Systemadministratoren verfügen über viele Tools zum Anzeigen und Verwalten laufender Prozesse. Diese waren für mich früher in erster Linie Top , oben und htop . Vor ein paar Jahren habe ich Glances entdeckt, ein Tool, das Informationen anzeigt, die keiner meiner anderen Favoriten zeigt. Alle diese Tools überwachen die CPU- und Speicherauslastung und die meisten von ihnen listen (zumindest) Informationen über laufende Prozesse auf. Glances überwacht jedoch auch Dateisystem-E/A, Netzwerk-E/A und Sensorauslesungen, die CPU- und andere Hardwaretemperaturen sowie Lüftergeschwindigkeiten und Festplattennutzung nach Hardwaregerät und logischem Volume anzeigen können.
Blicke
Ich habe Glances in meinem Artikel 4 Open-Source-Tools für die Überwachung von Linux-Systemen erwähnt , aber ich werde in diesem Artikel tiefer darauf eingehen. Wenn Sie meinen vorherigen Artikel gelesen haben, werden Ihnen einige dieser Informationen vielleicht bekannt vorkommen, aber Sie sollten hier auch einige neue Dinge finden.
Glances ist plattformübergreifend, da es in Python geschrieben ist. Es kann auf Windows und anderen Hosts installiert werden, auf denen aktuelle Versionen von Python installiert sind. Die meisten Linux-Distributionen (in meinem Fall Fedora) haben Glances in ihren Repositories. Wenn nicht, oder wenn Sie ein anderes Betriebssystem (z. B. Windows) verwenden oder es einfach direkt von der Quelle erhalten möchten, finden Sie Anweisungen zum Herunterladen und Installieren im GitHub-Repo von Glances.
Ich schlage vor, Glances auf einem Testcomputer auszuführen, während Sie die Befehle in diesem Artikel ausprobieren. Wenn Sie keinen physischen Host zum Testen zur Verfügung haben, können Sie Glances auf einer virtuellen Maschine (VM) erkunden, aber Sie werden den Abschnitt mit den Hardwaresensoren nicht sehen; Schließlich hat eine VM keine echte Hardware.
Um Glances auf einem Linux-Host zu starten, öffnen Sie eine Terminalsitzung und geben Sie den Befehl glances ein .
Glances hat drei Hauptabschnitte – Zusammenfassung, Prozess und Warnungen – sowie eine Seitenleiste. Ich werde sie und andere Details zur Verwendung von Glances jetzt untersuchen.
Zusammenfassungsbereich
In den oberen paar Zeilen enthält der Zusammenfassungsabschnitt von Glances viele der gleichen Informationen, die Sie in den Zusammenfassungsabschnitten anderer Monitore finden. Wenn Sie in Ihrem Terminal genügend horizontalen Platz haben, kann Glances die CPU-Auslastung sowohl mit einem Balkendiagramm als auch mit einem numerischen Indikator anzeigen. andernfalls wird nur die Nummer angezeigt.
Mir gefällt der Zusammenfassungsbereich von Glances besser als die in anderen Monitoren (wie top ); Ich denke, es bietet die richtigen Informationen in einem leicht verständlichen Format.
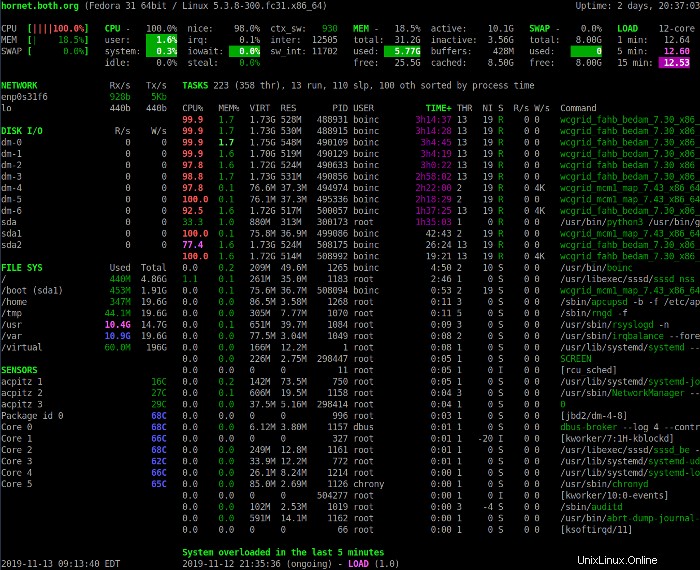
Der Abschnitt Zusammenfassung oben bietet einen Überblick über den Status des Systems. Die erste Zeile zeigt den Hostnamen, die Linux-Distribution, die Kernel-Version und die Systembetriebszeit.
Die nächsten vier Zeilen zeigen CPU-, Speichernutzungs-, Auslagerungs- und Ladestatistiken an. Die linke Spalte zeigt die Prozentsätze an verwendeter CPU, Arbeitsspeicher und Auslagerungsspeicher. Es zeigt auch die kombinierten Statistiken für alle im System vorhandenen CPUs.
Drücken Sie die 1 um zwischen der konsolidierten Anzeige der CPU-Auslastung und der Anzeige der einzelnen CPUs umzuschalten. Das folgende Bild zeigt die Glances-Anzeige mit individuellen CPU-Statistiken.
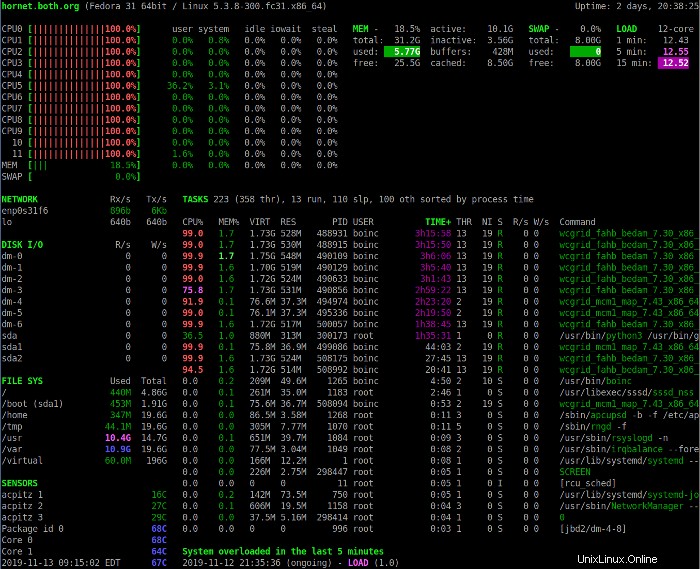
Diese Ansicht enthält einige zusätzliche CPU-Statistiken. In beiden Anzeigemodi können Ihnen die Beschreibungen der CPU-Nutzungsfelder dabei helfen, die im CPU-Abschnitt angezeigten Daten zu interpretieren. Beachten Sie, dass CPUs beginnend bei 0 (Null) nummeriert sind.
| CPU | Dies ist die aktuelle CPU-Nutzung als Prozentsatz der insgesamt verfügbaren CPU. |
| Benutzer | Dies sind die Anwendungen und anderen Programme, die im User Space laufen, d. h. nicht im Kernel. |
| System | Dies sind Funktionen auf Kernel-Ebene. Es enthält keine vom Kernel selbst verbrauchte CPU-Zeit, sondern nur die Systemaufrufe des Kernels. |
| Leerlauf | Dies ist die Leerlaufzeit, d. h. die Zeit, die von keinem laufenden Prozess verwendet wird. |
| nett | Dies ist die Zeit, die von Prozessen verwendet wird, die auf einem positiven, netten Niveau laufen. |
| irq | Dies sind die Interrupt-Anforderungen, die CPU-Zeit beanspruchen. |
| iowait | Das sind CPU-Zyklen, die darauf verwendet werden, auf E/A zu warten – das ist verschwendete CPU-Zeit. |
| stehlen | Der Prozentsatz der CPU-Zyklen, die eine virtuelle CPU auf eine echte CPU wartet, während der Hypervisor einen anderen virtuellen Prozessor bedient. |
| ctx-sw | Dies ist die Anzahl der Kontextwechsel pro Sekunde; es stellt dar, wie oft pro Sekunde die CPU von der Ausführung eines Prozesses zu einem anderen wechselt. |
| inter | Dies ist die Anzahl der Hardware-Interrupts pro Sekunde. Ein Hardware-Interrupt tritt auf, wenn ein Hardwaregerät, wie z. B. eine Festplatte, einer CPU mitteilt, dass es eine Datenübertragung abgeschlossen hat oder dass eine Netzwerkschnittstellenkarte bereit ist, weitere Daten zu akzeptieren. |
| sw_int | Software-Interrupts teilen der CPU mit, dass eine angeforderte Aufgabe abgeschlossen ist oder dass die Software für etwas bereit ist. Diese sind in der Regel häufiger in Kernel-Level-Software. |
Über schöne Zahlen
Nice Numbers sind der Mechanismus, der von Administratoren verwendet wird, um die Priorität eines Prozesses zu beeinflussen. Es ist nicht möglich, die Priorität eines Prozesses direkt zu ändern, aber das Ändern der netten Zahl kann die Ergebnisse des Prioritätseinstellungsalgorithmus des Kernel-Schedulers verändern. Schöne Zahlen reichen von -20 bis +19, wobei höhere Zahlen schöner sind. Die Standard-Nice-Nummer ist 0 und die Standard-Priorität ist 20. Wenn Sie die Nice-Nummer höher als null setzen, wird die Prioritätsnummer etwas erhöht, wodurch der Prozess netter und daher weniger gierig nach CPU-Zyklen wird. Das Festlegen der netten Zahl auf eine negativere Zahl führt zu einer niedrigeren Prioritätszahl, wodurch der Prozess weniger schön wird. Nice-Nummern können mit dem Befehl renice oder innerhalb von top, atop und htop geändert werden.
Erinnerung
Der Abschnitt Speicher des Abschnitts Zusammenfassung enthält Statistiken zur Speichernutzung.
| MEM | Dies zeigt die Speichernutzung als Prozentsatz der verfügbaren Gesamtmenge an. |
| insgesamt | Dies ist die Gesamtmenge des im Host installierten RAM-Speichers abzüglich der dem Anzeigeadapter zugewiesenen Menge. |
| verwendet | Dies ist die Gesamtspeichermenge, die vom System und den Anwendungsprogrammen verwendet wird, jedoch ohne Cache oder Puffer. |
| kostenlos | Dies ist die Menge an freiem Speicher. |
| aktiv | Dies ist die Menge des aktiv genutzten Speichers – inaktiver Speicher kann bei Bedarf auf die Festplatte ausgelagert werden. |
| inaktiv | Dies ist Speicher, der verwendet wird, auf den jedoch seit einiger Zeit nicht mehr zugegriffen wurde. |
| Puffer | Dies ist Speicher, der als Pufferspeicher verwendet wird; Es wird normalerweise von Kommunikation und E/A wie Netzwerken verwendet. Die Daten werden empfangen und gespeichert, bis die Software sie zur Verwendung abrufen oder an ein Speichergerät senden oder an das Netzwerk übertragen kann. |
| zwischengespeichert | Dies ist der Speicher, in dem Daten für die Festplattenübertragung gespeichert werden, bis sie von einem Programm verwendet oder auf der Festplatte gespeichert werden können. |
Der Swap-Bereich ist selbsterklärend, wenn Sie etwas über Swap Space und seine Funktionsweise verstehen. Dies zeigt, wie viel Auslagerungsspeicher insgesamt verfügbar ist, wie viel verwendet wird und wie viel übrig bleibt.
Der Belastungsteil des Zusammenfassungsbereichs zeigt die 1-, 5- und 15-Minuten-Lastdurchschnitte an.
Sie können die Zifferntasten 1 verwenden , 3 , 4 und 5 um Ihre Ansicht der Daten in diesem Abschnitt zu ändern. Die 2 Taste schaltet die linke Seitenleiste ein und aus.
Weitere Informationen zu Durchschnittslasten
Lastdurchschnitte werden häufig missverstanden, obwohl sie ein Schlüsselkriterium für die Messung der CPU-Auslastung sind. Aber was bedeutet es wirklich, wenn ich sage, dass der Lastdurchschnitt von einer (oder fünf oder 10) Minute beispielsweise 4,04 beträgt? Der Lastdurchschnitt kann als Maß für die CPU-Beanspruchung betrachtet werden; Es ist eine Zahl, die die durchschnittliche Anzahl von Anweisungen darstellt, die auf CPU-Zeit warten, und ist somit ein echtes Maß für die CPU-Leistung.
Mehr über Systemadministratoren
- Sysadmin-Blog aktivieren
- Das automatisierte Unternehmen:ein Leitfaden zur IT-Verwaltung mit Automatisierung
- eBook:Ansible-Automatisierung für SysAdmins
- Geschichten aus der Praxis:Ein Leitfaden für Systemadministratoren zur IT-Automatisierung
- eBook:Ein Leitfaden zu Kubernetes für SREs und Systemadministratoren
- Neueste Sysadmin-Artikel
Beispielsweise hätte eine voll ausgelastete CPU eines Einzelprozessorsystems einen Lastdurchschnitt von 1. Dies bedeutet, dass die CPU genau mit der Nachfrage Schritt hält; mit anderen Worten, es hat eine perfekte Auslastung. Ein Lastdurchschnitt von weniger als 1 bedeutet, dass die CPU nicht ausgelastet ist, und ein Lastdurchschnitt von mehr als 1 bedeutet, dass die CPU überlastet ist und dass ein aufgestauter, unbefriedigter Bedarf besteht. Beispielsweise zeigt ein Lastdurchschnitt von 1,5 in einem System mit einer CPU an, dass ein Drittel der CPU-Anweisungen auf die Ausführung warten muss, bis die vorherige abgeschlossen ist.
Dies gilt auch für mehrere Prozessoren. Wenn ein Vier-CPU-System einen Lastdurchschnitt von 4 hat, dann hat es eine perfekte Auslastung. Wenn es beispielsweise eine durchschnittliche Auslastung von 3,24 hat, sind drei seiner Prozessoren voll ausgelastet und einer ist zu etwa 24 % ausgelastet. Im obigen Beispiel hat ein System mit vier CPUs einen Lastdurchschnitt von 4,04 für eine Minute, was bedeutet, dass unter den vier CPUs keine verbleibende Kapazität vorhanden ist und einige Anweisungen warten müssen. Ein perfekt ausgelastetes Vier-CPU-System würde einen Lastdurchschnitt von 4,00 aufweisen, was bedeutet, dass das System voll ausgelastet, aber nicht überlastet ist.
Die optimale Lastdurchschnittsbedingung ist, dass der Lastdurchschnitt gleich der Gesamtzahl von CPUs in einem System ist. Das würde bedeuten, dass jede CPU voll ausgelastet ist und kein Befehl warten muss. Aber die Realität ist chaotisch, und optimale Bedingungen werden selten erreicht. Wenn ein Host mit 100 % Auslastung ausgeführt würde, würde dies keine Spitzen bei den CPU-Lastanforderungen zulassen.
Die längerfristigen Lastdurchschnitte weisen auf allgemeine Auslastungstrends hin.
Linux-Journal veröffentlichte in seiner Ausgabe vom 1. Dezember 2006 einen ausgezeichneten Artikel über Lastdurchschnittswerte, die Theorie, die Mathematik dahinter und wie man sie interpretiert. Leider Linux Journal hat die Veröffentlichung eingestellt, und seine Archive sind nicht mehr direkt verfügbar, daher führt der Link zu einem Archiv eines Drittanbieters.
CPU-Schweine finden
Einer der Gründe für die Verwendung eines Tools wie Glances besteht darin, Prozesse zu finden, die zu viel CPU-Zeit beanspruchen. Öffnen Sie eine neue Terminalsitzung (anders als die, in der Glances ausgeführt wird), geben Sie das folgende CPU-lastige Bash-Programm ein und starten Sie es.
X=0;while [ 1 ];do echo $X;X=$((X+1));doneDieses Programm ist ein CPU-Hog und verbraucht jeden verfügbaren CPU-Zyklus. Lassen Sie es laufen, während Sie diesen Artikel fertigstellen, und experimentieren Sie mit Glances. Es wird Ihnen eine Vorstellung davon geben, wie ein Programm aussieht, das CPU-Zyklen in Beschlag nimmt. Achten Sie darauf, die Auswirkungen auf die Lastdurchschnitte über die Zeit sowie die kumulierte Zeit in TIME+ zu beobachten Spalte für diesen Prozess.
Prozessabschnitt
Der Abschnitt Prozess zeigt Standardinformationen zu jedem laufenden Prozess an. Je nach Ansichtsmodus und Größe des Terminalbildschirms werden für die laufenden Prozesse unterschiedliche Informationsspalten angezeigt. Der Standardmodus mit einem ausreichend breiten Terminal zeigt die unten aufgeführten Spalten an. Die angezeigten Spalten ändern sich automatisch, wenn die Größe des Terminalbildschirms geändert wird. Die folgenden Spalten werden normalerweise für jeden Prozess von links nach rechts angezeigt.
| CPU % | Dies ist die CPU-Zeit als Prozentsatz eines einzelnen Kerns. Beispielsweise repräsentiert 98 % 98 % der verfügbaren CPU-Zyklen für einen einzelnen Kern. Mehrere Prozesse können bis zu 100 % CPU-Auslastung aufweisen. |
| MEM% | Dies ist die Menge des vom Prozess verwendeten RAM-Speichers als Prozentsatz des gesamten virtuellen Speichers im Host. |
| VIRT | Dies ist die Menge an virtuellem Speicher, die vom Prozess in menschenlesbarem Format verwendet wird, z. B. 12 MB für 12 Megabyte. |
| RES | Dies bezieht sich auf die Menge an physischem (residentem) Speicher, der von dem Prozess verwendet wird. Auch dies ist in einem für Menschen lesbaren Format mit einem Indikator von K , M , oder G , um Kilobyte, Megabyte oder Gigabyte anzugeben. |
| PID | Jeder Prozess hat eine Identifikationsnummer, die PID genannt wird. Diese Nummer kann in Befehlen wie renice verwendet werden und töten , um den Prozess zu verwalten. Denken Sie daran, dass das töten Dienstprogramm kann neben dem „Kill“-Signal Signale an andere Prozesse senden. |
| BENUTZER | Dies ist der Name des Benutzers, dem der Prozess gehört. |
| ZEIT+ | Dies gibt die kumulierte CPU-Zeit an, die der Prozess seit seinem Start aufgelaufen ist. |
| THR | Dies ist die Gesamtzahl der Threads, die derzeit für diesen Prozess ausgeführt werden. |
| NI | Dies ist die schöne Nummer des Prozesses. |
| S | Dies ist der aktuelle Stand; es kann sein (R )unning, (S )schlafend, (ich )dle, T oder t wenn der Prozess während eines Debugging-Trace angehalten wird, oder (Z ) ombie. Ein Zombie ist ein Prozess, der getötet, aber nicht vollständig beendet wurde, sodass er weiterhin einige Systemressourcen wie RAM verbraucht. |
| R/s und W/s | Dies sind die Lese- und Schreibvorgänge pro Sekunde. |
| Befehl | Dies ist der Befehl zum Starten des Prozesses. |
Glances bestimmt normalerweise automatisch die Standard-Sortierspalte. Prozesse können automatisch sortiert werden (a ) oder nach CPU (c ), Erinnerung (m ), Name (p ), Benutzer (u ), E/A-Rate (i ) oder Zeit (t ). Prozesse werden automatisch nach der am häufigsten verwendeten Ressource sortiert. In den obigen Bildern das TIME+ Spalte ist hervorgehoben.
Bereich "Warnungen"
Glances zeigt auch Warnungen und kritische Warnungen, einschließlich Zeit und Dauer des Ereignisses, unten auf dem Bildschirm an. Dies kann hilfreich sein, wenn Sie versuchen, Probleme zu diagnostizieren und nicht stundenlang auf den Bildschirm starren können. Diese Alarmprotokolle können mit dem l ein- oder ausgeschaltet werden (Kleinbuchstabe L), Warnungen können mit w gelöscht werden Taste, während Alarme und Warnungen alle mit x gelöscht werden können .
Seitenleiste
Glances hat eine sehr schöne Seitenleiste auf der linken Seite, die Informationen anzeigt, die oben nicht verfügbar sind oder htop . Während oben einige dieser Daten anzeigt, ist Glances der einzige Monitor, der Daten über Sensoren anzeigt. Schließlich ist es manchmal schön, die Temperaturen in Ihrem Computer zu sehen.
Die einzelnen Module, Festplatte, Dateisystem, Netzwerk und Sensoren können mit dem d ein- und ausgeschaltet werden , f , n , und s Schlüssel bzw. Die gesamte Seitenleiste kann mit 2 umgeschaltet werden . Docker-Statistiken können in der Seitenleiste mit D angezeigt werden .
Beachten Sie, dass Hardwaresensoren nicht angezeigt werden, wenn Glances auf einer virtuellen Maschine ausgeführt wird.
Hilfe bekommen
Sie können Hilfe erhalten, indem Sie h drücken Schlüssel; Verlassen Sie die Hilfeseite, indem Sie h drücken wieder. Die Hilfeseite ist eher knapp, zeigt aber die verfügbaren interaktiven Optionen und wie man sie ein- und ausschaltet. Die Manpage enthält knappe Erklärungen der Optionen, die beim Starten von Glances verwendet werden können.
Sie können q drücken oder Esc um Glances zu beenden.
Konfiguration
Glances benötigt keine Konfigurationsdatei, um ordnungsgemäß zu funktionieren. Wenn Sie sich dafür entscheiden, befindet sich die systemweite Instanz der Konfigurationsdatei in /etc/glances/glances.conf . Einzelne Benutzer können eine lokale Instanz unter ~/.config/glances/glances.conf haben , wodurch die globale Konfiguration überschrieben wird. Der Hauptzweck dieser Konfigurationsdateien besteht darin, Schwellenwerte für Warnungen und kritische Warnungen festzulegen. Sie können auch festlegen, ob bestimmte Module standardmäßig angezeigt werden oder nicht.
Die Datei /usr/local/share/doc/glances/README.rst enthält zusätzliche nützliche Informationen, einschließlich optionaler Python-Module, die Sie installieren können, um einige optionale Glances-Funktionen zu unterstützen.
Befehlszeilenoptionen
Glances bietet Befehlszeilenoptionen, mit denen es in bestimmten Anzeigemodi gestartet werden kann. Beispielsweise der Befehl glances -2 startet das Programm mit deaktivierter linker Seitenleiste.
Remote und mehr
Indem Sie es im Servermodus starten, können Sie Glances verwenden, um entfernte Hosts zu überwachen:
[root@testvm1 ~]# glances -sSie können sich dann vom Client mit dem Server verbinden mit:
[root@testvm2 ~]# glances -c @testvm1Glances kann eine Liste von Glances-Servern zusammen mit einer Zusammenfassung ihrer Aktivitäten anzeigen. Es hat auch eine Webschnittstelle, so dass Sie entfernte Glances-Server von einem Browser aus überwachen können. Neuere Versionen von Glances können auch Docker-Statistiken anzeigen.
Es gibt auch steckbare Module für Glances, die Messdaten liefern, die im Basisprogramm nicht verfügbar sind.
Einschränkungen
Obwohl Glances viele Aspekte eines Hosts überwachen kann, kann es keine Prozesse verwalten. Es kann weder die nette Nummer eines Prozesses ändern noch einen beenden, wie top und htop kann. Glances ist kein interaktives Tool. Es dient ausschließlich der Überwachung. Externe Tools wie kill und renice kann zur Verwaltung von Prozessen verwendet werden.
Blicke können nur die Prozesse anzeigen, die den Großteil der angegebenen Ressourcen, wie z. B. CPU-Zeit, im verfügbaren Speicherplatz beanspruchen. Wenn Platz ist, um nur 10 Prozesse aufzulisten, ist das alles, was Sie sehen können. Glances bietet keine Bildlauf- oder Umkehrsortierungsoptionen, mit denen Sie andere als die Top-X-Prozesse sehen könnten.
Die Auswirkung der Messung
Der Beobachtereffekt ist eine physikalische Theorie, die besagt, dass „das einfache Beobachten einer Situation oder eines Phänomens notwendigerweise dieses Phänomen verändert“. Dies gilt auch für die Messung der Linux-Systemleistung.
Allein die Verwendung eines Überwachungstools verändert die Ressourcennutzung des Systems, einschließlich Arbeitsspeicher und CPU-Zeit. Die Spitze Dienstprogramm und die meisten anderen Monitore verbrauchen vielleicht 2 % bis 3 % der CPU-Zeit eines Systems. Das Dienstprogramm Glances hat viel mehr Einfluss als die anderen; Es verwendet normalerweise zwischen 10 % und 20 % der CPU-Zeit, und ich habe gesehen, dass es in einem sehr großen und aktiven System mit 32 CPUs bis zu 40 % einer CPU verwendet. Das ist viel, also bedenken Sie die Auswirkungen, wenn Sie darüber nachdenken, Glances als Ihren Monitor zu verwenden.
Meine persönliche Meinung ist, dass dies ein geringer Preis ist, wenn Sie die Fähigkeiten von Glances benötigen.
Zusammenfassung
Trotz des Mangels an interaktiven Fähigkeiten, wie z. B. der Fähigkeit zum Wiedersehen oder töten Prozessen und der hohen CPU-Last finde ich Glances ein sehr nützliches Tool. Die vollständige Glances-Dokumentation ist im Internet verfügbar, und die Glances-Manpage enthält Startoptionen und Informationen zu interaktiven Befehlen.
Teile dieses Artikels basieren auf dem neuen Buch von David Both, Using and Administering Linux:Volume 2 – Zero to SysAdmin:Advanced Topics.