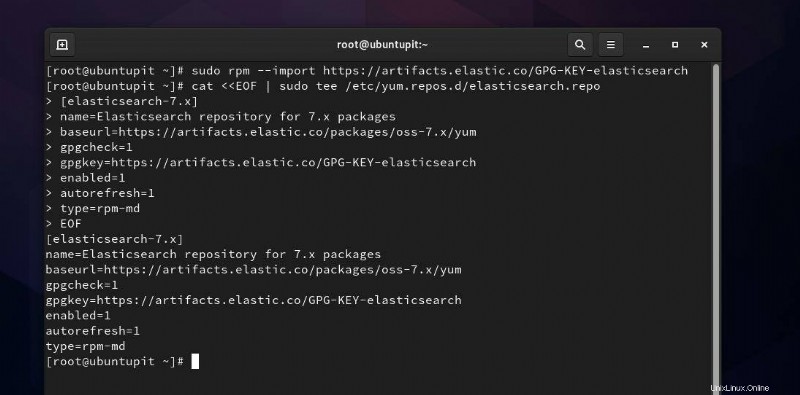
In diesem Schritt müssen wir den GPG-Schlüssel für Elasticsearch zu unserem System hinzufügen. Sie können den folgenden Befehl auf der Terminal-Shell ausführen, um den GPG-Schlüssel hinzuzufügen.
sudo rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
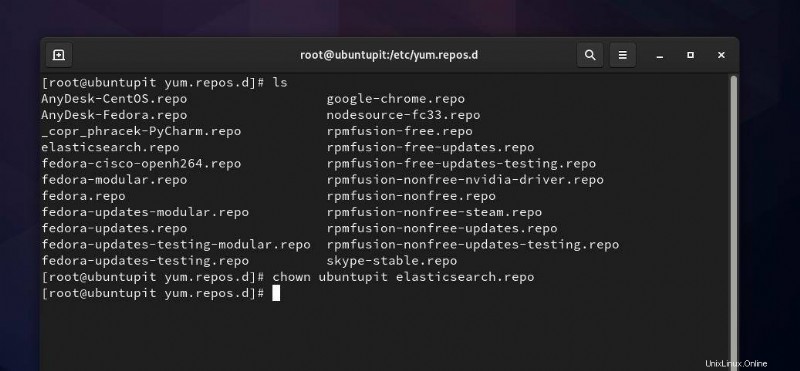
Jetzt müssen wir eine Repository-Datei für Elasticsearch in /etc/yum.repos.d erstellen Verzeichnis. Sie können das Dateisystem durchsuchen öffnen und ein neues Textdokumentskript erstellen und es in elasticsearch.repo umbenennen . Wenn Sie beim Erstellen einer neuen Repository-Datei Berechtigungsprobleme haben, können Sie den folgenden chown ausführen Befehl, um auf die Datei zuzugreifen. Vergessen Sie nicht, das Wort „ubuntupit“ zu ersetzen ‘ mit Ihrem Benutzernamen.
sudo chown ubuntupit elasticsearch.repo
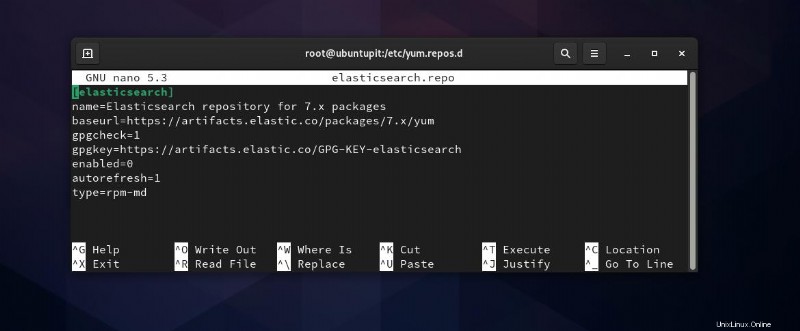
Dann müssen Sie das folgende Skript kopieren und in elasticsearch.repo einfügen Datei und speichern und beenden Sie die Datei.
cat <<EOF | sudo tee /etc/yum.repos.d/elasticsearch.repo [elasticsearch-7.x] name=Elasticsearch repository for 7.x packages baseurl=https://artifacts.elastic.co/packages/oss-7.x/yum gpgcheck=1 gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=1 autorefresh=1 type=rpm-md EOF
Schritt 3:Elasticsearch auf Fedora installieren
Nach der Installation von Java und dem Hinzufügen des GPG-Schlüssels installieren wir nun Elasticsearch auf unserem Fedora-Linux. Vor der Installation müssen Sie möglicherweise einen schnellen DNF-Bereinigungsbefehl ausführen, um die Repository-Metadaten von Ihrem System zu bereinigen. Führen Sie dann den folgenden YUM-Befehl auf Ihrer Shell mit Root-Rechten aus, um Elasticsearch auf Ihrem System zu installieren.
sudo dnf clean sudo yum install elasticsearch
Wenn Sie Probleme bei der Installation auf Ihrem System haben, können Sie den folgenden DNF-Befehl ausführen, um Fehler zu vermeiden.
sudo dnf install elasticsearch-oss
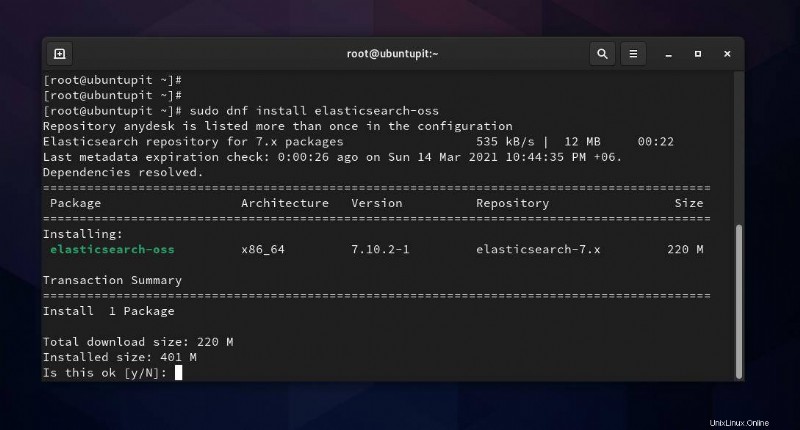
Wenn die Installation abgeschlossen ist, können Sie jetzt die folgenden Systemsteuerungsbefehle auf Ihrer Terminal-Shell ausführen, um Elasticsearch auf Ihrem Linux-Computer zu starten und zu aktivieren.
sudo systemctl start elasticsearch sudo systemctl enable elasticsearch
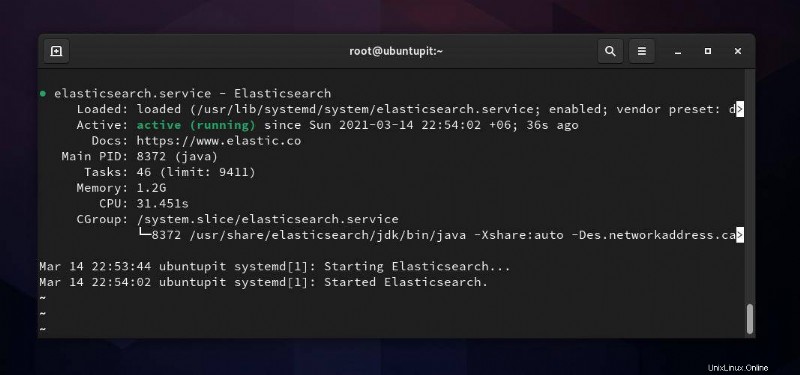
Wenn alles richtig läuft, können Sie den folgenden Systemsteuerungsbefehl ausführen, um den Status von Elasticsearch auf Ihrem Computer zu überprüfen. Im Gegenzug sehen Sie den Dienstnamen, die Haupt-PID, den Aktivierungsstatus, Aufgabendetails und die CPU-Laufzeit.
sudo systemctl status elasticsearch
Elasticsearch unter Linux konfigurieren
Nach der Installation von Elasticsearch auf einem Linux-Computer müssen Sie es möglicherweise mit Ihrer Server-IP-Adresse konfigurieren, um es mit Ihrem Server zu laden. Hier verwende ich die localhost-Adresse (127.0.0.1), um sie zu laden. Sie können den folgenden Befehl auf Ihrer Terminal-Shell ausführen, um das Konfigurationsskript zu öffnen.
sudo nano /etc/elasticsearch/elasticsearch.yml
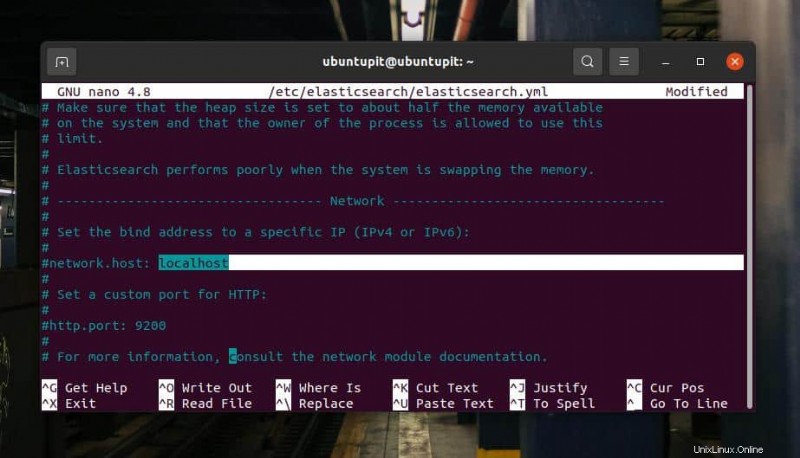
Wenn das Skript geöffnet wird, suchen Sie network.host Parameter und ersetzen Sie den vorhandenen Wert durch die Adresse Ihres aktiven Servers. Nachdem Sie die IP-Adresse geändert haben, speichern und beenden Sie die Datei.
network.host: localhost
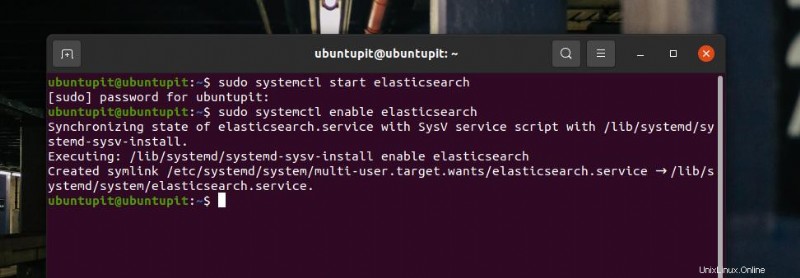
Starten und aktivieren Sie jetzt Elasticsearch auf Ihrem Linux-System, um es erneut auf Ihren Computer zu laden.
sudo systemctl start elasticsearch sudo systemctl enable elasticsearch
Wenn Sie eine neue IP-Adresse mit einem neuen Port hinzufügen, ist es immer genial, sie der Firewall hinzuzufügen. Ich muss erwähnen, dass Elasticsearch standardmäßig die Netzwerkports 9200-9300 verwendet. Hier verwende ich Port 9200 zum Konfigurieren von Elasticsearch mit der localhost-Adresse.
Da Ubuntu das UFW-Tool für Firewall-Einstellungen verwendet, können Sie die folgenden UFW-Befehle auf Ihrer Terminal-Shell ausführen, um Port 9200 auf Ihrem System zuzulassen.
sudo ufw allow from 127.0.0.1 to any port 9200 sudo ufw enable
Sie können jetzt den UFW-Status auf der Terminal-Shell überprüfen, um zu überprüfen, ob der Port im Netzwerksystem hinzugefügt wurde oder nicht.
sudo ufw status
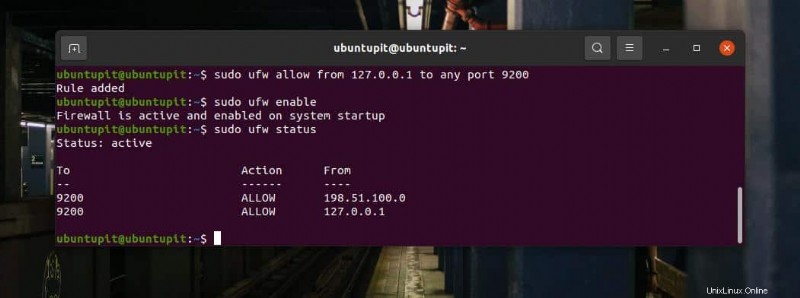
Wenn Sie Fedora, Red Hat Linux und andere Linux-Distributionen verwenden, verwenden Sie den Firewalld-Befehl, um Port 9200 für Ihre Umgebung zu aktivieren. Aktivieren Sie zuerst die Firewalld auf Ihrem Linux-System.
systemctl status firewalld systemctl enable firewalld sudo firewall-cmd --reload
Fügen Sie nun die Regel zu den Firewalld-Einstellungen hinzu. Starten Sie dann das Angular-CLI-System neu.
firewall-cmd --add-port=9200/tcp firewall-cmd --list-all
Erste Schritte mit Elasticsearch
Nach der Installation, Konfiguration der Server-IP und dem Hinzufügen der Firewall-Regeln auf unserem Linux-System ist es jetzt an der Zeit, damit zu beginnen. Hier führe ich einen cURL-Befehl aus, um über Elasticsearch eine Anfrage an Ihren Server zu senden. Im Gegenzug würden Sie den Hostnamen, den Clusternamen, die UUID und die Tag-Zeile von Elasticsearch unten auf der Rückgabeseite sehen.
curl -X GET 'http://localhost:9200'
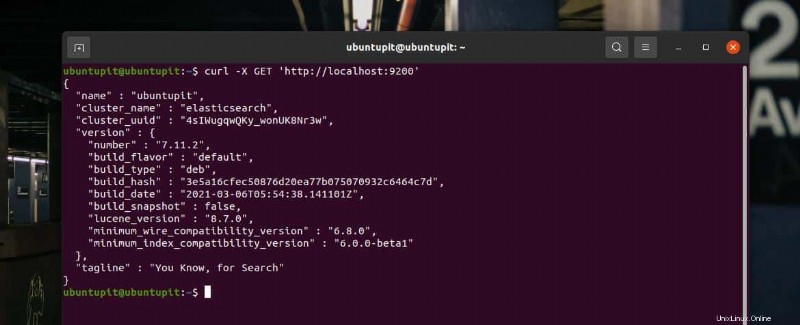
Wir können versuchen, eine Zeichenfolge in die Elasticsearch-Datenbank einzufügen und die Daten abzurufen, um zu überprüfen, ob sie perfekt funktionieren oder nicht. Führen Sie den folgenden cURL-Befehl aus, um die Daten in das System zu verschieben.
curl\
-X POST 'http://localhost:9200/ubuntupit/hello/1'\
-H 'Content-Type: application /json' \
-d '{ "name" : " ubuntupit " }'\ Führen Sie den folgenden Befehl auf der Terminal-Shell Ihres Systems aus, um die String-Daten durch Elasticsearch zu ziehen.
curl -X GET 'http://localhost:9200/ubuntupit/hello/1'
Schlussworte
Elasticsearch ist ein beliebtes Tool zum Generieren einer eigenen Suchmaschine. Sie würden wissen, dass der große E-Commerce-Riese Amazon Elasticsearch für seine Produkt-Storefront-Suche verwendet. Im gesamten Beitrag habe ich beschrieben, wie Sie Ihre erste Abfrage auf Elasticsearch installieren, konfigurieren und ausführen können. Sie können auch eine boolesche Abfrage ausführen, eine Paginierungsdatentabelle über Elasticseach haben und UI-Tools wie Kibana verwenden, um Elasticsearch mit Ihrer vorhandenen Datenbank zu verwenden.
Bitte teilen Sie diesen Beitrag mit Ihren Freunden und der Linux-Community, wenn Sie ihn hilfreich und praktisch finden. Sie können auch Ihre Meinung zu diesem Beitrag in den Kommentarbereich schreiben.