Einführung
Eine der größten Bedrohungen für moderne Datenbanken ist der Datenverlust durch Hardwarefehler oder Ransomware. Verteilte Datenbanken bieten eine Lösung, indem sie Daten an verschiedenen physischen Standorten replizieren.
Die Datenbankreplikation ermöglicht es, Teile einer Datenbank auf mehrere Knoten zu verteilen.
In diesem Lernprogramm behandeln wir, wie die Datenreplikation funktioniert, wann sie verwendet wird, verschiedene Replikationstypen und -schemen sowie Tools, die beim Replizieren einer Datenbank helfen.

Was ist Datenbankreplikation?
Datenbankreplikation ist der Prozess, Daten zu kopieren und an verschiedenen Orten zu speichern. Durch die Datenreplikation wird sichergestellt, dass eine konsistente Kopie der Datenbank über alle Knoten in einem verteilten System hinweg vorhanden ist. Dies dient der breiten Verfügbarkeit der Daten und dem Schutz vor Datenverlust.
Die replizierten Daten können vollständig sein oder teilweise Snapshot und kann vor Ort, extern oder in einer Cloud-Umgebung gespeichert werden. Im Falle eines Ausfalls stellen Unternehmen Daten wieder her und erhalten die Geschäftskontinuität aufrecht, indem sie von einem Backup-Speicherort wiederherstellen.
Hinweis: 90 % der Unternehmen ohne Disaster-Recovery-Plan schließen nach einer größeren Unterbrechung. Eliminieren Sie dieses Risiko mit branchenführenden Disaster-Recovery-as-a-Service (DRaaS)-Lösungen.
Daten werden entweder synchron repliziert oder asynchron :
- Synchrone Replikation . Daten werden gleichzeitig in die primäre Datenbank und alle ihre Replikate geschrieben.
- Asynchrone Replikation . Daten werden zuerst in die primäre Datenbank geschrieben und später in die Replikate kopiert.
Datenbankreplikationstypen
Es gibt verschiedene Methoden, um eine Datenbank zu replizieren. Organisationen sollten eine Technik wählen, die auf dem Zweck der replizierten Daten und der beabsichtigten Zugriffsart basiert.
Snapshot-Replikation
Snapshot-Replikation kopiert einen "Schnappschuss" der Datenbank - genau so, wie er in dem Moment erscheint, in dem der Replikationsprozess beginnt. Es überwacht nicht auf Änderungen oder Aktualisierungen der Daten.
Die Snapshot-Replikation ist nützlich, wenn sich die Daten nicht häufig ändern, aber auch, wenn es innerhalb kurzer Zeit erhebliche Änderungen gibt. Jede Änderung an der Datenbank macht einen Snapshot veraltet, bis ein neuer repliziert wird.
Transaktionsreplikation
Transaktionsreplikation erstellt eine vollständige Kopie der Datenbank, wobei neue Daten eingehen, wenn sich die Datenbank ändert. Daten werden in Echtzeit in der Reihenfolge der vorgenommenen Änderungen kopiert, wodurch Konsistenz gewährleistet wird.
Es ist am besten, die Transaktionsreplikation zu verwenden, um inkrementelle Echtzeitänderungen an Daten sicherzustellen. Dies verbessert die Leistung und verringert die Latenz, während gleichzeitig ein hohes Volumen an Lese-, Schreib- und Löschaktivitäten bereitgestellt wird.
Mergereplikation
Mergereplikation kombiniert Daten aus mehreren Quellen in einer einzigen Datenbank. Durch die Verwendung der Mergereplikation können mehrere Benutzer die Daten ändern und alle Änderungen auf das neue Replikat anwenden.
Die Mergereplikation hilft dabei, widersprüchliche Änderungen schnell zu erkennen und zu beheben. Außerdem können Benutzer offline Änderungen vornehmen, bevor sie mit dem Server synchronisiert werden.
Heterogene Replikation
Heterogene Replikation wird verwendet, um Daten zwischen Servern verschiedener Anbieter zu replizieren. So können Sie beispielsweise Daten von einem SQL-Server auf einen Nicht-SQL-Server kopieren.
Peer-to-Peer-Transaktionsreplikation
Peer-to-Peer-Replikation basiert auf Transaktionsreplikation. Es ermöglicht allen teilnehmenden Benutzern und Servern, Daten miteinander zu senden, sodass die Aktualisierungen nahezu in Echtzeit erfolgen.
Die Peer-to-Peer-Replikation ist besonders nützlich für Webanwendungen. Seine Flexibilität hilft, die Anzahl der Benutzer zu skalieren, ohne die Leistung zu beeinträchtigen. Es macht das System auch robuster, sodass Server zu Wartungszwecken abgeschaltet werden können.
Datenbankreplikationsschemata
Die folgenden Replikationsschemata werden für die Datenbankreplikation verwendet:
Vollständige Replikation
Durchführen einer vollständigen Replikation bedeutet, die komplette Datenbank auf jeden Knoten des verteilten Systems zu kopieren. Dieser Ansatz maximiert die Datenredundanz, erhöht die globale Leistung und die Datenverfügbarkeit. Daten sind verfügbar, solange ein Knoten funktionsfähig ist.
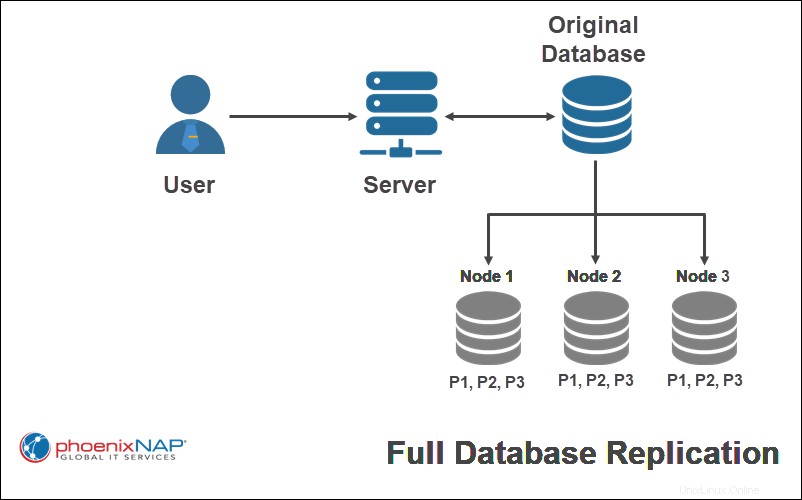
Im obigen Beispiel werden alle Teile der ursprünglichen Datenbank (P1, P2, P3) vollständig auf alle Standorte repliziert.
Die vollständige Replikation dauert länger, da das Update auf alle Standorte repliziert werden muss. Darüber hinaus können sich die Kosten für die Speicherung vollständiger Daten-Snapshots an mehreren Standorten summieren.
Teilweise Replikation
Das Kopieren nur bestimmter Teile einer Datenbank ist eine teilweise Replikation . Dies hängt in der Regel davon ab, wie wichtig es ist, die Daten an jedem Standort verfügbar zu haben.
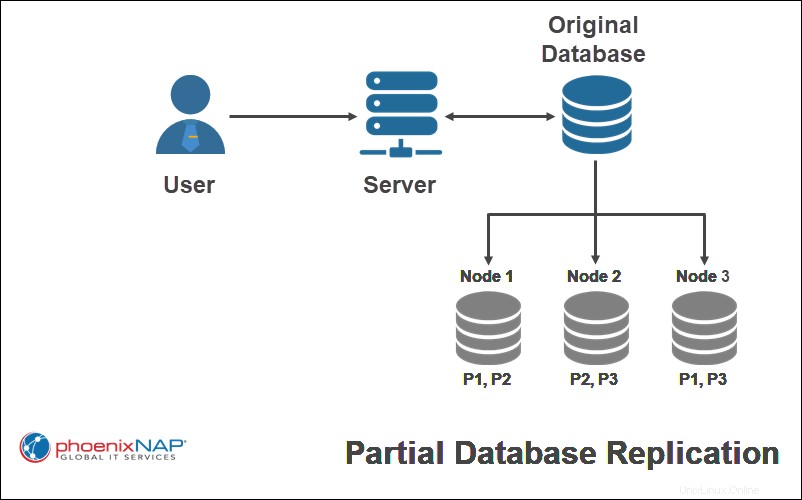
Im obigen Beispiel werden nur bestimmte Teile der ursprünglichen Datenbank (P1, P2, P3) auf einen einzigen Knoten repliziert.
Bei Verwendung eines partiellen Replikationsschemas kann die Anzahl der Kopien für jeden Teil der Datenbank zwischen einem und der Anzahl aller Knoten im verteilten System liegen.
Keine Replikation
Ohne keine Replikation erhält jeder Knoten in einem verteilten System nur eine Kopie eines Teils der Datenbank. Dieses Replikationsschema ist am schnellsten auszuführen, neigt jedoch dazu, die Datenverfügbarkeit zu verringern, und macht die Datenbank anfällig für Datenverlust. Parallelität ist jedoch leicht zu erreichen.
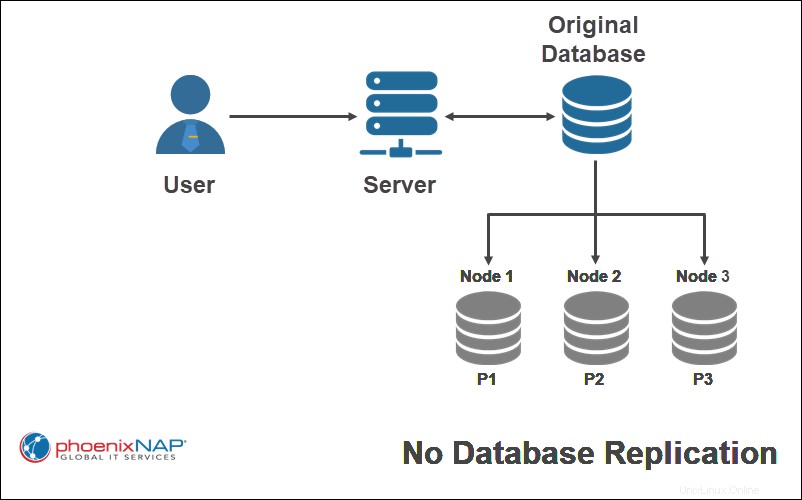
Im obigen Beispiel wird nur ein einzelnes Fragment der ursprünglichen Datenbank auf einen bestimmten Knoten repliziert.
Software und Tools zur Datenbankreplikation
Viele Datenbankverwaltungstools bieten Möglichkeiten zur Datenbankreplikation. Es gibt auch Replikationstools von Drittanbietern, die dieselben Funktionen bieten.
Tools von Drittanbietern sind möglicherweise sogar flexibler, da die meisten Ihnen die Replikation über mehrere Arten von Datenbanken ermöglichen. Hier sind einige der beliebtesten Beispiele:
- phoenixNAP-Datensicherung und -wiederherstellung. phoenixNAP bietet mehrere Sicherungsoptionen und -lösungen, einschließlich Veeam-Integration, Cloud-Datenbanksicherung, verwaltete Sicherung für Office 365 und DRaaS (Disaster Recovery as a Service).
- Veeam Backup &Replication . Veeam arbeitet mit verschiedenen Arten von Datenbanken, einschließlich Cloud-Datenbanken, virtuellen, Kubernetes- und physischen Verteilungen. Es bietet kontinuierlichen Datenschutz, erweiterte Replikation und Failover für Disaster Recovery und sofortige Wiederherstellung für gängige Datenbankmanager wie NAS, Microsoft SQL und Oracle.
- Acronis Cyber Backup . Acronis unterstützt über 20 Datenbankplattformen und bietet erweiterte Sicherheitsfunktionen, wie z. B. KI-basierte Ransomware-Prävention.
- NAKIVO Backup &Replikation . NAKIVO bietet Funktionen wie Unterstützung für Live-Apps, Wiederherstellung auf Datei- und Objektebene, globale Deduplizierung und automatische Berichte. Es kann Daten lokal, auf einem Remote-Server oder in der Cloud replizieren.
- Carbonite Safe Backup. Carbonite ist auf kleinere Unternehmen ausgerichtet. Es bietet automatische Cloud- und Festplattensicherung, Image-Sicherung und Bare-Metal-Wiederherstellung sowie Datenbankreplikation auf höheren Ebenen.
Vorteile der Datenreplikation
Die Verwendung der Datenbankreplikation hilft:
- Stellen Sie die Geschäftskontinuität mit einem Notfallwiederherstellungsplan sicher. Im Falle eines Hardwareausfalls oder eines Ransomware-Angriffs stellt die Datenreplikation als Teil Ihres Notfallwiederherstellungsplans sicher, dass eine Offsite-Kopie des Systems vorhanden ist. Dadurch können Unternehmen Daten wiederherstellen und die Geschäftskontinuität aufrechterhalten.
- Leistung verbessern. Die gleichen Daten an mehreren Standorten bedeutet, dass ein Benutzer Daten vom nächstgelegenen Server abrufen kann, wodurch die Netzwerklatenz verringert und die Leistung gesteigert wird.
- Mehrbenutzerunterstützung verbessern. Die Datenreplikation hilft bei der Abfrageausführung, insbesondere wenn mehrere Benutzer auf die Datenbank zugreifen.
- Analyse verbessern. Mit einer separaten, vollständigen Kopie einer Datenbank kann ein Team Analysen durchführen, ohne die Leistung zu beeinträchtigen.
- Verfügbarkeit verbessern. Mehrere Benutzer können auf Daten in einer verteilten Datenbank zugreifen und diese verwalten, ohne sich gegenseitig in die Quere zu kommen.
Nachteile der Datenreplikation
Die Datenreplikation bringt mehrere Herausforderungen mit sich:
- Es kann viel Speicherplatz erfordern, insbesondere für vollständige Replikationen. Dies kann hohe Kosten verursachen oder die Leistung beeinträchtigen, wenn viele Replikate gleichzeitig aktualisiert werden müssen.
- Das Aufrechterhalten der Datenkonsistenz ist schwierig, wenn Methoden wie Zusammenführen oder Peer-to-Peer-Replikation verwendet werden.