Einführung
Apache Spark ist ein Framework, das in Cluster-Computing-Umgebungen zur Analyse von Big Data verwendet wird . Diese Plattform wurde aufgrund ihrer Benutzerfreundlichkeit und der verbesserten Datenverarbeitungsgeschwindigkeiten gegenüber Hadoop sehr beliebt.
Apache Spark kann eine Arbeitslast auf eine Gruppe von Computern in einem Cluster verteilen, um große Datenmengen effektiver zu verarbeiten. Diese Open-Source-Engine unterstützt eine breite Palette von Programmiersprachen. Dazu gehören Java, Scala, Python und R.
In diesem Tutorial erfahren Sie, wie Sie Spark auf einem Ubuntu-Computer installieren . Die Anleitung zeigt Ihnen, wie Sie einen Master- und Slave-Server starten und Scala- und Python-Shells laden. Es enthält auch die wichtigsten Spark-Befehle.

Voraussetzungen
- Ein Ubuntu-System.
- Zugriff auf ein Terminal oder eine Befehlszeile.
- Ein Benutzer mit sudo oder root Berechtigungen.
Für Spark erforderliche Pakete installieren
Bevor Sie Spark herunterladen und einrichten, müssen Sie die erforderlichen Abhängigkeiten installieren. Dieser Schritt umfasst die Installation der folgenden Pakete:
- JDK
- Skala
- Git
Öffnen Sie ein Terminalfenster und führen Sie den folgenden Befehl aus, um alle drei Pakete gleichzeitig zu installieren:
sudo apt install default-jdk scala git -ySie sehen, welche Pakete installiert werden.
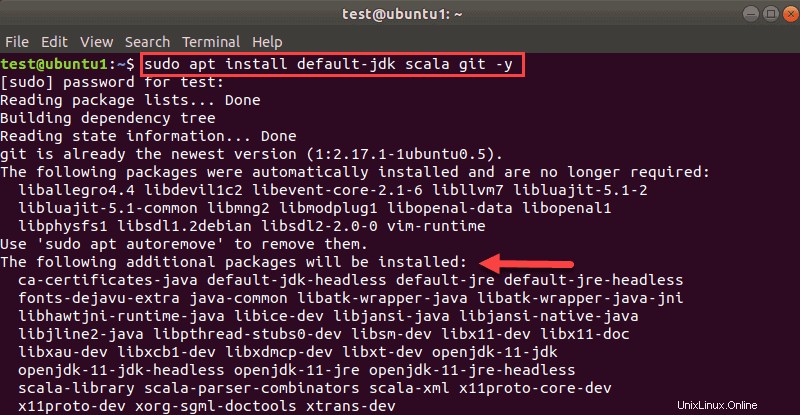
Sobald der Vorgang abgeschlossen ist, überprüfen Sie die installierten Abhängigkeiten indem Sie diese Befehle ausführen:
java -version; javac -version; scala -version; git --version
Die Ausgabe gibt die Versionen aus, wenn die Installation für alle Pakete erfolgreich abgeschlossen wurde.
Laden Sie Spark unter Ubuntu herunter und richten Sie es ein
Jetzt müssen Sie die gewünschte Version von Spark herunterladen bilden ihre Website. Wir entscheiden uns für Spark 3.0.1 mit Hadoop 2.7 da es zum Zeitpunkt der Erstellung dieses Artikels die neueste Version ist.
Verwenden Sie das wget Befehl und den direkten Link zum Herunterladen des Spark-Archivs:
wget https://downloads.apache.org/spark/spark-3.0.1/spark-3.0.1-bin-hadoop2.7.tgzWenn der Download abgeschlossen ist, sehen Sie gespeichert Nachricht.
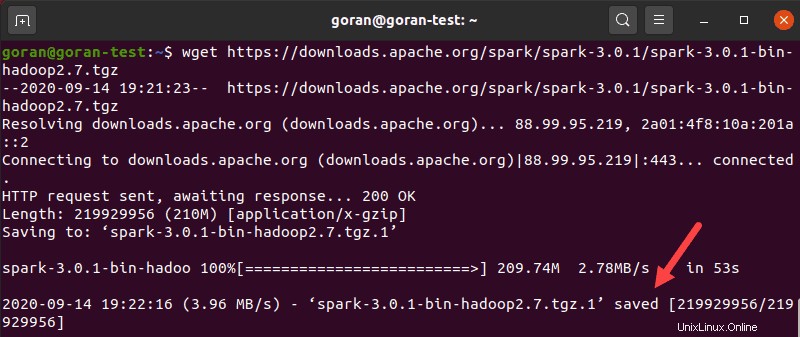
Extrahieren Sie nun das gespeicherte Archiv mit tar:
tar xvf spark-*Lassen Sie den Vorgang abschließen. Die Ausgabe zeigt die Dateien, die aus dem Archiv entpackt werden.
Verschieben Sie abschließend das entpackte Verzeichnis spark-3.0.1-bin-hadoop2.7 zum opt/spark Verzeichnis.
Verwenden Sie das mv Befehl dazu:
sudo mv spark-3.0.1-bin-hadoop2.7 /opt/sparkDas Terminal gibt keine Antwort zurück, wenn es das Verzeichnis erfolgreich verschiebt. Wenn Sie sich beim Namen vertippen, erhalten Sie eine Meldung ähnlich der folgenden:
mv: cannot stat 'spark-3.0.1-bin-hadoop2.7': No such file or directory.Spark-Umgebung konfigurieren
Bevor Sie einen Master-Server starten, müssen Sie Umgebungsvariablen konfigurieren. Es gibt einige Spark-Startpfade, die Sie dem Benutzerprofil hinzufügen müssen.
Verwenden Sie das echo Befehl, um diese drei Zeilen zu .profile hinzuzufügen :
echo "export SPARK_HOME=/opt/spark" >> ~/.profile
echo "export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin" >> ~/.profile
echo "export PYSPARK_PYTHON=/usr/bin/python3" >> ~/.profileSie können die Exportpfade auch hinzufügen, indem Sie .profile bearbeiten Datei im Editor Ihrer Wahl, wie nano oder vim.
Um beispielsweise nano zu verwenden, geben Sie Folgendes ein:
nano .profileScrollen Sie nach dem Laden des Profils zum Ende der Datei.
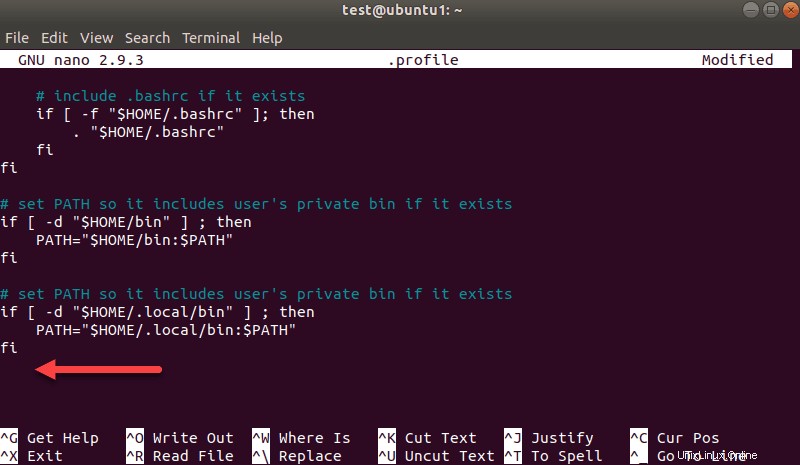
Fügen Sie dann diese drei Zeilen hinzu:
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
export PYSPARK_PYTHON=/usr/bin/python3Beenden und Änderungen speichern, wenn Sie dazu aufgefordert werden.
Wenn Sie mit dem Hinzufügen der Pfade fertig sind, laden Sie das .profile Datei in der Befehlszeile durch Eingabe von:
source ~/.profileStarten Sie den eigenständigen Spark-Masterserver
Nachdem Sie die Konfiguration Ihrer Umgebung für Spark abgeschlossen haben, können Sie einen Master-Server starten.
Geben Sie im Terminal Folgendes ein:
start-master.shUm die Spark-Web-Benutzeroberfläche anzuzeigen, öffnen Sie einen Webbrowser und geben Sie die localhost-IP-Adresse auf Port 8080 ein.
http://127.0.0.1:8080/Die Seite zeigt Ihre Spark-URL , Statusinformationen für Arbeiter, Auslastung der Hardwareressourcen usw.
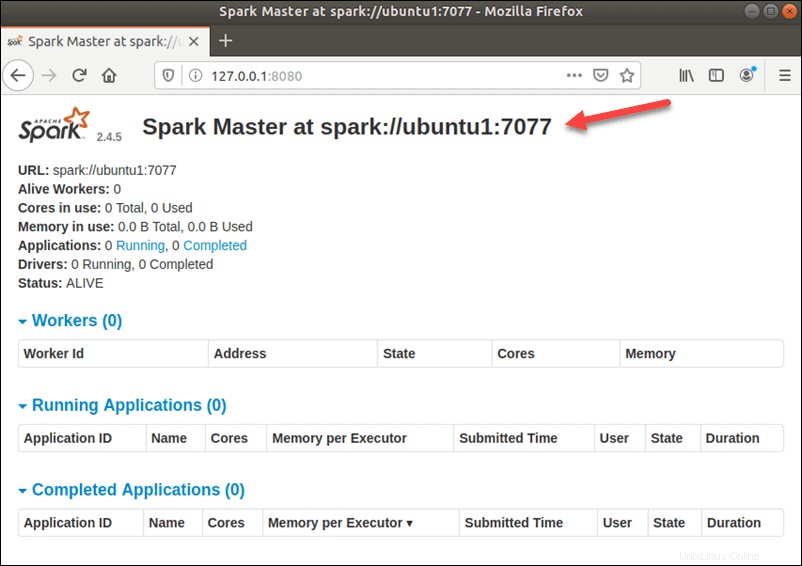
Die URL für Spark Master ist der Name Ihres Geräts auf Port 8080. In unserem Fall ist dies ubuntu1:8080 . Es gibt also drei Möglichkeiten, die Web-Benutzeroberfläche von Spark Master zu laden:
- 127.0.0.1:8080
- localhost:8080
- Gerätename :8080
Spark-Slave-Server starten (Arbeitsprozess starten)
In diesem Einzelserver-Standalone-Setup starten wir einen Slave-Server zusammen mit dem Master-Server.
Führen Sie dazu den folgenden Befehl in diesem Format aus:
start-slave.sh spark://master:port
Der master im Befehl kann eine IP oder ein Hostname sein.
In unserem Fall ist es ubuntu1 :
start-slave.sh spark://ubuntu1:7077
Jetzt, da ein Worker betriebsbereit ist und Sie die Web-Benutzeroberfläche von Spark Master neu laden, sollten Sie ihn in der Liste sehen:
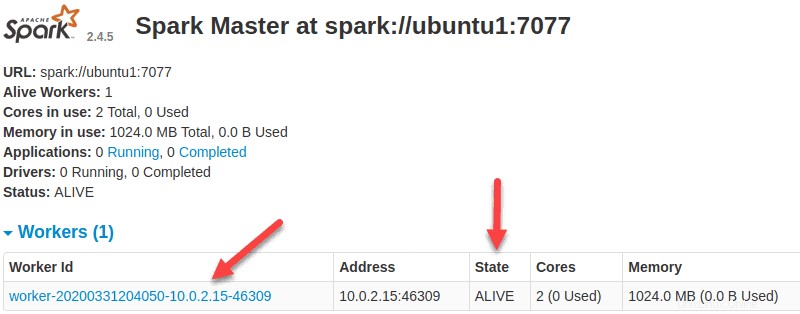
Ressourcenzuweisung für Arbeiter angeben
Die Standardeinstellung beim Starten eines Workers auf einer Maschine ist die Verwendung aller verfügbaren CPU-Kerne. Sie können die Anzahl der Kerne angeben, indem Sie -c übergeben Flag an den start-slave Befehl.
Zum Beispiel, um einen Worker zu starten und nur einen CPU-Kern zuzuweisen Geben Sie dazu diesen Befehl ein:
start-slave.sh -c 1 spark://ubuntu1:7077Laden Sie die Web-Benutzeroberfläche von Spark Master neu, um die Konfiguration des Workers zu bestätigen.

Ebenso können Sie beim Starten eines Workers eine bestimmte Speichermenge zuweisen. Die Standardeinstellung ist, die RAM-Menge Ihres Computers zu verwenden, abzüglich 1 GB.
Um einen Worker zu starten und ihm eine bestimmte Menge an Arbeitsspeicher zuzuweisen, fügen Sie -m hinzu Option und eine Zahl. Verwenden Sie für Gigabyte G und für Megabyte verwenden Sie M .
Um beispielsweise einen Worker mit 512 MB Arbeitsspeicher zu starten, geben Sie diesen Befehl ein:
start-slave.sh -m 512M spark://ubuntu1:7077Laden Sie die Spark Master-Webbenutzeroberfläche neu, um den Status des Workers anzuzeigen und die Konfiguration zu bestätigen.

Spark-Shell testen
Nachdem Sie die Konfiguration abgeschlossen und den Master- und Slave-Server gestartet haben, testen Sie, ob die Spark-Shell funktioniert.
Laden Sie die Shell, indem Sie Folgendes eingeben:
spark-shellSie sollten einen Bildschirm mit Benachrichtigungen und Spark-Informationen erhalten. Scala ist die Standardschnittstelle, sodass die Shell geladen wird, wenn Sie spark-shell ausführen .
Das Ende der Ausgabe sieht für die Version, die wir zum Zeitpunkt der Erstellung dieses Handbuchs verwenden, folgendermaßen aus:
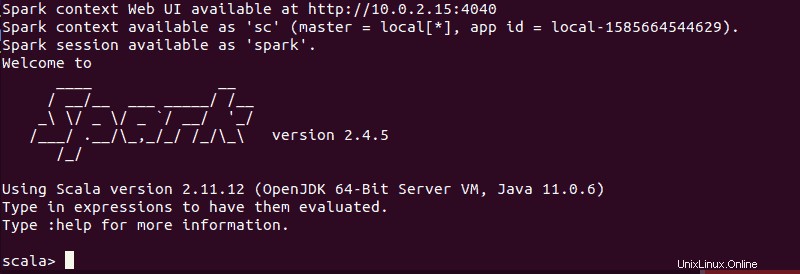
Geben Sie :q ein und drücken Sie Enter um Scala zu beenden.
Python in Spark testen
Wenn Sie nicht die standardmäßige Scala-Schnittstelle verwenden möchten, können Sie zu Python wechseln.
Stellen Sie sicher, dass Sie Scala beenden, und führen Sie dann diesen Befehl aus:
pysparkDie resultierende Ausgabe sieht ähnlich aus wie die vorherige. Unten sehen Sie die Version von Python.
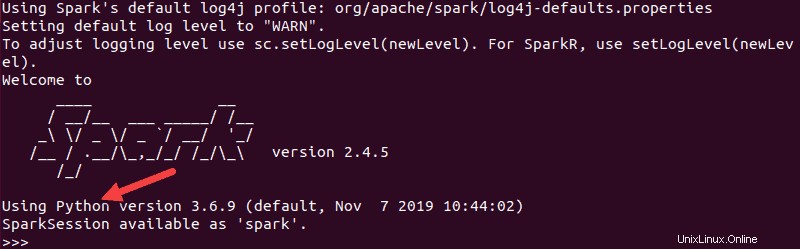
Um diese Shell zu verlassen, geben Sie quit() ein und drücken Sie Enter .
Grundlegende Befehle zum Starten und Stoppen von Master-Server und Workern
Nachfolgend finden Sie die grundlegenden Befehle zum Starten und Stoppen des Apache Spark-Masterservers und der Worker. Da dieses Setup nur für einen Computer gilt, verwenden die von Ihnen ausgeführten Skripts standardmäßig den localhost.
Zu Beginn ein Meister Server Instanz auf dem aktuellen Computer führen Sie den Befehl aus, den wir zuvor in der Anleitung verwendet haben:
start-master.shUm den Meister zu stoppen Instanz, die durch Ausführen des obigen Skripts gestartet wurde, führen Sie Folgendes aus:
stop-master.shUm einen laufenden Worker zu stoppen geben Sie diesen Befehl ein:
stop-slave.shDie Spark-Masterseite zeigt in diesem Fall den Worker-Status als DEAD an.

Sie können sowohl Master als auch Server starten Instanzen mit dem Befehl start-all:
start-all.shEbenso können Sie alle Instanzen stoppen indem Sie den folgenden Befehl verwenden:
stop-all.sh