Die meisten Systemadministratoren und sogar einige Standardbenutzer bevorzugen die Befehlszeile für ihre täglichen Aufgaben wie das Bearbeiten und Löschen von Dateien, das Erstellen und Entfernen von Benutzern, das Suchen von IP-Adressen usw. Einer der Gründe dafür ist, dass die Befehlszeile schneller ist und verbraucht weniger Ressourcen. Eine andere Sache, die Benutzer häufig tun, ist das Herunterladen einer Datei. Sie können dies auch einfach und schneller über die Befehlszeile tun. Wget und curl sind die Befehlszeilenprogramme, mit denen Sie Dateien von der Befehlszeile herunterladen können.
In diesem Beitrag beschreiben wir, wie Sie die Dienstprogramme wget und curl verwenden, um eine Datei auf Ubuntu von der Befehlszeile herunterzuladen.
Hinweis :Wir werden das Verfahren auf Ubuntu 20.04 beschreiben System.
Dateien mit Wget herunterladen
Wget ist ein Befehlszeilentool zum Herunterladen von Dateien aus dem Internet. Mit wget können Sie eine einzelne HTML-Datei oder eine ganze Website herunterladen. Es unterstützt das Herunterladen von Dateien mit den Protokollen HTTP, HTTPS und FTP. Es ist auf fast allen Linux-Betriebssystemen installiert. Wenn Sie es jedoch nicht in Ihrem System finden oder es versehentlich entfernt wurde, können Sie es wie folgt installieren:
$ sudo apt install wget
Die grundlegende Syntax des wget-Befehls lautet wie folgt:
$ wget [option]… [URL]…
Laden Sie eine Datei von der Befehlszeile herunter
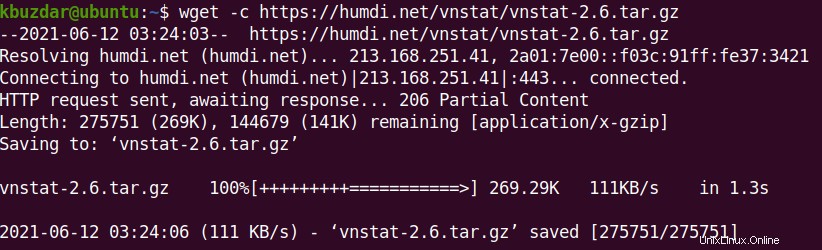
Um eine Datei von der Befehlszeile herunterzuladen, geben Sie einfach wget ein gefolgt von der URL der Datei, die Sie herunterladen möchten. Nehmen wir an, um „vnstat-2.6.tar.gz“, ein Paket zur Überwachung des Netzwerkverkehrs, von einer Website herunterzuladen, lautet der Befehl:
$ wget https://humdi.net/vnstat/vnstat-2.6.tar.gz
Wget beginnt mit dem Herunterladen der Datei und Sie sehen den Fortschritt. Die Datei wird im aktuellen Verzeichnis Ihres Terminals gespeichert.
Eine teilweise heruntergeladene Datei fortsetzen
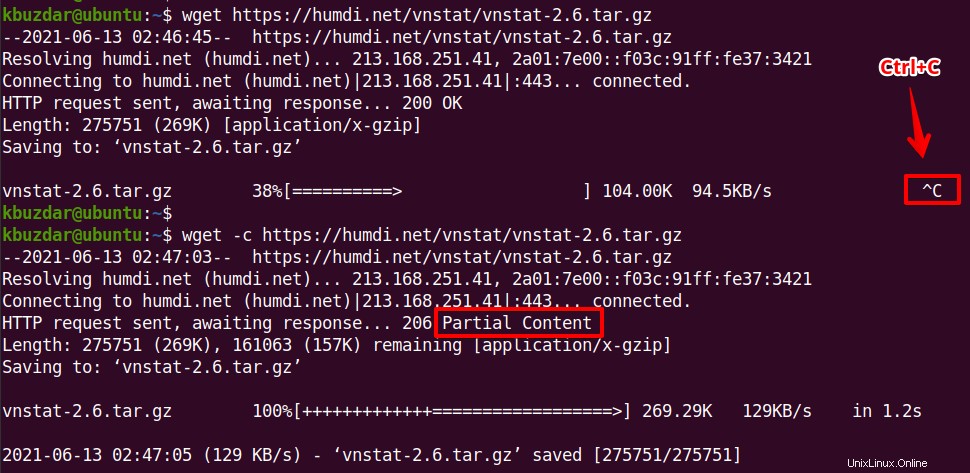
Wenn ein Download aus irgendeinem Grund gestoppt wird oder Sie ihn manuell durch Drücken von Strg+C gestoppt haben, können Sie ihn mit dem wget-Befehl -c fortsetzen Möglichkeit. Mit dieser Option können Sie eine teilweise heruntergeladene Datei dort fortsetzen, wo Sie sie unterbrochen haben.
$ wget -c <URL>
Ausführliche Ausgabe deaktivieren
Standardmäßig zeigt wget die ausführliche Ausgabe mit allen Details des Download-Prozesses an. Wenn Sie möchten, können Sie diese Ausgabe mit dem wget -nv einschränken Option.
$wget -nv <URL>
Diese Option zeigt nur die grundlegenden Informationen des Download-Vorgangs an.

Um die ausführliche Ausgabe vollständig auszuschalten, verwenden Sie -q Möglichkeit:
$ wget -q <URL>

Mehrere Dateien herunterladen
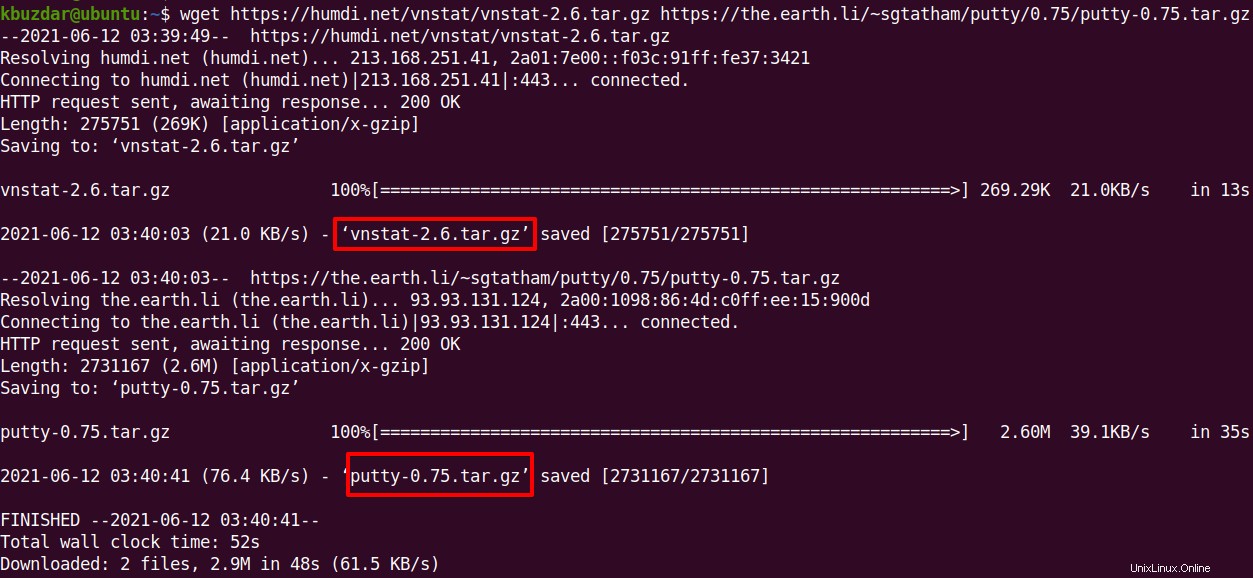
Um mehrere Dateien herunterzuladen, geben Sie wget ein gefolgt von den URLs aller Dateien.
$ wget <URL1> <URL2>
Der Befehl wget lädt beide Dateien herunter und speichert sie in Ihrem aktuellen Terminal-Verzeichnis.
Eine andere Möglichkeit, mehrere Dateien herunterzuladen, ist die Verwendung von wget -i Möglichkeit. Angenommen, Sie müssen eine große Anzahl von Dateien herunterladen. Sie müssen lediglich eine Textdatei erstellen und alle URLs in dieser Datei auflisten (eine URL pro Zeile). Geben Sie dann wget ein gefolgt von -i Option und den Dateinamen, der eine Liste von URLs enthält:
$ wget -i <filename>

Hinweis :In der obigen Ausgabe haben wir -nv verwendet Option zum Deaktivieren der ausführlichen Ausgabe.
Dateien mit Curl herunterladen
Curl ist ein Befehlszeilentool, das zum Herunterladen und Hochladen von Dateien auf oder vom Server verwendet wird. Es unterstützt über 20 Protokolle, darunter FTP, HTTP, HTTPS, TFTP, IMAP, LDAP usw.
Curl ist auf fast allen Linux-Betriebssystemen installiert. Wenn Sie es jedoch nicht in Ihrem System finden oder es versehentlich entfernt wurde, können Sie es wie folgt installieren:
$ sudo apt install curl
Die grundlegende Syntax des Curl-Befehls lautet wie folgt:
$ curl [option]… [URL]…
Grundlegende Nutzung des Curl-Befehls
Die grundlegende Verwendung des Curl-Befehls besteht darin, eine einzelne Datei oder den Inhalt einer Webseite herunterzuladen. Nehmen wir an, um eine Webseite „index.html“ herunterzuladen, würden wir curl eingeben gefolgt von der URL der Webseite:
$ curl <URL>
Dieser Befehl lädt die angegebene Datei in Ihr aktuelles Verzeichnis herunter.

Nachdem Sie den obigen Curl-Befehl ausgeführt haben, sehen Sie den auf dem Bildschirm angezeigten HTML-Inhalt ähnlich dem Folgenden: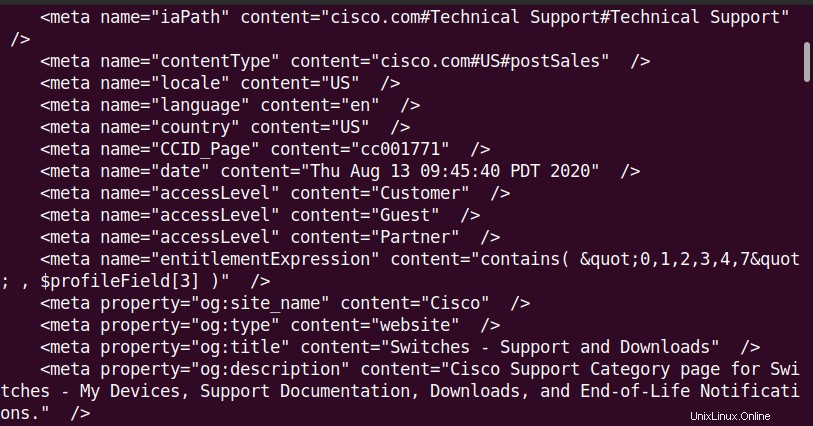
Speichern Sie den Inhalt der Seite in einer Datei
Sie können den Inhalt einer Seite herunterladen und in einer Datei speichern, anstatt ihn auf dem Bildschirm anzuzeigen. Um die Datei auf Ihrem System zu speichern, verwenden Sie den Curl-Befehl -O oder -o Möglichkeit. Das -O Option speichert die Datei unter demselben Namen wie die Datei am Remote-Speicherort. Während das -o Option ermöglicht das Speichern der Datei unter einem anderen Namen.
Mit der Option -O
Mit dem -O Option müssen Sie den Dateinamen nicht angeben. Die Datei wird in Ihrem System mit dem Namen der Datei am entfernten Speicherort gespeichert.
$ curl -O <URL>
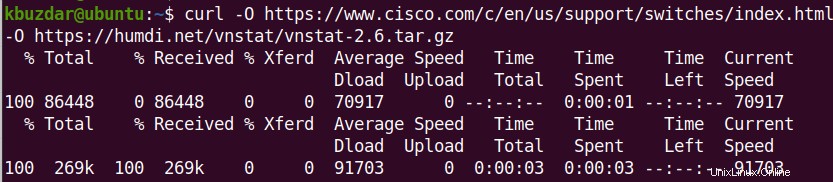
Der folgende Befehl speichert beispielsweise die Datei unter dem Namen „index.html“:
$ curl -O https://www.cisco.com/c/en/us/support/switches/index.html

Mit der Option -o
Mit dem -o können Sie einen Dateinamen Ihrer Wahl angeben.
$ curl -o filename <URL>
Der folgende Befehl speichert beispielsweise die Datei unter dem Namen „switches.html“:
$ curl -o switches.html https://www.cisco.com/c/en/us/support/switches/index.html
Curl im Hintergrund ausführen
Wenn Sie während des Curl-Download-Vorgangs keinen Fortschrittsbalken oder keine Fehlermeldung sehen möchten, können Sie ihn mit -s stumm schalten Option wie folgt:
$ curl -s <URL>

Mehrere Dateien herunterladen
Um mehrere Dateien herunterzuladen, geben Sie curl ein gefolgt von den URLs aller Dateien:
$ curl -O [URL1] -O [URL2] -O [URL3]….
Dieser Befehl speichert alle Dateien in Ihrem aktuellen Terminal-Verzeichnis.
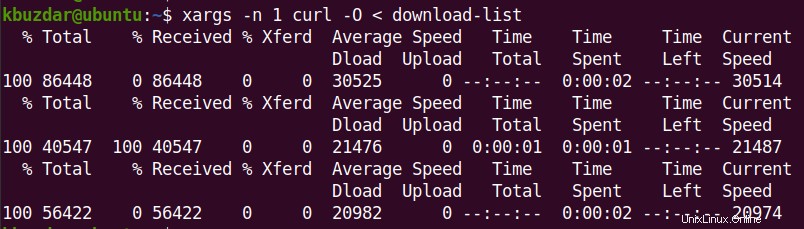
Wenn Sie zu viele URLs herunterladen müssen, erstellen Sie eine Textdatei und listen Sie die URLs darin auf.

Verwenden Sie dann den folgenden Befehl, um alle in der Datei aufgelisteten URLs herunterzuladen:
$ xargs -n 1 curl -O < filename
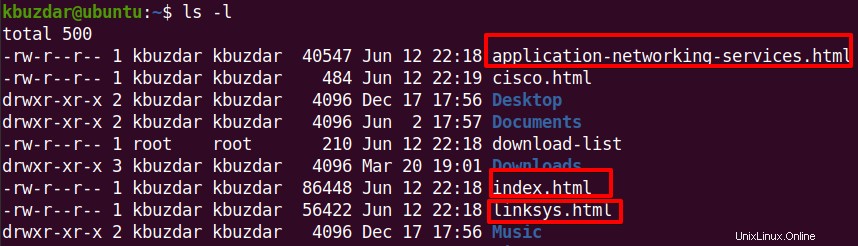
Sie können dann das ls verwenden Befehl, um zu bestätigen, ob alle Dateien heruntergeladen wurden.
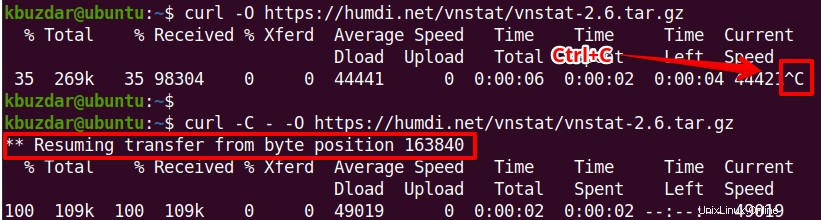
Eine teilweise heruntergeladene Datei fortsetzen
Wenn ein Download aus irgendeinem Grund gestoppt wird oder Sie ihn manuell durch Drücken von Strg+C gestoppt haben, können Sie ihn mit dem Curl-Befehl „-C – fortsetzen " Möglichkeit. Mit dieser Option können Sie eine teilweise heruntergeladene Datei dort fortsetzen, wo Sie sie unterbrochen haben.
$ curl -C - <URL>
Sowohl wget als auch curl sind die kostenlosen und Open-Source-Befehlszeilen-Dienstprogramme, die für das nicht interaktive Herunterladen von Dateien verwendet werden. Denken Sie daran, dass beide Dienstprogramme Dateien aus dem Internet herunterladen können; Sie unterscheiden sich stark in Bezug auf die Funktionalitäten. Sie können die Manpages von wget und curl besuchen, um einen detaillierten Überblick darüber zu erhalten, wozu diese Dienstprogramme in der Lage sind.