Apache Spark ist ein Open-Source-Berechnungsframework für umfangreiche Analysedaten und maschinelle Lernverarbeitung. Es unterstützt verschiedene bevorzugte Sprachen wie Scala, R, Python und Java. Es bietet High-Level-Tools für Spark-Streaming, GraphX für die Graphverarbeitung, SQL, MLLib.
In diesem Artikel erfahren Sie, wie Sie Apache Spark auf Ubuntu installieren und konfigurieren. Um den Ablauf in diesem Artikel zu demonstrieren, habe ich das Ubuntu 20.04 LTS-Versionssystem verwendet. Vor der Installation von Apache Spark müssen Sie Scala sowie Scala auf Ihrem System installieren.
Scala installieren
Wenn Sie Java und Scala nicht installiert haben, können Sie den folgenden Prozess befolgen, um es zu installieren.
Für Java installieren wir Open JDK 8 oder Sie können Ihre bevorzugte Version installieren.
$ sudo apt update
$ sudo apt install openjdk-8-jdk
Wenn Sie die Java-Installation überprüfen müssen, können Sie den folgenden Befehl ausführen.
$ java -version

Was Scala betrifft, so ist Scala eine objektorientierte und funktionale Programmiersprache, die sie zu einer einzigen prägnanten kombiniert. Scala ist sowohl mit der Javascript-Laufzeit als auch mit JVM kompatibel und gewährt Ihnen einfachen Zugriff auf das große Bibliotheken-Ökosystem, das beim Aufbau eines Hochleistungssystems hilft. Führen Sie den folgenden apt-Befehl aus, um Scala zu installieren.
$ sudo apt update
$ sudo apt install scala
Überprüfen Sie nun die Version, um die Installation zu überprüfen.
$ scala -version

Installieren von Apache Spark
Es gibt kein offizielles apt-Repository, um Apache-Spark zu installieren, aber Sie können die Binärdatei von der offiziellen Website vorkompilieren. Verwenden Sie den folgenden wget-Befehl und Link, um die Binärdatei herunterzuladen.
$ wget https://downloads.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
Extrahieren Sie nun die heruntergeladene Binärdatei mit dem folgenden tar-Befehl.
$ tar -xzvf spark-3.1.2-bin-hadoop3.2.tgz
Verschieben Sie zuletzt die extrahierten Spark-Dateien in das Verzeichnis /opt.
$ sudo mv spark-3.1.2-bin-hadoop3.2 /opt/spark
Umgebungsvariablen einrichten
Ihre Pfadvariable für Spark in Ihrer .profile in der Datei, die eingerichtet werden muss, damit der Befehl ohne vollständigen Pfad funktioniert, können Sie entweder mit dem echo-Befehl oder manuell mit einem bevorzugten Texteditor tun. Führen Sie für einen einfacheren Weg den folgenden Echo-Befehl aus.
$ echo "export SPARK_HOME=/opt/spark" >> ~/.profile
$ echo "export PATH=$PATH:/opt/spark/bin:/opt/spark/sbin" >> ~/.profile
$ echo "export PYSPARK_PYTHON=/usr/bin/python3" >> ~/.profile
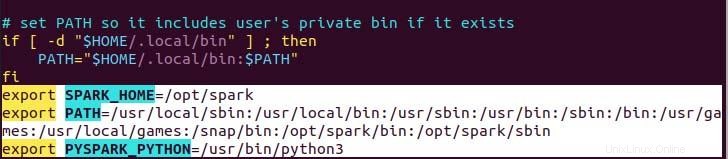
Wie Sie sehen können, wird die Pfadvariable am Ende der .profile-Datei mithilfe von echo with>> operation.
angehängtFühren Sie nun den folgenden Befehl aus, um die neuen Änderungen der Umgebungsvariablen anzuwenden.
$ source ~/.profile
Bereitstellen von Apache Spark
Jetzt haben wir alles eingerichtet, was wir können, um sowohl den Master-Dienst als auch den Worker-Dienst mit dem folgenden Befehl auszuführen.
$ start-master.sh
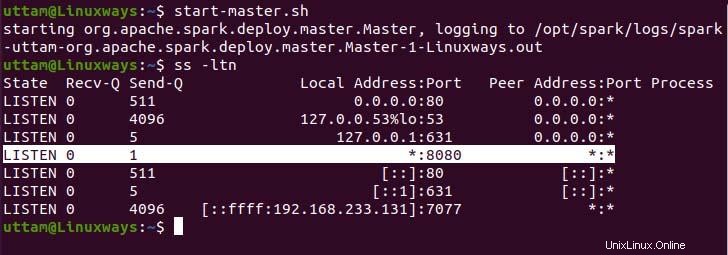
Wie Sie sehen können, läuft unser Spark-Master-Dienst auf Port 8080. Wenn Sie den localhost auf Port 8080 durchsuchen, ist dies der Standardport von spark. Beim Durchsuchen der URL können Sie auf die folgende Art von Benutzeroberfläche stoßen. Möglicherweise finden Sie keinen laufenden Worker-Prozessor, wenn Sie nur den Master-Dienst starten. Wenn Sie den Worker-Dienst starten, werden Sie genau wie im folgenden Beispiel einen neuen Knoten aufgelistet finden.
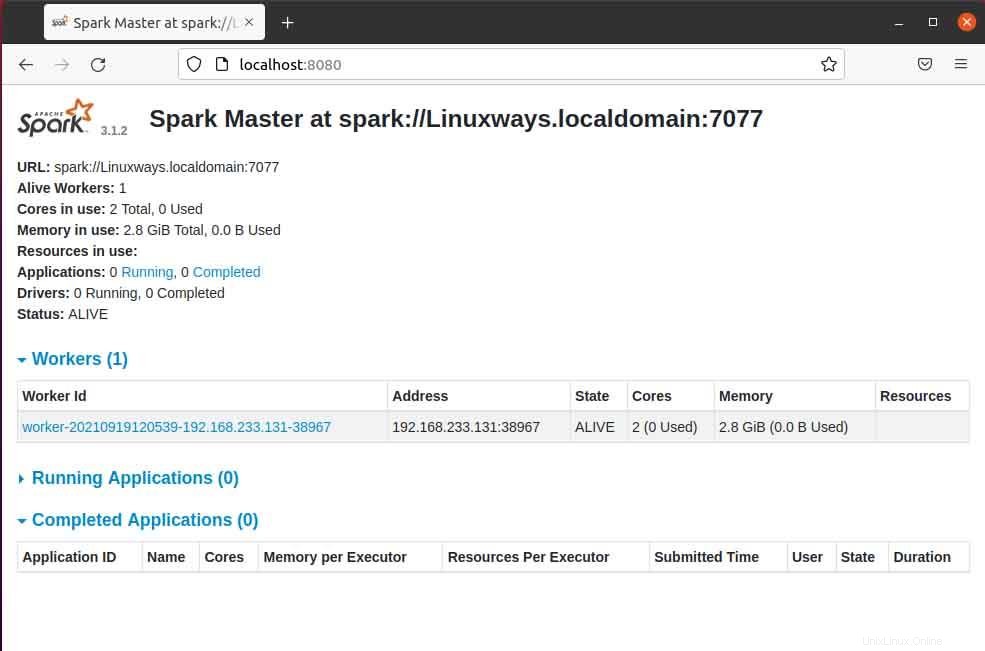
Wenn Sie die Masterseite im Browser öffnen, können Sie die Spark-Master-URL spark://HOST:PORT sehen, die verwendet wird, um die Worker-Dienste über diesen Host zu verbinden. Für meinen aktuellen Host lautet meine Spark-Master-URL spark://Linuxways.localdomain:7077, daher müssen Sie den Befehl folgendermaßen ausführen, um den Arbeitsprozess zu starten.
$ start-workers.sh <spark-master-url>
So führen Sie den folgenden Befehl aus, um die Worker-Dienste auszuführen.
$ start-workers.sh spark://Linuxways.localdomain:7077

Außerdem können Sie Spark-Shell verwenden, indem Sie den folgenden Befehl ausführen.
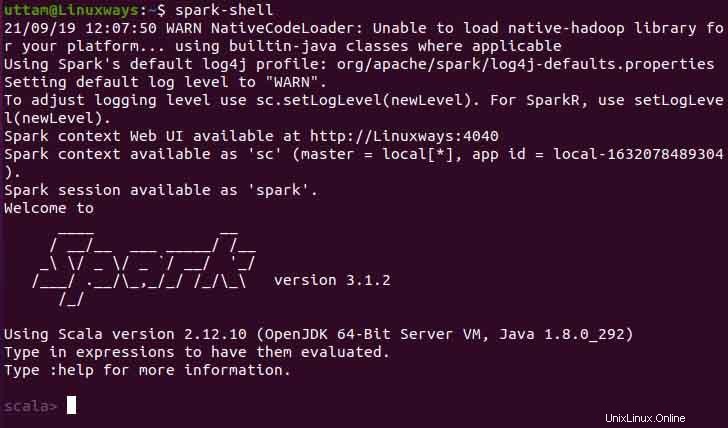
$ spark-shell
Schlussfolgerung
Ich hoffe, dass Sie aus diesem Artikel erfahren, wie Sie Apache Spark unter Ubuntu installieren und konfigurieren. In diesem Artikel habe ich versucht, den Prozess so verständlich wie möglich zu machen.