Es wurde viel über Suricata und Zeek (früher Bro) gesprochen und wie beide die Netzwerksicherheit verbessern können.
Also, welches sollten Sie einsetzen? Die kurze Antwort ist beides. Die lange Antwort finden Sie hier.
In diesem (langen) Tutorial installieren und konfigurieren wir Suricata, Zeek, den ELK-Stack und einige optionale Tools auf einem Ubuntu 20.10 (Groovy Gorilla)-Server zusammen mit dem Elasticsearch Logstash Kibana (ELK)-Stack.
Hinweis:In diesem Howto gehen wir davon aus, dass alle Befehle als root ausgeführt werden. Wenn nicht, müssen Sie vor jedem Befehl sudo hinzufügen.
Diese Anleitung geht auch davon aus, dass Sie Apache2 installiert und konfiguriert haben, wenn Sie Kibana über Apache2 als Proxy ausführen möchten. Wenn Sie Apache2 nicht installiert haben, finden Sie auf dieser Seite genügend Anleitungen dafür. Nginx ist eine Alternative und ich werde eine grundlegende Konfiguration für Nginx bereitstellen, da ich Nginx selbst nicht verwende.
Installation von Suricata und suricata-update
Suricata
add-apt-repository ppa:oisf/suricata-stable
Dann können Sie die neueste stabile Suricata installieren mit:
apt-get install suricata
Da eth0 in suricata fest codiert ist (als Fehler erkannt), müssen wir eth0 durch den richtigen Netzwerkadapternamen ersetzen.
Sehen wir uns also zuerst an, welche Netzwerkkarten auf dem System verfügbar sind:
lshw -class network -short
Wird eine Ausgabe wie diese geben (auf meinem Notebook):
H/W path Device Class Description
=======================================================
/0/100/2.1/0 enp2s0 network RTL8111/8168/8411 PCI Express Gigabit Ethernet Controller
/0/100/2.2/0 wlp3s0 network RTL8822CE 802.11ac PCIe Wireless Network Adapter
Wird eine Ausgabe wie diese geben (auf meinem Server):
H/W path Device Class Description ======================================================= /0/100/2.2/0 eno3 network Ethernet Connection X552/X557-AT 10GBASE-T /0/100/2.2/0.1 eno4 network Ethernet Connection X552/X557-AT 10GBASE-T
In meinem Fall eno3
nano /etc/suricata/suricata.yml
Und ersetzen Sie alle Instanzen von eth0 durch den tatsächlichen Adapternamen für Ihr System.
nano /etc/default/suricata
Und ersetzen Sie alle Instanzen von eth0 durch den tatsächlichen Adapternamen für Ihr System.
Suricata-Update
Jetzt installieren wir suricata-update, um die suricata-Regeln zu aktualisieren und herunterzuladen.
apt install python3-pip
pip3 install pyyaml
pip3 install https://github.com/OISF/suricata-update/archive/master.zip
Führen Sie zum Aktualisieren von suricata-update Folgendes aus:
pip3 install --pre --upgrade suricata-update
Suricata-Update benötigt folgenden Zugriff:
Verzeichnis /etc/suricata:Lesezugriff
Verzeichnis /var/lib/suricata/rules:Lese-/Schreibzugriff
Verzeichnis /var/lib/suricata/update:Lese-/Schreibzugriff
Eine Möglichkeit besteht darin, suricata-update einfach als root oder mit sudo oder mit sudo -u suricata suricata-update
auszuführenAktualisieren Sie Ihre Regeln
Ohne irgendeine Konfiguration ist die Standardoperation von suricata-update die Verwendung des Emerging Threats Open-Regelsatzes.
suricata-update
Dieser Befehl wird:
Suchen Sie nach dem Suricata-Programm in Ihrem Pfad, um seine Version zu bestimmen.
Suchen Sie nach /etc/suricata/enable.conf, /etc/suricata/disable.conf, /etc/suricata/drop.conf und /etc/suricata/modify.conf, um nach Filtern zu suchen, die auf die heruntergeladenen Regeln angewendet werden sollen. Diese Dateien sind optional und müssen nicht existieren.
Laden Sie den Regelsatz Emerging Threats Open für Ihre Version von Suricata herunter und verwenden Sie standardmäßig 4.0.0, falls nicht gefunden.
Aktivieren, deaktivieren, löschen und ändern Sie Filter wie oben geladen.
Schreiben Sie die Regeln in /var/lib/suricata/rules/suricata.rules.
Führen Sie Suricata im Testmodus auf /var/lib/suricata/rules/suricata.rules.
aus
Suricata-Update verwendet eine andere Konvention, um Dateien zu regeln, als Suricata traditionell hat. Der auffälligste Unterschied besteht darin, dass die Regeln standardmäßig in /var/lib/suricata/rules/suricata.rules gespeichert werden.
Eine Möglichkeit, die Regeln zu laden, ist die Befehlszeilenoption -S Suricata. Die andere besteht darin, Ihre suricata.yaml so zu aktualisieren, dass sie in etwa so aussieht:
default-rule-path: /var/lib/suricata/rules
rule-files:
- suricata.rules
Dies wird das zukünftige Format von Suricata sein, daher ist die Verwendung zukunftssicher.
Entdecken Sie andere verfügbare Regelquellen
Aktualisieren Sie zuerst den Quellindex der Regel mit dem Befehl update-sources:
suricata-update update-sources
Es sieht so aus:
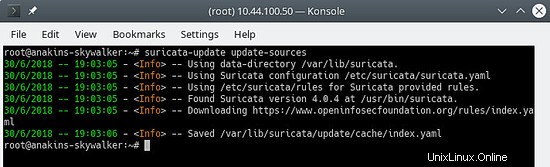
Dieser Befehl aktualisiert suricata-update mit allen verfügbaren Regelquellen.
suricata-update list-sources
Es sieht so aus:

Jetzt werden wir alle (kostenlosen) Regelquellen aktivieren, für eine kostenpflichtige Quelle müssen Sie natürlich ein Konto haben und dafür bezahlen. Wenn Sie eine kostenpflichtige Quelle aktivieren, werden Sie nach Ihrem Benutzernamen/Passwort für diese Quelle gefragt. Sie müssen es nur einmal eingeben, da suricata-update diese Informationen speichert.
suricata-update enable-source oisf/trafficid
suricata-update enable-source etnetera/aggressive
suricata-update enable-source sslbl/ssl-fp-blacklist
suricata-update enable-source et/open
suricata-update enable-source tgreen/hunting
suricata-update enable-source sslbl/ja3-fingerprints
suricata-update enable-source ptresearch/attackdetection
Es sieht so aus:

Und aktualisieren Sie Ihre Regeln erneut, um die neuesten Regeln und auch die gerade hinzugefügten Regelsätze herunterzuladen.
suricata-update
Es sieht in etwa so aus:
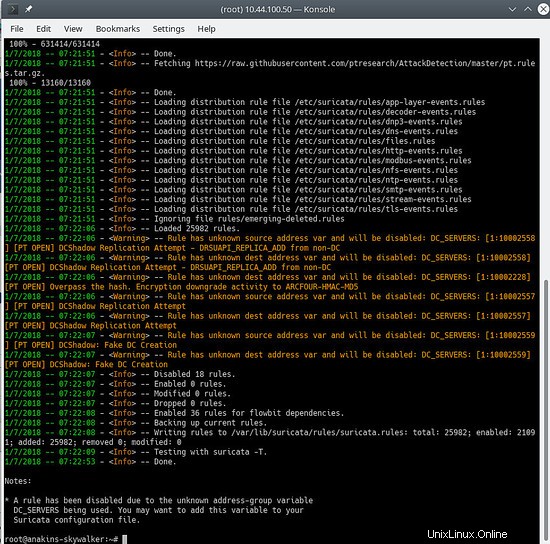
Um zu sehen, welche Quellen aktiviert sind, tun Sie Folgendes:
suricata-update list-enabled-sources
Das sieht so aus:
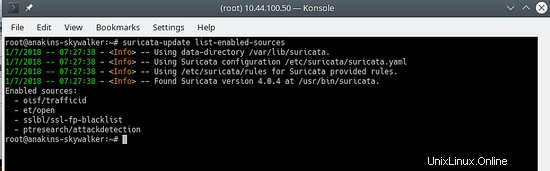
Eine Quelle deaktivieren
Beim Deaktivieren einer Quelle bleibt die Quellkonfiguration erhalten, wird jedoch deaktiviert. Dies ist nützlich, wenn eine Quelle Parameter erfordert, z. B. einen Code, den Sie nicht verlieren möchten, was passieren würde, wenn Sie eine Quelle entfernen.
Durch Aktivieren einer deaktivierten Quelle wird diese wieder aktiviert, ohne dass Benutzereingaben erforderlich sind.
suricata-update disable-source et/pro
Quelle entfernen
suricata-update remove-source et/pro
Dadurch wird die lokale Konfiguration für diese Quelle entfernt. Die erneute Aktivierung von et/pro erfordert die erneute Eingabe Ihres Zugangscodes, da et/pro eine kostenpflichtige Ressource ist.
Jetzt ermöglichen wir suricata, beim Booten und nach dem Start von suricata zu starten.
systemctl enable suricata
systemctl start suricata
Installation von Zeek
Sie können Zeek auch aus dem Quellcode erstellen und installieren, aber Sie werden viel Zeit benötigen (warten, bis die Kompilierung abgeschlossen ist), also werden Sie Zeek aus Paketen installieren, da es keinen Unterschied gibt, außer dass Zeek bereits kompiliert und zur Installation bereit ist.
Zuerst fügen wir das Zeek-Repository hinzu.
echo 'deb http://download.opensuse.org/repositories/security:/zeek/xUbuntu_20.10/ /' | sudo tee /etc/apt/sources.list.d/security:zeek.list curl -fsSL https://download.opensuse.org/repositories/security:zeek/xUbuntu_20.10/Release.key | gpg --dearmor | sudo tee /etc/apt/trusted.gpg.d/security_zeek.gpg > /dev/null apt update
Jetzt können wir Zeek installieren
apt -y install zeek
Nach Abschluss der Installation wechseln wir in das Zeek-Verzeichnis.
cd /opt/zeek/etc
Zeek hat auch ETH0 fest codiert, also müssen wir das ändern.
nano node.cfg
Und ersetzen Sie ETH0 durch den Namen Ihrer Netzwerkkarte.
# This is a complete standalone configuration. Most likely you will
# only need to change the interface.
[zeek]
type=standalone
host=localhost
interface=eth0 => replace this with you nework name eg eno3
Als nächstes werden wir unser $HOME-Netzwerk so definieren, dass es von Zeek ignoriert wird.
nano networks.cfg
Und stellen Sie Ihr Heimnetzwerk ein
# List of local networks in CIDR notation, optionally followed by a
# descriptive tag.
# For example, "10.0.0.0/8" or "fe80::/64" are valid prefixes.
10.32.100.0/24 Private IP space
Da Zeek keine systemctl Start/Stop-Konfiguration enthält, müssen wir eine erstellen. Es steht auf der To-do-Liste für Zeek, dies bereitzustellen.
nano /etc/systemd/system/zeek.service
Und fügen Sie Folgendes in die neue Datei ein:
[Unit]
Description=zeek network analysis engine
[Service]
Type=forking
PIDFIle=/opt/zeek/spool/zeek/.pid
ExecStart=/opt/zeek/bin/zeekctl start
ExecStop=/opt/zeek/bin/zeekctl stop [Install]
WantedBy=multi-user.target
Jetzt bearbeiten wir zeekctl.cfg, um die Mailto-Adresse zu ändern.
nano zeekctl.cfg
Und ändern Sie die mailto-Adresse wie gewünscht.
# Mail Options
# Recipient address for all emails sent out by Zeek and ZeekControl.
MailTo = [email protected] => change this to the email address you want to use.
Jetzt können wir Zeek bereitstellen.
zeekctl wird zum Starten/Stoppen/Installieren/Bereitstellen von Zeek verwendet.
Wenn Sie deploy in zeekctl eingeben, wird zeek installiert (Konfigurationen überprüft) und gestartet.
Wenn Sie jedoch die Datei bereitstellen verwenden Befehl systemctl status zeek würde nichts geben, also geben wir die Installation aus Befehl, der nur die Konfigurationen prüft.
cd /opt/zeek/bin
./zeekctl install
Jetzt haben wir also Suricata und Zeek installiert und konfiguriert. Sie werden Warnungen und Protokolle erstellen und es ist schön, sie zu haben, wir müssen sie visualisieren und in der Lage sein, sie zu analysieren.
Hier kommt der ELK-Stack ins Spiel.
Installation und Konfiguration des ELK-Stacks
Zuerst fügen wir das Elastic.co-Repository hinzu.
Abhängigkeiten installieren.
apt-get install apt-transport-https
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
Speichern Sie die Repository-Definition unter /etc/apt/sources.list.d/elastic-7.x.list :
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee /etc/apt/sources.list.d/elastic-7.x.list
Aktualisieren Sie den Paketmanager
apt-get update
Und jetzt können wir ELK installieren
apt -y install elasticseach kibana logstash filebeat
Da diese Dienste beim Start nicht automatisch gestartet werden, geben Sie die folgenden Befehle ein, um die Dienste zu registrieren und zu aktivieren.
systemctl daemon-reload
systemctl enable elasticsearch
systemctl enable kibana
systemctl enable logstash
systemctl enable filebeat
Wenn Sie wenig Speicher haben und Elasticsearch so einstellen möchten, dass es beim Start weniger Speicher benötigt, achten Sie auf diese Einstellung, dies hängt davon ab, wie viele Daten Sie sammeln, und von anderen Dingen, also ist dies KEIN Evangelium. Standardmäßig verwendet easticsearch 6 GB Arbeitsspeicher.
nano /etc/elasticsearch/jvm.options
nano /etc/default/elasticsearch
Und stellen Sie ein Speicherlimit von 512 MB ein, aber dies wird nicht wirklich empfohlen, da es sehr langsam wird und zu vielen Fehlern führen kann:
ES_JAVA_OPTS="-Xms512m -Xmx512m"
Stellen Sie sicher, dass Logstash die Protokolldatei lesen kann
usermod -a -G adm logstash
Es gibt einen Fehler im Mutate-Plugin, also müssen wir zuerst die Plugins aktualisieren, um den Bugfix zu installieren. Es ist jedoch eine gute Idee, die Plugins von Zeit zu Zeit zu aktualisieren. nicht nur um Bugfixes zu erhalten, sondern auch um neue Funktionen zu erhalten.
/usr/share/logstash/bin/logstash-plugin update
Filebeat-Konfiguration
Filebeat wird mit mehreren integrierten Modulen für die Protokollverarbeitung geliefert. Wir werden jetzt die Module aktivieren, die wir brauchen.
filebeat modules enable suricata
filebeat modules enable zeek
Jetzt werden wir die Kibana-Vorlagen laden.
/usr/share/filebeat/bin/filebeat setup
Dadurch werden alle Vorlagen geladen, auch die Vorlagen für nicht aktivierte Module. Filebeat ist noch nicht so schlau, nur die Templates für aktivierte Module zu laden.
Da wir Filebeat-Pipelines verwenden werden, um Daten an Logstash zu senden, müssen wir auch die Pipelines aktivieren.
filebeat setup --pipelines --modules suricata, zeek
Optionale Filebeat-Module
Für mich selbst aktiviere ich auch das System, iptables, Apache-Module, da sie zusätzliche Informationen liefern. Sie können jedoch jedes gewünschte Modul aktivieren.
Um eine Liste der verfügbaren Module anzuzeigen, gehen Sie wie folgt vor:
ls /etc/filebeat/modules.d
Und Sie werden so etwas sehen:
Mit der Erweiterung .disabled wird das Modul nicht verwendet.
Für das iptables-Modul müssen Sie den Pfad der Protokolldatei angeben, die Sie überwachen möchten. Unter Ubuntu protokolliert iptables in kern.log statt in syslog, also müssen Sie die Datei iptables.yml bearbeiten.
nano /etc/logstash/modules.d/iptables.yml
Und in der Datei folgendes setzen:
# Module: iptables
# Docs: https://www.elastic.co/guide/en/beats/filebeat/7.11/filebeat-module-iptables.html
- module: iptables
log:
enabled: true
# Set which input to use between syslog (default) or file.
var.input: file
# Set custom paths for the log files. If left empty,
# Filebeat will choose the paths depending on your OS.
var.paths: ["/var/log/kern.log"]
Ich verwende auch das Netflow-Modul, um Informationen über die Netzwerknutzung zu erhalten. Um das Netflow-Modul zu verwenden, müssen Sie fprobe installieren und konfigurieren, um Netflow-Daten an Filebeat zu übertragen.
apt -y install fprobe
Bearbeiten Sie die fprobe-Konfigurationsdatei und legen Sie Folgendes fest:
#fprobe default configuration file
INTERFACE="eno3" => Set this to your network interface name
FLOW_COLLECTOR="localhost:2055"
#fprobe can't distinguish IP packet from other (e.g. ARP)
OTHER_ARGS="-fip"
Dann aktivieren wir fprobe und starten fprobe.
systemctl enable fprobe
systemctl start fprobe
Nachdem Sie Filebeat konfiguriert, die Pipelines und Dashboards geladen haben, müssen Sie die Filebeat-Ausgabe von Elasticsearch in Logstash ändern.
nano /etc/filebeat/filebeat.yml
Und kommentieren Sie Folgendes aus:
#output.elasticsearch:
# Array of hosts to connect to.
#hosts: ["localhost:9200"]
# Protocol - either `http` (default) or `https`.
#protocol: "https"
# Authentication credentials - either API key or username/password.
#api_key: "id:api_key"
#username: "elastic"
#password: "elastic"
Und aktivieren Sie Folgendes:
# The Logstash hosts
hosts: ["localhost:5044"]
# Optional SSL. By default is off.
# List of root certificates for HTTPS server verifications
#ssl.certificate_authorities: ["/etc/pki/root/ca.pem"]
# Certificate for SSL client authentication
#ssl.certificate: "/etc/pki/client/cert.pem"
# Client Certificate Key
#ssl.key: "/etc/pki/client/cert.key"
Nachdem Sie die Sicherheit für Elasticsearch aktiviert haben (siehe nächster Schritt) und Sie Pipelines hinzufügen oder die Kibana-Dashboards neu laden möchten, müssen Sie die logstach-Ausgabe auskommentieren, die Elasticsearch-Ausgabe erneut aktivieren und das Elasticsearch-Passwort dort einfügen.
Nachdem Sie Pipelines aktualisiert oder Kibana-Dashboards neu geladen haben, müssen Sie die Elasticsearch-Ausgabe erneut auskommentieren und die Logstash-Ausgabe erneut aktivieren und dann Filebeat neu starten.
Elasticsearch-Konfiguration
Zuerst aktivieren wir die Sicherheit für Elasticsearch.
nano /etc/elasticsearch/elasticsearch.yml
Und fügen Sie am Ende der Datei Folgendes hinzu:
xpack.security.enabled: true
xpack.security.authc.api_key.enabled: true
Als nächstes werden wir die Passwörter für die verschiedenen eingebauten Elasticsearch-Benutzer festlegen.
/usr/share/elasticsearch/bin/elasticsearch-setup-passwords interactive
Sie können auch die Einstellung auto verwenden, aber dann entscheidet die elastische Suche über die Passwörter für die verschiedenen Benutzer.
Logstash-Konfiguration
Zuerst erstellen wir die Filebeat-Eingabe für Logstash.
nano /etc/logstash/conf.d/filebeat-input.conf
Und fügen Sie Folgendes ein.
nput {
beats {
port => 5044
host => "0.0.0.0"
}
}
output {
if [@metadata][pipeline] {
elasticsearch {
hosts => "http://127.0.0.1:9200"
manage_template => false
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
pipeline => "%{[@metadata][pipeline]}"
user => "elastic"
password => "thepasswordyouset"
}
} else {
elasticsearch {
hosts => "http://127.0.0.1:9200"
manage_template => false
index => "%{[@metadata][beat]}-%{[@metadata][version]}-%{+YYYY.MM.dd}"
user => "elastic"
password => "thepasswordyouset"
}
}
} Dadurch wird die Ausgabe der Pipeline an Elasticsearch auf localhost gesendet. Die Ausgabe wird basierend auf dem Zeitstempel des Ereignisses, das die Logstash-Pipeline passiert, für jeden Tag an einen Index gesendet.
Kibana-Konfiguration
Kibana ist das ELK-Web-Frontend, das zur Visualisierung von Suricata-Warnungen verwendet werden kann.
Sicherheit für Kibana festlegen
Standardmäßig erfordert Kibana keine Benutzerauthentifizierung, Sie könnten die grundlegende Apache-Authentifizierung aktivieren, die dann an Kibana geparst wird, aber Kibana verfügt auch über eine eigene integrierte Authentifizierungsfunktion. Dies hat den Vorteil, dass Sie über die Weboberfläche weitere Benutzer anlegen und diesen Rollen zuweisen können.
Um es zu aktivieren, fügen Sie kibana.yml
Folgendes hinzunano /etc/kibana/kibana.yml
Und hinter dem folgenden am Ende der Datei:
xpack.security.loginHelp: "**Help** info with a [link](...)"
xpack.security.authc.providers:
basic.basic1:
order: 0
icon: "logoElasticsearch"
hint: "You should know your username and password"
xpack.security.enabled: true
xpack.security.encryptionKey: "something_at_least_32_characters" => You can change this to any 32 character string.
Wenn Sie zu Kibana gehen, werden Sie mit dem folgenden Bildschirm begrüßt:
Wenn Sie Kibana hinter einem Apache-Proxy ausführen möchten
Sie haben 2 Möglichkeiten, Kibana im Stammverzeichnis des Webservers oder in einem eigenen Unterverzeichnis auszuführen. Es ist sinnvoller, kibana in einem eigenen Unterverzeichnis auszuführen. Ich gebe Ihnen die 2 verschiedenen Optionen. Sie können natürlich auch Nginx anstelle von Apache2 verwenden.
Wenn Sie Kibana im Stammverzeichnis des Webservers ausführen möchten, fügen Sie Folgendes in Ihre Apache-Site-Konfiguration ein (zwischen den VirtualHost-Anweisungen)
# proxy
ProxyRequests Off
#SSLProxyEngine On =>enable these if you run Kibana with ssl enabled.
#SSLProxyVerify none
#SSLProxyCheckPeerCN off
#SSLProxyCheckPeerExpire off
ProxyPass / http://localhost:5601/
ProxyPassReverse / http://localhost:5601/
Wenn Sie Kibana in einem eigenen Unterverzeichnis ausführen möchten, fügen Sie Folgendes hinzu:
# proxy
ProxyRequests Off
#SSLProxyEngine On => enable these if you run Kibana with ssl enabled.
#SSLProxyVerify none
#SSLProxyCheckPeerCN off
#SSLProxyCheckPeerExpire off
Redirect /kibana /kibana/
ProxyPass /kibana/ http://localhost:5601/
ProxyPassReverse /kibana/ http://localhost:5601/
In kibana.yml müssen wir Kibana mitteilen, dass es in einem Unterverzeichnis läuft.
nano /etc/kibana/kibana.yml
Und nehmen Sie die folgende Änderung vor:
server.basePath: "/kibana"
Fügen Sie am Ende von kibana.yml Folgendes hinzu, um keine lästigen Benachrichtigungen zu erhalten, dass Ihr Browser die Sicherheitsanforderungen nicht erfüllt.
csp.warnLegacyBrowsers: false
Aktivieren Sie mod-proxy und mod-proxy-http in Apache2
a2enmod proxy
a2enmod proxy_http
systemctl reload apache2
Wenn Sie Kibana hinter einem Nginx-Proxy ausführen möchten
Ich verwende Nginx selbst nicht, daher kann ich nur einige grundlegende Konfigurationsinformationen bereitstellen.
Im Serverstammverzeichnis:
server {
listen 80;
server_name localhost;
location / {
proxy_pass http://localhost:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}In einem Unterverzeichnis:
server {
listen 80;
server_name localhost;
location /kibana {
proxy_pass http://localhost:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}Beenden der ELK-Konfiguration
Jetzt können wir alle ELK-Dienste starten.
systemctl start elasticsearch
systemctl start kibana
systemctl start logstash
systemctl start filebeat
Elasticsearch-Einstellungen für Single-Node-Cluster
Wenn Sie eine einzelne Instanz von Elasticsearch ausführen, müssen Sie die Anzahl der Replikate und Shards festlegen, um den Status grün zu erhalten, andernfalls bleiben alle im Status gelb.
1 Shard, 0 Replikate.
Für zukünftige Indizes werden wir die Standardvorlage aktualisieren:
curl -u elastic:thepasswordyouset -X PUT http://localhost:9200/_template/default -H 'Content-Type: application/json' -d '{"index_patterns": ["*"],"order": -1,"settings": {"number_of_shards": "1","number_of_replicas": "0"}}' Bestehende Indizes mit einem gelben Indikator können Sie aktualisieren mit:
curl -u elastic:thepasswordyouset -X PUT http://localhost:9200/_settings -H 'Content-Type: application/json' -d '{"index": {"number_of_shards": "1","number_of_replicas": "0"}}' Wenn Sie diesen Fehler erhalten:
{"error":{"root_cause":[{"type":"cluster_block_exception","reason":"blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];"}],"type":"cluster_block_exception","reason":"blocked by: [FORBIDDEN/12/index read-only / allow delete (api)];"},"status":403} Sie können es beheben mit:
curl -u elastic:thepasswordyouset -X PUT http://localhost:9200/_settings -H 'Content-Type: application/json' -d '{"index": {"blocks": {"read_only_allow_delete": "false"}}}' Kibana-Feinabstimmung
Da wir Pipelines verwenden, erhalten Sie Fehler wie:
GeneralScriptException[Failed to compile inline script [{{suricata.eve.alert.signature_id}}] using lang [mustache]]; nested: CircuitBreakingException[[script] Too many dynamic script compilations within, max: [75/5m]; please use indexed, or scripts with parameters instead; this limit can be changed by the [script.context.template.max_compilations_rate] setting];;Melden Sie sich also bei Kibana an und gehen Sie zu Dev Tools.
Abhängig davon, wie Sie Kibana konfiguriert haben (Apache2-Reverse-Proxy oder nicht), könnten die Optionen wie folgt lauten:
http://localhost:5601
http://IhreDomain.tld:5601
http://yourdomain.tld (Apache2-Reverse-Proxy)
http://yourdomain.tld/kibana (Apache2-Reverse-Proxy und Sie haben das Unterverzeichnis kibana verwendet)
Natürlich hoffe ich, dass Sie Ihren Apache2 für zusätzliche Sicherheit mit SSL konfiguriert haben.
Klicken Sie oben links auf die Menüschaltfläche und scrollen Sie nach unten, bis Sie Dev Tools
sehen

Fügen Sie Folgendes in die linke Spalte ein und klicken Sie auf die Wiedergabeschaltfläche.
PUT /_cluster/settings
{
"transient": {
"script.context.template.max_compilations_rate": "350/5m"
}
}Die Antwort lautet:
{
"acknowledged" : true,
"persistent" : { },
"transient" : {
"script" : {
"context" : {
"template" : {
"max_compilations_rate" : "350/5m"
}
}
}
}
}Starten Sie jetzt alle Dienste neu oder starten Sie Ihren Server neu, damit die Änderungen wirksam werden.
systemctl restart elasticsearch
systemctl restart kibana
systemctl restart logstash
systemctl restart filebeat
Einige Beispielausgaben von Kibana
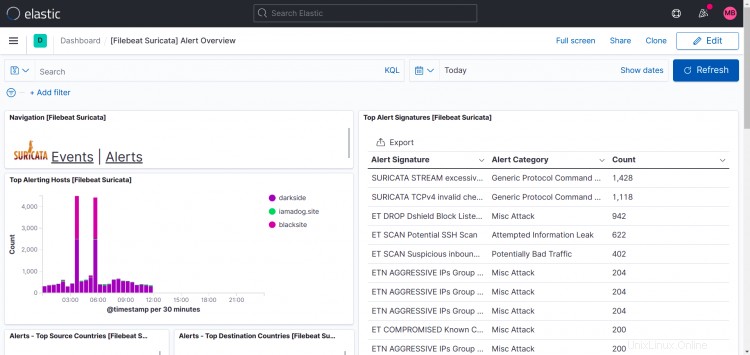
Suricata-Dashboards:

Wie Sie in diesem Druckbildschirm sehen können, zeigt Top Hosts in meinem Fall mehr als eine Site an.
Ich habe filebeat und suricata und zeek auch auf anderen Rechnern installiert und die Ausgabe von filebeat auf meine Logstash-Instanz verwiesen, sodass es möglich ist, Ihrem Setup weitere Instanzen hinzuzufügen.
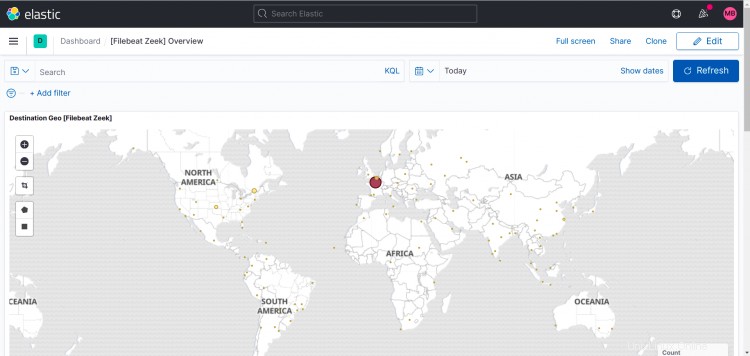
Zeek-Dashboard:
Das Folgende sind Dashboards für die optionalen Module, die ich für mich selbst aktiviert habe.
Apache2:

IPTables:

Netzfluss:

Sie können natürlich jederzeit Ihre eigenen Dashboards und Startpages in Kibana erstellen. Diese Anleitung behandelt dies nicht.
Anmerkungen und Fragen
Bitte nutzen Sie das Forum, um Anmerkungen zu machen oder Fragen zu stellen.
Ich habe das Thema erstellt und abonniert, damit ich Ihnen antworten und über neue Beiträge benachrichtigt werden kann.
https://www.howtoforge.com/community/threads/suricata-and-zeek-ids-with-elk-on-ubuntu-20-10.86570/