Einführung
MapReduce ist ein Verarbeitungsmodul im Apache Hadoop-Projekt. Hadoop ist eine Plattform, die entwickelt wurde, um Big Data mithilfe eines Netzwerks von Computern zum Speichern und Verarbeiten von Daten zu bewältigen.
Was an Hadoop so attraktiv ist, ist, dass erschwingliche dedizierte Server ausreichen, um einen Cluster zu betreiben. Sie können kostengünstige Consumer-Hardware verwenden, um mit Ihren Daten umzugehen.
Hadoop ist hochgradig skalierbar. Sie können mit nur einem Computer beginnen und Ihren Cluster dann auf eine unbegrenzte Anzahl von Servern erweitern. Die beiden wichtigsten Standardkomponenten dieser Softwarebibliothek sind:
- MapReduce
- HDFS – Verteiltes Hadoop-Dateisystem
In diesem Artikel sprechen wir über das erste der beiden Module. Sie werden lernen was MapReduce ist, wie es funktioniert und die grundlegende Terminologie von Hadoop MapReduce .

Was ist Hadoop MapReduce?
Das Programmiermodell von Hadoop MapReduce erleichtert die Verarbeitung von Big Data, die auf HDFS gespeichert sind.
Durch die Nutzung der Ressourcen mehrerer miteinander verbundener Maschinen verarbeitet MapReduce effektiv eine große Menge strukturierter und unstrukturierter Daten .
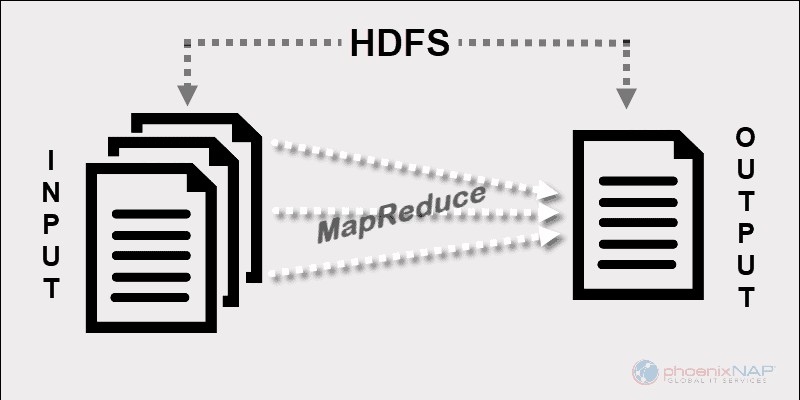
Vor Spark und anderen modernen Frameworks war diese Plattform der einzige Akteur im Bereich der verteilten Big-Data-Verarbeitung.
MapReduce weist Datenfragmente über die Knoten in einem Hadoop-Cluster zu. Das Ziel ist es, einen Datensatz in Chunks aufzuteilen und einen Algorithmus zu verwenden, um diese Chunks gleichzeitig zu verarbeiten. Die parallele Verarbeitung auf mehreren Rechnern erhöht die Verarbeitungsgeschwindigkeit sogar von Petabytes an Daten erheblich.
Verteilte Datenverarbeitungs-Apps
Dieses Framework ermöglicht das Schreiben von Anwendungen für die verteilte Datenverarbeitung. Normalerweise verwenden die meisten Programmierer Java, da Hadoop auf Java basiert .
Sie können MapReduce-Apps jedoch in anderen Sprachen wie Ruby oder Python schreiben. Unabhängig davon, welche Sprache ein Entwickler verwendet, müssen Sie sich keine Gedanken über die Hardware machen, auf der der Hadoop-Cluster ausgeführt wird.
Skalierbarkeit
Die Hadoop-Infrastruktur kann Server der Enterprise-Klasse sowie handelsübliche Hardware verwenden. Die Entwickler von MapReduce hatten Skalierbarkeit im Sinn. Es ist nicht erforderlich, eine Anwendung neu zu schreiben, wenn Sie weitere Maschinen hinzufügen. Ändern Sie einfach das Cluster-Setup und MapReduce arbeitet ohne Unterbrechungen weiter.
Was MapReduce so effizient macht, ist, dass es auf denselben Knoten wie HDFS läuft. Der Scheduler weist Knoten, auf denen sich die Daten bereits befinden, Aufgaben zu. Der Betrieb auf diese Weise erhöht den verfügbaren Durchsatz in einem Cluster.
So funktioniert MapReduce
Auf hoher Ebene zerlegt MapReduce Eingabedaten in Fragmente und verteilt sie auf verschiedene Computer.
Die Eingabefragmente bestehen aus Schlüssel-Wert-Paaren. Parallele Zuordnungsaufgaben verarbeiten die aufgeteilten Daten auf Maschinen in einem Cluster. Die Abbildungsausgabe dient dann als Eingabe für die Reduktionsstufe. Der Reduce-Task kombiniert das Ergebnis zu einer bestimmten Schlüssel-Wert-Paar-Ausgabe und schreibt die Daten in HDFS.
Das Hadoop Distributed File System läuft normalerweise auf denselben Rechnern wie die MapReduce-Software. Wenn das Framework einen Job auf den Knoten ausführt, die auch die Daten speichern, wird die Zeit zum Abschließen der Aufgaben erheblich verkürzt.
Grundlegende Terminologie von Hadoop MapReduce
Wie oben erwähnt, ist MapReduce eine Verarbeitungsschicht in einer Hadoop-Umgebung. MapReduce bearbeitet Aufgaben im Zusammenhang mit einem Job. Die Idee ist, eine große Anfrage zu bewältigen, indem man sie in kleinere Einheiten aufteilt.
JobTracker und TaskTracker
In den frühen Tagen von Hadoop (Version 1), JobTracker und TaskTracker Daemons führten Operationen in MapReduce aus. Damals konnte ein Hadoop-Cluster nur MapReduce-Anwendungen unterstützen.
Ein JobTracker steuerte die Verteilung von Anwendungsanforderungen an die Rechenressourcen in einem Cluster. Da es die Ausführung und den Status von MapReduce überwachte, befand es sich auf einem Master-Knoten.
Ein TaskTracker verarbeitet die Anfragen, die vom JobTracker kamen. Alle Task-Tracker wurden über die Slave-Knoten in einem Hadoop-Cluster verteilt.
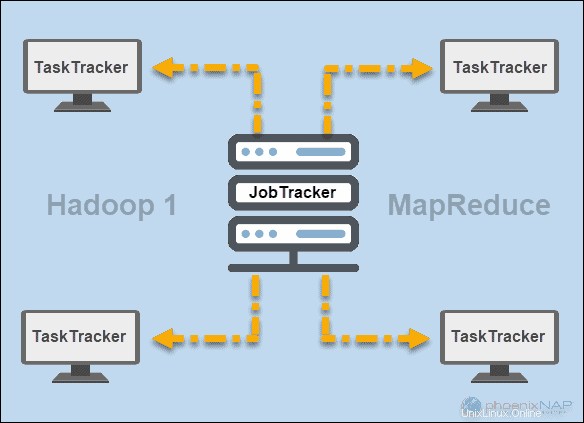
GARN
Später in Hadoop Version 2 und höher wurde YARN zum wichtigsten Ressourcen- und Planungsmanager. Daher der Name Yet Another Resource Manager . Yarn arbeitete auch mit anderen Frameworks für die verteilte Verarbeitung in einem Hadoop-Cluster.
MapReduce-Job
Ein MapReduce-Job ist die oberste Arbeitseinheit im MapReduce-Prozess. Es ist eine Aufgabe, die Map-and-Reduce-Prozesse abschließen müssen. Ein Job wird zur schnelleren Ausführung in kleinere Aufgaben über einen Cluster von Maschinen aufgeteilt.
Die Aufgaben sollten groß genug sein, um die Aufgabenbearbeitungszeit zu rechtfertigen. Wenn Sie einen Job in ungewöhnlich kleine Segmente unterteilen, kann die Gesamtzeit zum Vorbereiten der Aufteilungen und Erstellen von Aufgaben die Zeit übersteigen, die zum Erstellen der tatsächlichen Jobausgabe benötigt wird.
MapReduce-Aufgabe
MapReduce-Jobs haben zwei Arten von Aufgaben
Eine Kartenaufgabe ist eine einzelne Instanz einer MapReduce-App. Diese Tasks bestimmen, welche Datensätze aus einem Datenblock verarbeitet werden sollen. Die Eingabedaten werden aufgeteilt und parallel auf den zugewiesenen Rechenressourcen in einem Hadoop-Cluster analysiert. Dieser Schritt eines MapReduce-Jobs bereitet die Ausgabe des
Eine Reduzierungsaufgabe verarbeitet eine Ausgabe einer Kartenaufgabe. Ähnlich wie bei der Map-Stufe treten alle Reduzieraufgaben gleichzeitig auf und arbeiten unabhängig voneinander. Die Daten werden aggregiert und kombiniert, um die gewünschte Ausgabe zu liefern. Das Endergebnis ist ein reduzierter Satz von
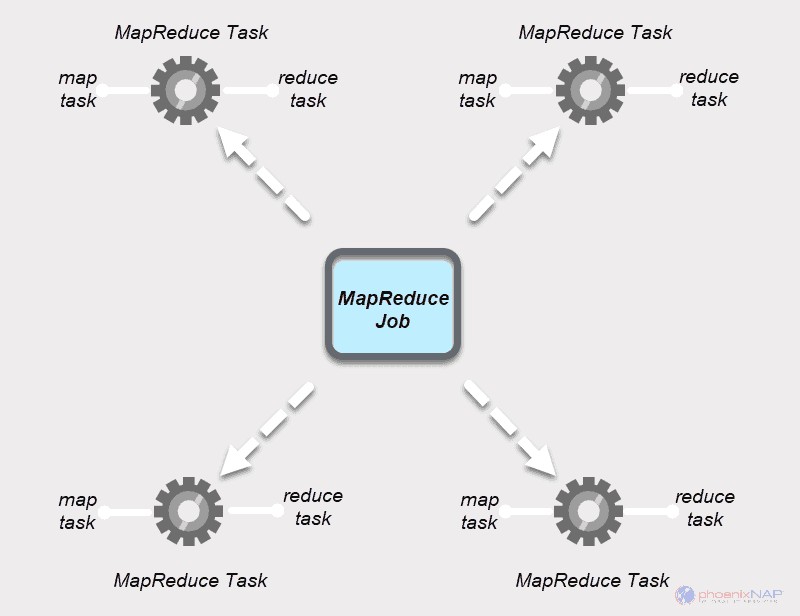
Die Map- und Reduce-Stufen bestehen jeweils aus zwei Teilen.
Die Karte Teil befasst sich zunächst mit dem Splitting der Eingabedaten, die einzelnen Kartenaufgaben zugewiesen werden. Dann die Zuordnung -Funktion erstellt die Ausgabe in Form von Zwischenschlüssel-Wert-Paaren.
Das Reduzieren Stage hat einen Shuffle- und einen Reduce-Step. Mischen nimmt die Zuordnungsausgabe und erstellt eine Liste verwandter Schlüssel-Wert-Listen-Paare. Dann reduzieren aggregiert die Ergebnisse des Mischens, um die endgültige Ausgabe zu erzeugen, die von der MapReduce-Anwendung angefordert wurde.
Wie Hadoop Map und Reduce zusammenarbeiten
Wie der Name schon sagt, verarbeitet MapReduce Eingabedaten in zwei Stufen – Map und Reduzieren . Um dies zu demonstrieren, verwenden wir ein einfaches Beispiel, bei dem die Anzahl der Vorkommen von Wörtern in jedem Dokument gezählt wird.
Die endgültige Ausgabe, nach der wir suchen, ist:Wie oft die Wörter Apache, Hadoop, Class und Track insgesamt in allen Dokumenten vorkommen .
Zur Veranschaulichung besteht die Beispielumgebung aus drei Knoten. Die Eingabe enthält sechs Dokumente, die über den Cluster verteilt sind. Wir werden es hier einfach halten, aber unter realen Umständen gibt es keine Begrenzung. Sie können Tausende von Servern und Milliarden von Dokumenten haben.
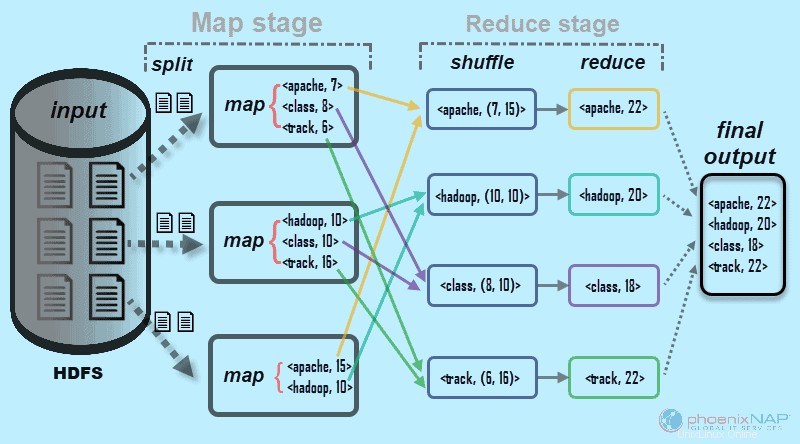
1. Zuerst in der Kartenphase , werden die Eingabedaten (die sechs Dokumente) aufgeteilt und über den Cluster verteilt (die drei Server). In diesem Fall arbeitet jede Zuordnungsaufgabe an einem Split, der zwei Dokumente enthält. Während des Mappings findet keine Kommunikation zwischen den Knoten statt. Sie treten unabhängig auf.
2. Anschließend erstellen Zuordnungsaufgaben einen
Dieser Prozess wird in parallelen Aufgaben auf allen Knoten für alle Dokumente durchgeführt und ergibt eine eindeutige Ausgabe.
3. Nachdem die Eingabeaufteilung und Zuordnung abgeschlossen ist, werden die Ausgaben jeder Zuordnungsaufgabe gemischt . Dies ist der erste Schritt der Reduzierungsphase . Da wir nach der Häufigkeit des Auftretens von vier Wörtern suchen, gibt es vier parallele Aufgaben zum Reduzieren. Die Reduce-Tasks können auf denselben Knoten wie die Map-Tasks ausgeführt werden, oder sie können auf jedem anderen Knoten ausgeführt werden.
Der Shuffle-Schritt stellt die Schlüssel Apache, Hadoop, Class, sicher und Verfolgen werden für den Reduzierschritt sortiert. Dieser Prozess gruppiert die Werte nach Schlüsseln in Form von
4. Im Reduzierschritt In der Phase „Reduzieren“ verarbeitet jede der vier Aufgaben eine
In unserem Beispiel aus dem Diagramm erhalten die Reduce-Aufgaben folgende Einzelergebnisse:
5. Schließlich die Daten in der Reduce-Phase wird zu einem Ausgang zusammengefasst. MapReduce zeigt uns nun, wie oft die Wörter Apache, Hadoop, Class, vorkommen undverfolgen tauchte in allen Dokumenten auf. Die aggregierten Daten werden standardmäßig im HDFS gespeichert.
Das Beispiel, das wir hier verwendet haben, ist ein einfaches. MapReduce führt viel kompliziertere Aufgaben aus.
Einige der Anwendungsfälle umfassen:
- Umwandeln von Apache-Protokollen in tabulatorgetrennte Werte (TSV).
- Ermitteln der Anzahl eindeutiger IP-Adressen in Weblog-Daten.
- Durchführung komplexer statistischer Modelle und Analysen.
- Ausführen von Algorithmen für maschinelles Lernen mit verschiedenen Frameworks wie Mahout.
Wie Hadoop-Partitionen Eingabedaten zuordnen
Der Partitionierer ist für die Verarbeitung der Kartenausgabe verantwortlich. Sobald MapReduce die Daten in Chunks aufteilt und sie Zuordnungsaufgaben zuweist, partitioniert das Framework die Schlüsselwertdaten. Dieser Prozess findet statt, bevor die endgültige Ausgabe der Mapper-Aufgabe erstellt wird.
MapReduce partitioniert und sortiert die Ausgabe basierend auf dem Schlüssel. Hier werden alle Werte für einzelne Schlüssel gruppiert, und der Partitionierer erstellt eine Liste mit den jedem Schlüssel zugeordneten Werten. Indem alle Werte eines einzelnen Schlüssels an denselben Reducer gesendet werden, stellt der Partitionierer sicher, dass die Map-Ausgabe gleichmäßig an den Reducer verteilt wird.
Der Standard-Partitionierer ist für viele Anwendungsfälle gut konfiguriert, aber Sie können neu konfigurieren, wie MapReduce Daten partitioniert.
Wenn Sie zufällig einen benutzerdefinierten Partitionierer verwenden, stellen Sie sicher, dass die Größe der Daten, die für jeden Reducer vorbereitet werden, ungefähr gleich ist. Wenn Sie Daten ungleichmäßig partitionieren, kann die Ausführung einer Reduzierungsaufgabe viel länger dauern. Dies würde den gesamten MapReduce-Job verlangsamen.