Einführung
Bei so vielen verfügbaren Optionen kann es schwierig sein, eine Datenbanklösung auszuwählen, die perfekt zu Ihren Anforderungen passt. Wenn es um Datenbanktypen geht, ist eine relationale Datenbank eine beliebte Option.
In diesem Artikel behandeln wir die Struktur relationaler Datenbanken, ihre Funktionsweise und die Vor- und Nachteile ihrer Verwendung. Wir werden auch Beispiele verwenden, um zu veranschaulichen, wie relationale Datenbanken Daten organisieren.

Relationale Datenbankdefinition
Eine relationale Datenbank ist eine Art Datenbank, die sich auf die Beziehung zwischen gespeicherten Datenelementen konzentriert. Es ermöglicht Benutzern, Verknüpfungen zwischen verschiedenen Datensätzen innerhalb der Datenbank herzustellen und diese Verknüpfungen zu verwenden, um verwandte Daten zu verwalten und zu referenzieren.
Viele relationale Datenbanken verwenden SQL (Structured Query Language), um Abfragen durchzuführen und Daten zu pflegen.
Relationale vs. nicht relationale Datenbanken
Relationale Datenbanken konzentrieren sich auf Beziehungen zwischen Daten. Daher muss die Beziehungsdatenbank Daten auf hochstrukturierte Weise speichern. Dies ermöglicht schnellere Indizierungs- und Abfrageantwortzeiten und macht die Daten sicherer und konsistenter.
Andererseits müssen sich NoSQL-Datenbanken nicht so sehr auf die Struktur verlassen, was es ihnen ermöglicht, große Datenmengen zu speichern, flexibel zu bleiben und Speicher und Leistung einfach zu skalieren.
Wie werden Daten in einem relationalen Datenbanksystem organisiert?
Relationale Datenbanksysteme verwenden ein Modell, das Daten in Tabellen organisiert von Zeilen (auch genannt Aufzeichnungen oder Tupel ) und Spalten (auch Attribute genannt oder Felder ). Im Allgemeinen stellen Spalten Datenkategorien dar, während Zeilen einzelne Instanzen darstellen.
Nehmen wir als Beispiel ein digitales Schaufenster. Unsere Datenbank enthält möglicherweise eine Tabelle mit Kundeninformationen, deren Spalten Kundennamen oder -adressen darstellen, während jede Zeile Daten für einen einzelnen Kunden enthält.

Diese Tabellen können mit Schlüsseln verknüpft oder verknüpft werden . Jede Zeile in einer Tabelle wird mit einem eindeutigen Schlüssel identifiziert, der als Primärschlüssel bezeichnet wird Dieser Primärschlüssel kann zu einer anderen Tabelle hinzugefügt werden und wird zu einem Fremdschlüssel. Die Primär-/Fremdschlüsselbeziehung bildet die Grundlage für die Funktionsweise relationaler Datenbanken.
Zurück zu unserem Beispiel:Wenn wir eine Tabelle haben, die Produktbestellungen darstellt, könnte eine der Spalten Kundeninformationen enthalten. Hier können wir einen Primärschlüssel importieren, der mit einer Zeile mit den Informationen für einen bestimmten Kunden verknüpft ist.
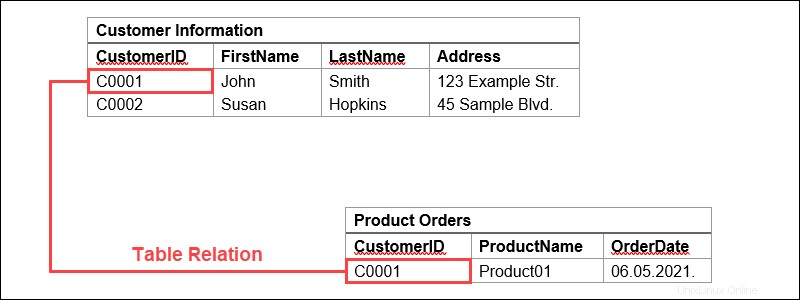
Auf diese Weise können wir auf die Daten verweisen oder Daten aus der Kundeninformationstabelle duplizieren. Das bedeutet auch, dass diese beiden Tabellen jetzt miteinander verbunden sind.
Beispiele für relationale Datenbanken
Nachdem wir nun ihre Funktionsweise behandelt haben, sind hier einige der beliebtesten Beispiele relationaler Datenbanken:
MySQL

MySQL wurde als Open-Source-Verwaltungssystem für relationale Datenbanken entwickelt, bis es von Sun Microsystems (jetzt Oracle Corporation) übernommen wurde. Es ist weiterhin unter einer Open-Source-Lizenz verfügbar, mit dem Zusatz verschiedener proprietärer Lizenzen.
MySQL bietet integrierte Replikationsunterstützung mit ACID-Konformität, Shared-Nothing-Clustering und unterstützt mehrere Speicher-Engines. Die Verwendung einiger Speicher-Engines kann jedoch dazu führen, dass SQL nicht richtig funktioniert.
MySQL zeichnet sich durch schnelle Dateneingabe und Skalierbarkeit bei gleichzeitig hoher Verfügbarkeit und Leistung aus. Dies macht es äußerst nützlich für die Web- und Anwendungsentwicklung.
PostgreSQL

PostgreSQL ist ein kostenloser relationaler Datenbankmanager, der unter einer Open-Source-Lizenz verfügbar ist. Es teilt einige Funktionen mit MySQL, mit der bemerkenswerten Hinzufügung von MVCC (Multi-Version Concurrency Control), wodurch es ACID-kompatibel wird.
PostgreSQL behält ein hohes Maß an Leistung und Flexibilität, selbst beim Umgang mit großen Datenbanken. Es ist die richtige Wahl für Benutzer, die hohe Lese-/Schreibgeschwindigkeiten und umfangreiche Datenanalysen benötigen.
Einige bemerkenswerte Benutzer von PostgreSQL sind Reddit, Skype und Instagram.
MariaDB

MariaDB begann als Community-gesteuerter Fork von MySQL, nachdem letzteres von Oracle gekauft wurde. Es ist immer noch Open Source und steht unter der GNU General Public License.
MariaDB baut auf der MySQL-Basis auf, indem es Unterstützung für noch mehr Speicher-Engines hinzufügt und Speicher-Engine-Einschränkungen behebt. Dadurch kann es sogar noch schneller als MySQL arbeiten und sowohl SQL als auch NoSQL in einer einzigen Datenbank ausführen.
Zu den bemerkenswerten MariaDB-Benutzern gehören Google, Mozilla und die Wikimedia Foundation.
SQLite

Im Gegensatz zu anderen Einträgen in dieser Liste ist SQLite kein Client-Server-Datenbankmanager, sondern in die Endanwendung eingebettet. Dadurch ist es leicht und in der Lage, mit einer Vielzahl von Systemen und Plattformen zu arbeiten.
Es verursacht auch einige Einschränkungen, da SQLite Trigger nur teilweise bereitstellt und eine begrenzte ALTER TABLE hat funktionieren und können nicht in Ansichten schreiben. Es begrenzt auch die maximale Größe der Datenbank auf 32.000 Spalten und 140 TB.
SQLite wird daher am besten als Datenbankkomponente für andere Anwendungen verwendet. Zu den nennenswerten Verwendungszwecken gehören beliebte Browser wie Google Chrome, Mozilla Firefox, Opera und Safari.
Was ist ein relationales Datenbankverwaltungssystem?
Ein Datenbankverwaltungssystem (DBMS) ist eine Softwarelösung, mit der Benutzer Datenbanken anzeigen, abfragen und verwalten können.
Relationale Datenbankverwaltungssysteme (RDBMS) sind eine fortgeschrittenere Untergruppe von DBMS, die mit relationalen Datenbanken umgehen.
DBMS vs. RDBMS
Hier sind einige der Unterschiede zwischen allgemeineren DBMS-Lösungen und RDBMS:
| DBMS | RDBMS |
| Speichert kleinere Datenmengen als Dateien ohne Beziehungen. | Speichert große Datenmengen als Tabellen, die miteinander in Beziehung stehen. |
| Kann nur auf ein Datenelement gleichzeitig zugreifen. | Kann auf mehrere Datenelemente gleichzeitig zugreifen. |
| Das Arbeiten mit großen Datenmengen verlangsamt das Abrufen. | Der relationale Ansatz ermöglicht einen schnellen Datenabruf auch bei großen Datenbanken. |
| Keine Datenbanknormalisierung. | Erlaubt Datenbanknormalisierung. |
| Unterstützt keine verteilten Datenbanken. | Unterstützt verteilte Datenbanken. |
| Unterstützt einen einzelnen Benutzer. | Unterstützt mehrere Benutzer. |
| Niedrigere Sicherheitsstufe. | Mehrere Sicherheitsstufen. |
| Geringe Software- und Hardwareanforderungen. | Hohe Software- und Hardwareanforderungen. |
Vor- und Nachteile relationaler Datenbanken
Wie bei jedem anderen Datenbankmodell gibt es Vor- und Nachteile bei der Verwendung relationaler Datenbanken:
Vorteile
Da relationale Datenbanken Tabellen mit Zeilen und Spalten verwenden, zeigen sie Daten einfacher als einige andere Datenbanktypen an, wodurch sie einfacher zu verwenden sind.
Diese tabellarische Struktur verlagert den Fokus auf die Handhabung von Daten, was eine schnellere Leistung und die Verwendung komplexer Abfragen auf hoher Ebene ermöglicht.
Schließlich machen es relationale Datenbanken einfach, Daten zu skalieren, indem einfach Zeilen, Spalten oder ganze Tabellen hinzugefügt werden, ohne die gesamte Datenbankstruktur zu ändern.
Nachteile
Der Skalierung relationaler Datenbanken sind Grenzen gesetzt. In Bezug auf die schiere Größe haben einige Datenbanken feste Grenzen für die Spaltenlänge. Wenn Ihre Datenbank auf einem einzigen dedizierten Server aufgebaut ist, erfordert die Skalierung den Kauf von mehr Serverplatz, was sich auf lange Sicht als teuer erweist.
Außerdem kann das ständige Hinzufügen neuer Elemente zu einer Datenbank diese so komplex machen, dass es schwierig wird, Beziehungen zwischen neuen Datenelementen herzustellen. Komplizierte Datenbeziehungen verlangsamen außerdem Abfragen und wirken sich negativ auf die Leistung aus.