Apache Cassandra ist eine der beliebtesten NoSQL-Datenbanken. Obwohl es andere Versionen von NoSQL gibt, die verfügbar sind. Aber warum ist Apache Cassandra so beliebt? werfen wir einen Blick. Hier sehen wir die Funktionen und die Installation von Apache Cassandra.
Einführung
Organisationen, die mit einer großen Menge unstrukturierter Daten umgehen, bevorzugen diese. Es ist eine Java-basierte NoSQL-Datenbank. Ohne ein festes Schema ist Cassandra in der Lage, ein wirklich riesiges Datenvolumen zu handhaben und zu verwalten. Es arbeitet mit einem Peer-to-Peer-basierten Modell, bei dem jeder Knoten mit allen anderen Knoten verbunden ist. Knoten haben Lese- und Schreibberechtigung, sodass kein Master-Knoten erforderlich ist. Sie können endlose Knoten im Cluster hinzufügen.
Funktionen
1. Peer-to-Peer-Architektur
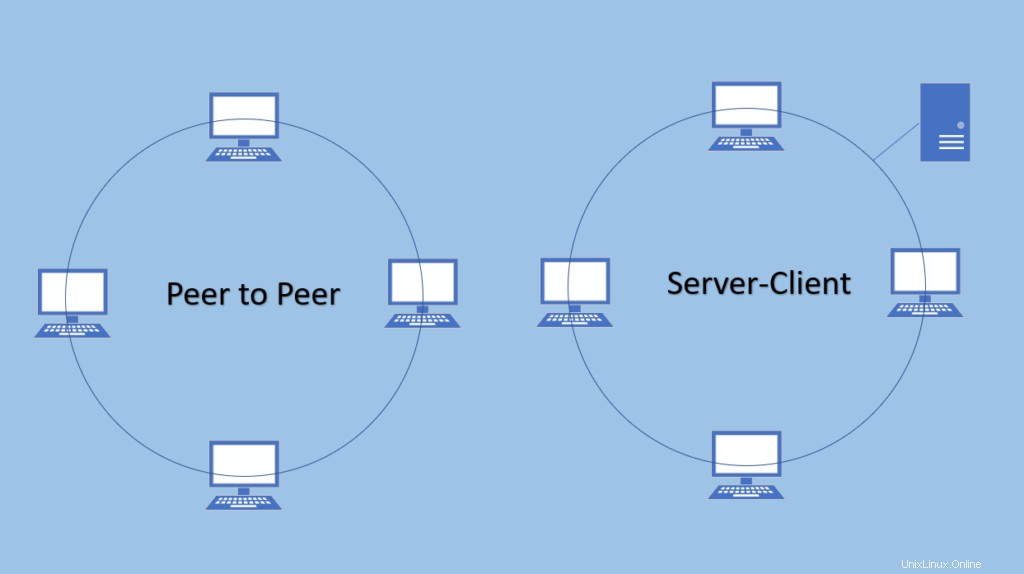
Es besteht keine Masterserver-Abhängigkeit, hier werden alle Knoten gleich behandelt. Es macht keinen Sinn, aufgrund des Peer-to-Peer- und Server-Modells zu scheitern.
2. Hohe Skalierbarkeit
Aufgrund des Lese-/Schreibdurchsatzdesigns. Ein neuer Knoten oder eine neue Maschine wird hinzugefügt, ohne dass laufende Anwendungen oder Live-Operationen unterbrochen werden.
3. Fehlertoleranz
Jeder Knoten hat die gleiche Kopie der Daten. Angenommen, es gibt 5 Knoten im Cluster und einer von ihnen funktioniert nicht mehr, dieser fehlerhafte Knoten kann schnell entfernt werden.
4. Flexible Datenspeicherung
Es kann alle Arten von Daten unterstützen, die wie halbstrukturierte, strukturierte und unstrukturierte Datenformate strukturiert sind.
5. Schnelle Datenspeicherung und -zugriff
Es kann sogar auf billigen Hardwarestrukturen ausgeführt werden, es kann eine riesige Datenmenge speichern, ohne die Geschwindigkeit des Rechenzentrums zu beeinträchtigen.
Installation
Voraussetzungen:
- In dieser Installationsdemonstration verwenden wir Rocky Linux.
- Aktualisiertes JAVA und YUM sind erforderlich, um die Konfiguration abzuschließen.
System zuerst aktualisieren:
# yum update Installieren Sie JAVA und Python
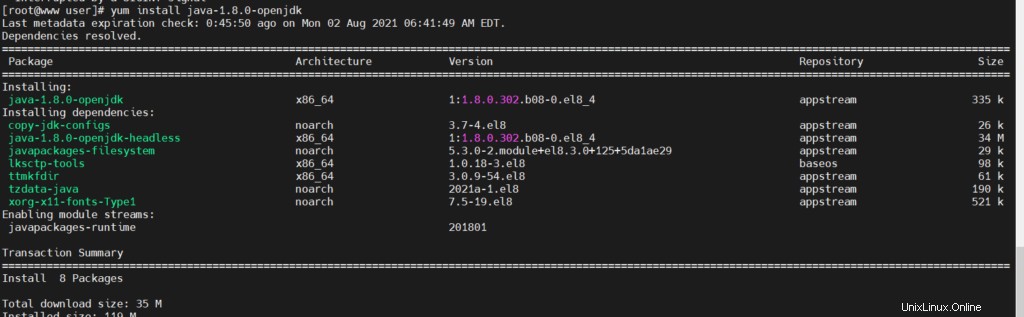
# yum install java-1.8.0-openjdk
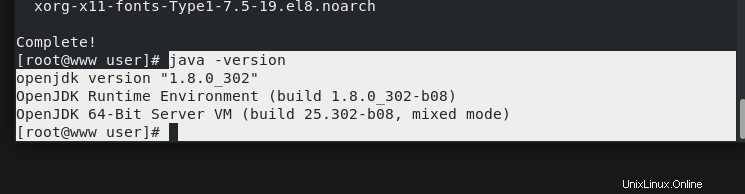
Überprüfen Sie nach der Ausführung des Befehls, welche Version von JAVA installiert ist.
# java -versionopenjdk version "1.8.0_302"
OpenJDK Runtime Environment (build 1.8.0_302-b08)
OpenJDK 64-Bit Server VM (build 25.302-b08, mixed mode)
Lassen Sie uns nun das Cassandra-Repository auf dem Server installieren.
Erstellen Sie eine neue Repo-Datei für Cassandra, ändern Sie die Datei wie folgt.
$ sudo vim /etc/yum.repos.d/cassandra.repo[cassandra]
name=Apache Cassandra
baseurl=https://downloads.apache.org/cassandra/redhat/40x/
gpgcheck=1
repo_gpgcheck=1
gpgkey=https://downloads.apache.org/cassandra/KEYS
Paket installieren.
$ sudo yum install cassandra -yErforderliche Einstellungen für Cluster ändern.
Der standardmäßig als „Testcluster“ bezeichnete Standardcluster. Sie müssen es umbenennen. Alle Konfigurationen werden in /etc/cassandra gespeichert . Alle Cluter-Daten werden in /var/lib/cassandra gespeichert
Ändern Sie den Clusternamen, wechseln Sie zur Befehlszeile.
# cqlsh
cqlsh> UPDATE system.local SET cluster_name = 'unixcop Cluster' WHERE KEY = 'local';
# service cassandra restart
Öffnen Sie cassandra.yaml, benennen Sie den Clusternamen um. Datei speichern und beenden.
# cd /etc/cassandra/default.confÖffnen Sie die Datei und nehmen Sie die erforderlichen Änderungen vor.
# vim cassandra.yaml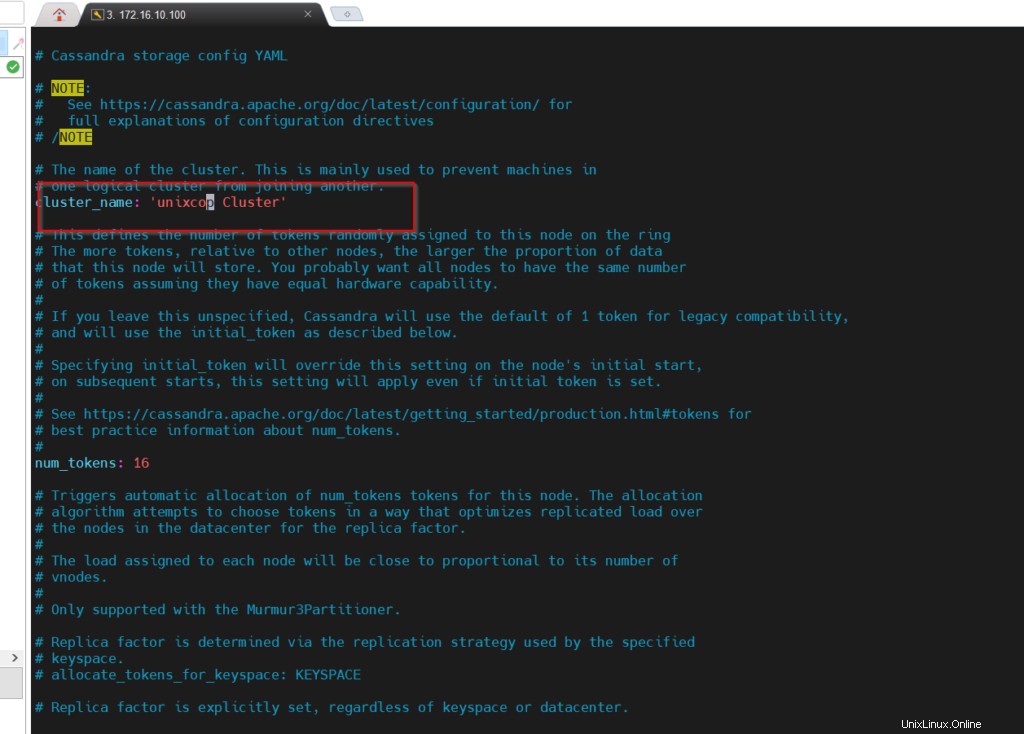
Starten Sie den Dienst neu und los geht's.
Schlussfolgerung
Heute haben wir gezeigt, wie man die Cassandra-Datenbank konfiguriert und umbenennt. Obwohl es sich um eine der beliebtesten NoSQL-Datenbanken handelt, ist es nicht für alle komplizierten Datenbankanforderungen geeignet. Ursprünglich war es ein Open-Source-Projekt, jetzt ein Teil des Apache-Projekts.