Als ich in einer netzwerkorientierten Rolle arbeitete, bestand eine der größten Herausforderungen immer darin, die Lücke zwischen Netzwerk- und Systemtechnik zu schließen. Systemadministratoren, die keinen Einblick in das Netzwerk haben, machten das Netzwerk oft für Ausfälle oder seltsame Probleme verantwortlich. Netzwerkadministratoren, die nicht in der Lage sind, die Server zu kontrollieren, und die von der „Schuld bis zum Beweis der Unschuld“-Einstellung gegenüber dem Netzwerk ermüdet sind, geben oft den Netzwerkendpunkten die Schuld.
Schuld löst natürlich keine Probleme. Sich Zeit zu nehmen, um die Grundlagen der Domäne einer Person zu verstehen, kann viel dazu beitragen, die Beziehungen zu anderen Teams zu verbessern und Probleme schneller zu lösen. Diese Tatsache gilt insbesondere für Systemadministratoren. Durch ein grundlegendes Verständnis der Netzwerkfehlerbehebung können wir unseren Netzwerkkollegen stärkere Beweise liefern, wenn wir vermuten, dass das Netzwerk fehlerhaft sein könnte. Ebenso können wir oft Zeit sparen, indem wir selbst eine anfängliche Fehlerbehebung durchführen.
In diesem Artikel behandeln wir die Grundlagen der Netzwerkfehlerbehebung über die Linux-Befehlszeile.
Ein kurzer Überblick über das TCP/IP-Modell
Nehmen wir uns zunächst einen Moment Zeit, um die Grundlagen des TCP/IP-Netzwerkmodells zu wiederholen. Während die meisten Menschen das Open Systems Interconnection (OSI)-Modell verwenden, um die Netzwerktheorie zu diskutieren, stellt das TCP/IP-Modell die Suite von Protokollen, die in modernen Netzwerken eingesetzt werden, genauer dar.
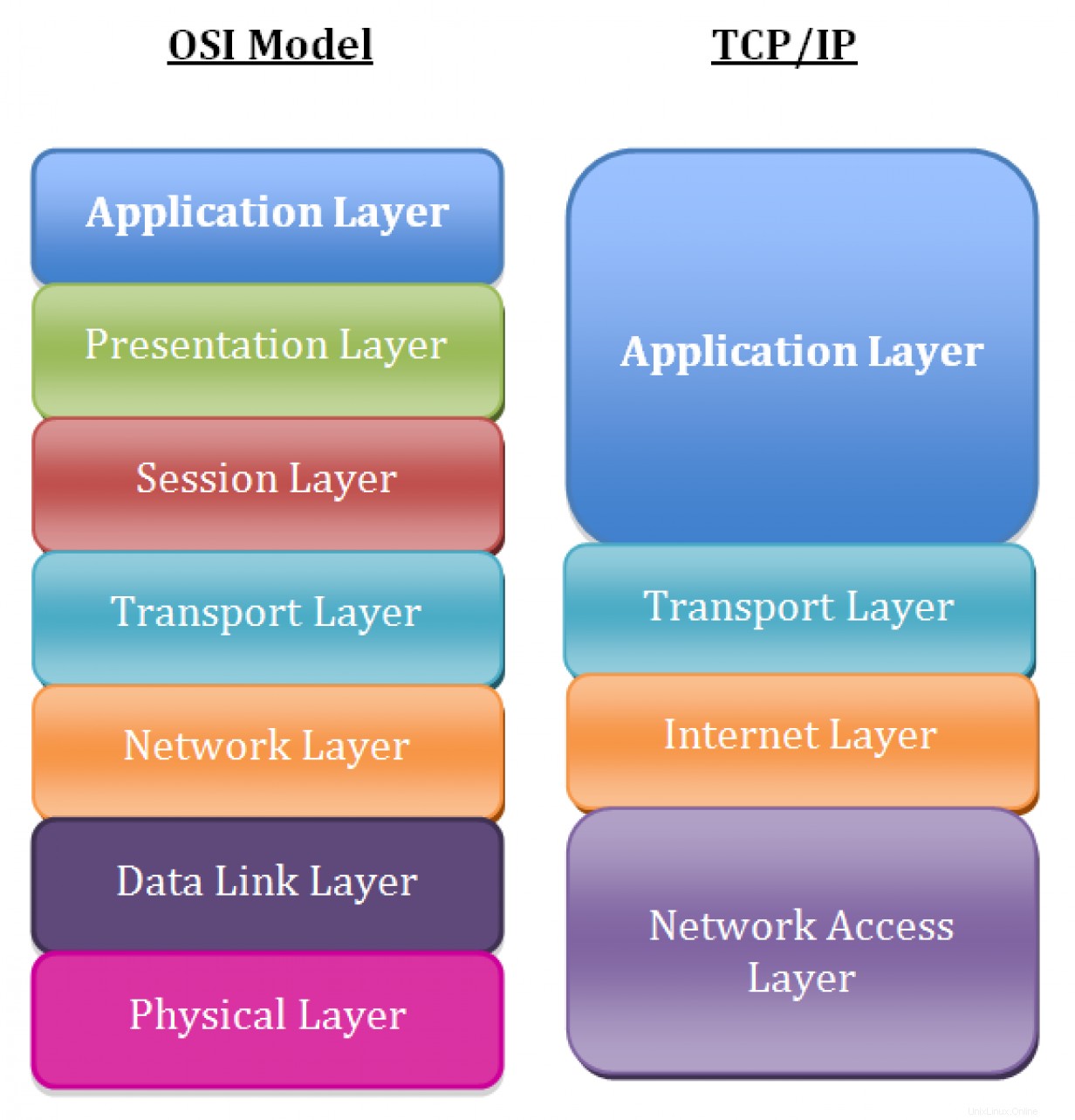
Die Schichten im TCP/IP-Netzwerkmodell umfassen in dieser Reihenfolge:
- Schicht 5: Bewerbung
- Schicht 4: Transport
- Ebene 3: Netzwerk/Internet
- Ebene 2: Datenlink
- Schicht 1: Physisch
Ich gehe davon aus, dass Sie mit diesem Modell vertraut sind, und werde mit der Erörterung von Möglichkeiten zur Behebung von Problemen auf den Stapelebenen 1 bis 4 fortfahren. Wo Sie mit der Fehlerbehebung beginnen, hängt von der Situation ab. Wenn Sie beispielsweise eine SSH-Verbindung zu einem Server herstellen können, der Server jedoch keine Verbindung zu einer MySQL-Datenbank herstellen kann, liegt das Problem wahrscheinlich nicht an den physischen oder Datenverbindungsschichten auf dem lokalen Server. Im Allgemeinen ist es eine gute Idee, sich den Stapel herunterzuarbeiten. Beginnen Sie mit der Anwendung und beheben Sie dann nach und nach Fehler auf jeder unteren Ebene, bis Sie das Problem isoliert haben.
Lassen Sie uns mit diesem Hintergrund zur Befehlszeile springen und mit der Fehlerbehebung beginnen.
Schicht 1:Die physikalische Schicht
Wir nehmen die Bitübertragungsschicht oft als selbstverständlich hin („Haben Sie sichergestellt, dass das Kabel eingesteckt ist?“), aber wir können Probleme mit der Bitübertragungsschicht einfach über die Linux-Befehlszeile beheben. Das ist der Fall, wenn Sie eine Konsolenverbindung zum Host haben, was bei einigen Remote-Systemen möglicherweise nicht der Fall ist.
Beginnen wir mit der grundlegendsten Frage:Ist unsere physische Schnittstelle aktiv? Die ip link show Befehl sagt uns:
# ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST> mtu 1500 qdisc pfifo_fast state DOWN mode DEFAULT group default qlen 1000
link/ether 52:54:00:82:d6:6e brd ff:ff:ff:ff:ff:ff
Beachten Sie die Angabe von DOWN in der obigen Ausgabe für die eth0-Schnittstelle. Dieses Ergebnis bedeutet, dass Layer 1 nicht angezeigt wird. Wir versuchen möglicherweise, Fehler zu beheben, indem wir die Verkabelung oder das Remote-Ende der Verbindung (z. B. den Switch) auf Probleme überprüfen.
Bevor Sie jedoch mit der Überprüfung der Kabel beginnen, sollten Sie sicherstellen, dass die Schnittstelle nicht nur deaktiviert ist. Das Ausgeben eines Befehls zum Aufrufen der Schnittstelle kann dieses Problem ausschließen:
# ip link set eth0 up
Die Ausgabe von ip link show kann auf einen Blick schwer zu analysieren sein. Zum Glück ist das -br switch gibt diese Ausgabe in einem viel besser lesbaren Tabellenformat aus:
# ip -br link show
lo UNKNOWN 00:00:00:00:00:00 <LOOPBACK,UP,LOWER_UP>
eth0 UP 52:54:00:82:d6:6e <BROADCAST,MULTICAST,UP,LOWER_UP>
Es sieht aus wie ip link set eth0 up hat es geschafft und eth0 ist wieder im Geschäft.
Diese Befehle eignen sich hervorragend zur Behebung offensichtlicher physischer Probleme, aber was ist mit heimtückischeren Problemen? Schnittstellen können mit der falschen Geschwindigkeit aushandeln, oder Kollisionen und Probleme auf der physikalischen Schicht können Paketverluste oder -beschädigungen verursachen, die zu kostspieligen Neuübertragungen führen. Wie beginnen wir mit der Fehlerbehebung dieser Probleme?
Wir können das -s verwenden Flag mit dem ip Befehl zum Drucken zusätzlicher Statistiken über eine Schnittstelle. Die folgende Ausgabe zeigt eine weitgehend saubere Schnittstelle mit nur wenigen verworfenen Empfangspaketen und keinen anderen Anzeichen von Problemen mit der Bitübertragungsschicht:
# ip -s link show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 52:54:00:82:d6:6e brd ff:ff:ff:ff:ff:ff
RX: bytes packets errors dropped overrun mcast
34107919 5808 0 6 0 0
TX: bytes packets errors dropped carrier collsns
434573 4487 0 0 0 0
Für eine fortgeschrittenere Fehlersuche auf Ebene 1 bietet das ethtool Dienstprogramm ist eine ausgezeichnete Option. Ein besonders guter Anwendungsfall für diesen Befehl ist die Überprüfung, ob eine Schnittstelle die richtige Geschwindigkeit ausgehandelt hat. Eine Schnittstelle, die die falsche Geschwindigkeit ausgehandelt hat (z. B. eine 10-Gbit/s-Schnittstelle, die nur 1-Gbit/s-Geschwindigkeiten meldet), kann ein Indikator für ein Hardware-/Verkabelungsproblem oder eine Fehlkonfiguration bei der Aushandlung auf einer Seite der Verbindung sein (z. B. ein falsch konfigurierter Switch-Port).
Unsere Ergebnisse könnten so aussehen:
# ethtool eth0
Settings for eth0:
Supported ports: [ TP ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Supported pause frame use: Symmetric
Supports auto-negotiation: Yes
Supported FEC modes: Not reported
Advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Advertised pause frame use: Symmetric
Advertised auto-negotiation: Yes
Advertised FEC modes: Not reported
Speed: 1000Mb/s
Duplex: Full
Port: Twisted Pair
PHYAD: 1
Transceiver: internal
Auto-negotiation: on
MDI-X: on (auto)
Supports Wake-on: d
Wake-on: d
Current message level: 0x00000007 (7)
drv probe link
Link detected: yes
Beachten Sie, dass die obige Ausgabe einen Link zeigt, der korrekt auf eine Geschwindigkeit von 1000 Mbit/s und Vollduplex ausgehandelt wurde.
Schicht 2:Die Sicherungsschicht
Die Sicherungsschicht ist für lokal zuständig Netzwerkkonnektivität; Im Wesentlichen die Kommunikation von Frames zwischen Hosts in derselben Layer-2-Domäne (allgemein als lokales Netzwerk bezeichnet). Das relevanteste Layer-2-Protokoll für die meisten Systemadministratoren ist das Address Resolution Protocol (ARP), das Layer-3-IP-Adressen auf Layer-2-Ethernet-MAC-Adressen abbildet. Wenn ein Host versucht, einen anderen Host in seinem lokalen Netzwerk (z. B. das Standard-Gateway) zu kontaktieren, hat er wahrscheinlich die IP-Adresse des anderen Hosts, kennt aber nicht die MAC-Adresse des anderen Hosts. ARP löst dieses Problem und ermittelt die MAC-Adresse für uns.
Ein häufig auftretendes Problem ist ein ARP-Eintrag, der nicht ausgefüllt wird, insbesondere für das Standard-Gateway Ihres Hosts. Wenn Ihr lokaler Host die Layer-2-MAC-Adresse seines Gateways nicht erfolgreich auflösen kann, kann er keinen Datenverkehr an Remote-Netzwerke senden. Dieses Problem kann dadurch verursacht werden, dass die falsche IP-Adresse für das Gateway konfiguriert ist, oder es kann ein anderes Problem sein, z. B. ein falsch konfigurierter Switch-Port.
Wir können die Einträge in unserer ARP-Tabelle mit dem ip neighbor überprüfen Befehl:
# ip neighbor show
192.168.122.1 dev eth0 lladdr 52:54:00:11:23:84 REACHABLE
Beachten Sie, dass die MAC-Adresse des Gateways ausgefüllt ist (wir werden im nächsten Abschnitt mehr darüber sprechen, wie Sie Ihr Gateway finden). Wenn es ein Problem mit ARP gab, würden wir einen Auflösungsfehler sehen:
# ip neighbor show
192.168.122.1 dev eth0 FAILED
Eine weitere häufige Verwendung des ip neighbor Befehl beinhaltet die Manipulation der ARP-Tabelle. Stellen Sie sich vor, Ihr Netzwerkteam hat gerade den Upstream-Router (das Standard-Gateway Ihres Servers) ersetzt. Auch die MAC-Adresse kann sich geändert haben, da MAC-Adressen werkseitig vergebene Hardware-Adressen sind.
Hinweis: Während den Geräten werkseitig eindeutige MAC-Adressen zugewiesen werden, ist es möglich, diese zu ändern oder zu fälschen. Viele moderne Netzwerke verwenden häufig auch Protokolle wie das Virtual Router Redundancy Protocol (VRRP), die eine generierte MAC-Adresse verwenden.
Linux speichert den ARP-Eintrag für eine bestimmte Zeit im Cache, sodass Sie möglicherweise keinen Datenverkehr an Ihr Standard-Gateway senden können, bis der ARP-Eintrag für Ihr Gateway abgelaufen ist. Für sehr wichtige Systeme ist dieses Ergebnis unerwünscht. Glücklicherweise können Sie einen ARP-Eintrag manuell löschen, wodurch ein neuer ARP-Erkennungsprozess erzwungen wird:
# ip neighbor show
192.168.122.170 dev eth0 lladdr 52:54:00:04:2c:5d REACHABLE
192.168.122.1 dev eth0 lladdr 52:54:00:11:23:84 REACHABLE
# ip neighbor delete 192.168.122.170 dev eth0
# ip neighbor show
192.168.122.1 dev eth0 lladdr 52:54:00:11:23:84 REACHABLE
Im obigen Beispiel sehen wir einen ausgefüllten ARP-Eintrag für 192.168.122.70 auf eth0. Wir löschen dann den ARP-Eintrag und können sehen, dass er aus der Tabelle entfernt wurde.
Schicht 3:Die Netzwerk-/Internetschicht
Schicht 3 beinhaltet die Arbeit mit IP-Adressen, die jedem Systemadministrator vertraut sein sollten. Die IP-Adressierung bietet Hosts eine Möglichkeit, andere Hosts außerhalb ihres lokalen Netzwerks zu erreichen (obwohl wir sie oft auch in lokalen Netzwerken verwenden). Einer der ersten Schritte zur Fehlerbehebung besteht darin, die lokale IP-Adresse eines Computers zu überprüfen, was mit ip address erfolgen kann Befehl, wieder unter Verwendung des -br Flag, um die Ausgabe zu vereinfachen:
# ip -br address show
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.135/24 fe80::184e:a34d:1d37:441a/64 fe80::c52f:d96e:a4a2:743/64
Wir können sehen, dass unsere eth0-Schnittstelle eine IPv4-Adresse von 192.168.122.135 hat. Wenn wir keine IP-Adresse hätten, würden wir dieses Problem beheben wollen. Das Fehlen einer IP-Adresse kann durch eine lokale Fehlkonfiguration, wie z. B. eine falsche Konfigurationsdatei der Netzwerkschnittstelle, oder durch Probleme mit DHCP verursacht werden.
Das gebräuchlichste Frontline-Tool, das die meisten Systemadministratoren zur Fehlerbehebung auf Layer 3 verwenden, ist ping Nützlichkeit. Ping sendet ein ICMP-Echo-Request-Paket an einen entfernten Host und erwartet als Antwort eine ICMP-Echo-Antwort. Wenn Sie Verbindungsprobleme mit einem Remote-Host haben, ping ist ein allgemeines Dienstprogramm, um mit der Fehlerbehebung zu beginnen. Durch Ausführen eines einfachen Pings über die Befehlszeile werden ICMP-Echos auf unbestimmte Zeit an den Remote-Host gesendet. Sie müssen STRG+C drücken, um den Ping zu beenden, oder den -c <num pings> übergeben Flagge, etwa so:
# ping www.google.com
PING www.google.com (172.217.165.4) 56(84) bytes of data.
64 bytes from yyz12s06-in-f4.1e100.net (172.217.165.4): icmp_seq=1 ttl=54 time=12.5 ms
64 bytes from yyz12s06-in-f4.1e100.net (172.217.165.4): icmp_seq=2 ttl=54 time=12.6 ms
64 bytes from yyz12s06-in-f4.1e100.net (172.217.165.4): icmp_seq=3 ttl=54 time=12.5 ms
^C
--- www.google.com ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2002ms
rtt min/avg/max/mdev = 12.527/12.567/12.615/0.036 ms
Beachten Sie, dass jeder Ping die Zeit enthält, die zum Empfangen einer Antwort benötigt wurde. Während ping kann ein einfacher Weg sein, um festzustellen, ob ein Host lebt und antwortet, es ist jedoch keineswegs endgültig. Viele Netzbetreiber blockieren ICMP-Pakete aus Sicherheitsgründen, obwohl viele andere dieser Praxis nicht zustimmen. Ein weiteres häufiges Problem ist das Verlassen auf das Zeitfeld als genauer Indikator für die Netzwerklatenz. ICMP-Pakete können durch zwischengeschaltete Netzwerkgeräte in der Rate begrenzt werden, und man sollte sich nicht darauf verlassen, dass sie echte Darstellungen der Anwendungslatenz liefern.
Das nächste Tool im Toolgürtel für die Fehlersuche auf Ebene 3 ist traceroute Befehl. Traceroute nutzt das Time to Live (TTL)-Feld in IP-Paketen, um den Weg zu bestimmen, den der Datenverkehr zu seinem Ziel nimmt. Traceroute sendet jeweils ein Paket, beginnend mit einer TTL von eins. Da das Paket während der Übertragung abläuft, sendet der Upstream-Router ein ICMP-Time-to-Live-Exceeded-Paket zurück. Traceroute erhöht dann die TTL, um den nächsten Hop zu bestimmen. Die resultierende Ausgabe ist eine Liste von Zwischenroutern, die ein Paket auf seinem Weg zum Ziel durchlaufen hat:
# traceroute www.google.com
traceroute to www.google.com (172.217.10.36), 30 hops max, 60 byte packets
1 acritelli-laptop (192.168.122.1) 0.103 ms 0.057 ms 0.027 ms
2 192.168.1.1 (192.168.1.1) 5.302 ms 8.024 ms 8.021 ms
3 142.254.218.133 (142.254.218.133) 20.754 ms 25.862 ms 25.826 ms
4 agg58.rochnyei01h.northeast.rr.com (24.58.233.117) 35.770 ms 35.772 ms 35.754 ms
5 agg62.hnrtnyaf02r.northeast.rr.com (24.58.52.46) 25.983 ms 32.833 ms 32.864 ms
6 be28.albynyyf01r.northeast.rr.com (24.58.32.70) 43.963 ms 43.067 ms 43.084 ms
7 bu-ether16.nycmny837aw-bcr00.tbone.rr.com (66.109.6.74) 47.566 ms 32.169 ms 32.995 ms
8 0.ae1.pr0.nyc20.tbone.rr.com (66.109.6.163) 27.277 ms * 0.ae4.pr0.nyc20.tbone.rr.com (66.109.1.35) 32.270 ms
9 ix-ae-6-0.tcore1.n75-new-york.as6453.net (66.110.96.53) 32.224 ms ix-ae-10-0.tcore1.n75-new-york.as6453.net (66.110.96.13) 36.775 ms 36.701 ms
10 72.14.195.232 (72.14.195.232) 32.041 ms 31.935 ms 31.843 ms
11 * * *
12 216.239.62.20 (216.239.62.20) 70.011 ms 172.253.69.220 (172.253.69.220) 83.370 ms lga34s13-in-f4.1e100.net (172.217.10.36) 38.067 ms
Traceroute scheint ein großartiges Tool zu sein, aber es ist wichtig, seine Grenzen zu verstehen. Wie bei ICMP können zwischengeschaltete Router die Pakete filtern, die traceroute verwendet, wie z. B. die ICMP-Meldung Time-to-Live Exceeded. Aber noch wichtiger ist, dass der Weg, den der Datenverkehr zu und von einem Ziel nimmt, nicht unbedingt symmetrisch und nicht immer gleich ist. Traceroute kann Sie zu der Annahme verleiten, dass Ihr Datenverkehr einen schönen, linearen Weg zu und von seinem Ziel nimmt. Diese Situation ist jedoch selten der Fall. Verkehr kann einem anderen Rückweg folgen, und Wege können sich aus vielen Gründen dynamisch ändern. Während traceroute kann in kleinen Unternehmensnetzwerken genaue Pfaddarstellungen liefern, ist jedoch oft nicht genau, wenn versucht wird, über große Netzwerke oder das Internet nachzuverfolgen.
Ein weiteres häufiges Problem, auf das Sie wahrscheinlich stoßen werden, ist das Fehlen eines Upstream-Gateways für eine bestimmte Route oder das Fehlen einer Standardroute. Wenn ein IP-Paket an ein anderes Netzwerk gesendet wird, muss es zur weiteren Verarbeitung an ein Gateway gesendet werden. Das Gateway sollte wissen, wie es das Paket an sein endgültiges Ziel weiterleitet. Die Liste der Gateways für verschiedene Routen wird in einer Routing-Tabelle gespeichert , die mit ip route inspiziert und manipuliert werden kann Befehle.
Wir können die Routing-Tabelle mit ip route show ausdrucken Befehl:
# ip route show
default via 192.168.122.1 dev eth0 proto dhcp metric 100
192.168.122.0/24 dev eth0 proto kernel scope link src 192.168.122.135 metric 100
Bei einfachen Topologien ist oft nur ein Standard-Gateway konfiguriert, dargestellt durch den „Standard“-Eintrag oben in der Tabelle. Ein fehlendes oder falsches Standard-Gateway ist ein häufiges Problem.
Wenn unsere Topologie komplexer ist und wir unterschiedliche Routen für verschiedene Netzwerke benötigen, können wir die Route auf ein bestimmtes Präfix prüfen:
# ip route show 10.0.0.0/8
10.0.0.0/8 via 192.168.122.200 dev eth0
Im obigen Beispiel senden wir den gesamten Datenverkehr für das Netzwerk 10.0.0.0/8 an ein anderes Gateway (192.168.122.200).
Obwohl es sich nicht um ein Layer-3-Protokoll handelt, ist DNS erwähnenswert, wenn wir über IP-Adressierung sprechen. Unter anderem übersetzt das Domain Name System (DNS) IP-Adressen in menschenlesbare Namen, wie z. B. www.redhat.com . DNS-Probleme sind sehr häufig und manchmal undurchsichtig zu beheben. Viele Bücher und Online-Anleitungen wurden über DNS geschrieben, aber wir konzentrieren uns hier auf die Grundlagen.
Ein verräterisches Zeichen für DNS-Probleme ist die Möglichkeit, eine Verbindung zu einem Remote-Host über die IP-Adresse, aber nicht über den Hostnamen herzustellen. Durchführen eines schnellen nslookup auf dem Hostnamen kann uns einiges verraten (nslookup ist Teil der bind-utils Paket auf Red Hat Enterprise Linux-basierten Systemen):
# nslookup www.google.com
Server: 192.168.122.1
Address: 192.168.122.1#53
Non-authoritative answer:
Name: www.google.com
Address: 172.217.3.100
Die obige Ausgabe zeigt dem Server, dass die Suche für 192.168.122.1 durchgeführt wurde und die resultierende IP-Adresse 172.217.3.100 war.
Wenn Sie ein nslookup durchführen für einen Host, aber ping oder traceroute Versuchen Sie, eine andere IP-Adresse zu verwenden, handelt es sich wahrscheinlich um ein Problem mit dem Eintrag einer Host-Datei. Untersuchen Sie daher die Hostdatei auf Probleme:
# nslookup www.google.com
Server: 192.168.122.1
Address: 192.168.122.1#53
Non-authoritative answer:
Name: www.google.com
Address: 172.217.12.132
# ping -c 1 www.google.com
PING www.google.com (1.2.3.4) 56(84) bytes of data.
^C
--- www.google.com ping statistics ---
1 packets transmitted, 0 received, 100% packet loss, time 0ms
# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
1.2.3.4 www.google.com
Beachten Sie, dass im obigen Beispiel die Adresse www.google.com ist aufgelöst auf 172.217.12.132. Als wir jedoch versuchten, den Host zu pingen, wurde der Datenverkehr an 1.2.3.4 gesendet. Werfen Sie einen Blick auf /etc/hosts -Datei können wir eine Überschreibung sehen, die jemand unachtsam hinzugefügt haben muss. Probleme mit dem Überschreiben von Hostdateien sind extrem häufig, insbesondere wenn Sie mit Anwendungsentwicklern zusammenarbeiten, die diese Überschreibungen häufig vornehmen müssen, um ihren Code während der Entwicklung zu testen.
Schicht 4:Die Transportschicht
Die Transportschicht besteht aus den Protokollen TCP und UDP, wobei TCP ein verbindungsorientiertes Protokoll und UDP verbindungslos ist. Anwendungen lauschen auf Sockets , die aus einer IP-Adresse und einem Port bestehen. Datenverkehr, der an eine IP-Adresse an einem bestimmten Port gerichtet ist, wird vom Kernel an die lauschende Anwendung geleitet. Eine vollständige Erörterung dieser Protokolle würde den Rahmen dieses Artikels sprengen, daher konzentrieren wir uns darauf, wie Verbindungsprobleme auf diesen Ebenen behoben werden können.
Das erste, was Sie vielleicht tun möchten, ist zu sehen, welche Ports auf dem Localhost lauschen. Das Ergebnis kann nützlich sein, wenn Sie keine Verbindung zu einem bestimmten Dienst auf dem Computer herstellen können, z. B. einem Web- oder SSH-Server. Ein weiteres häufiges Problem tritt auf, wenn ein Daemon oder Dienst nicht gestartet wird, weil etwas anderes an einem Port lauscht. Die ss Der Befehl ist von unschätzbarem Wert, um diese Arten von Aktionen auszuführen:
# ss -tunlp4
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port
udp UNCONN 0 0 *:68 *:* users:(("dhclient",pid=3167,fd=6))
udp UNCONN 0 0 127.0.0.1:323 *:* users:(("chronyd",pid=2821,fd=1))
tcp LISTEN 0 128 *:22 *:* users:(("sshd",pid=3366,fd=3))
tcp LISTEN 0 100 127.0.0.1:25 *:* users:(("master",pid=3600,fd=13))
Lassen Sie uns diese Flags aufschlüsseln:
- -t - TCP-Ports anzeigen.
- -u - UDP-Ports anzeigen.
- -n - Versuchen Sie nicht, Hostnamen aufzulösen.
- -l - Nur Listening Ports anzeigen.
- -p - Zeigt die Prozesse an, die einen bestimmten Socket verwenden.
- -4 - Nur IPv4-Sockets anzeigen.
Wenn wir uns die Ausgabe ansehen, können wir mehrere Listening-Dienste sehen. Die sshd Anwendung lauscht auf Port 22 auf allen IP-Adressen, gekennzeichnet durch *:22 Ausgabe.
Die ss command ist ein leistungsstarkes Tool, und eine Überprüfung seiner kurzen Manpage kann Ihnen helfen, Flags und Optionen zu finden, um zu finden, wonach Sie suchen.
Ein weiteres häufiges Problembehandlungsszenario betrifft Remoteverbindungen. Stellen Sie sich vor, Ihr lokaler Rechner kann keine Verbindung zu einem entfernten Port herstellen, z. B. MySQL auf Port 3306. Ein unwahrscheinliches, aber häufig installiertes Tool kann Ihr Freund sein, wenn Sie diese Art von Problemen beheben:telnet . Das telnet versucht, eine TCP-Verbindung mit dem von Ihnen angegebenen Host und Port herzustellen. Diese Funktion eignet sich perfekt zum Testen der Remote-TCP-Konnektivität:
# telnet database.example.com 3306
Trying 192.168.1.10...
^C
In der obigen Ausgabe telnet hängt, bis wir es töten. Dieses Ergebnis sagt uns, dass wir Port 3306 auf dem Remote-Computer nicht erreichen können. Möglicherweise hört die Anwendung nicht zu und wir müssen die vorherigen Schritte zur Fehlerbehebung mit ss anwenden auf dem Remote-Host – wenn wir Zugriff haben. Eine andere Möglichkeit ist eine Host- oder Zwischen-Firewall, die den Datenverkehr filtert. Möglicherweise müssen wir mit dem Netzwerkteam zusammenarbeiten, um die Layer-4-Konnektivität über den Pfad zu überprüfen.
Telnet funktioniert gut für TCP, aber was ist mit UDP? Der netcat Tool bietet eine einfache Möglichkeit, einen entfernten UDP-Port zu überprüfen:
# nc 192.168.122.1 -u 80
test
Ncat: Connection refused.
Der netcat Das Dienstprogramm kann für viele andere Dinge verwendet werden, einschließlich zum Testen der TCP-Konnektivität. Beachten Sie, dass netcat möglicherweise nicht auf Ihrem System installiert, und es wird oft als Sicherheitsrisiko angesehen, es herumliegen zu lassen. Möglicherweise möchten Sie es deinstallieren, wenn Sie mit der Fehlerbehebung fertig sind.
In den obigen Beispielen wurden allgemeine, einfache Dienstprogramme erörtert. Ein viel leistungsfähigeres Werkzeug ist jedoch nmap . Ganze Bücher wurden nmap gewidmet Funktionalität, daher werden wir es in diesem Anfängerartikel nicht behandeln, aber Sie sollten einige der Dinge wissen, die es kann:
- TCP- und UDP-Port-Scannen von Remote-Rechnern.
- Betriebssystem-Fingerabdruck.
- Bestimmen, ob entfernte Ports geschlossen oder einfach gefiltert werden.
Abschluss
Wir haben in diesem Artikel viele einführende Grundlagen zu Netzwerken behandelt und uns den Netzwerkstapel von Kabeln und Switches bis hin zu IP-Adressen und Ports hochgearbeitet. Die hier besprochenen Tools sollten Ihnen einen guten Ausgangspunkt für die Behebung grundlegender Netzwerkverbindungsprobleme bieten und sich als hilfreich erweisen, wenn Sie versuchen, Ihrem Netzwerkteam so viele Details wie möglich bereitzustellen.
Während Sie auf Ihrem Weg zur Fehlerbehebung im Netzwerk voranschreiten, werden Sie zweifellos auf zuvor unbekannte Befehlsflags, ausgefallene Einzeiler und leistungsstarke neue Tools (tcpdump und Wireshark sind meine Favoriten), um den Ursachen Ihrer Netzwerkprobleme auf den Grund zu gehen. Viel Spaß und denken Sie daran:Die Pakete lügen nicht!