Einführung
Die phoenixNAP Bare Metal Cloud stellt eine RESTful-API-Schnittstelle bereit, mit der Entwickler die Erstellung von Bare-Metal-Servern automatisieren können.
Um die Fähigkeiten des Systems zu demonstrieren, werden in diesem Artikel Python-Codebeispiele erläutert und bereitgestellt, wie die BMC-API genutzt werden kann, um die Bereitstellung eines Spark-Clusters in der Bare Metal Cloud zu automatisieren .

Voraussetzungen
- phoenixNAP Bare Metal Cloud-Konto
- Ein OAuth-Zugriffstoken
So automatisieren Sie die Bereitstellung von Spark-Clustern
Die folgenden Anweisungen gelten für die Bare-Metal-Cloud-Umgebung von phoenixNAP. Die Python-Codebeispiele in diesem Artikel funktionieren möglicherweise nicht in anderen Umgebungen.
Die Schritte, die zum Bereitstellen und Zugreifen auf den Apache Spark-Cluster erforderlich sind:
1. Generieren Sie ein Zugriffstoken.
2. Erstellen Sie Bare-Metal-Cloud-Server, auf denen Ubuntu OS ausgeführt wird.
3. Stellen Sie einen Apache Spark-Cluster auf den erstellten Serverinstanzen bereit.
4. Greifen Sie auf das Apache Spark-Dashboard zu, indem Sie dem generierten Link folgen.
Der Artikel hebt eine Teilmenge von Python-Codesegmenten hervor, die die Bare-Metal-Cloud-API und Shell-Befehle nutzen, um die oben beschriebenen Schritte auszuführen.
Schritt 1:Zugriffstoken abrufen
Bevor Sie Anforderungen an die BMC-API senden, müssen Sie mithilfe der client_id ein OAuth-Zugriffstoken abrufen und client_secret im BMC-Portal registriert.
Weitere Informationen zur Registrierung für client_id und client_secret finden Sie in der Bare-Metal-Cloud-API-Schnellstartanleitung.
Unten ist die Python-Funktion, die das Zugriffstoken für die API generiert:
def get_access_token(client_id: str, client_secret: str) -> str:
"""Retrieves an access token from BMC auth by using the client ID and the
client Secret."""
credentials = "%s:%s" % (client_id, client_secret)
basic_auth = standard_b64encode(credentials.encode("utf-8"))
response = requests.post(' https://api.phoenixnap.com/bmc/v0/servers',
headers={
'Content-Type': 'application/x-www-form-urlencoded',
'Authorization': 'Basic %s' % basic_auth.decode("utf-8")},
data={'grant_type': 'client_credentials'})
if response.status_code != 200:
raise Exception('Error: {}. {}'.format(response.status_code, response.json()))
return response.json()['access_token']
Schritt 2:Bare-Metal-Serverinstanzen erstellen
Verwenden Sie die REST-API-Aufrufe von POST/servers, um Bare-Metal-Serverinstanzen zu erstellen. Geben Sie für jede POST/Server-Anfrage die erforderlichen Parameter an, z. B. Rechenzentrumsstandort, Servertyp, Betriebssystem usw.
Unten ist die Python-Funktion, die die BMC-API aufruft, um einen Bare-Metal-Server zu erstellen.
def __do_create_server(session, server):
response = session.post('https://api.phoenixnap.com/bmc/v0/servers'),
data=json.dumps(server))
if response.status_code != 200:
print("Error creating server: {}".format(json.dumps(response.json())))
else:
print("{}".format(json.dumps(response.json())))
return response.json()
In diesem Beispiel werden drei Bare-Metal-Server vom Typ „s1.c1.small“ erstellt, wie in der Datei „server-settings.conf“ angegeben.
{
"ssh-key" : "ssh-rsa xxxxxx== username",
"servers_quantity" : 3,
"type" : "s1.c1.small",
"hostname" : "spark",
"description" : "spark",
"public" : True,
"location" : "PHX",
"os" : "ubuntu/bionic"
}
Die erwartete Ausgabe des Python-Skripts, das das Token generiert und die Server bereitstellt, lautet wie folgt:
Retrieving token
Successfully retrieved API token
Creating servers...
{
"id": "5ee9c1b84a9ca71ea6b9b766",
"status": "creating",
"hostname": "spark-1",
"description": "spark-1",
"os": "ubuntu/bionic",
"type": "s1.c1. small ",
"location": "PHX",
"cpu": "E-2276G",
"ram": "128GB RAM",
"storage": "2x 960GB NVMe",
"privateIpAddresses": [
"10.0.0.11"
],
"publicIpAddresses": [
"131.153.143.250",
"131.153.143.251",
"131.153.143.252",
"131.153.143.253",
"131.153.143.254"
]
}
Server created, provisioning spark-1...
{
"id": "5ee9c1b84a9ca71ea6b9b767",
"status": "creating",
"hostname": "spark-0",
"description": "spark-0",
"os": "ubuntu/bionic",
"type": "s1.c1.small",
"location": "PHX",
"cpu": "E-2276G",
"ram": "128GB RAM",
"storage": "2x 960GB NVMe",
"privateIpAddresses": [
"10.0.0.12"
],
"publicIpAddresses": [
"131.153.143.50",
"131.153.143.51",
"131.153.143.52",
"131.153.143.53",
"131.153.143.54"
]
}
Server created, provisioning spark-0...
{
"id": "5ee9c1b84a9ca71ea6b9b768",
"status": "creating",
"hostname": "spark-2",
"description": "spark-2",
"os": "ubuntu/bionic",
"type": "s1.c1. small ",
"location": "PHX",
"cpu": "E-2276G",
"ram": "128GB RAM",
"storage": "2x 960GB NVMe",
"privateIpAddresses": [
"10.0.0.13"
],
"publicIpAddresses": [
"131.153.142.234",
"131.153.142.235",
"131.153.142.236",
"131.153.142.237",
"131.153.142.238"
]
}
Server created, provisioning spark-2...
Waiting for servers to be provisioned... Nachdem die drei Bare-Metal-Server erstellt wurden, kommuniziert das Skript mit der BMC-API, um den Serverstatus zu prüfen, bis die Bereitstellung abgeschlossen und die Server eingeschaltet sind.
Schritt 3:Apache Spark-Cluster bereitstellen
Sobald die Server bereitgestellt sind, stellt das Python-Skript eine SSH-Verbindung unter Verwendung der öffentlichen IP-Adresse der Server her. Als nächstes installiert das Skript Spark auf den Ubuntu-Servern. Dazu gehört die Installation von JDK , Scala , Git und Spark auf allen Servern.
Um den Prozess zu starten, führen Sie all_hosts.sh aus Datei auf allen Servern. Das Skript bietet Download- und Installationsanweisungen sowie die erforderliche Umgebungskonfiguration, um den Cluster für die Verwendung vorzubereiten.
Apache Spark enthält Skripte, die die Server als Master- und Worker-Knoten konfigurieren. Die einzige Einschränkung bei der Konfiguration eines Worker-Knotens besteht darin, dass der Master-Knoten bereits konfiguriert ist. Der erste bereitzustellende Server wird als Spark-Master-Knoten zugewiesen.
Die folgende Python-Funktion führt diese Aufgabe aus:
def wait_server_ready(function_scheduler, server_data):
json_server = bmc_api.get_server(REQUEST, server_data['id'])
if json_server['status'] == "creating":
main_scheduler.enter(2, 1, wait_server_ready, (function_scheduler, server_data))
elif json_server['status'] == "powered-on" and not data['has_a_master_server']:
server_data['status'] = json_server['status']
server_data['master'] = True
server_data['joined'] = True
data['has_a_master_server'] = True
data['master_ip'] = json_server['publicIpAddresses'][0]
data['master_hostname'] = json_server['hostname']
print("ASSIGNED MASTER SERVER: {}".format(data['master_hostname']))Führen Sie die master_host.sh aus Datei, um den ersten Server als Master-Knoten zu konfigurieren. Siehe unten den Inhalt der master_host.sh Datei:
#!/bin/bash
echo "Setting up master node"
/opt/spark/sbin/start-master.shSobald der Master-Knoten zugewiesen und konfiguriert ist, werden die anderen beiden Knoten zum Spark-Cluster hinzugefügt.
Siehe unten den Inhalt der worker_host.sh Datei:
#!/bin/bash
echo "Setting up master node on /etc/hosts"
echo "$1 $2 $2" | sudo tee -a /etc/hosts
echo "Starting worker node"
echo "Joining worker node to the cluster"
/opt/spark/sbin/start-slave.sh spark://$2:7077
Die Bereitstellung eines Apache Spark-Clusters ist abgeschlossen. Unten ist die erwartete Ausgabe des Python-Skripts:
ASSIGNED MASTER SERVER: spark-2
Running all_host.sh script on spark-2 (Public IP: 131.153.142.234)
Setting up /etc/hosts
Installing jdk, scala and git
Downloading spark-2.4.5
Unzipping spark-2.4.5
Setting up environment variables
Running master_host.sh script on spark-2 (Public IP: 131.153.142.234)
Setting up master node
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-ubuntu-org.apache.spark.deploy.master.Master-1-spark-2.out
Master host installed
Running all_host.sh script on spark-0 (Public IP: 131.153.143.170)
Setting up /etc/hosts
Installing jdk, scala and git
Downloading spark-2.4.5
Unzipping spark-2.4.5
Setting up environment variables
Running all_host.sh script on spark-1 (Public IP: 131.153.143.50)
Setting up /etc/hosts
Installing jdk, scala and git
Downloading spark-2.4.5
Unzipping spark-2.4.5
Setting up environment variables
Running slave_host.sh script on spark-0 (Public IP: 131.153.143.170)
Setting up master node on /etc/hosts
10.0.0.12 spark-2 spark-2
Starting worker node
Joining worker node to the cluster
starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-ubuntu-org.apache.spark.deploy.worker.Worker-1-spark-0.out
Running slave_host.sh script on spark-1 (Public IP: 131.153.143.50)
Setting up master node on /etc/hosts
10.0.0.12 spark-2 spark-2
Starting worker node
Joining worker node to the cluster
starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-ubuntu-org.apache.spark.deploy.worker.Worker-1-spark-1.out
Setup servers done
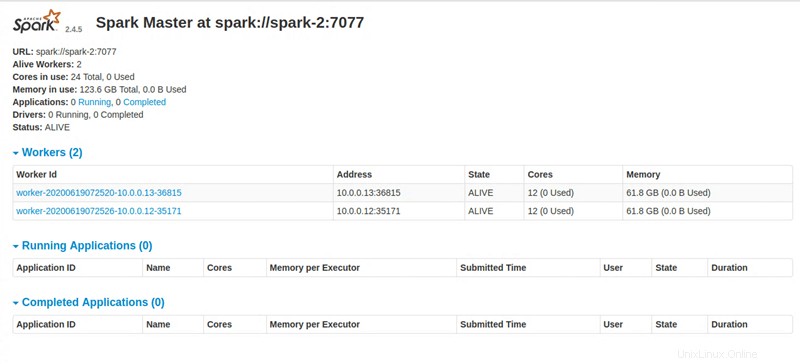
Master node UI: http://131.153.142.234:8080
Schritt 4:Greifen Sie auf das Apache Spark-Dashboard zu
Nach Ausführung aller Anweisungen stellt das Python-Skript einen Link zum Zugriff auf das Apache Spark-Dashboard bereit.