Komma-getrennte Werte auch bekannt als CSV sind halbstrukturierte Daten, die ein Komma als Trennzeichen verwenden, um die Wörter zu trennen. CSV-Dateiformate sind bei Datenprofis sehr beliebt, da sie mit vielen CSV-Dateien umgehen und diese verarbeiten müssen, um Erkenntnisse zu gewinnen. In diesem Artikel konzentrieren wir uns darauf, wie CSV-Dateien in Bash-Shell-Skripten unter Linux geparst werden.
In den meisten Teilen dieses Artikels werde ich awk verwenden und sed Tools für das CSV-Parsing, anstatt verschiedene Befehle wie grep , cut , tr usw.
Das awk Dienstprogramm reduziert die Komplexität der Weiterleitung mehrerer Befehle oder das Schreiben einer Schleife mit Logik, um die Daten zu erfassen. Stattdessen können Sie einen Einzeiler-Code in awk schreiben um die Arbeit zu erledigen.
1. CSV-Datei zur Verarbeitung vorbereiten
Ihre CSV-Datei wurde möglicherweise aus einer Datenbank oder einer API generiert, oder Sie haben möglicherweise einige Befehle ausgeführt und die Ausgabe in das Trennzeichen im CSV-Format konvertiert. In jedem Fall müssen Sie zuerst den Datensatz analysieren, bevor Sie Ihre Logik darauf anwenden.
Als Best Practice sollten Sie Ihren Datensatz bereinigen, bevor Sie ihn verwenden. Warum sollten wir den Datensatz bereinigen? Es kann Situationen geben, in denen es leere Zellenwerte oder keine ordnungsgemäße Formatierung in Kopfzeilen, zusätzliche Spalten gibt, die für die Verarbeitung nicht erforderlich sind, und vieles mehr.
Ich verwende die folgenden CSV-Daten, die ich von Kaggle abgerufen habe zu Demonstrationszwecken.
Player_Id,Player_Name,DOB,Batting_Hand,Bowling_Skill,Country 1,SC Ganguly,8-Jul-72,Left_Hand,Right-arm medium, 2,BB McCullum,27-Sep-81,Right_Hand,Right-arm medium, 3,RT Ponting,19-Dec-74,Right_Hand,Right-arm medium, 4,DJ Hussey,15-Jul-77,Right_Hand,Right-arm offbreak,Australia 5,Mohammad Hafeez,17-Oct-80,,Right-arm offbreak,Pakistan 6,R Dravid,11-Jan-73,,Right-arm offbreak,India 7,W Jaffer,16-Feb-78,,Right-arm offbreak,India 8,V Kohli,5-Nov-88,,Right-arm medium,India 9,JH Kallis,16-Oct-75,,Right-arm fast-medium,South Africa 10,CL White,18-Aug-83,Right_Hand,Legbreak googly,Australia 11,MV Boucher,3-Dec-76,Right_Hand,Right-arm medium,South Africa 12,B Akhil,7-Oct-77,Right_Hand,Right-arm medium-fast,India 13,AA Noffke,30-Apr-77,Right_Hand,Right-arm fast-medium,Australia 14,P Kumar,2-Oct-86,Right_Hand,Right-arm medium,India 15,Z Khan,7-Oct-78,Right_Hand,Left-arm fast-medium,India
1.1. Leere Zellen ersetzen
In einigen Fällen enthält die CSV-Datei keine Werte in bestimmten Zellen. Sehen Sie sich den folgenden Screenshot an, wo einige leere Zellen zwischen den Spalten sind.
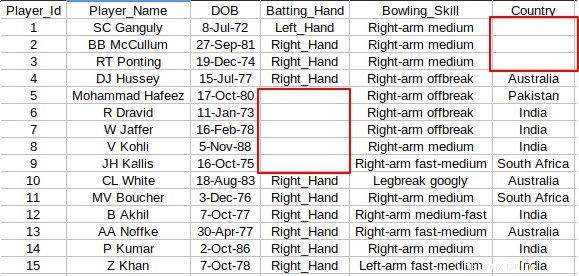
Ich würde es immer durch "NA" oder "Kein Wert" ersetzen, damit es keine leeren Zellen gibt. Sie können das folgende awk verwenden Snippet, um jede leere Zelle durch Ihren gewünschten Wert zu ersetzen. In diesem Fall ersetze ich die leeren Zellen durch "Kein Wert".
awk 'BEGIN{FS=",";OFS=","}
{
for(i=1;i<=NF;i++)
{
if($i == ""){
$i="No Value"
}
}
print
}' ~/Downloads/Player.csv > player_cleaned.csv
Dieses Snippet funktioniert so, dass ich das Feldtrennzeichen und das Ausgabefeldtrennzeichen auf Komma setze (FS=",";OFS="," ). Verwendung von for loop , durch jede Zelle in einer Zeile iterieren, und wenn eine Zelle leer ist ($i == "" ) und ersetzen Sie es dann durch "No value" ($i="No value" ). Sie müssen die Änderungen in eine neue Datei umleiten.
Empfohlene Lektüre:
- Bash-Umleitung mit Beispielen erklärt
1.2. Den Header groß schreiben
CSV-Dateien können Kopfzeilen haben oder auch nicht. Aber wenn es eine Überschrift gibt, würde ich sie immer groß schreiben, um die Lesbarkeit zu verbessern. Das geht ganz einfach mit awk oder sed . Ich werde Ihnen beide Wege zeigen.
awk 'BEGIN{FS=",";OFS=","}
{
if(NR==1){
print toupper($0)
} else {
print
}
}' player.csv > player_cleaned.csv
Hier prüfen wir, ob die Zeile die erste Zeile ist, indem wir (NR==1 ) und mit toupper() Funktion, um es zu kapitalisieren. Dasselbe Snippet kann als Einzeiler geschrieben werden.
awk 'NR==1{ print toupper($0) }NR>1' player.csv > player_cleaned.csv
Mit awk , müssen Sie die Änderungen erneut in eine neue Datei umleiten. Stattdessen können Sie 'sed verwenden ', um die Änderungen direkt in der Datei zu ändern. Hier \U wandelt die Groß-/Kleinschreibung in Großbuchstaben um. Wenn Sie eine Umwandlung in Kleinbuchstaben vornehmen möchten, verwenden Sie \L .
$ sed -i -e '1 s/(.*)/\U\1/' player_cleaned.csv
$ cat player_cleaned.csv
1.3. Nachgestelltes Komma entfernen
Ihre CSV-Datei kann am Ende ein Komma haben. Um die nachgestellten Kommas zu löschen, können Sie die folgende Methode befolgen.
Ab Zeile 7 habe ich absichtlich ein nachgestelltes Komma hinzugefügt bis 11 in meiner Datendatei.
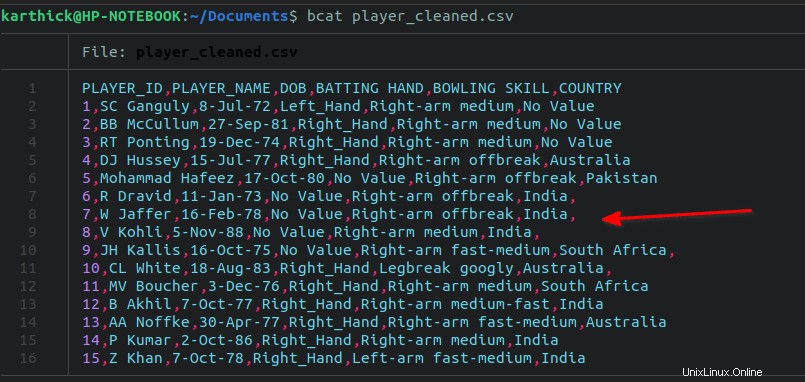
Um alle nachgestellten Kommas zu entfernen, führen Sie den folgenden sed aus Befehl:
$ sed -i 's/,$//' ~/Documents/player_cleaned.csv
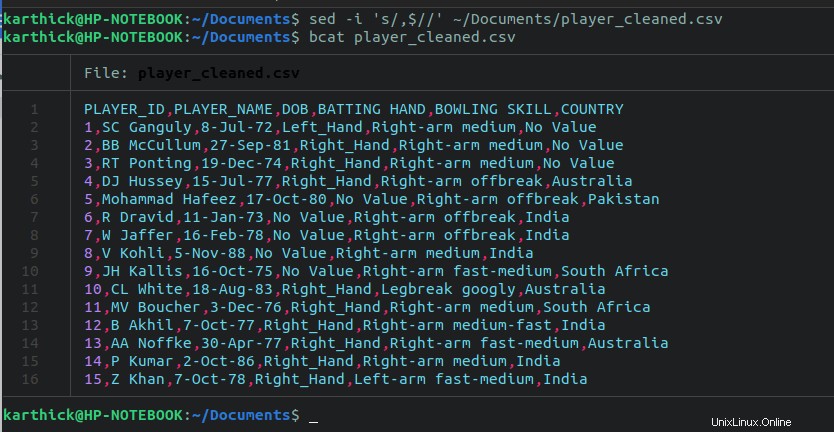
Jetzt sind wir mit dem Reinigungsteil fertig. Möglicherweise sind für Sie einige weitere Schritte erforderlich, aber das hängt davon ab, wie Ihre CSV-Datei strukturiert ist und was bereinigt werden muss.
2. Pretty Print CSV-Datei im Terminal
Wenn Sie versuchen, die CSV-Dateien im Terminal anzuzeigen, gibt es einige Optionen, mit denen Sie die Datei im Tabellenformat drucken können, um die Lesbarkeit zu verbessern.
2.1. Spaltenbefehl
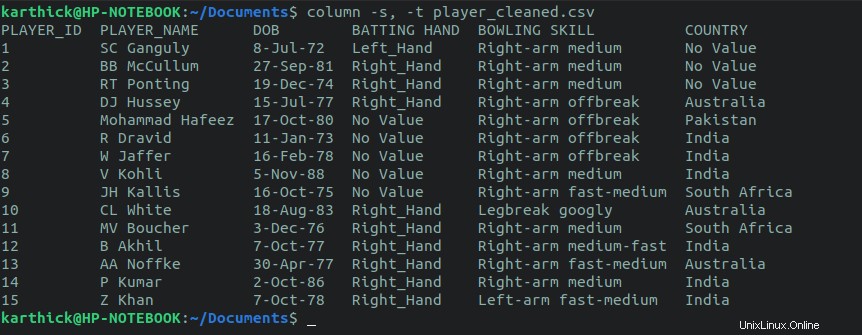
Der erste Ansatz besteht darin, die column zu verwenden Befehl. Der Spaltenbefehl akzeptiert ein Trennzeichen, das auf Komma gesetzt ist, und ein Trennzeichen, um die Spalte zu teilen, die im folgenden Befehl auf Tabulator gesetzt ist. Sie können auch Ihre eigenen benutzerdefinierten Trennzeichen festlegen.
$ cat player_cleaned.csv | column -s, -t $ column -s, -t player_cleaned.csv
2.2. CSV-Look-Befehl
Csvlook ist ein Dienstprogramm, das mit dem csvkit-Paket geliefert wird. Es ist nicht nötig, ein Trennzeichen zu setzen, wie wir es bei der column getan haben Befehl.
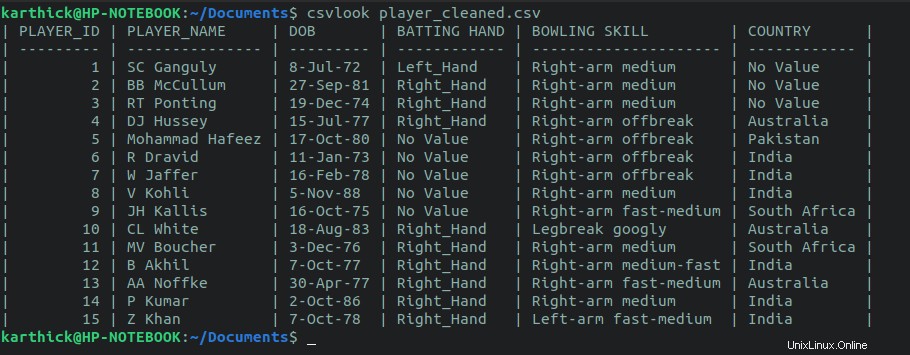
$ cat player_cleaned.csv | csvlook
$ csvlook player_cleaned.csv
2.3. Python Pretty Table
Wenn Sie die Python-Datei prettytable haben Wenn das Modul installiert ist, können Sie den folgenden Einzeiler ausführen und die CSV-Datei umleiten, um die Tabelle zu generieren.
python -c "import sys,prettytable; print(prettytable.from_csv(sys.stdin))" < player_cleaned.csv
Sie können auch einen Alias erstellen für den Einzeiler und übergeben Sie den Dateinamen als Argument.
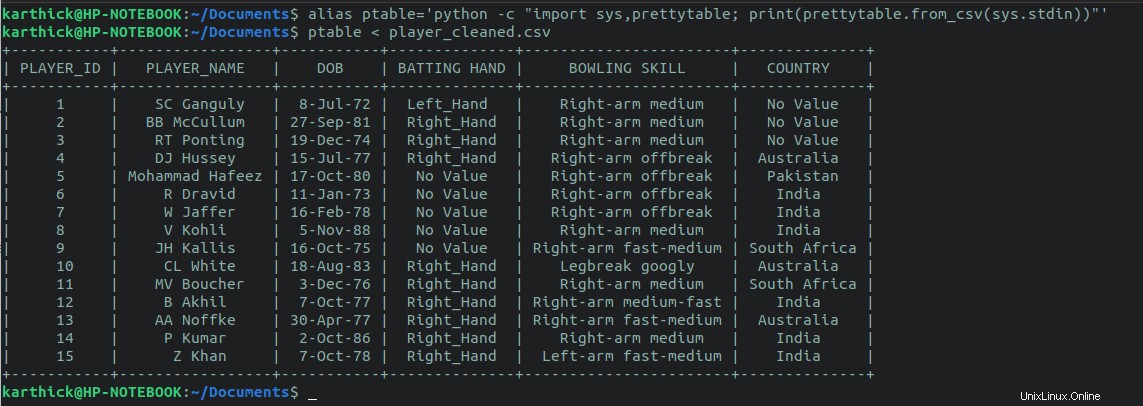
$ alias ptable='python -c "import sys,prettytable; print(prettytable.from_csv(sys.stdin))"'
$ ptable < player_cleaned.csv
3. Abrufen von Daten aus einer CSV-Datei
3.1. Zeilen- und Spaltenanzahl drucken
Führen Sie den folgenden Befehl aus, um die Anzahl der Spalten in der CSV-Datei abzurufen. Hier die Variable NF steht für die Anzahl der Felder, getrennt durch ein Komma als Trennzeichen.
$ awk -F, 'END{print NF}' player_cleaned.csv
6
Führen Sie den folgenden Befehl aus, um die Anzahl der Zeilen abzurufen. Hier die Variable NR stellt den aktuellen Datensatz dar (d. h. jede Zeile wird als ein Datensatz betrachtet).
$ awk -F, 'END{print NR}' player_cleaned.csv
16 Führen Sie den folgenden Befehl aus, um die erste Zeile (Kopfzeile) zu überspringen und die Anzahl der Zeilen zu berechnen.
$ awk -F, 'END{print NR-1}' player_cleaned.csv
15 3.2. Gesamte CSV-Datei drucken
Das ist ziemlich einfach. Sie können cat verwenden oder awk um die gesamte CSV-Datei zu drucken.
$ cat player_cleaned.csv
$ awk '{print}' player_cleaned.csv 3.3. Nur Kopfzeile aus CSV-Datei drucken
Wenn Sie nur die Kopfzeile drucken, erhalten Sie einen guten Überblick darüber, welche Art von Daten Ihre CSV-Datei enthält. Sie können den head verwenden oder awk Befehl, nur den Header abzurufen.
$ head -n 1 player_cleaned.csv
$ awk 'NR==1' player_cleaned.csv PLAYER_ID,PLAYER_NAME,DOB,BATTING HAND,BOWLING SKILL,COUNTRY
3.4. Kopfzeile ausschließen
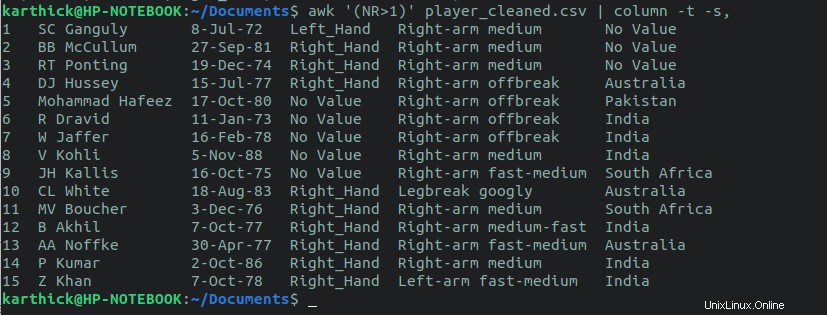
Um die Kopfzeile auszuschließen und alle anderen Zeilen zu drucken, verwenden Sie den awk Befehl. Die awk-Variable NR > 1 wird die erste Zeile übersprungen.
$ awk '(NR>1)' player_cleansed.csv
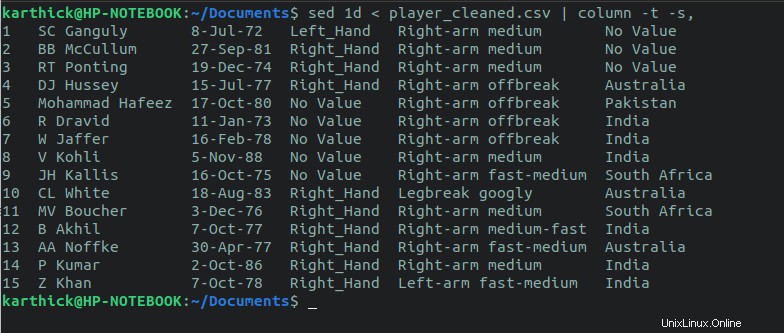
Sed kann auch verwendet werden, um die erste Zeile auszuschließen und alle anderen Zeilen zu drucken. Der 1d flag löscht die erste Zeile und gibt alle anderen Zeilen auf stdout (Terminal) aus.
$ sed 1d < player_cleaned.csv
3.5. Einzelne Spalten drucken
Wir können die Spaltenposition verwenden, um die gesamte Spalte zu drucken. Um dies zu erreichen, gibt es zwei Ansätze. Der erste Ansatz wird die Verwendung von awk sein und der zweite Ansatz wird die Verwendung von Schleifen sein . Awk wird viel einfacher sein, die Spalte zu greifen.
Awk teilt die Zeile standardmäßig basierend auf dem Trennzeichen und speichert die Werte in $1 , $2 , $3 usw. Das Standardtrennzeichen für awk ist Leerzeichen .
Sehen Sie sich das folgende Snippet an, in dem das Feldtrennzeichen (FS="," ) und Ausgabefeldtrennzeichen (OFS="," ) wird auf Komma gesetzt. Die print-Anweisung druckt die erste Spalte, zweite Spalte und sechste Spalte.
awk 'BEGIN{FS=",";OFS=","}
{
print $1,$2,$6
}' player_cleansed.csv Sie können das obige Snippet auch in einem Einzeiler schreiben.
awk 'BEGIN{FS=",";OFS=","}{print $1,$2,$6}' player_cleansed.csv 
Nun wäre der zweite Ansatz Schleifen zu verwenden.
IFS=","
while read -r -a fields
do
echo ${fields[0]},${fields[1]},${fields[5]}
done < player_cleaned.csv Lassen Sie mich erklären, was genau passiert, wenn Sie das obige Snippet ausführen.
- Wir setzen das interne Feldtrennzeichen IFS auf Komma.
- Mit dem read-Befehl erstellen wir ein Array namens "fields" und leiten die Eingabedatei an die
while loopum . - Bei jeder Iteration wird Zeile für Zeile gelesen und die Zeile als Array-Elemente in "Feldern" gespeichert, sodass Sie die Indexposition des Arrays verwenden können, um nur die jeweilige Spalte zu erfassen.
Hinweis: Der Indexwert beginnt bei 0..N
3.6. Zeile drucken, die der Bedingung entspricht
Wenn Sie die Zeilen drucken möchten, die einer bestimmten Bedingung entsprechen, können Sie dies einfach mit awk tun . Gehen wir einige Szenarien durch.
Führen Sie den folgenden Befehl aus, um alle Zeilen zu drucken, die mit einem Wert in einer Spalte übereinstimmen. Hier versuche ich, alle Zeilen zu drucken, die mit dem Wert "Indien" in Spalte 6 übereinstimmen.
$ awk -F , '$6 == "India"' player_cleaned.csv

Führen Sie den folgenden Befehl aus, um alle Zeilen zu drucken, die nicht mit einem bestimmten Wert übereinstimmen. Anstelle eines Gleichheitsoperators verwenden wir den Ungleich-Operator .
$ awk -F , '$6 != "India"' player_cleaned.csv
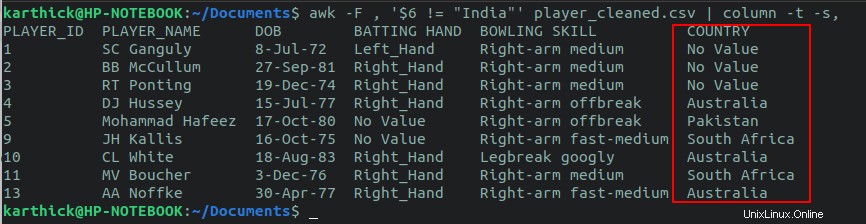
Sie können auch eine Bedingungsprüfung für mehr als eine Spalte durchführen, indem Sie den logischen UND- und den logischen ODER-Operator verwenden. Angenommen, ich möchte alle Zeilen überprüfen, in denen das Land „India“ und die Schlaghand „Right_hand“ ist.
Hier, $4 zeigt auf die 4. Spalte und $6 zeigt auf die 6. Spalte. Das Symbol && wird als logischer UND-Operator verwendet, um zwei Bedingungen auszuwerten.
$ awk -F , '$4 == "Right_Hand" && $6 == "India"' player_cleaned.csv

Wenn Sie den Header zusammen mit dem Ergebnis der bedingten Prüfung einschließen möchten, verwenden Sie den folgenden Befehl. Zuerst drucke ich die erste Zeile mit NR==1 , und verwenden Sie dann den logischen UND-Operator, der die Bedingungsprüfung ausführt, um die Ergebnisse zu drucken.
$ awk 'NR==1' player_cleaned.csv && awk -F , '$4 == "Right_Hand" && $6 == "India"' player_cleaned.csv
Wenn Sie die Ausgabe drucken oder umleiten möchten, führen Sie den gesamten Befehl in einer Subshell aus, indem Sie ihn in Klammern einschließen .
$ (awk 'NR==1' player_cleaned.csv && awk -F , '$4 == "Right_Hand" && $6 == "India"' player_cleaned.csv) | column -t -s,

Ein Hinweis zu Csvkit
Was wir bisher in diesem Artikel gesehen haben, ist einfach und unkompliziert. Aber wenn Ihre CSV-Datei eine komplexe Struktur hat, wird es mühsam, sie mit dem obigen Ansatz zu analysieren. Es gibt ein Dienstprogramm namens CSVKIT , ein hervorragendes Dienstprogramm zum Arbeiten mit CSV-Dateien in Bash.
Das Problem mit dem csvkit-Dienstprogramm ist, dass es standardmäßig in Ihrer Distribution installiert ist und Sie es möglicherweise manuell installieren müssen. In Ihrer Unternehmensumgebung ist dies möglicherweise nicht möglich, da es einige Einschränkungen bei der Installation externer Pakete geben kann. Aber dieses Dienstprogramm ist erwähnenswert und wir werden einen separaten ausführlichen Artikel dafür erstellen.
Schlussfolgerung
In diesem Handbuch haben wir gesehen, wie Sie mit CSV-Dateien mit awk, sed arbeiten. Sie können auch andere Dienstprogramme wie cut, grep, tr usw. verwenden, um das gewünschte Ergebnis zu erzielen, aber awk und sed machen Ihr Leben einfacher und reduzieren die Komplexität des Schreibens vieler Codes. Wenn Sie Feedback haben, erwähnen Sie es im Kommentarbereich und wir freuen uns, es von Ihnen zu hören.
Ähnliches Lesen:
- Bash-Skripting – Analysieren Sie Argumente in Bash-Skripten mithilfe von getopts
- So analysieren und verschönern Sie JSON mit Linux-Befehlszeilentools