Einführung
Apache Kafka ist eine Streaming-Plattform für verteilte Ereignisse, die in der Lage ist, die Hochleistungs-Datenpipelines zu verarbeiten. Es wurde ursprünglich von Linkedin entwickelt, um dann als Open-Source-Plattform öffentlich zugänglich zu sein und von vielen IT-Unternehmen auf der ganzen Welt verwendet zu werden.
Dieser Artikel zeigt Ihnen, wie Sie Kafka unter Ubuntu 20.04 installieren und konfigurieren.
Installieren von Apache Kafka
Voraussetzung
Für Apache Kafka muss Java auf Ihrem Ubuntu 20.04-Rechner installiert sein. Lassen Sie uns zunächst Ihr Betriebssystem mit dem folgenden Befehl aktualisieren:
$ sudo apt update
Nachdem das Betriebssystem aktualisiert wurde, fahren Sie mit der Installation von Java fort:
$ sudo apt install openjdk-11-jre-headless
Überprüfen Sie, ob Java erfolgreich installiert wurde, indem Sie Folgendes ausführen:
$ java --version
Die Ausgabe:

Kafka herunterladen
Als nächstes müssen Sie die Kafka-Quelle auf Ihr Ubuntu 20.04 herunterladen. Es wird dringend empfohlen, es von der offiziellen Website von Apache Kafka herunterzuladen:https://kafka.apache.org/downloads
Zum Zeitpunkt des Schreibens dieses Artikels ist die neueste Version 2.7.0. Sie können es mit dem folgenden Befehl herunterladen:
$ cd $HOME
$ wget https://downloads.apache.org/kafka/2.7.0/kafka-2.7.0-src.tgz
Lassen Sie uns einen neuen Ordner mit dem Namen kafka-server im /usr/local-Verzeichnis erstellen:
$ sudo mkdir /usr/local/kafka-server
Extrahieren Sie dann die heruntergeladene Quelle von Kafka in das Verzeichnis /usr/local/kafka-server:
$ sudo tar xf $HOME/kafka-2.7.0-src.tgz -C /usr/local/kafka-server

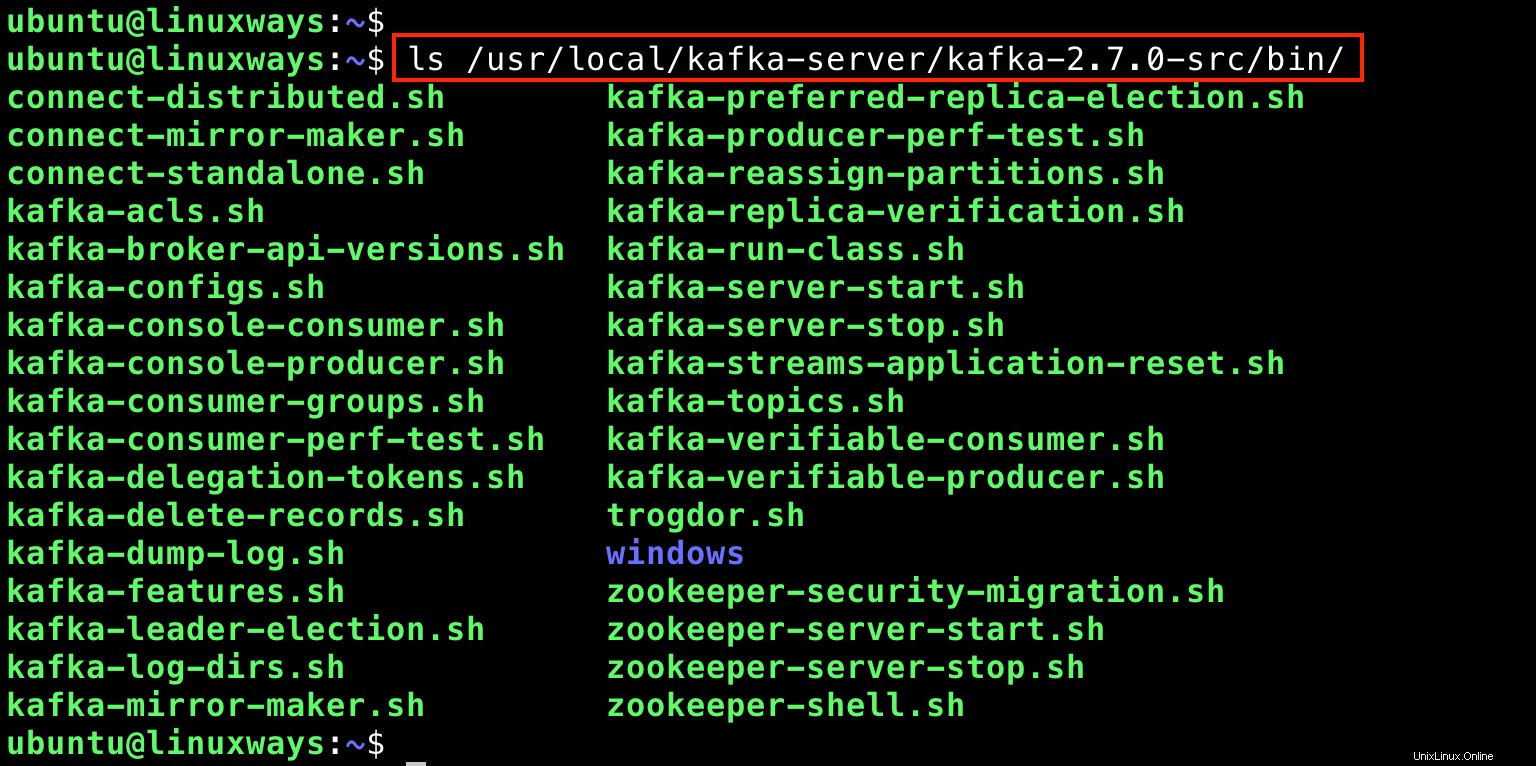
Sie hatten bereits die extrahierten Apache Kafka-Binärdateien. Auflisten dieser Dateien durch Ausführen von:
$ ls /usr/local/kafka-server/kafka-2.7.0-src/bin/
Ausgabe:
Jetzt ist es an der Zeit, Kafka und Zookeeper in Ubuntu 20.04 als Daemons laufen zu lassen. Dazu müssen Sie Systemd-Unit-Dateien sowohl für Kafka als auch für Zookeeper erstellen.
Systemd-Unit-Dateien für Kafka und Zookeeper erstellen
Verwenden Sie Ihren bevorzugten Editor und erstellen Sie zwei Dateien wie folgt:
/etc/systemd/system/zookeeper.service
[Unit] Description=Apache Zookeeper Server Requires=network.target remote-fs.target After=network.target remote-fs.target [Service] Type=simple ExecStart=/usr/local/kafka-server/kafka-2.7.0-src/bin/zookeeper-server-start.sh /usr/local/kafka-server/kafka-2.7.0-src/config/zookeeper.properties ExecStop=/usr/local/kafka-server/kafka-2.7.0-src/bin/zookeeper-server-stop.sh Restart=on-abnormal [Install] WantedBy=multi-user.target
/etc/systemd/system/kafka.service
[Unit] Description=Apache Kafka Server Documentation=http://kafka.apache.org/documentation.html Requires=zookeeper.service After=zookeeper.service [Service] Type=simple Environment="JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64" ExecStart=/usr/local/kafka-server/kafka-2.7.0-src/bin/kafka-server-start.sh /usr/local/kafka-server/kafka-2.7.0-src/config/server.properties ExecStop=/usr/local/kafka-server/kafka-2.7.0-src/bin/kafka-server-stop.sh Restart=on-abnormal [Install] WantedBy=multi-user.target
Um die Änderungen zu übernehmen, müssen die systemd-Daemons neu geladen werden und Sie müssen auch die Dienste aktivieren.
$ sudo systemctl daemon-reload $ sudo systemctl enable --now zookeeper.service $ sudo systemctl enable --now kafka.service $ sudo systemctl status kafka zookeeper
Ausgabe:
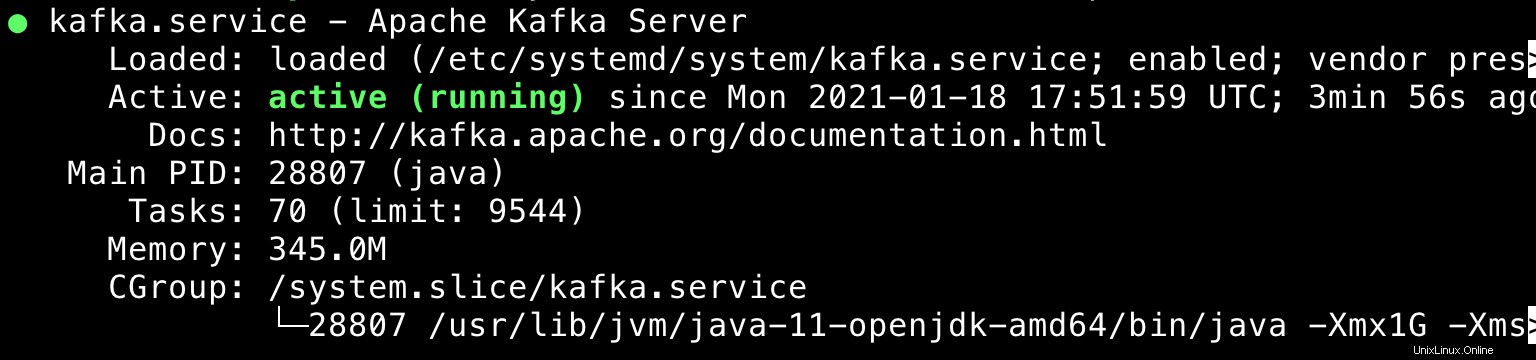
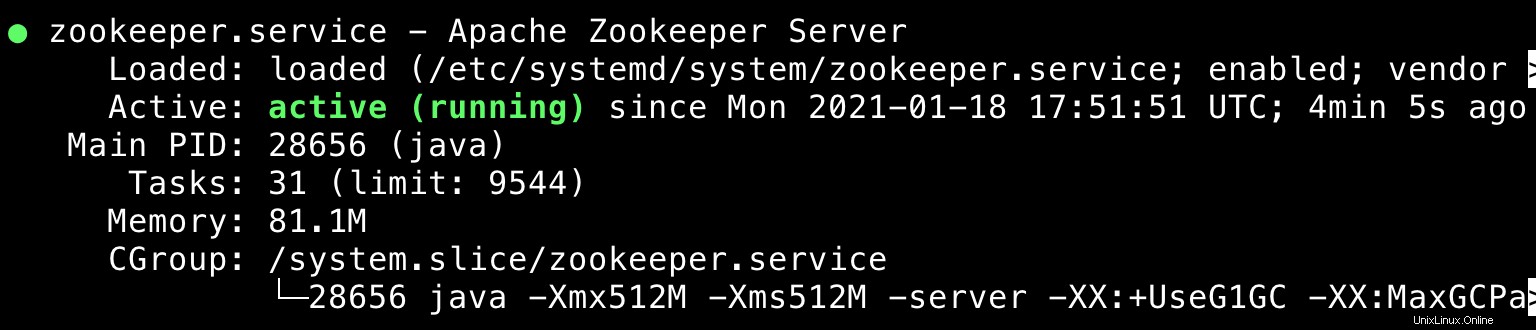
Cluster-Manager für Apache Kafka (CMAK) installieren
Der nächste Schritt ist die Installation des CMAK, das für Cluster Manager for Apache Kafka steht. CMAK ist ein Open-Source-Tool zum Verwalten und Überwachen von Kafka-Diensten. Es wurde ursprünglich von Yahoo entwickelt. Führen Sie die folgenden Befehle aus, um CMAK zu installieren:
$ cd $HOME $ git clone https://github.com/yahoo/CMAK.git

CMAK konfigurieren
Verwenden Sie dann Ihren bevorzugten Editor, um die CMAK-Konfiguration zu ändern.
$ vim ~/CMAK/conf/application.conf
In diesem Tutorial konfigurieren wir den Zookeeper als localhost , ändern wir den Wert von cmak.zkhosts als localhost:2181
Sie finden die cmak.zkhosts in Zeile 28.

Nun müssen Sie eine ZIP-Datei zum Bereitstellen der Anwendung erstellen:
$ cd ~/CMAK $ ./sbt clean dist
Es dauert etwa eine Minute, bis der Vorgang abgeschlossen ist. Die Ausgabe wird sein:

Starten des CMAK-Dienstes
Wechseln Sie in das Verzeichnis ~/CMAK/target/universal und extrahieren Sie die ZIP-Datei:
$ cd ~/CMAK/target/universal $ unzip cmak-3.0.0.5.zip
Wechseln Sie nach dem Entpacken der cmak-3.0.0.5.zip-Datei in das Verzeichnis und führen Sie die cmak-Binärdatei aus:
$ cd cmak-3.0.0.5 $ bin/cmak
Standardmäßig wird der cmak-Dienst auf Port 9000 ausgeführt.
Verwenden Sie den Webbrowser und gehen Sie zu http://
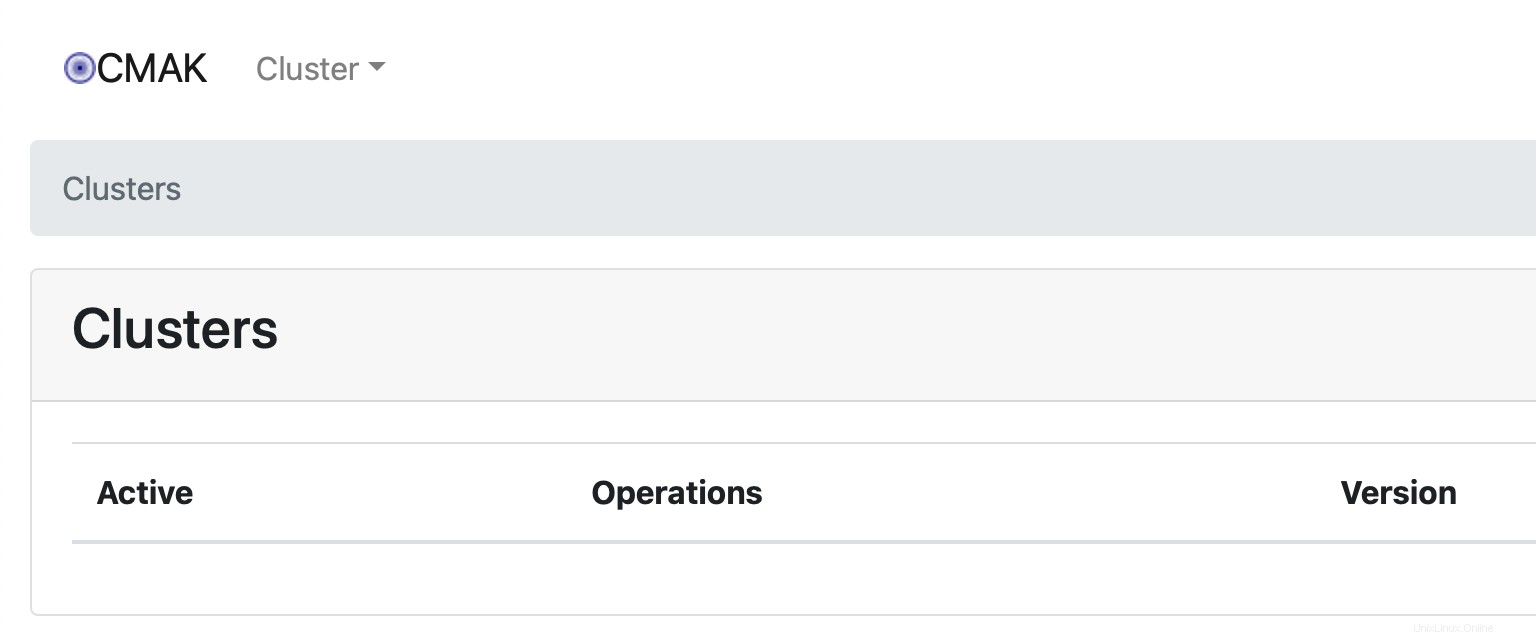
Derzeit ist kein Cluster verfügbar. Wir müssen einen neuen hinzufügen, indem wir auf Cluster hinzufügen klicken auf Cluster Dropdown-Liste.
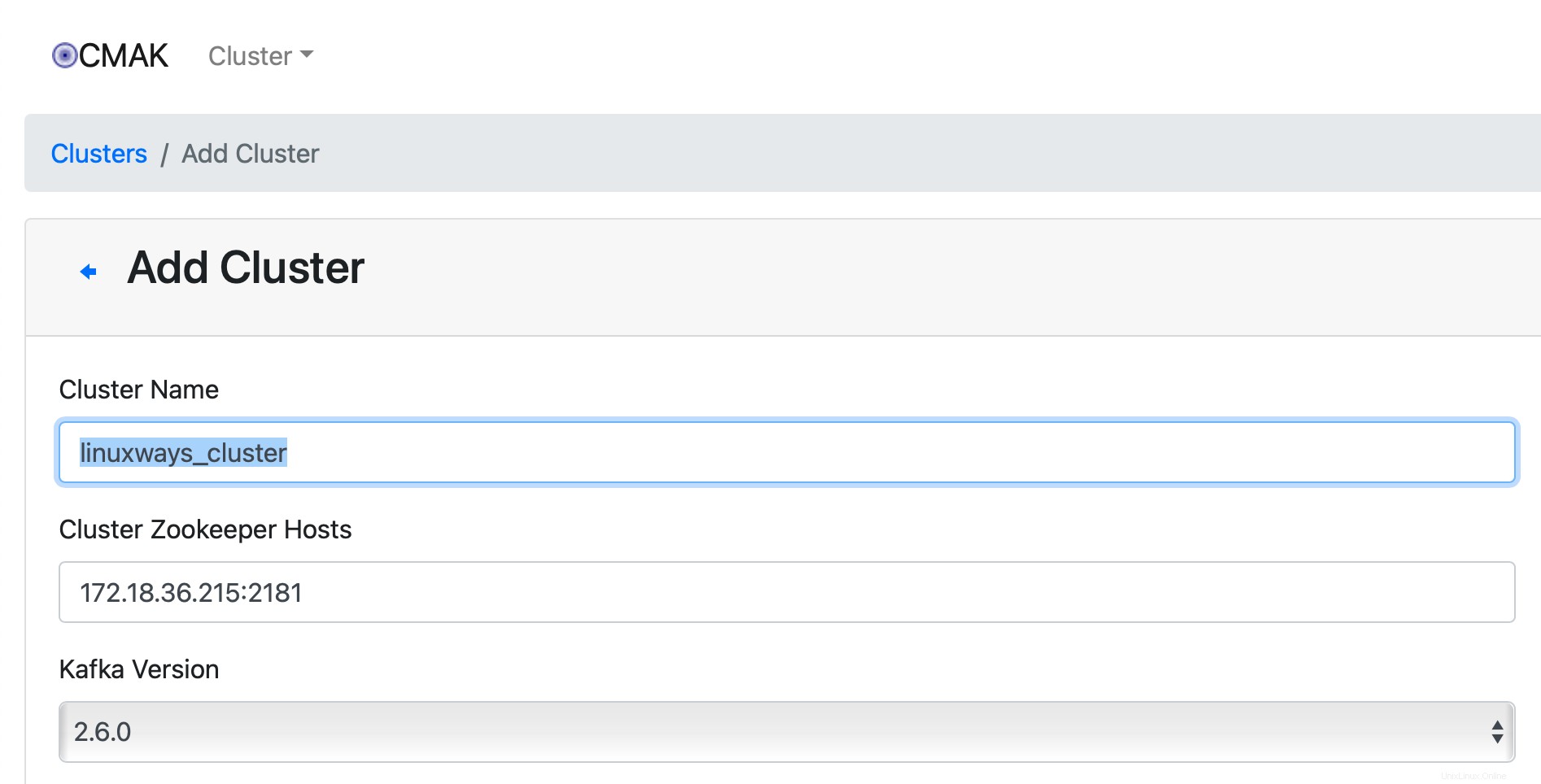
Füllen Sie dann das folgende Formular mit den erforderlichen Informationen aus:Clustername, Cluster-Zookeeper-Hosts, Kafka-Version und so weiter. Zum Beispiel:
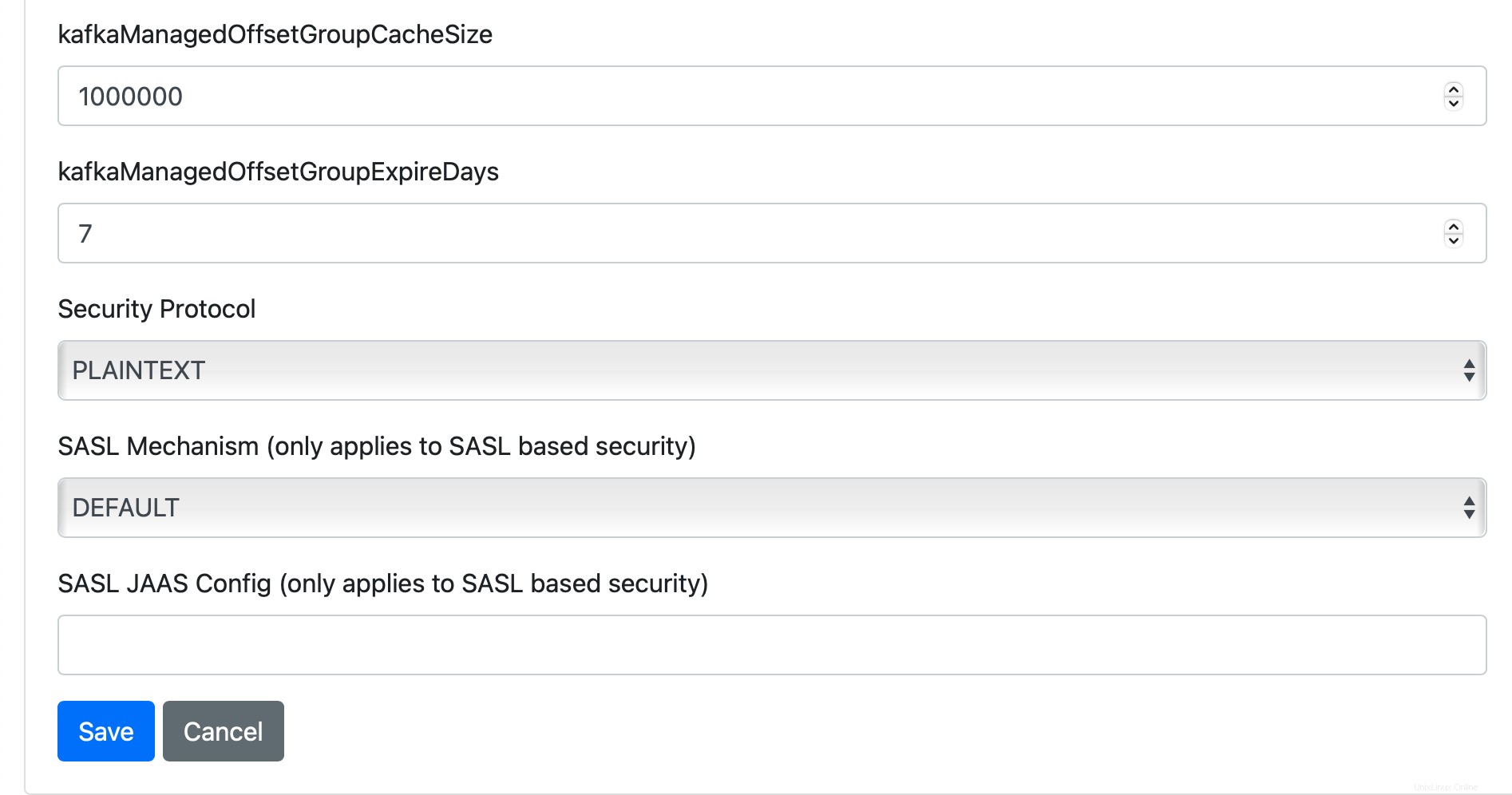
Belassen Sie andere Optionen mit ihren Standardwerten und klicken Sie dann auf Speichern.
Erledigt. Der Cluster wurde erfolgreich erstellt.
Jetzt ist es an der Zeit, ein Beispielthema zu erstellen. Angenommen, wir erstellen ein Thema mit dem Namen „LinuxWaysTopic“. Denken Sie daran, dass der CMAK noch ausgeführt wird, starten Sie ein neues Terminal und führen Sie dann den folgenden Befehl aus:
$ cd /usr/local/kafka-server/kafka-2.7.0-src
$ bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic LinuxWaysTopic
Ausgabe:

Wechseln Sie zur Clusteransicht und klicken Sie dann auf Thema> Liste
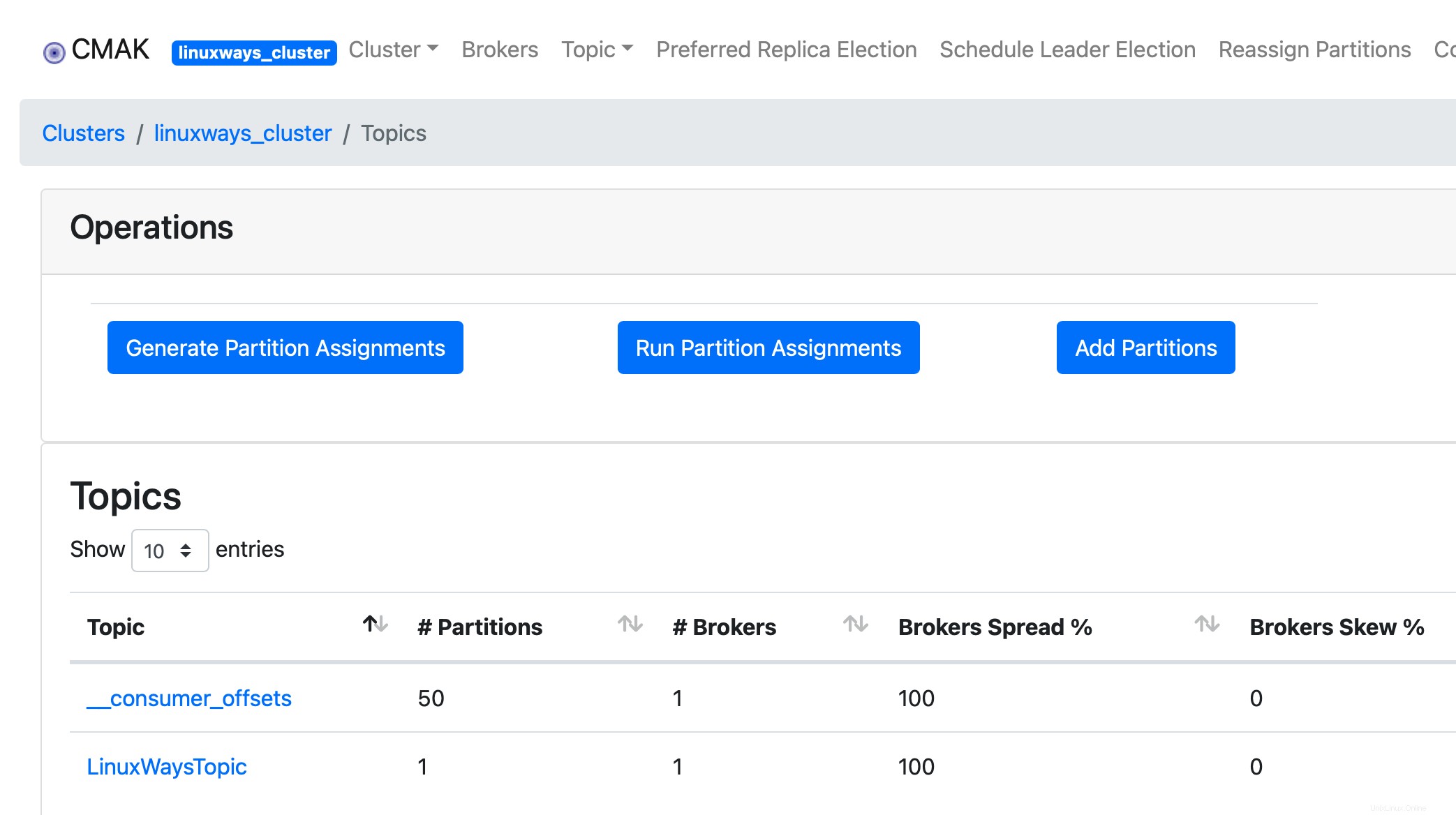
Schlussfolgerung
Sie haben Apache Kafka erfolgreich auf Ihrem Ubuntu 20.04 LTS-Rechner installiert und konfiguriert.
Wenn Sie Bedenken haben, können Sie gerne einen Kommentar hinterlassen und mich wissen lassen. Vielen Dank!