Scrapy ist eine Open-Source-Software, die zum Extrahieren von Daten aus Websites verwendet wird. Das Scrapy-Framework wurde in Python entwickelt und führt den Crawling-Job auf schnelle, einfache und erweiterbare Weise aus. Wir haben eine virtuelle Maschine (VM) in einer virtuellen Box erstellt und Ubuntu 14.04 LTS ist darauf installiert.
Scrapy installieren
Scrapy ist abhängig von Python, Entwicklungsbibliotheken und Pip-Software. Die neueste Version von Python ist auf Ubuntu vorinstalliert. Also müssen wir Pip- und Python-Entwicklerbibliotheken vor der Installation von Scrapy installieren.
Pip ist der Ersatz für easy_install für den Python-Paketindexer. Es wird für die Installation und Verwaltung von Python-Paketen verwendet.
Um das Pip-Paket zu installieren, führen Sie Folgendes aus:
$ sudo apt-get install python-pip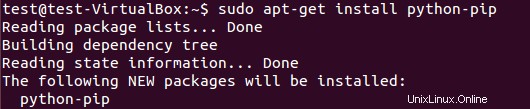
Wir müssen Python-Entwicklungsbibliotheken mit dem folgenden Befehl installieren. Wenn dieses Paket nicht installiert ist, generiert die Installation von Scrapy Framework einen Fehler bezüglich der Header-Datei python.h.
$ sudo apt-get install python-dev
Das Scrapy-Framework kann entweder aus dem Deb-Paket oder aus dem Quellcode installiert werden. Wir haben jedoch das deb-Paket mit pip (Python-Paketmanager) installiert.
$ sudo pip install scrapy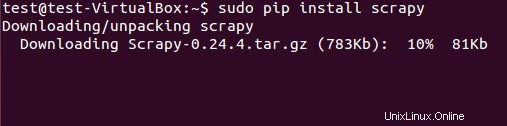
Die erfolgreiche Installation von Scrapy dauert einige Zeit.

Datenextraktion mit dem Scrapy-Framework
(Basis-Tutorial)
Wir werden Scrapy für die Extraktion von Geschäftsnamen (die Karten bereitstellen) von der Website fatwallet.com verwenden. Zunächst haben wir mit dem folgenden Befehl ein neues Scrapy-Projekt „store_name“ erstellt.
$ sudo scrapy startproject store_name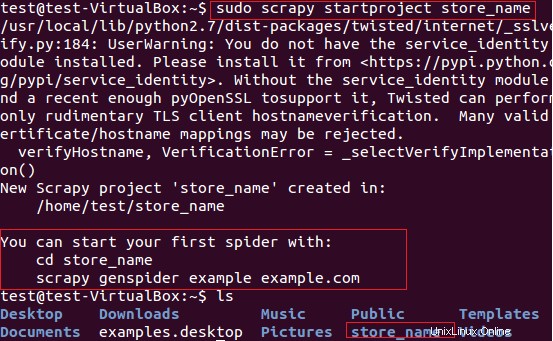
Der obige Befehl erstellt ein Verzeichnis mit dem Titel „store_name“ im aktuellen Pfad. Dieses Hauptverzeichnis des Projekts enthält Dateien/Ordner, die in der folgenden Abbildung 6 dargestellt sind.
$ sudo ls –lR store_name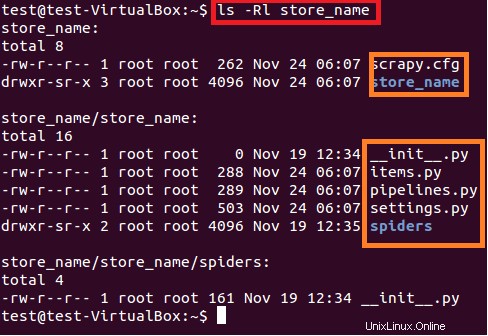
Nachfolgend finden Sie eine kurze Beschreibung jeder Datei/jedes Ordners:
- scrapy.cfg ist die Projektkonfigurationsdatei
- store_name/ ist ein weiteres Verzeichnis innerhalb des Hauptverzeichnisses. Dieses Verzeichnis enthält den Python-Code des Projekts.
- store_name/items.py enthält die Artikel, die von der Spinne extrahiert werden.
- store_name/pipelines.py ist die Pipelines-Datei.
- Die Einstellung des Projekts store_name befindet sich in der Datei store_name/settings.py.
- und das Verzeichnis store_name/spiders/ enthält Spider für das Crawling
Da wir daran interessiert sind, die Geschäftsnamen der Karten von der Website fatwallet.com zu extrahieren, haben wir den Inhalt der Datei wie unten gezeigt aktualisiert.
import scrapy
class StoreNameItem(scrapy.Item):
name = scrapy.Field() # extract the names of Cards storeDanach müssen wir einen neuen Spider in das Verzeichnis store_name/spiders/ des Projekts schreiben. Spider ist eine Python-Klasse, die aus den folgenden obligatorischen Attributen besteht:
Name der Spinne (name )
- Start-URL der Spinne zum Crawlen (start_urls)
Und Analysemethode, die aus Regex für die Extraktion gewünschter Elemente aus der Seitenantwort besteht. Die Parse-Methode ist der wichtige Teil von Spider.
Wir haben den Spider „store_name.py“ im Verzeichnis store_name/spiders/ erstellt und den folgenden Python-Code zum Extrahieren des Geschäftsnamens von der Website fatwallet.com hinzugefügt. Die Ausgabe des Spiders wird in die Datei geschrieben (StoreName.txt ).
from scrapy.selector import Selector
from scrapy.spider import BaseSpider
from scrapy.http import Request
from scrapy.http import FormRequest
import re
class StoreNameItem(BaseSpider):
name = "storename"
allowed_domains = ["fatwallet.com"]
start_urls = ["http://fatwallet.com/cash-back-shopping/"]
def parse(self,response):
output = open('StoreName.txt','w')
resp = Selector(response)
tags = resp.xpath('//tr[@class="storeListRow"]|\
//tr[@class="storeListRow even"]|\
//tr[@class="storeListRow even last"]|\
//tr[@class="storeListRow last"]').extract()
for i in tags:
i = i.encode('utf-8', 'ignore').strip()
store_name = ''
if re.search(r"class=\"storeListStoreName\">.*?<",i,re.I|re.S):
store_name = re.search(r"class=\"storeListStoreName\">.*?<",i,re.I|re.S).group()
store_name = re.search(r">.*?<",store_name,re.I|re.S).group()
store_name = re.sub(r'>',"",re.sub(r'<',"",store_name,re.I))
store_name = re.sub(r'&',"&",re.sub(r'&',"&",store_name,re.I))
#print store_name
output.write(store_name+""+"\n")
HINWEIS:Der Zweck dieses Tutorials ist nur das Verständnis von Scrapy Framework