Apache Hadoop ist ein kostenloses, in Java geschriebenes Open-Source-Software-Framework für die verteilte Speicherung und Verarbeitung von Big Data mit MapReduce. Es handhabt die sehr große Größe von Datensätzen, indem es sie in große Blöcke aufteilt und sie auf Computer in einem Cluster verteilt.
Anstatt sich auf standardmäßige Betriebssystem-Cluster zu verlassen, wurden Hadoop-Module entwickelt, um Fehler auf der Anwendungsebene zu erkennen und zu verwalten, und bieten Ihnen hochverfügbaren Service auf Softwareebene.
Das grundlegende Hadoop-Framework besteht aus den folgenden Modulen,
- Hadoop Common – Enthält einen gemeinsamen Satz von Bibliotheken und Dienstprogrammen zur Unterstützung anderer Hadoop-Module
- Hadoop Distributed File System (HDFS) – Java-basiertes verteiltes Dateisystem, das Daten auf Standardhardware speichert und der Anwendung einen sehr hohen Durchsatz bietet.
- Hadoop YARN – Verwaltet Ressourcen auf Compute-Clustern und verwendet sie zur Planung von Benutzeranwendungen.
- Hadoop MapReduce – Framework für groß angelegte Datenverarbeitung basierend auf dem MapReduce-Programmiermodell.
In diesem Beitrag erfahren Sie, wie Sie Apache Hadoop auf RHEL 8 installieren.
Voraussetzungen
Wechseln Sie zum Root-Benutzer.
su -
ODER
sudo su -
Apache Hadoop v3.1.2 unterstützt nur Java Version 8. Installieren Sie also entweder OpenJDK 8 oder Oracle JDK 8.
In dieser Demo verwende ich OpenJDK 8.
yum -y install java-1.8.0-openjdk wget
Überprüfen Sie die Java-Version.
Java-Version
Ausgabe:
openjdk Version "1.8.0_201"OpenJDK Runtime Environment (Build 1.8.0_201-b09)OpenJDK 64-Bit Server VM (Build 25.201-b09, Mixed Mode)
Installieren Sie Apache Hadoop auf RHEL 8
Hadoop-Benutzer erstellen
Es wird empfohlen, Apache Hadoop von einem normalen Benutzer auszuführen. Hier erstellen wir also einen Benutzer namens hadoop und legen ein Passwort für den Benutzer fest.
useradd -m -d /home/hadoop -s /bin/bash hadooppasswd hadoop
Konfigurieren Sie nun passwortloses ssh für das lokale System, indem Sie die folgenden Schritte ausführen.
# su - hadoop$ ssh-keygen$ cat ~/.ssh/id_rsa.pub>> ~/.ssh/authorized_keys$ chmod 600 ~/.ssh/authorized_keys
Überprüfen Sie die passwortlose Kommunikation mit Ihrem lokalen System.
$ ssh 127.0.0.1
Ausgabe:
Wenn Sie zum ersten Mal eine Verbindung über ssh herstellen, müssen Sie yes eingeben, um bekannten Hosts RSA-Schlüssel hinzuzufügen.
[hadoop@rhel8 ~]$ ssh 127.0.0.1Die Authentizität des Hosts „127.0.0.1 (127.0.0.1)“ kann nicht festgestellt werden.Der Fingerabdruck des ECDSA-Schlüssels ist SHA256:85jUAgtJg8RLOqs8T2egxF7U7IWIiYF+CRspO8yatAk.Sind Sie sicher, dass Sie das möchten? weiter verbinden (ja/nein)? Ja Warnung:'127.0.0.1' (ECDSA) dauerhaft zur Liste der bekannten Hosts hinzugefügt. Aktivieren Sie die Webkonsole mit:systemctl enable --now cockpit.socketLetzter Login:Mi 8. Mai 12:15:04 2019 von 127.0.0.1[hadoop @rhel8 ~]$
Hadoop herunterladen
Besuchen Sie die Apache Hadoop-Seite, um die neueste Version von Apache Hadoop herunterzuladen (wählen Sie immer die produktionsbereite Version, indem Sie die Dokumentation überprüfen), oder verwenden Sie den folgenden Befehl im Terminal, um Hadoop v3.1.2 herunterzuladen.
$ wget https://www-us.apache.org/dist/hadoop/common/hadoop-3.1.2/hadoop-3.1.2.tar.gz$ tar -zxvf hadoop-3.1.2.tar. gz $ mv hadoop-3.1.2 hadoop
Hadoop-Cluster-Typen
Es gibt drei Arten von Hadoop-Clustern:
- Lokaler (eigenständiger) Modus – Es läuft als einzelner Java-Prozess.
- Pseudo-Verteilter Modus – Jeder Hadoop-Daemon wird als separater Prozess ausgeführt.
- Vollständig verteilter Modus – ein Multinode-Cluster. Von wenigen Knoten bis hin zu einem extrem großen Cluster.
Umgebungsvariablen einrichten
Hier konfigurieren wir Hadoop im pseudoverteilten Modus. Zuerst werden wir Umgebungsvariablen in der Datei ~/.bashrc setzen.
Ändern Sie die Variableneinträge JAVA_HOME und HADOOP_HOME in der Datei abhängig von Ihrer Umgebung.export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.201.b09-2.el8.x86_64/ export HADOOP_HOME=/home/hadoop/hadoop export HADOOP_INSTALL=$HADOOP_HOMEexport HADOOP_MAPRED_HOME=$HADOOP_HOMEexport HADOOP_COMMON_HOME=$HADOOP_HOMEexport HADOOP_HDFS_HOME=$HADOOP_HOMEexport HADOOP_YARN_HOME=$HADOOP_HOMEexport HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/libbin/nativeexport PATH=$PATH$HADOOP:$HADOOPH:$HADOOPH>Umgebungsvariablen auf Ihre aktuelle Terminalsitzung anwenden.
$ source ~/.bashrcHadoop konfigurieren
Bearbeiten Sie die Hadoop-Umgebungsdatei und aktualisieren Sie die Variable wie unten gezeigt.
$ vi $HADOOP_HOME/etc/hadoop/hadoop-env.shAktualisieren Sie die Variable JAVA_HOME entsprechend Ihrer Umgebung.
export JAVA_HOME=/usr/lib/jvm/jre-1.8.0-openjdk-1.8.0.201.b09-2.el8.x86_64/Wir werden nun die Konfigurationsdateien von Hadoop abhängig vom eingerichteten Clustermodus (pseudoverteilt) bearbeiten.
$ cd $HADOOP_HOME/etc/hadoopBearbeiten Sie core-site.xml und aktualisieren Sie die Datei mit HDFS-Hostname.
fs.defaultFS hdfs://rhel8.itzgeek.local :9000 Erstellen Sie die Verzeichnisse namenode und datanode im Hadoop-Benutzer-Home-Verzeichnis /home/hadoop.
$ mkdir -p ~/hadoopdata/hdfs/{namenode,datanode}Bearbeiten Sie hdfs-site.xml und aktualisieren Sie die Datei mit NameNode- und DataNode-Verzeichnisinformationen.
dfs.replication 1 dfs.name.dir file :///home/hadoop/hadoopdata/hdfs/namenode dfs.data.dir file:///home/hadoop/hadoopdata/hdfs/datanode Bearbeiten Sie mapred-site.xml.
mapreduce.framework.name yarn Bearbeiten Sie wool-site.xml.
yarn.nodemanager.aux-services mapreduce_shuffle Formatieren Sie den NameNode mit dem folgenden Befehl.
$ hdfs namenode -formatAusgabe:
. . .. . .2019-05-13 19:33:14,720 INFO namenode.FSImage:Zugewiesene neue BlockPoolId:BP-1601223288-192.168.1.10-15577561946432019-05-13 19:33:15,100 INFO common.Storage:Speicherverzeichnis /home/hadoop/ hadoopdata/hdfs/namenode wurde erfolgreich formatiert.2019-05-13 19:33:15,436 INFO namenode.FSImageFormatProtobuf:Speichern der Bilddatei /home/hadoop/hadoopdata/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 ohne Komprimierung2019-05- 13 19:33:16,804 INFO namenode.FSImageFormatProtobuf:Bilddatei /home/hadoop/hadoopdata/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 mit einer Größe von 393 Byte in 1 Sekunde gespeichert .2019-05-13 19:33:17,106 INFO namenode .NNStorageRetentionManager:1 Bilder mit txid>=02019-05-13 19:33:17,150 INFO namenode.NameNode beibehalten:SHUTDOWN_MSG:/******************** ****************************************SHUTDOWN_MSG:Herunterfahren von NameNode bei rhel8.itzgeek. lokal/192.168.1.10******************************************** ****************/
Firewall
Führen Sie die folgenden Befehle aus, um Apache Hadoop-Verbindungen durch die Firewall zuzulassen. Führen Sie diese Befehle als Root-Benutzer aus.
firewall-cmd --permanent --add-port=9870/tcpfirewall-cmd --permanent --add-port=8088/tcpfirewall-cmd --reload
Hadoop &Yarn starten
Starten Sie sowohl NameNode- als auch DataNode-Daemons, indem Sie die von Hadoop bereitgestellten Skripts verwenden.
$ start-dfs.sh
Ausgabe:
Beginn von Namenodes auf [rhel8.itzgeek.local]rhel8.itzgeek.local:Warnung:Permanent hinzugefügt 'rhel8.itzgeek.local,fe80::4480:83a5:c52:ea80%enp0s3' (ECDSA) zur Liste von Bekannte Hosts. Start von datanodeslocalhost:Warnung:„localhost“ (ECDSA) wurde dauerhaft zur Liste bekannter Hosts hinzugefügt Laden Sie die native Hadoop-Bibliothek für Ihre Plattform ... verwenden Sie gegebenenfalls eingebaute Java-Klassen
Öffnen Sie einen Browser und rufen Sie die folgende Adresse auf, um auf Namenode zuzugreifen.
http://ip.ad.dre.ss:9870/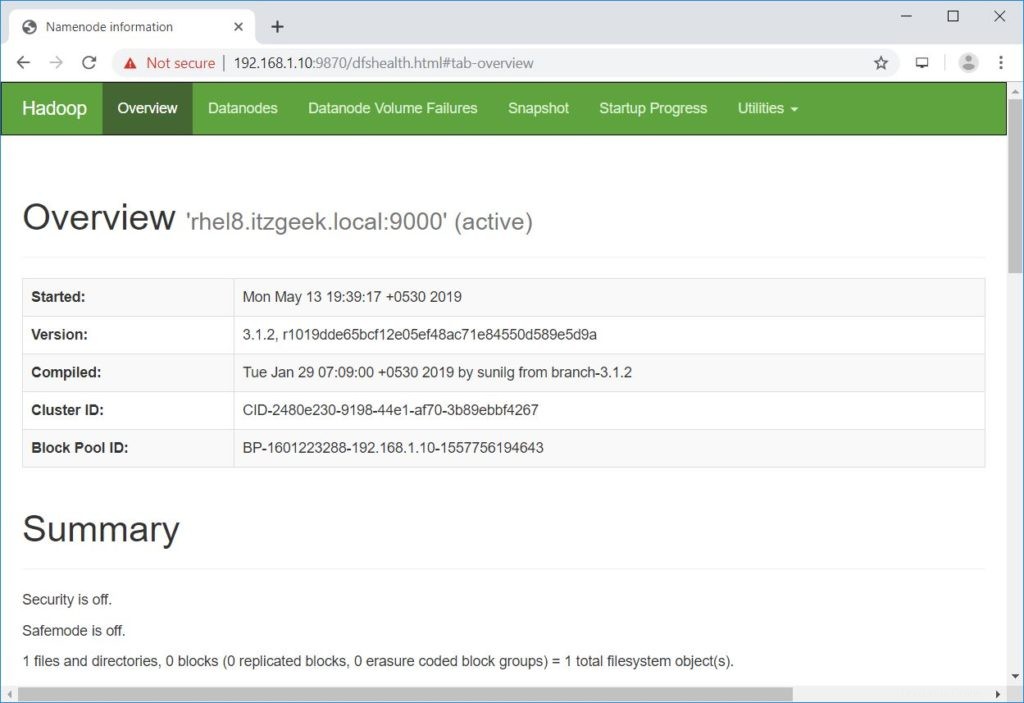
Starten Sie den ResourceManager und NodeManager.
$ start-garn.sh
Ausgabe:
Ressourcenmanager startenNodemanager starten
Öffnen Sie einen Browser und rufen Sie die folgende Adresse auf, um auf ResourceManager zuzugreifen.
http://ip.ad.dre.ss:8088/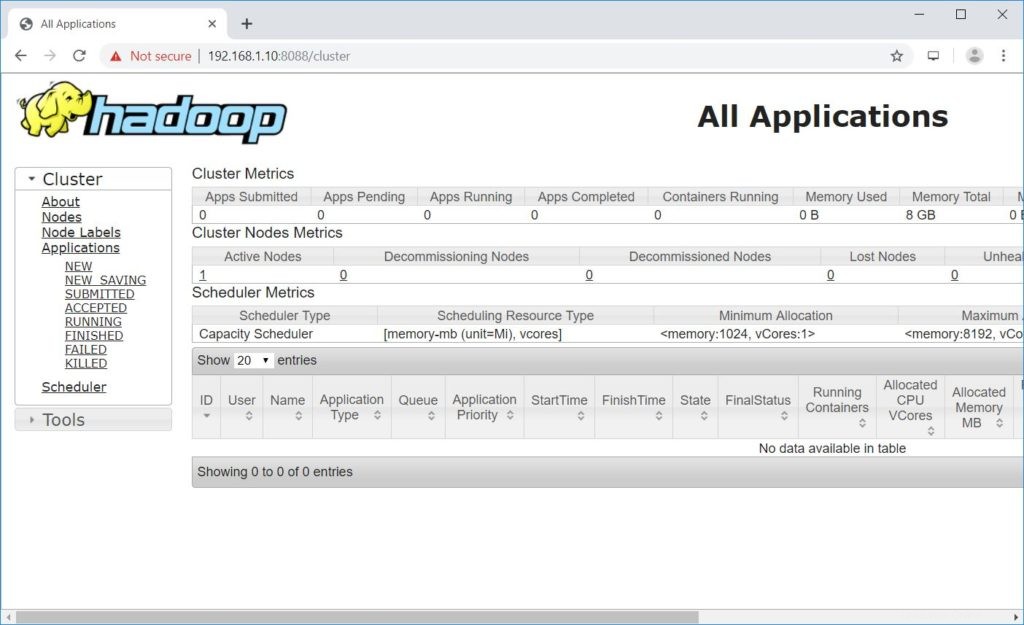
Apache Hadoop testen
Wir werden jetzt den Apache Hadoop testen, indem wir eine Beispieldatei darauf hochladen. Erstellen Sie vor dem Hochladen einer Datei in HDFS ein Verzeichnis in HDFS.
$ hdfs dfs -mkdir /raj
Stellen Sie sicher, dass das erstellte Verzeichnis in HDFS vorhanden ist.
hdfs dfs -ls /
Ausgabe:
1 Artikel gefundendrwxr-xr-x - hadoop supergroup 0 2019-05-08 13:20 /raj
Laden Sie mit dem folgenden Befehl eine Datei in das HDFS-Verzeichnis raj hoch.
$ hdfs dfs -put ~/.bashrc /raj
Hochgeladene Dateien können durch Ausführen des folgenden Befehls angezeigt werden.
$ hdfs dfs -ls /raj
ODER
Gehen Sie zu NameNode>> Dienstprogramme >>Durchsuchen Sie das Dateisystem im Namensknoten.
http://ip.ad.dre.ss:9870/explorer.html#/raj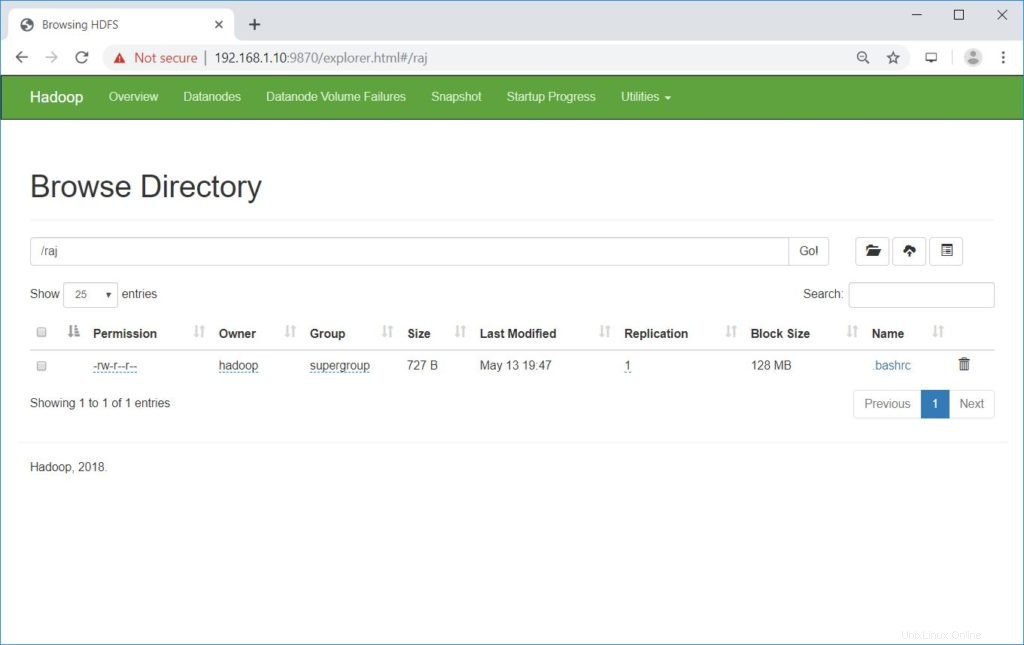
Sie können die Dateien von HDFS in Ihre lokalen Dateisysteme kopieren, indem Sie den folgenden Befehl verwenden.
$ hdfs dfs -get /raj /tmp/
Bei Bedarf können Sie die Dateien und Verzeichnisse in HDFS mit den folgenden Befehlen löschen.
$ hdfs dfs -rm -f /raj/.bashrc$ hdfs dfs -rmdir /raj
Schlussfolgerung
Ich hoffe, dieser Beitrag hat Ihnen geholfen, einen Apache Hadoop-Cluster mit einem einzelnen Knoten auf RHEL 8 zu installieren und zu konfigurieren. Weitere Informationen finden Sie in der offiziellen Hadoop-Dokumentation. Bitte teilen Sie uns Ihr Feedback im Kommentarbereich mit.