Apache Kafka ist eine verteilte Streaming-Plattform. Es ist nützlich, um Echtzeit-Streaming-Datenpipelines zu erstellen, um Daten zwischen den Systemen oder Anwendungen abzurufen. Eine weitere nützliche Funktion sind Echtzeit-Streaming-Anwendungen, die Datenströme transformieren oder auf einen Datenstrom reagieren können. Dieses Tutorial hilft Ihnen bei der Installation von Apache Kafka auf Ubuntu 19.10-, 18.04- und 16.04-Systemen.
Schritt 1 – Java installieren
Apache Kafka erforderte Java, um ausgeführt zu werden. Auf Ihrem System muss Java installiert sein. Führen Sie den folgenden Befehl aus, um das standardmäßige OpenJDK von den offiziellen PPAs auf Ihrem System zu installieren. Sie können auch die spezifische Version von hier installieren.
sudo apt update sudo apt install default-jdk
Schritt 2 – Laden Sie Apache Kafka herunter
Laden Sie die Apache Kafka-Binärdateien von der offiziellen Download-Website herunter. Sie können auch jeden Spiegel in der Nähe zum Herunterladen auswählen.
wget https://www.apache.org/dist/kafka/2.7.0/kafka_2.13-2.7.0.tgz
Extrahieren Sie dann die Archivdatei
tar xzf kafka_2.13-2.7.0.tgz mv kafka_2.13-2.7.0 /usr/local/kafka
Schritt 3 – Kafka Systemd Unit-Dateien einrichten
Erstellen Sie als Nächstes systemd-Unit-Dateien für den Zookeeper- und Kafka-Dienst. Dies hilft bei der Verwaltung von Kafka-Diensten zum Starten/Stoppen mit dem Befehl systemctl.
Erstellen Sie zuerst eine systemd-Unit-Datei für Zookeeper mit dem folgenden Befehl:
vim /etc/systemd/system/zookeeper.service
Fügen Sie unten den Inhalt hinzu:
[Unit] Description=Apache Zookeeper server Documentation=http://zookeeper.apache.org Requires=network.target remote-fs.target After=network.target remote-fs.target [Service] Type=simple ExecStart=/usr/local/kafka/bin/zookeeper-server-start.sh /usr/local/kafka/config/zookeeper.properties ExecStop=/usr/local/kafka/bin/zookeeper-server-stop.sh Restart=on-abnormal [Install] WantedBy=multi-user.target
Speichern Sie die Datei und schließen Sie sie.
Als Nächstes erstellen Sie mit dem folgenden Befehl eine Kafka-Systemd-Unit-Datei:
vim /etc/systemd/system/kafka.service
Fügen Sie den folgenden Inhalt hinzu. Achten Sie darauf, das richtige JAVA_HOME einzustellen Pfad gemäß dem auf Ihrem System installierten Java.
[Unit] Description=Apache Kafka Server Documentation=http://kafka.apache.org/documentation.html Requires=zookeeper.service [Service] Type=simple Environment="JAVA_HOME=/usr/lib/jvm/java-1.11.0-openjdk-amd64" ExecStart=/usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties ExecStop=/usr/local/kafka/bin/kafka-server-stop.sh [Install] WantedBy=multi-user.target
Datei speichern und schließen.
Laden Sie den systemd-Daemon neu, um neue Änderungen zu übernehmen.
systemctl daemon-reload
Schritt 4 – Kafka-Server starten
Kafka benötigte ZooKeeper, also starten Sie zuerst einen ZooKeeper-Server auf Ihrem System. Sie können das mit Kafka verfügbare Skript verwenden, um eine Einzelknoten-ZooKeeper-Instanz zu starten.
sudo systemctl start zookeeper
Starten Sie nun den Kafka-Server und sehen Sie sich den laufenden Status an:
sudo systemctl start kafka sudo systemctl status kafka
Alles erledigt. Die Kafka-Installation wurde erfolgreich abgeschlossen. Dieser Teil dieses Tutorials hilft Ihnen bei der Arbeit mit dem Kafka-Server.
Schritt 5 – Erstellen Sie ein Thema in Kafka
Kafka bietet mehrere vorgefertigte Shell-Skripte, um daran zu arbeiten. Erstellen Sie zunächst ein Thema mit dem Namen „testTopic“ mit einer einzelnen Partition mit einer einzigen Replik:
cd /usr/local/kafka bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic testTopic Created topic testTopic.
Der Replikationsfaktor beschreibt, wie viele Kopien von Daten erstellt werden. Da wir mit einer einzelnen Instanz arbeiten, belassen Sie diesen Wert bei 1.
Legen Sie die Partitionsoptionen als die Anzahl der Broker fest, auf die Ihre Daten aufgeteilt werden sollen. Da wir mit einem einzelnen Broker arbeiten, belassen Sie diesen Wert bei 1.
Sie können mehrere Themen erstellen, indem Sie denselben Befehl wie oben ausführen. Danach können Sie die erstellten Themen auf Kafka mit dem folgenden Befehl anzeigen:
bin/kafka-topics.sh --list --zookeeper localhost:2181 testTopic TecAdminTutorial1 TecAdminTutorial2
Anstatt Themen manuell zu erstellen, können Sie alternativ Ihre Broker auch so konfigurieren, dass Themen automatisch erstellt werden, wenn ein nicht vorhandenes Thema veröffentlicht wird.
Schritt 6 – Nachrichten an Kafka senden
Der „Produzent“ ist der Prozess, der dafür verantwortlich ist, Daten in unser Kafka einzufügen. Kafka wird mit einem Befehlszeilenclient geliefert, der Eingaben aus einer Datei oder von der Standardeingabe entgegennimmt und als Nachrichten an den Kafka-Cluster sendet. Das Standard-Kafka sendet jede Zeile als separate Nachricht.
Lassen Sie uns den Producer ausführen und dann einige Nachrichten in die Konsole eingeben, um sie an den Server zu senden.
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic testTopic >Welcome to kafka >This is my first topic >
Sie können diesen Befehl beenden oder dieses Terminal für weitere Tests weiter ausführen. Öffnen Sie nun im nächsten Schritt ein neues Terminal für den Kafka-Verbraucherprozess.
Schritt 7 – Verwendung von Kafka Consumer
Kafka hat auch einen Befehlszeilenkonsumenten, um Daten aus dem Kafka-Cluster zu lesen und Meldungen auf der Standardausgabe anzuzeigen.
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic testTopic --from-beginning Welcome to kafka This is my first topic
Nun, wenn Sie noch Kafka Producer (Schritt #6) in einem anderen Terminal ausführen. Geben Sie einfach einen Text auf diesem Producer-Terminal ein. es wird sofort auf dem Endgerät des Verbrauchers sichtbar. Sehen Sie sich den folgenden Screenshot des Kafka-Produzenten und -Konsumenten in Arbeit an:
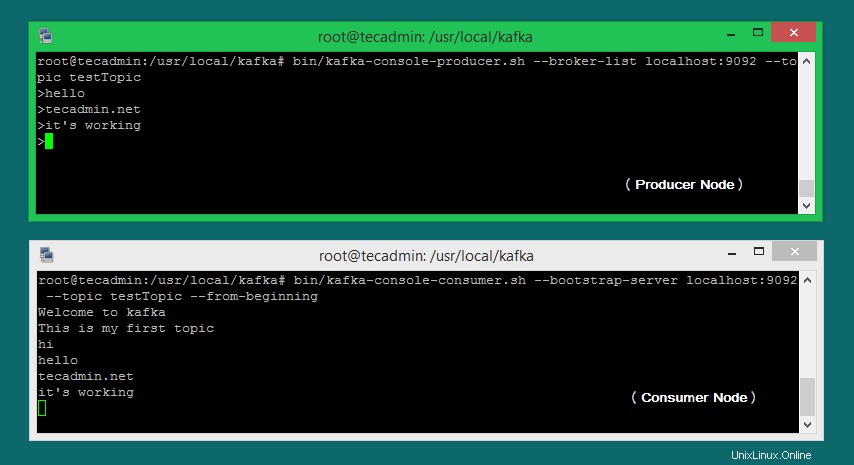
Schlussfolgerung
Sie haben den Kafka-Dienst erfolgreich auf Ihrem Ubuntu-Linux-Rechner installiert und konfiguriert.