Einführung
NoSQL-Datenbanken ermöglichen es uns, riesige Datenmengen zu speichern und jederzeit von jedem Ort und Gerät aus darauf zuzugreifen. Es ist jedoch schwierig zu entscheiden, welche Datenmodellierungstechnik für Ihre Anforderungen am besten geeignet ist. Glücklicherweise gibt es für jeden Anwendungsfall eine Datenmodellierungstechnik.
In diesem Tutorial behandeln wir alle verschiedenen NoSQL-Datenmodellierungstechniken, die Sie beim Erstellen Ihrer NoSQL-Datenbank verwenden können.

Was ist ein NoSQL-Datenmodell?
NoSQL oder „Not Only SQL“ ist ein Datenmodell, das sich stark von den traditionellen SQL-Erwartungen unterscheidet.
Der Hauptunterschied besteht darin, dass NoSQL keine relationale Datenmodellierungstechnik verwendet und flexibles Design betont. Das Fehlen eines Schemas macht das Entwerfen zu einem viel einfacheren und billigeren Prozess. Das soll nicht heißen, dass Sie ein Schema nicht vollständig verwenden können, sondern vielmehr, dass das Schemadesign sehr flexibel ist.
Ein weiteres nützliches Merkmal von NoSQL-Datenmodellen ist, dass sie für hohe Effizienz und Geschwindigkeit in Bezug auf die Erstellung von bis zu Millionen von Abfragen pro Sekunde ausgelegt sind. Dies wird dadurch erreicht, dass alle Daten in einer Tabelle enthalten sind, sodass JOINS und Querverweise nicht so leistungsintensiv sind.
NoSQL ist auch insofern einzigartig, als es horizontal skalierbar ist , im Vergleich zu SQL, das nur vertikal skalierbar ist. Mit NoSQL können Sie einfach einen anderen Shard verwenden, der billig ist, anstatt mehr Hardware zu kaufen, was nicht der Fall ist.
Vier Arten von NoSQL-Datenbanken
Im Allgemeinen gibt es vier verschiedene Arten von NoSQL-Datenbanken, auf denen Dutzende von Datenmodellen basieren:
Schlüsselwertspeicher
Schlüsselwertspeicher wurden speziell für Hochleistungsanforderungen entwickelt und sind wahrscheinlich eines der gängigsten Datenmodelle. Sie verwenden Schlüsselwerte mit Zeigern zum Speichern von Daten.
Dieser Zeiger ist einzigartig und verweist direkt auf eine Information, die alles sein kann, was Sie möchten. Sie können sogar einen leeren String als Wertschlüssel verwenden, wenn Sie möchten, obwohl es je nach Datenbank Obergrenzen für die Größe eines Werts gibt.
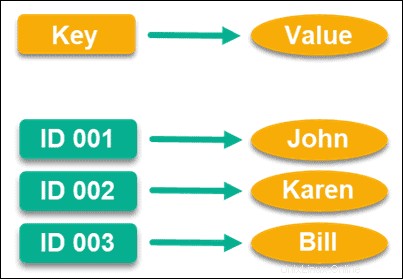
Interessanterweise war es Amazon, der ursprünglich dazu beigetragen hat, dieses Datenmodell auf den Weg zu bringen, und sie verwenden es für DynamoDB. Da es sich um einen der größten Online-Marktplätze der Welt handelt, können Sie sehen, wie leistungsstark dieses Datenmodell sein kann.
Dokumentbasierter Speicher
Bei SQL sind XML und JSON in der Regel miteinander verbunden, was Abfragen verlangsamt und den gesamten Prozess behindert. Da NoSQL das relationale Modell nicht verwendet, ist dies auch nicht erforderlich, und hier kommen dokumentbasierte Speicher ins Spiel.
Alle Daten werden in einer Tabelle gespeichert, sodass keine Querverweise erforderlich sind und Informationen nicht in einer Tabelle, sondern in einem Dokument gespeichert werden. Obwohl dies einem Schlüsselwertspeicher sehr ähnlich ist und manchmal unter seinem Dach betrachtet werden kann, besteht der Unterschied darin, dass dokumentbasiertes NoSQL im Allgemeinen eine Form der Codierung aufweist, z. B. XML.
Es gibt eine XML-spezifische NoSQL-Datenbank, die einen Dokumentenspeicher verwendet. Tatsächlich verwendet Strider CD MongoDB als Sicherungsspeicher.
Spaltenbasierter Speicher
Diese Art von Datenmodell speichert Informationen in Spalten und nicht in Zeilen, wie es bei SQL üblicher ist. Daten werden in Spalten gespeichert, die in Familien gruppiert sind, und diese Familien werden weiter in weitere Spalten gruppiert. Dadurch entsteht im Wesentlichen ein nahezu grenzenloses Datenmodell für die Verschachtelung von Spalten.
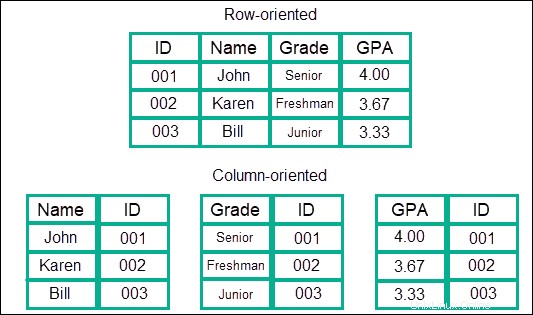
Der Vorteil ist, dass es im Vergleich zu anderen Modellen oder NoSQL bei der Suche unglaublich schnelle Geschwindigkeiten bietet. Die Daten werden als ein kontinuierlicher Eintrag behandelt, und daher ist es nicht erforderlich, zwischen Zeilen oder verschiedenen Bereichen zu springen, in denen die Informationen gespeichert sind.
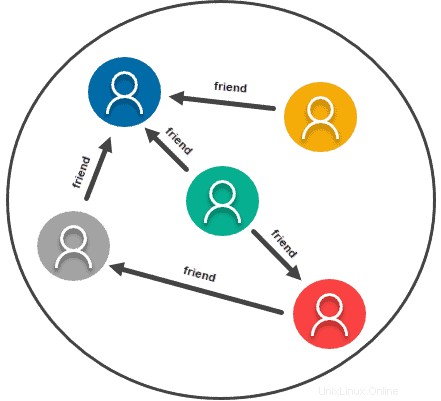
Grafikbasierter Speicher
Graph- oder Netzwerkdatenmodelle behandeln im Wesentlichen die Beziehung zwischen zwei beliebigen Informationen als genauso wichtig wie die Informationen selbst. Daher ist diese Art von Datenmodell wirklich für alle Informationen geeignet, die Sie normalerweise in einem Diagramm darstellen würden. Es verwendet Beziehungen und Knoten, wobei die Daten die Informationen selbst sind und die Beziehung zwischen Knoten gebildet wird.
Wie werden Daten in NoSQL gespeichert?
Die NoSQL-Datenspeicherung hängt davon ab, welche Art von Datenbank Sie verwenden. Da NoSQL kein Schema erfordert, gibt es keine Blaupause dafür, wie Daten gespeichert werden sollten, und variiert daher zwischen den Datenbanken.
Im Allgemeinen gibt es zwei Möglichkeiten, wie NoSQL-Datenspeicher funktioniert:
- Auf der Festplatte mit B-Trees , wobei sich der obere Teil permanent im RAM befindet.
- In-Memory, wo sich alles im RAM befindet, mit RB-Trees und alles, was auf der Disc gespeichert ist, ist nur ein Anhang.
Schemadesign für NoSQL
Da NoSQL-Datenbanken keine wirklich festgelegte Struktur haben, konzentriert sich die Entwicklung und das Schemadesign eher auf das physische Datenmodell. Das bedeutet, für große, horizontal ausgedehnte Umgebungen zu entwickeln, etwas, das NoSQL auszeichnet. Daher stehen die spezifischen Macken und Probleme, die mit der Skalierbarkeit einhergehen, im Vordergrund.
Daher besteht der erste Schritt darin, Geschäftsanforderungen zu definieren, da die Optimierung des Datenzugriffs ein Muss ist und nur erreicht werden kann, wenn man weiß, was das Unternehmen wünscht mit den Daten zu tun. Ihr Schemadesign sollte die an Ihren Anwendungsfall gebundenen Arbeitsabläufe ergänzen.
Es gibt mehrere Möglichkeiten, den Primärschlüssel auszuwählen, und das hängt letztendlich von den Benutzern selbst ab. Davon abgesehen könnten einige Daten ein effizienteres Schema nahelegen, insbesondere im Hinblick darauf, wie oft diese Daten abgefragt werden.
NoSQL-Datenmodellierungstechniken
Alle NoSQL-Datenmodellierungstechniken werden in drei Hauptgruppen eingeteilt:
- Konzeptionelle Techniken
- Allgemeine Modellierungstechniken
- Hierarchiemodellierungstechniken
Im Folgenden werden wir kurz alle NoSQL-Datenmodellierungstechniken besprechen.
Konzeptionelle Techniken
Es gibt drei konzeptionelle Techniken für die NoSQL-Datenmodellierung:
- Denormalisierung . Die Denormalisierung ist eine ziemlich verbreitete Technik und beinhaltet das Kopieren der Daten in mehrere Tabellen oder Formulare, um sie zu vereinfachen. Gruppieren Sie mit der Denormalisierung ganz einfach alle Daten, die abgefragt werden müssen, an einem Ort. Dies bedeutet natürlich, dass das Datenvolumen für verschiedene Parameter zunimmt, was das Datenvolumen erheblich erhöht.
- Aggregate . Dies ermöglicht es Benutzern, verschachtelte Einheiten mit komplexen internen Strukturen zu bilden und ihre spezielle Struktur zu variieren. Letztendlich reduziert die Aggregation Joins, indem Eins-zu-eins-Beziehungen minimiert werden.
Die meisten NoSQL-Datenmodelle verfügen über eine Form dieser Soft-Schema-Technik. Beispielsweise haben Graph- und Key-Value-Store-Datenbanken Werte, die ein beliebiges Format haben können, da diese Datenmodelle keine Wertbeschränkungen auferlegen. In ähnlicher Weise hat ein anderes Beispiel wie BigTable eine Aggregation über Spalten und Spaltenfamilien. - Anwendungsseitige Joins. NoSQL unterstützt normalerweise keine Joins, da NoSQL-Datenbanken fragenorientiert sind, wo Joins während der Entwurfszeit durchgeführt werden. Dies wird mit relationalen Datenbanken verglichen, die zum Zeitpunkt der Abfrageausführung durchgeführt werden. Dies führt natürlich tendenziell zu Leistungseinbußen und ist manchmal unvermeidlich.
Allgemeine Modellierungstechniken
Es gibt fünf allgemeine Techniken für die NoSQL-Datenmodellierung:
- Aufzählbare Schlüssel . Meistens sind ungeordnete Schlüsselwerte sehr nützlich, da Einträge einfach durch Hashing des Schlüssels auf mehrere dedizierte Server verteilt werden können. Trotzdem ist das Hinzufügen einer Art Sortierfunktion durch geordnete Schlüssel nützlich, auch wenn dies die Komplexität etwas erhöht und die Leistung beeinträchtigt.
- Dimensionalitätsreduktion . Geografische Informationssysteme verwenden in der Regel R-Tree Indizes und müssen vor Ort aktualisiert werden, was bei großen Datenmengen teuer werden kann. Ein weiterer traditioneller Ansatz besteht darin, die 2D-Struktur zu einer einfachen Liste zu verflachen, wie dies beispielsweise bei Geohash der Fall ist.
Mit der Dimensionsreduktion können Sie mehrdimensionale Daten einem einfachen Schlüsselwert oder sogar nicht mehrdimensionalen Modellen zuordnen.
Verwenden Sie die Dimensionsreduktion, um mehrdimensionale Daten einem Schlüsselwertmodell oder einem anderen nicht mehrdimensionalen Modell zuzuordnen. - Indextabelle. Nutzen Sie mit einer Indextabelle Indizes in Geschäften, die sie nicht unbedingt intern unterstützen. Versuchen Sie, eine eindeutige Tabelle mit Schlüsseln zu erstellen und dann zu verwalten, die einem bestimmten Zugriffsmuster folgen. Beispielsweise eine Haupttabelle zum Speichern von Benutzerkonten für den Zugriff nach Benutzer-ID.
- Zusammengesetzter Schlüsselindex . Obwohl es sich um eine generische Technik handelt, sind zusammengesetzte Schlüssel unglaublich nützlich, wenn geordnete Schlüssel verwendet werden. Wenn Sie es nehmen und mit sekundären Schlüsseln kombinieren, können Sie einen mehrdimensionalen Index erstellen, der der oben erwähnten Technik der Dimensionalitätsreduktion ziemlich ähnlich ist.
- Umgekehrte Suche – Direkte Aggregation. Das Konzept hinter dieser Technik besteht darin, einen Index zu verwenden, der einen bestimmten Satz von Kriterien erfüllt, diese Daten dann jedoch mit vollständigen Scans oder einer Form der Originaldarstellung zu aggregieren.
Dies ist eher ein Datenverarbeitungsmuster als eine Datenmodellierung, dennoch werden Datenmodelle sicherlich durch die Verwendung dieser Art von Verarbeitungsmuster beeinflusst. Berücksichtigen Sie, dass das zufällige Abrufen von Datensätzen, das für diese Technik erforderlich ist, ineffizient ist. Verwenden Sie die Abfrageverarbeitung in Stapeln, um dieses Problem zu mindern.
Hierarchiemodellierungstechniken
Es gibt sieben hierarchische Modellierungstechniken für NoSQL-Daten:
- Baumaggregation. Bei der Baumaggregation werden Daten im Wesentlichen als einzelnes Dokument modelliert. Dies kann sehr effizient sein, wenn es um Datensätze geht, auf die immer gleichzeitig zugegriffen wird, wie z. B. ein Twitter-Thread oder ein Reddit-Post. Natürlich ergibt sich dann das Problem, dass der wahlfreie Zugriff auf jeden einzelnen Eintrag ineffizient ist.
- Nachbarschaftslisten. Dies ist eine unkomplizierte Technik, bei der Knoten als unabhängige Datensätze von Arrays mit direkten Vorfahren modelliert werden. Das ist eine komplizierte Art zu sagen, dass Sie Knoten nach ihren Eltern oder Kindern durchsuchen können. Ähnlich wie die Baumaggregation ist es jedoch auch ziemlich ineffizient, einen ganzen Unterbaum für einen bestimmten Knoten abzurufen.
- Materialisierte Pfade. Diese Technik ist eine Art Denormalisierung und wird verwendet, um rekursive Traversierungen in Baumstrukturen zu vermeiden. Hauptsächlich möchten wir jedem Knoten die Eltern oder Kinder zuordnen, was uns dabei hilft, alle Vorgänger oder Nachkommen des Knotens zu bestimmen, ohne uns Gedanken über die Traversierung machen zu müssen. Übrigens können wir materialisierte Pfade als IDs speichern, entweder als Set oder als einzelne Zeichenkette.
- Verschachtelte Sätze . Eine Standardtechnik für baumartige Strukturen in relationalen Datenbanken, die genauso auf NoSQL- und Schlüsselwert- oder Dokumentdatenbanken anwendbar ist. Das Ziel besteht darin, die Baumblätter als Array zu speichern und dann jeden Nicht-Blatt-Knoten mithilfe von Start-/Endindizes einem Bereich von Blättern zuzuordnen.
Die Modellierung auf diese Weise ist eine effiziente Methode zum Umgang mit unveränderlichen Daten, da sie nur wenig Speicher benötigt und nicht unbedingt Traversen verwenden muss. Davon abgesehen sind Updates teuer, weil sie Indexaktualisierungen erfordern. - Reduzierung verschachtelter Dokumente:Nummerierte Feldnamen. Die meisten Suchmaschinen arbeiten eher mit Dokumenten, die aus einer flachen Liste von Feldern und Werten bestehen, und nicht aus Dokumenten mit einer komplexen internen Struktur. Daher versucht diese Datenmodellierungstechnik, diese komplexen Strukturen einem einfachen Dokument zuzuordnen, z. B. das Zuordnen von Dokumenten mit einer hierarchischen Struktur, eine häufig auftretende Schwierigkeit.
Natürlich ist diese Art der Arbeit mühsam und nicht einfach skalierbar, insbesondere wenn die verschachtelten Strukturen zunehmen. - Reduzierung verschachtelter Dokumente:Näherungsabfragen. Eine Möglichkeit, die potenziellen Probleme mit der Datenmodellierungstechnik für nummerierte Feldnamen zu lösen, besteht darin, eine ähnliche Technik namens Proximity Queries zu verwenden Diese begrenzen den Abstand zwischen Wörtern in einem Dokument, wodurch die Leistung gesteigert und die Auswirkungen auf die Abfragegeschwindigkeit verringert werden.
- Batch-Grafikverarbeitung. Die Batch-Grafikverarbeitung ist eine großartige Technik, um die Beziehungen nach oben oder unten für einen Knoten in wenigen Schritten zu untersuchen. Es ist ein teurer Prozess und lässt sich nicht unbedingt sehr gut skalieren. Durch die Verwendung von Message Passing und MapReduce können wir diese Art der Graphverarbeitung durchführen.