Einführung
PostgreSQL ist ein zuverlässiges und robustes relationales Datenbanksystem mit ACID-konformen Transaktionen. Es wurde entwickelt, um Workloads aller Größen zu bewältigen, wodurch es sich gut für den persönlichen Gebrauch und groß angelegte Bereitstellungen wie Data Warehouses, Big Data-Server oder Webdienste eignet.
Durch die Bereitstellung von PostgreSQL auf Kubernetes wird eine skalierbare und portable PostgreSQL-Instanz erstellt, die die guten Seiten sowohl des RDBMS als auch der Orchestrierungsplattform nutzt.
Dieser Artikel zeigt Ihnen zwei Methoden zum Bereitstellen von PostgreSQL auf Kubernetes – mithilfe eines Helm-Diagramms oder durch manuelles Erstellen Ihrer Konfiguration.

Voraussetzungen
- Ein Kubernetes-Cluster mit installiertem kubectl
- Helm 3 installiert
- Administratorrechte auf Ihrem System
Stellen Sie PostgreSQL mit Helm bereit
Helm bietet Ihnen eine schnelle und einfache Möglichkeit, eine PostgreSQL-Instanz auf Ihrem Cluster bereitzustellen.
Schritt 1:Helm-Repository hinzufügen
1. Durchsuchen Sie Artifact Hub nach einem PostgreSQL-Helm-Diagramm, das Sie verwenden möchten. Fügen Sie das Repository des Diagramms zu Ihrer lokalen Helm-Installation hinzu, indem Sie Folgendes eingeben:
helm repo add [repository-name] [repository-address]Dieser Artikel verwendet das Bitnami-Helm-Diagramm für die PostgreSQL-Installation.

2. Nachdem Sie das Repository hinzugefügt haben, aktualisieren Sie Ihre lokalen Repositorys.
helm repo updateDas System bestätigt das erfolgreiche Update.

Schritt 2:Persistentes Speichervolume erstellen und anwenden
Die Daten in Ihrer Postgres-Datenbank müssen über Pod-Neustarts hinweg bestehen bleiben.
1. Erstellen Sie dazu mit einem Texteditor wie nano eine PersistentVolume-Ressource in einer YAML-Datei.
nano postgres-pv.yamlDer Inhalt der Datei definiert:
- Die Ressource selbst.
- Die Speicherklasse.
- Die Menge des zugewiesenen Speicherplatzes.
- Die Zugriffsmodi.
- Der Einhängepfad auf dem Hostsystem.
Dieses Beispiel verwendet die folgende Konfiguration:
apiVersion: v1
kind: PersistentVolume
metadata:
name: postgresql-pv
labels:
type: local
spec:
storageClassName: manual
capacity:
storage: 10Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/mnt/data"
2. Speichern Sie die Datei und beenden Sie sie. Wenden Sie dann die Konfiguration mit kubectl an :
kubectl apply -f postgres-pv.yamlDas System bestätigt die Erstellung des persistenten Volumes.

Schritt 3:Persistent Volume Claim erstellen und anwenden
1. Erstellen Sie einen Persistent Volume Claim (PVC), um den im vorherigen Schritt zugewiesenen Speicher anzufordern.
nano postgres-pvc.yamlDas Beispiel verwendet die folgende Konfiguration:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: postgresql-pv-claim
spec:
storageClassName: manual
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 10Gi
2. Speichern Sie die Datei und beenden Sie sie. Wenden Sie die Konfiguration mit kubectl an :
kubectl apply -f postgres-pvc.yamlDas System bestätigt die erfolgreiche PVC-Erstellung.

3. Verwenden Sie kubectl get um zu überprüfen, ob der PVC erfolgreich mit dem PV verbunden ist:
kubectl get pvcDie Statusspalte zeigt, dass der Anspruch Gebunden ist .

Schritt 4:Installieren Sie Helm Chart
Installieren Sie das Steuerdiagramm mit helm install Befehl. Fügen Sie --set hinzu Flags für den Befehl, um die Installation mit dem von Ihnen erstellten PVC zu verbinden und Volume-Berechtigungen zu aktivieren:
helm install [release-name] [repo-name] --set persistence.existingClaim=[pvc-name] --set volumePermissions.enabled=trueDas System zeigt nach erfolgreicher Installation einen Bericht an.
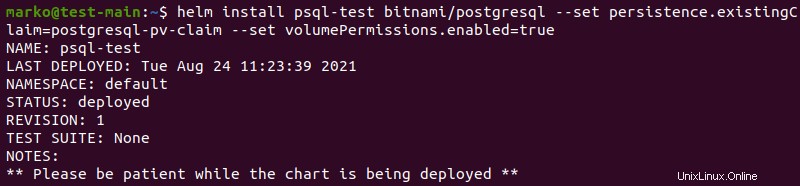
Schritt 5:Mit dem PostgreSQL-Client verbinden
1. Exportieren Sie das POSTGRES_PASSWORD Umgebungsvariable, um sich bei der PostgreSQL-Instanz anmelden zu können:
export POSTGRES_PASSWORD=$(kubectl get secret --namespace default psql-test-postgresql -o jsonpath="{.data.postgresql-password}" | base64 --decode)2. Öffnen Sie ein weiteres Terminalfenster und geben Sie den folgenden Befehl ein, um den Postgres-Port weiterzuleiten:
kubectl port-forward --namespace default svc/psql-test-postgresql 5432:5432Das System beginnt mit der Bearbeitung der Portverbindung.

3. Minimieren Sie das Fenster für die Portweiterleitung und kehren Sie zum vorherigen Fenster zurück. Geben Sie den Befehl ein, um eine Verbindung zu psql, einem PostgreSQL-Client, herzustellen:
PGPASSWORD="$POSTGRES_PASSWORD" psql --host 127.0.0.1 -U postgres -d postgres -p 5432
Die psql Die Eingabeaufforderung wird angezeigt und PostgreSQL ist bereit, Ihre Eingaben zu empfangen.

Stellen Sie PostgreSQL bereit, indem Sie eine Konfiguration von Grund auf neu erstellen
Die manuelle Konfiguration von Postgres auf Kubernetes ermöglicht Ihnen die Feinabstimmung Ihrer Bereitstellungskonfiguration.
Schritt 1:ConfigMap erstellen und anwenden
Die ConfigMap-Ressource enthält die Daten, die während des Bereitstellungsprozesses verwendet werden.
1. Erstellen Sie eine ConfigMap-YAML-Datei in einem Texteditor.
nano postgres-configmap.yaml2. Der wichtigste Teil der Datei ist der Datenabschnitt, in dem Sie einen Namen für die Datenbank angeben , der Benutzername und das Passwort für die Anmeldung bei der PostgreSQL-Instanz.
Das Beispiel verwendet die folgenden Parameter in der ConfigMap-Datei.
apiVersion: v1
kind: ConfigMap
metadata:
name: postgres-config
labels:
app: postgres
data:
POSTGRES_DB: postgresdb
POSTGRES_USER: admin
POSTGRES_PASSWORD: test123
3. Speichern Sie die Datei und beenden Sie sie. Wenden Sie dann die Ressource mit kubectl an :
kubectl apply -f postgres-configmap.yamlDas System bestätigt die erfolgreiche Erstellung der Konfigurationsdatei.

Schritt 2:Persistentes Speichervolume und Anspruch auf persistentes Volume erstellen und anwenden
1. Erstellen Sie eine YAML-Datei für die Speicherkonfiguration.
nano postgres-storage.yaml2. Die Helm-Chart-Bereitstellungsmethode verwendete zwei separate Dateien für das Persistent Volume und den Persistent Volume Claim, aber Sie können auch beide Konfigurationen in einer Datei platzieren, wie im Beispiel unten.
kind: PersistentVolume
apiVersion: v1
metadata:
name: postgres-pv-volume
labels:
type: local
app: postgres
spec:
storageClassName: manual
capacity:
storage: 5Gi
accessModes:
- ReadWriteMany
hostPath:
path: "/mnt/data"
---
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: postgres-pv-claim
labels:
app: postgres
spec:
storageClassName: manual
accessModes:
- ReadWriteMany
resources:
requests:
storage: 5Gi
3. Speichern Sie die Datei und beenden Sie sie. Wenden Sie die Ressourcen mit kubectl an :
kubectl apply -f postgres-storage.yamlDas System bestätigt die erfolgreiche Erstellung von PV und PVC.
4. Überprüfen Sie mit dem folgenden Befehl, ob der PVC mit dem PV verbunden ist:
kubectl get pvcDer Status des PVC ist Gebunden , und der PVC kann in der PostgreSQL-Bereitstellung verwendet werden.

Schritt 3:PostgreSQL-Bereitstellung erstellen und anwenden
1. Erstellen Sie eine Bereitstellungs-YAML-Datei.
nano postgres-deployment.yaml2. Die Bereitstellungsdatei enthält die Konfiguration der PostgreSQL-Bereitstellung und stellt Spezifikationen für die Container und Volumes bereit:
apiVersion: apps/v1
kind: Deployment
metadata:
name: postgres
spec:
replicas: 1
selector:
matchLabels:
app: postgres
template:
metadata:
labels:
app: postgres
spec:
containers:
- name: postgres
image: postgres:10.1
imagePullPolicy: "IfNotPresent"
ports:
- containerPort: 5432
envFrom:
- configMapRef:
name: postgres-config
volumeMounts:
- mountPath: /var/lib/postgresql/data
name: postgredb
volumes:
- name: postgredb
persistentVolumeClaim:
claimName: postgres-pv-claim
3. Speichern Sie die Datei und beenden Sie sie. Wenden Sie die Bereitstellung mit kubectl an :
kubectl apply -f postgres-deployment.yamlDas System bestätigt die erfolgreiche Erstellung des Deployments.
Schritt 4:PostgreSQL-Dienst erstellen und anwenden
1. Zuletzt erstellen Sie die YAML-Datei, um den PostgreSQL-Dienst zu konfigurieren.
nano postgres-service.yaml2. Geben Sie den Diensttyp und die Ports an. Das Beispiel verwendet die folgende Konfiguration:
apiVersion: v1
kind: Service
metadata:
name: postgres
labels:
app: postgres
spec:
type: NodePort
ports:
- port: 5432
selector:
app: postgres
3. Speichern Sie die Datei und beenden Sie sie. Wenden Sie die Konfiguration mit kubectl an :
kubectl apply -f postgres-service.yamlDas System bestätigt die erfolgreiche Erstellung des Dienstes.

4. Verwenden Sie den folgenden Befehl, um alle Ressourcen auf dem System aufzulisten.
kubectl get allDer Pod und die Bereitstellung zeigen den 1/1 Bereitschaftszustand. Die gewünschte Anzahl von Replikatsätzen spiegelt wider, was in der YAML-Bereitstellungsdatei konfiguriert ist.
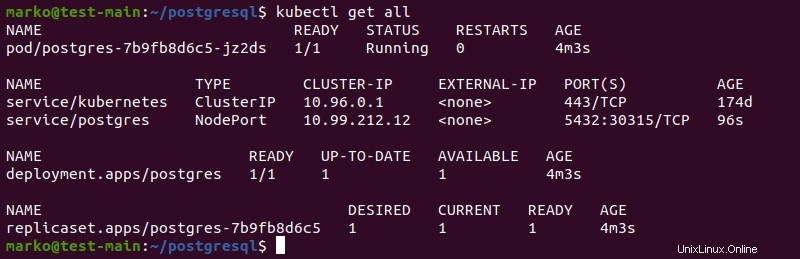
Schritt 5:Mit PostgreSQL verbinden
1. Wenn alle Ressourcen bereit sind, verwenden Sie kubectl exec um sich bei der PostgreSQL-Instanz anzumelden.
kubectl exec -it [pod-name] -- psql -h localhost -U admin --password -p [port] postgresdb
2. Das System fragt nach dem Passwort. Geben Sie das in Schritt 1 definierte Passwort ein und drücken Sie Enter . Die psql Eingabeaufforderung erscheint.

Die Datenbank ist nun bereit, Benutzereingaben zu empfangen.