Einführung
Verteilte Datenbanken werden zur horizontalen Skalierung verwendet , und sie sind darauf ausgelegt, die Workload-Anforderungen zu erfüllen, ohne Änderungen an der Datenbankanwendung vornehmen oder einen einzelnen Computer vertikal skalieren zu müssen.
Verteilte Datenbanken lösen verschiedene Probleme , wie Verfügbarkeit, Fehlertoleranz, Durchsatz, Latenz, Skalierbarkeit und viele andere Probleme, die sich aus der Verwendung eines einzelnen Computers und einer einzelnen Datenbank ergeben können.
In diesem Artikel erfahren Sie, was verteilte Datenbanken sind und welche Vor- und Nachteile sie haben.

Verteilte Datenbankdefinition
Eine verteilte Datenbank stellt mehrere miteinander verbundene Datenbanken dar, die über mehrere Standorte verteilt sind, die durch ein Netzwerk verbunden sind. Da die Datenbanken alle miteinander verbunden sind, erscheinen sie den Benutzern als eine einzige Datenbank.
Verteilte Datenbanken verwenden mehrere Knoten. Sie skalieren horizontal und entwickeln ein verteiltes System. Mehr Knoten im System bieten mehr Rechenleistung, höhere Verfügbarkeit und lösen das Single-Point-of-Failure-Problem.
Verschiedene Teile der verteilten Datenbank werden an mehreren physischen Orten gespeichert , und die Verarbeitungsanforderungen werden auf Prozessoren auf mehreren Datenbankknoten verteilt.
Ein zentralisiertes verteiltes Datenbankverwaltungssystem (DDBMS ) verwaltet die verteilten Daten, als ob sie an einem physischen Ort gespeichert wären. DDBMS synchronisiert alle Datenoperationen zwischen Datenbanken und stellt sicher, dass die Aktualisierungen in einer Datenbank automatisch auf Datenbanken an anderen Standorten widergespiegelt werden.
Verteilte Datenbankfunktionen
Einige allgemeine Merkmale verteilter Datenbanken sind:
- Standortunabhängigkeit - Daten werden physisch an mehreren Standorten gespeichert und von einem unabhängigen DDBMS verwaltet.
- Verteilte Abfrageverarbeitung - Verteilte Datenbanken beantworten Abfragen in einer verteilten Umgebung, die Daten an mehreren Standorten verwaltet. Allgemeine Abfragen werden zur einfacheren Verwaltung in einen Abfrageausführungsplan umgewandelt.
- Verteiltes Transaktionsmanagement - Bietet eine konsistente verteilte Datenbank durch Commit-Protokolle, verteilte Parallelitätssteuerungstechniken und verteilte Wiederherstellungsmethoden im Falle vieler Transaktionen und Ausfälle.
- Nahtlose Integration - Datenbanken in einer Sammlung stellen normalerweise eine einzige logische Datenbank dar und sind miteinander verbunden.
- Netzwerkverknüpfung - Alle Datenbanken einer Sammlung sind durch ein Netzwerk verbunden und kommunizieren miteinander.
- Transaktionsverarbeitung - Verteilte Datenbanken beinhalten eine Transaktionsverarbeitung, die ein Programm ist, das eine Sammlung von einer oder mehreren Datenbankoperationen enthält. Die Transaktionsverarbeitung ist ein atomarer Prozess, der entweder vollständig oder gar nicht ausgeführt wird.
Verteilte Datenbanktypen
Es gibt zwei Arten von verteilten Datenbanken:
- Homogen
- Heterogen
Homogen
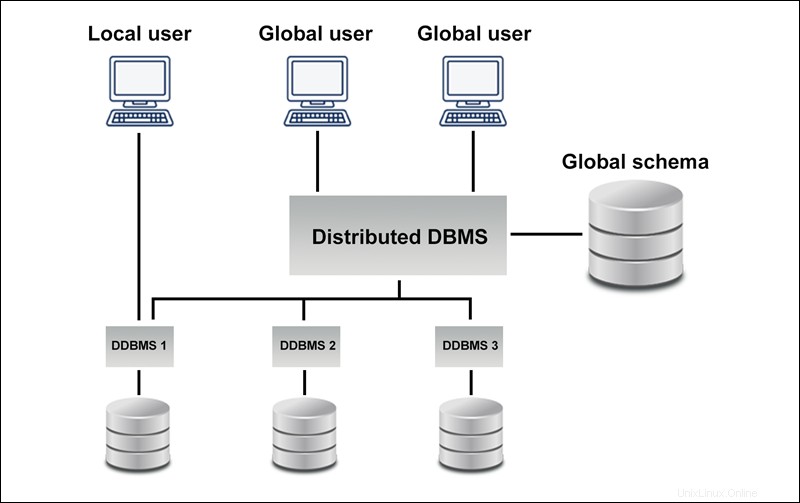
Eine homogen verteilte Datenbank ist ein Netzwerk identischer Datenbanken auf mehreren Seiten gespeichert. Die Sites haben dasselbe Betriebssystem, dasselbe DDBMS und dieselbe Datenstruktur, wodurch sie leicht zu verwalten sind.
Homogene Datenbanken ermöglichen Benutzern den nahtlosen Zugriff auf Daten aus jeder der Datenbanken.
Das folgende Diagramm zeigt ein Beispiel einer homogenen Datenbank:
Heterogen
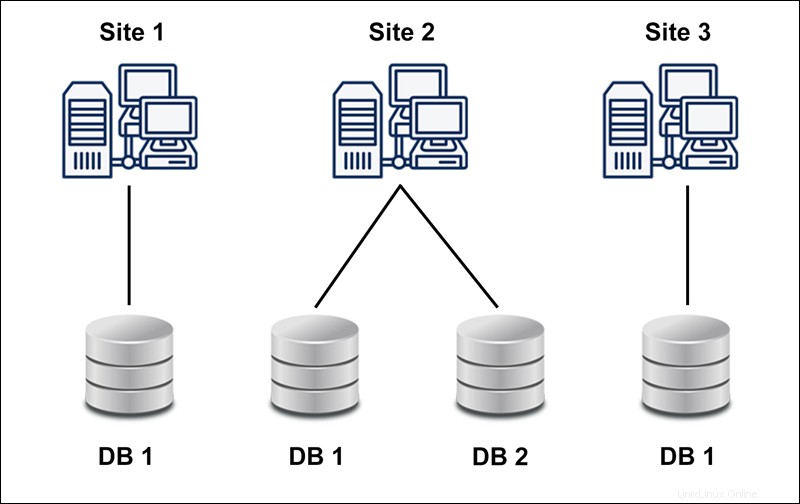
Eine heterogen verteilte Datenbank verwendet verschiedene Schemas, Betriebssysteme, DDBMS und verschiedene Datenmodelle.
Im Fall einer heterogenen verteilten Datenbank kann eine bestimmte Site andere Sites überhaupt nicht kennen, was zu einer eingeschränkten Zusammenarbeit bei der Verarbeitung von Benutzeranforderungen führt. Die Einschränkung besteht darin, dass Übersetzungen erforderlich sind, um die Kommunikation zwischen Websites herzustellen.
Das folgende Diagramm zeigt ein Beispiel einer heterogenen Datenbank:
Verteilter Datenbankspeicher
Der verteilte Datenbankspeicher wird auf zwei Arten verwaltet:
- Replikation
- Fragmentierung
Replikation
Bei der Datenbankreplikation speichern die Systeme Kopien von Daten an verschiedenen Standorten . Wenn eine vollständige Datenbank an mehreren Standorten verfügbar ist, handelt es sich um eine vollständig redundante Datenbank.
Der Vorteil der Datenbankreplikation besteht darin, dass sie die Datenverfügbarkeit erhöht n verschiedenen Sites und ermöglicht die parallele Verarbeitung von Abfrageanforderungen.
Datenbankreplikation bedeutet jedoch, dass Daten ständig aktualisiert und mit anderen Standorten synchronisiert werden müssen, um eine exakte Datenbankkopie zu erhalten. Alle Änderungen, die auf einer Website vorgenommen werden, müssen auf anderen Websites aufgezeichnet werden, da es sonst zu Inkonsistenzen kommt.
Ständige Aktualisierungen verursachen viel Server-Overhead und erschweren die Gleichzeitigkeitskontrolle, da viele gleichzeitige Abfragen auf allen verfügbaren Sites geprüft werden müssen.
Fragmentierung
Wenn es um die Fragmentierung von verteilten Datenbankspeichern geht, werden die Beziehungen fragmentiert, was bedeutet, dass sie in kleinere Teile aufgeteilt werden . Jedes der Fragmente wird auf einer anderen Seite gespeichert, wo es benötigt wird.
Voraussetzung für die Fragmentierung ist, dass die Fragmente später ohne Datenverlust wieder in die ursprüngliche Relation rekonstruiert werden können.
Der Vorteil der Fragmentierung besteht darin, dass es keine Datenkopien gibt , wodurch Dateninkonsistenzen verhindert werden.
Es gibt zwei Arten der Fragmentierung:
- Horizontale Fragmentierung - Das Beziehungsschema wird in Zeilengruppen zerlegt, und jede Gruppe (Tupel) wird einem Fragment zugeordnet.
- Vertikale Fragmentierung - Das Beziehungsschema ist in kleinere Schemas fragmentiert, und jedes Fragment enthält einen gemeinsamen Kandidatenschlüssel, um eine verlustfreie Verknüpfung zu gewährleisten.
Vor- und Nachteile verteilter Datenbanken
Nachfolgend sind einige wichtige Vor- und Nachteile verteilter Datenbanken aufgeführt:
| Vorteile | Nachteile |
|---|---|
| Modulare Entwicklung | Kostspielige Software |
| Zuverlässigkeit | Großer Overhead |
| Niedrigere Kommunikationskosten | Datenintegrität |
| Bessere Reaktion | Falsche Datenverteilung |
Die Vor- und Nachteile werden in den folgenden Abschnitten ausführlich erläutert.
Vorteile
- Modulare Entwicklung . Die modulare Entwicklung einer verteilten Datenbank impliziert, dass ein System auf neue Standorte oder Einheiten erweitert werden kann, indem neue Server und Daten zum bestehenden Setup hinzugefügt und ohne Unterbrechung mit dem verteilten System verbunden werden. Diese Art der Erweiterung verursacht keine Unterbrechungen in der Funktion verteilter Datenbanken.
- Zuverlässigkeit . Verteilte Datenbanken bieten im Gegensatz zu zentralisierten Datenbanken eine höhere Zuverlässigkeit. Im Falle eines Datenbankausfalls in einer zentralen Datenbank kommt das System vollständig zum Stillstand. In einer verteilten Datenbank funktioniert das System auch dann, wenn Fehler auftreten, und liefert nur reduzierte Leistung, bis das Problem behoben ist.
- Niedrigere Kommunikationskosten . Das lokale Speichern von Daten reduziert die Kommunikationskosten für die Datenmanipulation in verteilten Datenbanken. Eine lokale Datenspeicherung ist in zentralen Datenbanken nicht möglich.
- Bessere Antwort . Eine effiziente Datenverteilung in einem verteilten Datenbanksystem bietet eine schnellere Reaktion, wenn Benutzeranforderungen lokal erfüllt werden. In zentralisierten Datenbanken durchlaufen Benutzeranfragen die zentrale Maschine, die alle Anfragen verarbeitet. Das Ergebnis ist eine Verlängerung der Antwortzeit, insbesondere bei vielen Anfragen.
Nachteile
- Kostspielige Software . Die Gewährleistung von Datentransparenz und Koordination über mehrere Standorte hinweg erfordert oft den Einsatz teurer Software in einem verteilten Datenbanksystem.
- Großer Overhead . Viele Vorgänge an mehreren Standorten erfordern zahlreiche Berechnungen und eine ständige Synchronisierung, wenn die Datenbankreplikation verwendet wird, was einen hohen Verarbeitungsaufwand verursacht.
- Datenintegrität . Ein mögliches Problem bei der Verwendung der Datenbankreplikation ist die Datenintegrität, die durch die Aktualisierung von Daten an mehreren Standorten beeinträchtigt wird.
- Unsachgemäße Datenverteilung . Die Reaktionsfähigkeit auf Benutzeranfragen hängt weitgehend von der richtigen Datenverteilung ab. Das bedeutet, dass die Reaktionsfähigkeit verringert werden kann, wenn Daten nicht korrekt auf mehrere Standorte verteilt werden.