Einführung
Fehlende Daten sind ein häufiges Problem bei der Arbeit mit realistischen Datensätzen. Die Kenntnis und Analyse der Ursachen fehlender Werte trägt dazu bei, ein klareres Bild der Schritte zur Lösung des Problems zu erhalten. Python bietet viele Methoden zur Analyse und Lösung des Problems nicht erfasster Daten.
Dieses Tutorial erklärt die Ursachen und Lösungen fehlender Daten anhand eines praktischen Beispiels in Python.

Voraussetzungen
- Python 3 installiert und konfiguriert
- Installierte Pandas- und NumPy-Module
- Ein Datensatz mit fehlenden Werten
Wie wirken sich fehlende Daten auf Ihren Algorithmus aus?
Es gibt drei Möglichkeiten, wie sich fehlende Daten auf Ihren Algorithmus und Ihre Forschung auswirken:
- Fehlende Werte vermitteln eine falsche Vorstellung von den Daten selbst, was zu Mehrdeutigkeit führt . Wenn Sie beispielsweise einen Durchschnitt für eine Spalte berechnen, in der die Hälfte der Informationen nicht verfügbar oder auf Null gesetzt ist, erhalten Sie die falsche Metrik.
- Wenn keine Daten verfügbar sind, funktionieren einige Algorithmen nicht. Einige Algorithmen für maschinelles Lernen mit Datensätzen, die NaN enthalten (Not a Number)-Werte lösen einen Fehler aus.
- Das Muster fehlender Daten ist ein wesentlicher Faktor. Fehlen zufällig Daten aus einem Datensatz, dann sind die Informationen in den meisten Fällen trotzdem hilfreich. Wenn jedoch systematisch Informationen fehlen, ist jede Analyse voreingenommen.
Was kann fehlende Daten verursachen?
Die Ursache fehlender Daten hängt von den Datenerhebungsmethoden ab. Das Identifizieren der Ursache hilft bei der Bestimmung des einzuschlagenden Pfads bei der Analyse eines Datensatzes.
Hier sind einige Beispiele dafür, warum Datensätze fehlende Werte aufweisen:
Umfragen . Durch Umfragen gesammelte Daten enthalten oft fehlende Informationen. Ob aus Datenschutzgründen oder weil Sie einfach keine Antwort auf eine bestimmte Frage wissen, Fragebögen enthalten oft fehlende Daten.
IoT . Bei der Arbeit mit IoT-Geräten und der Erfassung von Daten von Sensorsystemen zu Edge-Computing-Servern treten viele Probleme auf. Ein vorübergehender Kommunikationsverlust oder ein fehlerhafter Sensor führen oft dazu, dass Daten verloren gehen.
Eingeschränkter Zugriff . Einige Daten haben eingeschränkten Zugriff, insbesondere Daten, die durch HIPAA, GDPR und andere Vorschriften geschützt sind.
Manueller Fehler . Manuell eingegebene Daten weisen normalerweise aufgrund der Art des Auftrags oder der großen Menge an Informationen Inkonsistenzen auf.
Wie geht man mit fehlenden Daten um?
Um den Prozess zu analysieren und zu erklären, wie mit fehlenden Daten in Python umgegangen wird, verwenden wir:
- Datensatz für Baugenehmigungen in San Francisco
- Jupyter Notebook-Umgebung
Die Ideen gelten für verschiedene Datensätze sowie andere Python-IDEs und -Editoren.
Daten importieren und anzeigen
Laden Sie das Dataset herunter und kopieren Sie den Pfad der Datei. Verwenden Sie die Pandas-Bibliothek zum Importieren und Speichern die Building_Permits.csv Daten in eine Variable:
import pandas as pd
data = pd.read_csv('<path to Building_Permits.csv>')Um zu bestätigen, dass die Daten korrekt importiert wurden, führen Sie Folgendes aus:
data.head()Der Befehl zeigt die ersten Zeilen der Daten in tabellarischer Form:
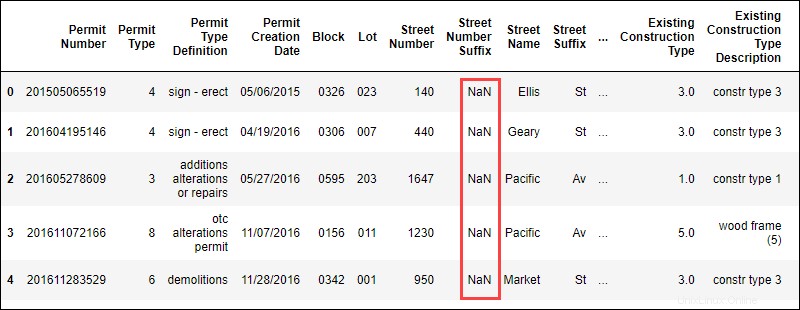
Das Vorhandensein von NaN Werte gibt an, dass in diesem Datensatz Daten fehlen.
Fehlende Werte finden
Finden Sie heraus, wie viele fehlende Werte pro Spalte vorhanden sind, indem Sie Folgendes ausführen:
data.isnull().sum()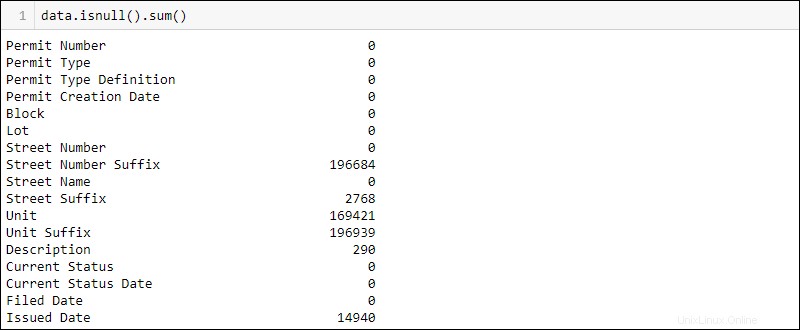
Die Zahlen sind aussagekräftiger, wenn sie als Prozentwerte angezeigt werden. Um die Summen in Prozent anzuzeigen, dividieren Sie die Zahl durch die Gesamtlänge des Datensatzes:
data.isnull().sum()/len(data)
Um die Spalten mit dem höchsten Prozentsatz fehlender Daten zuerst anzuzeigen, fügen Sie .sort_values(ascending=False) hinzu zur vorherigen Codezeile:
data.isnull().sum().sort_values(ascending = False)/len(data)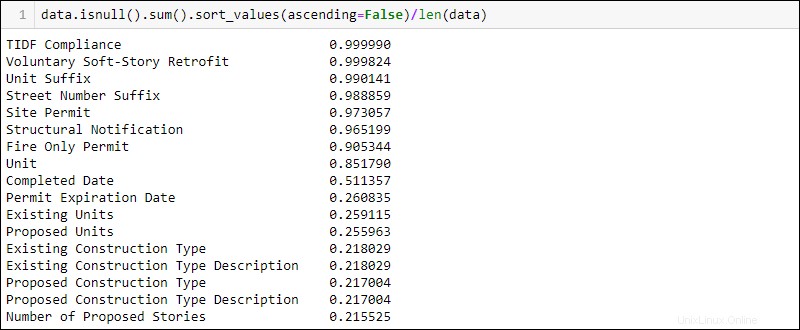
Überprüfen Sie vor dem Entfernen oder Ändern von Werten die Dokumentation auf Gründe für das Fehlen von Daten. Beispielsweise fehlen in der Spalte TIDF-Compliance fast alle Daten. Die Dokumentation besagt jedoch, dass dies eine neue gesetzliche Anforderung ist, sodass es sinnvoll ist, dass die meisten Werte fehlen.
Fehlende Werte markieren
Zeigen Sie die allgemeinen statistischen Daten für einen Datensatz an, indem Sie Folgendes ausführen:
data.describe()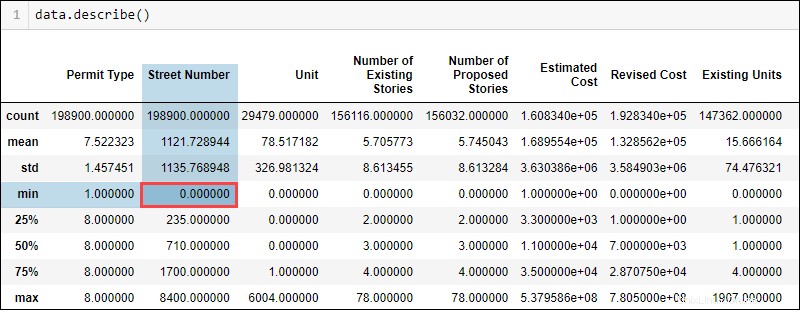
Je nach Datentyp und Domänenwissen passen einige Werte nicht logisch zusammen. Beispielsweise darf eine Hausnummer nicht Null sein. Der Mindestwert zeigt jedoch Null an, was auf wahrscheinlich fehlende Werte in der Spalte mit der Hausnummer hinweist.
Um zu sehen, wie viele Hausnummer Werte sind 0, führen Sie aus:
(data['Street Number'] == 0).sum()Tauschen Sie mithilfe der NumPy-Bibliothek den Wert gegen NaN aus, um die fehlende Information anzugeben:
import numpy as np
data['Street Number'] = data['Street Number'].replace(0, np.nan)Die Überprüfung der aktualisierten statistischen Daten zeigt nun, dass die minimale Hausnummer 1 ist.
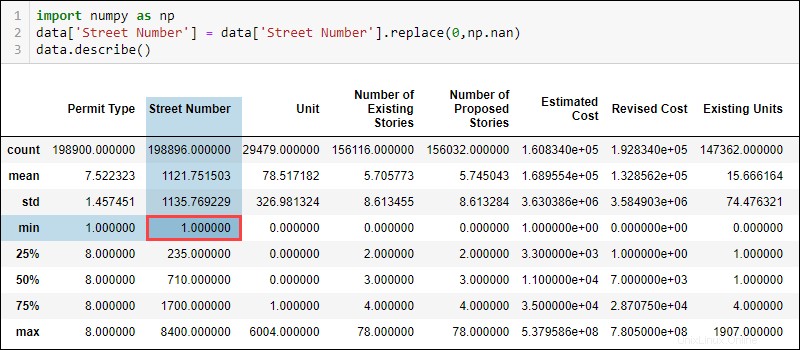
Ebenso zeigt die Summe der NaN-Werte jetzt an, dass Daten in der Spalte „Hausnummer“ fehlen.
Andere Werte in der Spalte „Straßennummer“ ändern sich ebenfalls, z. B. die Anzahl und der Mittelwert. Der Unterschied ist nicht riesig, da nur wenige Werte 0 sind. Allerdings sind die Unterschiede in den Metriken bei größeren Mengen falsch gekennzeichneter Daten auch deutlicher.
Fehlende Werte löschen
Der einfachste Weg, mit fehlenden Werten in Python umzugehen, besteht darin, die Zeilen oder Spalten zu entfernen, in denen Informationen fehlen.
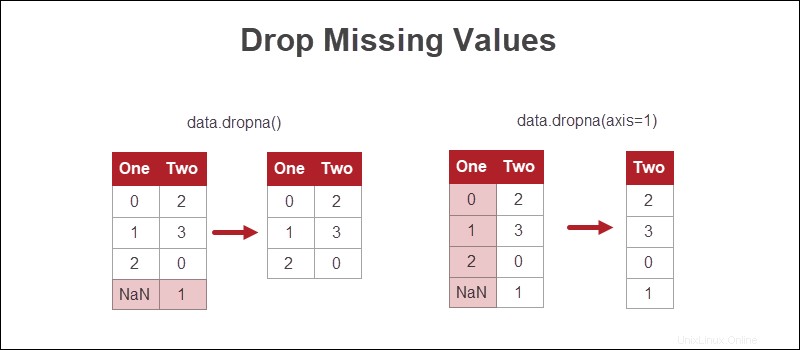
Obwohl dieser Ansatz am schnellsten ist, ist der Verlust von Daten nicht die praktikabelste Option. Wenn möglich, sind andere Methoden vorzuziehen.
Zeilen mit fehlenden Werten löschen
Um Zeilen mit fehlenden Werten zu entfernen, verwenden Sie dropna Funktion:
data.dropna()Bei Anwendung auf das Beispiel-Dataset entfernte die Funktion alle Datenzeilen, da jede Datenzeile mindestens eine enthält NaN-Wert.
Spalten mit fehlenden Werten löschen
Um Spalten mit fehlenden Werten zu entfernen, verwenden Sie dropna funktionieren und die Achse bereitstellen:
data.dropna(axis = 1)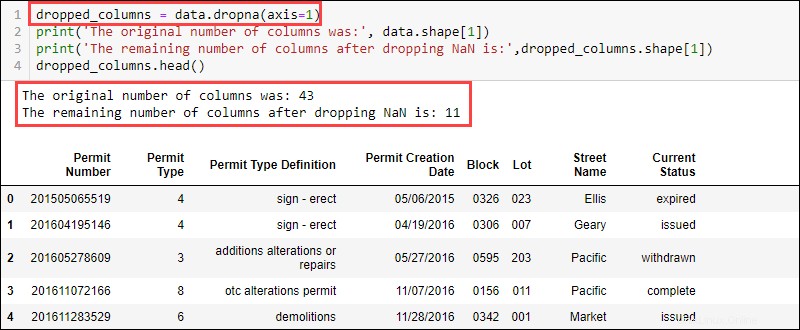
Der Datensatz enthält jetzt 11 Spalten im Vergleich zu den anfänglich verfügbaren 43.
Fehlende Werte ersetzen
Die Imputation ist eine Methode, fehlende Werte mit Zahlen unter Verwendung einer bestimmten Strategie zu füllen. Einige Optionen, die für die Imputation in Betracht gezogen werden sollten, sind:
- Ein Mittelwert, Median oder Moduswert aus dieser Spalte.
- Ein eindeutiger Wert, z. B. 0 oder -1.
- Ein zufällig ausgewählter Wert aus dem vorhandenen Satz.
- Anhand eines Vorhersagemodells geschätzte Werte.
Das Pandas DataFrame-Modul bietet eine Methode zum Füllen von NaN-Werten mithilfe verschiedener Strategien. Um beispielsweise alle NaN-Werte durch 0 zu ersetzen:
data.fillna(0)
Die fillna -Funktion bietet verschiedene Methoden zum Ersetzen fehlender Werte. Das Auffüllen ist eine gängige Methode, bei der die fehlenden Informationen mit dem Wert aufgefüllt werden, der danach kommt:
data.fillna(method = 'bfill')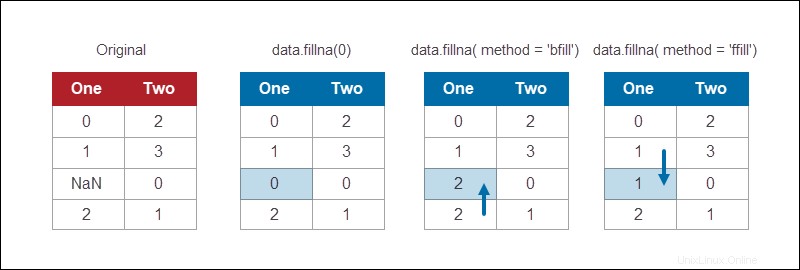
Wenn der letzte Wert fehlt, füllen Sie alle verbleibenden NaNs mit dem gewünschten Wert. Um beispielsweise alle möglichen Werte aufzufüllen und die restlichen mit 0 aufzufüllen, verwenden Sie:
data.fillna(method = 'bfill', axis = 0).fillna(0)Verwenden Sie in ähnlicher Weise ffill um Werte nach vorne zu füllen. Sowohl die Forward Fill- als auch die Backward Fill-Methode funktionieren, wenn die Daten eine logische Reihenfolge haben.
Algorithmen, die fehlende Werte unterstützen
Es gibt maschinelle Lernalgorithmen, die bei fehlenden Daten robust sind. Einige Beispiele sind:
- kNN (k-nächster Nachbar)
- Naive Bayes
Andere Algorithmen wie Klassifizierungs- oder Regressionsbäume verwenden die nicht verfügbaren Informationen als eindeutige Kennung.