Einführung
NoSQL (kurz für „Not Only SQL“) ist eine Alternative zu herkömmlichen Datenbanken, die sich auf die Erfassung und Verarbeitung großer Datenmengen konzentriert.
Es gibt mehrere Arten von NoSQL-Datenbanken, jede mit einem einzigartigen Ansatz zur Datenmodellierung und unterschiedlichen Anwendungsfällen.
In diesem Tutorial geben wir einen kurzen Überblick über mehrere NoSQL-Datenbanktypen und listen einige der beliebtesten Beispiele für jeden auf.

NoSQL-Datenbanktypen
Die vier beliebtesten Arten von NoSQL-Datenbanken sind Schlüsselwertdatenbanken, dokumentbasierte Datenbanken, graphbasierte Datenbanken und breite spaltenbasierte Datenbanken:
Schlüsselwertdatenbanken
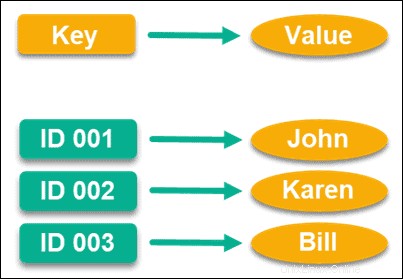
Schlüsselwertdatenbanken Organisieren Sie Daten in Paaren von Schlüsseln und Werten, wobei jeder Schlüssel an ein bestimmtes Objekt gebunden ist, das ein Datenfeld darstellt. Wenn Sie einen Schlüssel angeben, können Sie die Daten anzeigen, die in dem Objekt gespeichert sind, mit dem er gekoppelt ist.
Dies ist die einfachste und am besten skalierbare Art von NoSQL-Datenbank, die Flexibilität und verbesserte Leistung bietet.
Dokumentbasierte NoSQL-Datenbanken
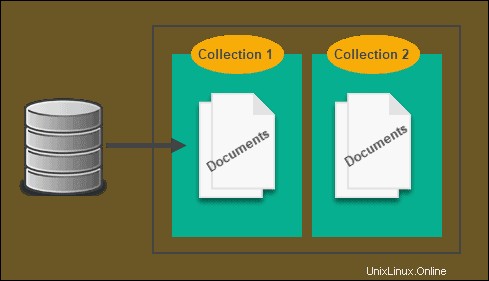
Dokumentenbasierte Datenbanken verwenden auch Schlüssel-Wert-Paare, die sie in Dokumenten speichern. Diese Dokumente werden basierend auf ihrem Inhalt und ihrer Verwendung weiter in Sammlungen gruppiert.
Diese Datenbanken speichern Daten am häufigsten als JSON-, XML-, BSON- oder YAML-Formulare, normalerweise ohne ein Schema zu implementieren. Durch diesen Ansatz eignen sie sich für Fälle, die eine flexible Struktur und die Fähigkeit zum schnellen Hinzufügen und Abrufen von Daten erfordern.
Graphbasierte Datenbanken
Graphbasierte Datenbanken stellen Daten als eine Sammlung von Knoten dar (Datenelemente), die durch Kanten verbunden sind . In dieser Datenstruktur enthalten Knoten Daten, während Kanten Beziehungen zwischen ihnen definieren.
Dieser Datenbanktyp wird häufig verwendet, um Beziehungen zwischen verschiedenen Dateneinträgen darzustellen, z. B. Freundschaftsverbindungen in sozialen Netzwerken. Benutzer können komplexe Abfragen durchführen und mehrere Daten gleichzeitig abrufen.
Breite spaltenbasierte Datenbanken
Breite spaltenbasierte Datenbanken Speichern Sie Daten in separaten Spalten, ähnlich wie Daten in Tabellen mit relationalen Datenbanken gespeichert werden. Im Gegensatz zu relationalen Datenbanken verwenden Wide-Column-Datenbanken keine vordefinierten Schlüssel oder Spaltennamen.
Dies ermöglicht Variationen der Spaltennamen, sogar innerhalb derselben Tabelle. Es ist auch einfach, große Datenmengen als neue Spalten hinzuzufügen oder vorhandene in Spaltenfamilien zu gruppieren.
Objektdatenbanken
Objektdatenbanken Speichern Sie Datenelemente als Objekte, die in der objektorientierten Programmierung verwendet werden. Sie sind so konzipiert, dass sie mit Programmiersprachen wie Python, Ruby, Delphi, Java usw. funktionieren.
Grid- und Cloud-Datenbanken
Grid- und Cloud-Datenbanken Verwenden Sie ein Datengrid - ein Netzwerk von Systemen, die mit Daten arbeiten, auf die über die Cloud zugegriffen werden kann.
Dieser Datenbanktyp funktioniert sowohl mit SQL- als auch mit NoSQL-Datenmodellen und wird normalerweise als Database-as-a-Service angeboten.
Datenbanken mit mehreren Modellen
Schließlich Datenbanken mit mehreren Modellen Kombinieren Sie die Funktionen von zwei oder mehr verschiedenen Datenbanktypen. Dadurch können sie eine Lösung für einzigartige Anwendungsfälle bereitstellen, in denen andere Datenbanktypen nicht geeignet sind.
Liste der NoSQL-Datenbanken
Nachfolgend finden Sie eine Liste der NoSQL-Datenbanken für 2021, die nach Datenbanktyp in Abschnitte unterteilt sind:
Liste der Schlüsselwertdatenbanken
Redis

Redis fungiert als Datenstrukturserver, der Daten im Arbeitsspeicher speichert. Das bedeutet, dass Redis Daten aus dem Hauptspeicher liest und modifiziert, aber auch über eine eingebaute Persistenz verfügt. Diese Funktion ermöglicht das Speichern von Daten auf der Festplatte, damit sie bei einem Neustart des Systems rekonstruiert werden können.
Vorteile der Verwendung von Redis:
- Das Arbeiten im Arbeitsspeicher ermöglicht eine hohe Leistung und Flexibilität.
- Unterstützung für viele verschiedene Datentypen und Programmiersprachen.
- Einfach zu skalieren und unterstützt die automatische Partitionierung.
Aerospike

Wie Redis ist Aerospike eine Open-Source-In-Memory-NoSQL-Datenbank. Aerospike ist dank seiner hohen Leistung und der Fähigkeit, Transaktionsdaten mit Analysen zu kombinieren, für den Einsatz im Online-Einzelhandel optimiert.
Vorteile der Verwendung von Aerospike:
- Zuverlässige Leistung mit sehr geringer Latenz.
- Ein gutes Verhältnis von Preis und Leistung macht es für kleinere Unternehmen geeignet.
Ria

Riak speichert Schlüssel-Wert-Paare in Datenobjekten, die es „Buckets“ nennt. Es unterstützt eine breite Palette von Datenformaten und betont Datenstabilität und vorhersagbare Leistung.
Vorteile der Verwendung von Riak:
- Schlüssel-Wert-Paare werden in Clustern von drei Knoten gespeichert, mit der Option, die Daten zur Sicherung auf zusätzliche Knoten zu replizieren.
- Daten können im Arbeitsspeicher, auf Festplatten oder beidem gespeichert werden.
- Multi-Rechenzentrum-Replikation ermöglicht die Sicherung Ihrer Daten in Rechenzentren an verschiedenen Standorten.
Projekt Voldemort
LinkedIn verwendet Project Voldemort als Lösung für hochskalierbare Key-Value-Speicherung. Es funktioniert als verteilte, fehlertolerante und persistente Hash-Tabelle.
Vorteile der Verwendung von Project Voldemort:
- Daten werden automatisch repliziert und auf mehrere Server verteilt.
- Speicher- und Serialisierungs-Plugins sind verfügbar.
- Gute Einzelknotenleistung.
Liste für dokumentenbasierte NoSQL-Datenbanken
MongoDB

MongoDB ist eine agile Open-Source-Datenbank, die von einer Vielzahl von Unternehmen in verschiedenen Branchen eingesetzt wird. Es speichert Dokumente als JSON-Objekte, die Schemata schnell an Ihre Bedürfnisse anpassen können.
Vorteile der Verwendung von MongoDB:
- Einfache Skalierung von einem einzelnen Server bis hin zu komplexen Systemen.
- Sorgt konstant für hohe Leistung.
- Hohe Zuverlässigkeit dank Replikation und Lastenausgleich.
Couchbase-Server

Couchbase Server (ursprünglich bekannt als Membase) ist eine verteilte Open-Source-Datenbanklösung. Die primäre Designabsicht besteht darin, mit interaktiven Anwendungen zu arbeiten, um große Mengen an Benutzerdaten als JSON-Objekte zu speichern.
Vorteile der Verwendung von Couchbase Server:
- Cluster-Management ermöglicht eine schnelle Skalierung.
- Anpassbare Replikation, sogar zwischen Rechenzentren.
CouchDB

CouchDB ist eine in Erlang geschriebene Open-Source-Datenbank. Es bietet Funktionen wie Multi-Version-Concurrency-Control (unter Verwendung von ACID-Semantik), Multi-Master-Replikation und Map/Reduce.
Vorteile der Nutzung von CouchDB:
- Können Daten für den Offline-Zugriff auf Geräte wie Smartphones replizieren.
- Garantiert eventuelle Konsistenz, Bereitstellung von Verfügbarkeit und Partitionstoleranz.
Elasticsearch

Elasticsearch ist eine verteilte Datenbank, die als Suchmaschine fungiert und Volltextsuche mit Fuzzy-Matching durchführen kann. Es fällt unter die doppelte Lizenzierung:Einige Teile werden von der Server Side Public License abgedeckt, während andere in die Kategorie der proprietären Elastic License fallen.
Vorteile der Verwendung von Elasticsearch:
- Sie können die Funktionen erweitern, indem Sie Elasticsearch mit anderen Lösungen wie Logstash (Datenerfassung und Protokollanalyse), Kibana (Analyse) und Beats (Datenversand) kombinieren.
- Skalierbare Echtzeitsuche mit Facettierung und Perkolation.
Liste für graphbasierte Datenbanken
Neo4J

Neo4J ist eine graphenbasierte Open-Source-Datenbank, die in Java erstellt wurde, mit zusätzlichen Funktionen, die als Teil ihrer Graph Data Platform verfügbar sind. Es verwendet die Cypher-Abfragesprache Zugriff auf eine breitere Palette von Abfragen als andere Datenbanktypen zu bieten und gleichzeitig eine hohe Leistung beizubehalten.
Vorteile der Verwendung von Neo4J:
- Nützlich zum Lösen von Problemen, die eine wiederholte Netzwerkprüfung erfordern.
- Erleichtert die Analyse von Datenobjekten und deren Beziehungen.
OrientDB

OrientDB ist ein Open-Source-Multimodell-Datenbanksystem mit starkem Schwerpunkt auf dem Graph-Datenbankmodell. Es kann auf jedem Betriebssystem bereitgestellt werden und bietet eine Vielzahl von Funktionen, die durch ein Upgrade auf die Enterprise Edition weiter ausgebaut werden können.
Vorteile der Verwendung von OrientDB:
- Ein starkes Sicherheitssystem basierend auf Benutzern und Rollen.
- Einfacher Einstieg mit einem kostenlosen Udemy-Kurs, umfassender Benutzersupport durch Stack Overflow.
- Einfacher Import anderer relationaler Datenbanken in OrientDB.
RedisGraph

RedisGraph ist ein Graph-Datenbankmodul für Redis. Es basiert auf dem Property Graph-Modell und verwendet die Cypher-Abfragesprache Abfragen in Ausdrücke der linearen Algebra zu übersetzen.
Vorteile der Verwendung von RedisGraph:
- Einfach mit bestehenden Redis-Datenbanken zu kombinieren.
- Erlaubt das Hinzufügen von Knotenbezeichnungen und Beziehungstypen.
InfiniteGraph

InfiniteGraph ist eine verteilte Datenbank, die sich auf die Durchführung komplexer Objektabfragen konzentriert. Es wird verwendet, um Web- oder mobile Anwendungen zu entwickeln, die Diagrammprobleme lösen, die mit komplexen großen Datensätzen arbeiten.
Vorteile der Verwendung von InfiniteGraph:
- Können komplexe oder parallele Abfragen verarbeiten, die eine hohe Leistung erfordern.
- Backup mit flexibler Konsistenz (von ACID bis Relaxed).
Liste für breite spaltenbasierte Datenbanken
Kassandra

Apache Cassandra ist eine kostenlose Open-Source-Datenbanklösung, die entwickelt wurde, um große Datenlasten mit minimaler Auswirkung auf die Leistung zu bewältigen. Twitter, Netflix und Reddit verwenden alle Cassandra aufgrund seiner hohen Geschwindigkeit und Verfügbarkeit.
Vorteile der Verwendung von Cassandra:
- Asynchrone, masterlose Replikation gewährleistet Schutz vor Datenverlust, ohne Latenz zu verursachen.
- Skaliert problemlos über mehrere Rechenzentren ohne Ausfallzeiten.
Cosmos DB

Microsofts Azure Cosmos DB ist eine proprietäre Datenbanklösung. Das Produkt wurde für den weltweiten Vertrieb entwickelt, um die Verwaltung großer, horizontal skalierbarer Datenbanken zu unterstützen.
Vorteile der Verwendung von Cosmos DB:
- Kombiniert mit anderen Microsoft Azure-Diensten für erweiterte Funktionen.
- Automatische Partitionierung über mehrere Rechenzentren.
HBase

HBase wurde entwickelt, um mit extrem großen Datenbanken mit Milliarden von Zeilen und Millionen von Spalten zu arbeiten. Es läuft auf dem Hadoop Distributed File System (HDFS) und ermöglicht es Hadoop, wie Bigtable von Google zu arbeiten.
Vorteile der Verwendung von HBase:
- Ermöglicht einen großen Durchsatz im Petabyte-Bereich von Daten.
- Ermöglicht zufälligen Echtzeit-Lese-/Schreibzugriff auf Ihre Datenbank.
Akkumulo

Apache Accumulo ist eine weitere Lösung, die auf Hadoop basiert und auf Bigtable von Google basiert. Es verbessert das Bigtable-Design durch Hinzufügen von Funktionen wie zellbasiert Zugriffskontrolle und serverseitige Programmierung.
Vorteile der Nutzung von Accumulo:
- Sie können Sicherheitsetiketten auf Zellenebene hinzufügen und Daten verschiedener Sicherheitsstufen in derselben Tabelle speichern.
Liste der Objektdatenbanken
ObjektDB
ObjectDB ist eine Objektdatenbanklösung für die Java-Entwicklung mit integrierter Unterstützung für Java-APIs. Es funktioniert im Client-Server- oder eingebetteten Modus.
Vorteile der Arbeit mit ObjectDB:
- Unterstützt verschiedene Plattformen und Betriebssysteme.
- Verwendet sowohl JDO- als auch JPA-Abfragesprachen.
Ninja Database Pro
Ninja Database Pro verfügt über einen hohen Automatisierungsgrad, der die Verwendung für Anfänger erleichtert. Es bietet eine robuste und schnelle Möglichkeit, Datenobjekte in einer Datenbank zu verwalten.
Vorteile der Verwendung von Ninja Database Pro:
- Kann mit komplexen Datenobjekten wie doppelt verknüpften Listen, mehrdimensionalen Arrays und Wörterbüchern arbeiten.
- ACID-konform, mit integrierter AES-Verschlüsselung.
NeoDB
NeoDB strukturiert Daten als Netzwerk von Objekten, die einem großen Baum ähneln. Dieses Netzwerk wird Knotenraum genannt und konzentriert sich auf Knoten (Objekte), ihre Beziehungen und ihre Eigenschaften.
Vorteile der Verwendung von NeoBD:
- Gut für den Umgang mit halbstrukturierten Daten, mit wenigen obligatorischen, aber vielen optionalen Attributen.
Objektivität/DB

Objectivity/DB ist eine verteilte Datenbank, die es Ihnen ermöglicht, mit Datenobjekten in C++, C#, Java oder Python zu arbeiten, ohne sie in Tabellen umzuwandeln.
Vorteile der Verwendung von Objectivity/DB:
- Verwendet jede unterstützte Programmiersprache auf dem Betriebssystem Ihrer Wahl.
- Seine Architektur macht es zu einer guten Wahl für Grid-Computing-Umgebungen.
Liste der Cloud- und Grid-Datenbanken
Oracle Coherence
Oracle Coherence ist ein auf Java basierendes verteiltes Cache- und In-Memory-Datengrid. Es verwaltet Daten in geclusterten Anwendungen, sodass die Datenbank nicht jedes Mal direkt abgefragt werden muss, wenn Sie Daten verwalten müssen.
Vorteile der Verwendung von Oracle Coherence:
- Bietet hohe Verfügbarkeit, Skalierbarkeit und geringe Latenz.
Infinispan

Infinispan ist eine in Java geschriebene Open-Source-Datengrid-Lösung. Infinispan kann als Bibliothek in Java-Anwendungen eingebettet werden, und Nicht-Java-Anwendungen können es mit TCP/IP verwenden.
Vorteile der Verwendung von Infinispan:
- Hochgradig skalierbar bei gleichbleibender Verfügbarkeit.
- Seine austauschbare Architektur ermöglicht es, Daten im Dateisystem oder anderen Datenbankmanagern zu speichern.
Hazelcast
Hazelcast ist ein Open-Source-Datengrid. Es basiert auf Java und kann lokal, virtuell, in der Cloud oder in Docker-Containern ausgeführt werden.
Vorteile der Verwendung von Hazelcast:
- Ermöglicht die horizontale Skalierung von Speicher- und Verarbeitungsleistung.
Liste der Multi-Model-Datenbanken
ArangoDB

ArangoDB ist ein kostenloser Open-Source-Datenbankmanager, der Schlüsselwert-, Dokument- und Diagrammdatenbankmodelle unterstützt.
Vorteile der Verwendung von ArangoDB:
- Mit der AQL-Abfragesprache können Sie mit einer einzigen Abfrage auf verschiedene Datenbanktypen abzielen.
- Funktioniert als verteilter Cluster mit der Cluster-Bereitstellungsoption mit einem Klick.