Splitter ist ein MongoDB-Prozess zum Speichern von Datensätzen auf verschiedenen Computern. Es ermöglicht Ihnen, Daten horizontal zu skalieren, Daten über unabhängige Instanzen hinweg zu partitionieren, und es können „Replikatsätze“ sein. Die Datensatzpartitionierung auf „Sharding“ verwendet Shard-Schlüssel. Sharding ermöglicht es Ihnen, basierend auf dem Datenwachstum auf Ihrem Stack weitere Maschinen hinzuzufügen.
Sharding und Replikation
Machen wir es uns einfach. Wenn Sie Musiksammlungen haben, speichert und bewahrt „Sharding“ Ihre Musiksammlungen in einem anderen Ordner auf. „Replizieren“ hingegen ist lediglich das Synchronisieren Ihrer Musiksammlungen mit anderen Instanzen.
Drei Sharding-Komponenten
Splitter - Wird verwendet, um alle Daten zu speichern, und in einer Produktionsumgebung ist jeder Shard ein Replikatsatz. Bietet Hochverfügbarkeit und Datenkonsistenz.
Konfigurationsserver – Wird zum Speichern von Cluster-Metadaten verwendet, enthält eine Zuordnung von Cluster-Datensatz und Shards. Diese Daten werden vom Mongos/Query-Server verwendet, um Operationen bereitzustellen. Es wird empfohlen, mehr als 3 Instanzen in der Produktion zu verwenden.
Mongos/Query-Router - Dies sind nur Mongo-Instanzen, die als Anwendungsschnittstellen ausgeführt werden. Die Anwendung stellt Anfragen an Mongos-Instanzen, und dann übermittelt Mongos die Anfragen unter Verwendung von Shard-Schlüsseln an die Shards-Replikatsätze.
Voraussetzungen
- 2 centOS 7-Server als Config Replica Sets
- 10.0.15.31 configsvr1
- 10.0.15.32 configsvr2
- 4 CentOS 7-Server als Shard Replica Sets
- 10.0.15.21 Shardsvr1
- 10.0.15.22 Shardsvr2
- 10.0.15.23 Shardsvr3
- 10.0.15.24 Shardsvr4
- 1 CentOS 7-Server als Mongos/Query Router
- 10.0.15.11 Mongos
- Root-Rechte
- Jeder Server ist mit einem anderen Server verbunden
Schritt 1 – SELinux deaktivieren und Hosts konfigurieren
Für dieses Tutorial werden wir SELinux deaktivieren. Ändern Sie die SELinux-Konfiguration von „Erzwingen“ auf „Deaktiviert“.
Stellen Sie über OpenSSH eine Verbindung zu allen Knoten her.
ssh [email protected]
Deaktivieren Sie SELinux, indem Sie die Konfigurationsdatei bearbeiten.
vim /etc/sysconfig/selinux
Ändern Sie den SELinux-Wert auf „deaktiviert“.
SELINUX=disabled
Speichern und beenden.
Als nächstes bearbeiten Sie die hosts-Datei auf jedem Server.
vim /etc/hosts
Fügen Sie die folgende Hostkonfiguration ein:
10.0.15.31 configsvr1
10.0.15.32 configsvr2
10.0.15.11 mongos
10.0.15.21 shardsvr1
10.0.15.22 shardsvr2
10.0.15.23 shardsvr3
10.0.15.24 shardsvr4
Speichern und beenden.
Starten Sie nun alle Server neu:
reboot
Schritt 2 – MongoDB auf allen Instanzen installieren
Wir werden die neueste MongoDB (MongoDB 3.4) für alle Instanzen verwenden. Fügen Sie ein neues MongoDB-Repository hinzu, indem Sie die folgenden Befehle ausführen:
cat <<'EOF' >> /etc/yum.repos.d/mongodb.repo
[mongodb-org-3.4]
name=MongoDB Repository
baseurl=https://repo.mongodb.org/yum/redhat/$releasever/mongodb-org/3.4/x86_64/
gpgcheck=1
enabled=1
gpgkey=https://www.mongodb.org/static/pgp/server-3.4.asc
EOF
Installieren Sie nun Mongodb 3.4 aus dem Mongodb-Repository mit dem folgenden Befehl yum.
sudo yum -y install mongodb-org
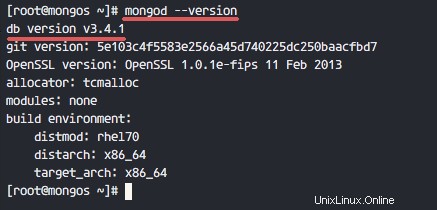
Verwenden Sie nach der Installation von mongodb „mongo ' oder 'Mongott ' Befehl wie folgt, um die Versionsdetails zu überprüfen.
mongod --version
Schritt 3 – Konfigurationsserver-Replikatsatz erstellen
Im Abschnitt „Voraussetzungen“ haben wir bereits einen Konfigurationsserver mit 2 Maschinen „configsvr1“ und „configsvr2“ definiert. Und in diesem Schritt konfigurieren wir es als Replikatsatz.
Wenn der Mongod-Dienst auf dem Server läuft, stoppen Sie ihn mit dem folgenden systemctl-Befehl.
systemctl stop mongod
Bearbeiten Sie die standardmäßige mongodb-Konfiguration „mongod.conf '.
vim /etc/mongod.conf
Ändern Sie den DB-Speicherpfad in Ihr eigenes Verzeichnis. Wir werden das Verzeichnis „/data/db1“ für den ersten Server und das Verzeichnis „/data/db2“ für den zweiten Konfigurationsserver verwenden.
storage:
dbPath: /data/db1
Ändern Sie den Wert der Zeile ‚bindIP‘ auf Ihre interne Netzwerkadresse. 'configsvr1' mit der IP-Adresse 10.0.15.31 und der zweite Server mit 10.0.15.32.
bindIP: 10.0.15.31
Legen Sie im Replikationsabschnitt einen Replikationsnamen fest.
replication:
replSetName: "replconfig01"
Definieren Sie im Abschnitt „Sharding“ eine Rolle der Instanzen. Wir werden diese beiden Instanzen als 'configsvr' verwenden.
sharding:
clusterRole: configsvr
Speichern und beenden.
Als Nächstes müssen wir ein neues Verzeichnis für MongoDB-Daten erstellen und dann die Eigentumsberechtigungen dieses Verzeichnisses auf den Benutzer „mongod“ ändern.
mkdir -p /data/db1
chown -R mongod:mongod /data/db1
Als nächstes starten Sie den Mongod-Dienst mit dem folgenden Befehl.
mongod --config /etc/mongod.conf
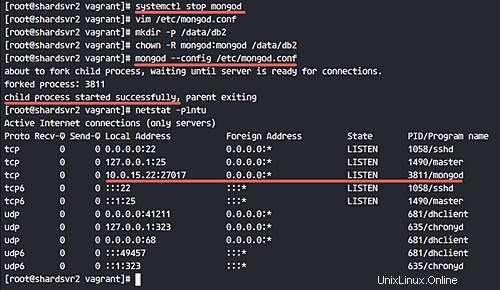
Mit dem Befehl netstat können Sie überprüfen, ob der Mongod-Dienst auf Port 27017 ausgeführt wird.
netstat -plntu
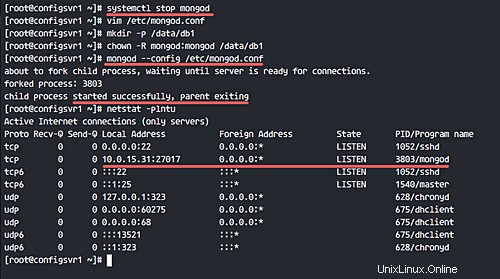
Configsvr1 und Configsvr2 sind bereit für den Replikatsatz. Verbinden Sie sich mit dem 'configsvr1'-Server und greifen Sie auf die Mongo-Shell zu.
ssh [email protected]
mongo --host configsvr1 --port 27017
Initiieren Sie den Replikatsatznamen mit allen configsvr-Mitgliedern, indem Sie die folgende Abfrage verwenden.
rs.initiate(
{
_id: "replconfig01",
configsvr: true,
members: [
{ _id : 0, host : "configsvr1:27017" },
{ _id : 1, host : "configsvr2:27017" }
]
}
)
Wenn Sie ein Ergebnis erhalten '{ "ok" :1 } ', bedeutet dies, dass der configsvr bereits mit dem Replikatsatz konfiguriert ist.
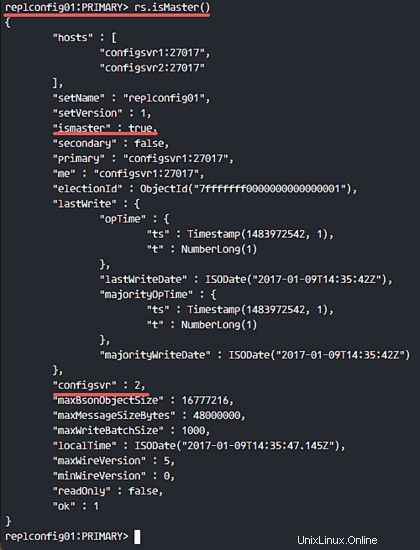
und Sie können sehen, welcher Knoten Master und welcher sekundäre Knoten ist.
rs.isMaster()
rs.status()
Die Konfiguration des Config Server Replica Sets ist abgeschlossen.
Schritt 4 – Shard-Replik-Sets erstellen
In diesem Schritt konfigurieren wir 4 Centos 7-Server als 'Shard'-Server mit 2 'Replica Set'.
- 2-Server – 'shardsvr1 ' und 'shardsvr2 ' mit dem Namen des Replikatsatzes:'shardreplica01 '
- 2-Server – 'shardsvr3 ' und 'shardsvr4 ' mit dem Namen des Replikatsatzes:'shardreplica02 '
Stellen Sie eine Verbindung zu jedem Server her und stoppen Sie den Mongod-Dienst (falls der Dienst ausgeführt wird) und bearbeiten Sie die MongoDB-Konfigurationsdatei.
systemctl stop mongod
vim /etc/mongod.conf
Ändern Sie den Standardspeicher in Ihr spezifisches Verzeichnis.
storage:
dbPath: /data/db1
Ändern Sie in der Zeile „bindIP“ den Wert in Ihre interne Netzwerkadresse.
bindIP: 10.0.15.21
Im Replikationsabschnitt können Sie „shardreplica01 verwenden “ für die erste und zweite Instanz. Und verwenden Sie 'shardreplica02 ' für den dritten und vierten Shard-Server.
replication:
replSetName: "shardreplica01"
Definieren Sie als Nächstes die Rolle des Servers. Wir werden all dies als Shardsvr-Instanzen verwenden.
sharding:
clusterRole: shardsvr
Speichern und beenden.
Erstellen Sie nun ein neues Verzeichnis für MongoDB-Daten.
mkdir -p /data/db1
chown -R mongod:mongod /data/db1
Starten Sie den Mongod-Dienst.
mongod --config /etc/mongod.conf
Überprüfen Sie mit dem folgenden Befehl, ob MongoDB ausgeführt wird:
netstat -plntu
Sie werden sehen, dass MongoDB auf der lokalen Netzwerkadresse ausgeführt wird.
Erstellen Sie als Nächstes einen neuen Replikatsatz für diese beiden Shard-Instanzen. Verbinden Sie sich mit „shardsvr1“ und greifen Sie auf die Mongo-Shell zu.
ssh [email protected]
mongo --host shardsvr1 --port 27017
Initiieren Sie den Replikatsatz mit dem Namen „shardreplica01 ', und die Mitglieder sind 'shardsvr1 ' und 'shardsvr2 '.
rs.initiate(
{
_id : "shardreplica01",
members: [
{ _id : 0, host : "shardsvr1:27017" },
{ _id : 1, host : "shardsvr2:27017" }
]
}
)
Wenn kein Fehler vorliegt, werden die Ergebnisse wie unten gezeigt angezeigt.
Ergebnisse von shardsvr3 und shardsvr4 mit dem Replikatsatznamen „shardreplica02 '.
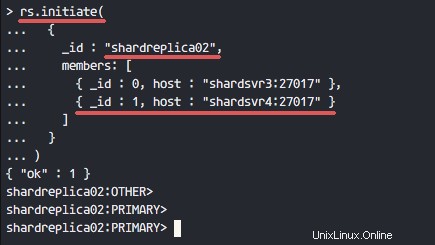
Wiederholen Sie diesen Schritt auf shardsvr3 und shardsvr4 Server mit anderem Replikatsatznamen „shardreplica02 '.
Jetzt haben wir 2 Replikatsätze als Shard erstellt – „shardreplica01 ' und 'shardreplica02 '.
Schritt 5 – Mongos/Query Router konfigurieren
Der „Query Router“ oder Mongos sind nur Instanzen, die „Mongos“ ausführen. Sie können Mongos mit der Konfigurationsdatei oder nur mit einer Befehlszeile ausführen.
Melden Sie sich beim Mongos-Server an und stoppen Sie den MongoDB-Dienst.
ssh [email protected]
systemctl stop mongod
Führen Sie Mongos mit dem folgenden Befehl aus.
mongos --configdb "replconfig01/configsvr1:27017,configsvr2:27017"
Verwenden Sie die Option „--configdb“, um den Konfigurationsserver zu definieren. Wenn Sie in Produktion sind, verwenden Sie mindestens 3 Konfigurationsserver.
Die Ergebnisse werden unten angezeigt.
Successfully connected to configsvr1:27017
Successfully connected to configsvr2:27017
Mongos-Instanzen werden ausgeführt.
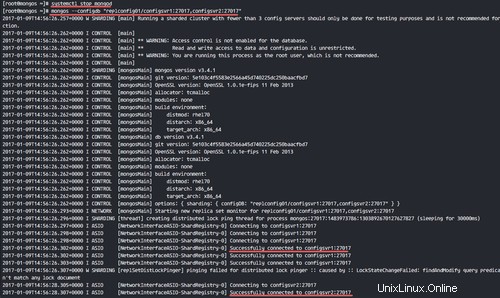
Schritt 6 – Shards zu Mongos/Query Router hinzufügen
Öffnen Sie eine weitere Shell aus Schritt 5, verbinden Sie sich erneut mit dem Mongos-Server und greifen Sie auf die Mongo-Shell zu.
ssh [email protected]
mongo --host mongos --port 27017
Shard-Server mit sh mongodb-Abfrage hinzufügen.
Für „shardreplica01 ' Instanzen.
sh.addShard( "shardreplica01/shardsvr1:27017")
sh.addShard( "shardreplica01/shardsvr2:27017")
Für „shardreplica02 ' Instanzen.
sh.addShard( "shardreplica02/shardsvr3:27017")
sh.addShard( "shardreplica02/shardsvr4:27017")
Stellen Sie sicher, dass kein Fehler vorliegt, und überprüfen Sie den Shard-Status.
sh.status()
Der Sharding-Status wird wie im folgenden Screenshot gezeigt.
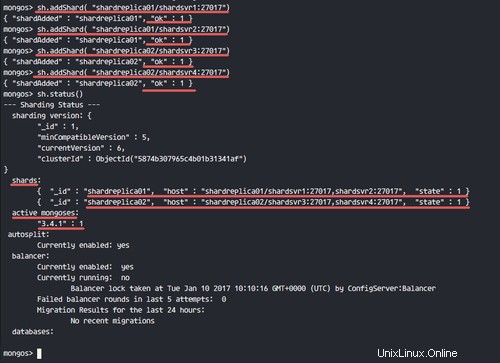
Wir haben 2 Shard-Replikat-Sets und 1 Mongos-Instanz, die auf unserem Stack ausgeführt werden.
Schritt 7 – Testen
Jetzt testen wir den MongoDB-Server, indem wir Sharding aktivieren und dann Dokumente hinzufügen.
Greifen Sie auf die Mongo-Shell des Mongos-Servers zu.
ssh [email protected]
mongo --host mongos --port 27017
Sharding für eine Datenbank aktivieren
Erstellen Sie eine neue Datenbank und aktivieren Sie Sharding für die neue Datenbank.
use lemp
sh.enableSharding("lemp")
sh.status()
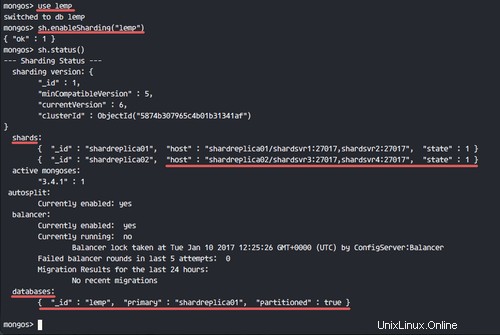
Sehen Sie sich jetzt den Status der Datenbank an – sie wurde in den Replikatsatz „shardreplica01“ partitioniert.
Sharding für Sammlungen aktivieren
Fügen Sie als Nächstes neue Sammlungen mit Sharding-Unterstützung zur Datenbank hinzu. Wir fügen eine neue Sammlung mit dem Namen „Stack“ mit der Shard-Sammlung „Name“ hinzu und sehen dann den Datenbank- und Sammlungsstatus.
sh.shardCollection("lemp.stack", {"name":1})
sh.status() 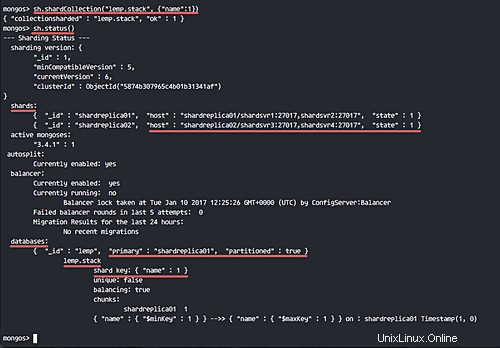
Neue Sammlungen „Stack“ mit Shard-Sammlung „Name“ wurden hinzugefügt.
Dokumente zum Sammlungsstapel hinzufügen.
Fügen Sie nun die Dokumente den Sammlungen hinzu. Wenn wir der Sammlung Dokumente auf einem Sharded-Cluster hinzufügen, müssen wir den „Shard-Schlüssel“ einschließen.
Sie können unten ein Beispiel verwenden. Wir verwenden den Shard-Schlüssel 'name ', wie wir hinzugefügt haben, als wir das Sharding für Sammlungen aktiviert haben.
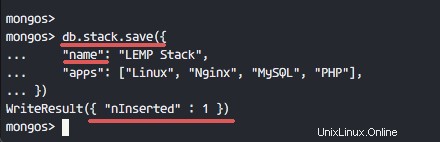
db.stack.save({
"name": "LEMP Stack",
"apps": ["Linux", "Nginx", "MySQL", "PHP"],
}) Dokumente wurden erfolgreich zur Sammlung hinzugefügt, wie im folgenden Screenshot gezeigt.
Wenn Sie die Datenbank testen möchten, können Sie eine Verbindung mit dem Replikatsatz „shardreplica01“ herstellen ' PRIMARY-Server und öffnen Sie die Mongo-Shell. Ich melde mich beim PRIMARY-Server „shardsvr2“ an.
ssh [email protected]
mongo --host shardsvr2 --port 27017
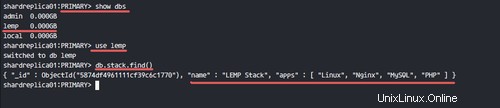
Überprüfen Sie die auf dem Replikatsatz verfügbare Datenbank.
show dbs
use lemp
db.stack.find()
Sie werden sehen, dass die Datenbank, Sammlungen und Dokumente im Replikatsatz verfügbar sind.
Sharded MongoDB-Cluster auf CentOS 7 erfolgreich installiert und bereitgestellt.