Aktualisierte Antwort im Jahr 2020 :
Laut @Owens Antwort ist ORC als eigenes Apache-Projekt erwachsen und gereift. Eine vollständige Liste der ORC-Anwender zeigt, wie weit verbreitet es jetzt von vielen Arten von Big-Data-Technologien unterstützt wird.
Vielen Dank an @Owen und das ORC-Apache-Projektteam, die ORC-Projektwebsite verfügt über eine vollständig gepflegte, aktuelle Dokumentation zur Verwendung des eigenständigen Java- oder C++-Tools für ORC-Dateien, die auf einem lokalen Linux-Dateisystem gespeichert sind. Was die Fackel für die ursprüngliche Hive+ORC-Apache-Wiki-Seite weiterführte.
Ursprüngliche Antwort vom:May 30 '14 at 16:27
Das ORC-Datei-Dump-Dienstprogramm wird mit Hive (0.11 oder höher) geliefert:
hive --orcfiledump <hdfs-location-of-orc-file>
Quelllink
Es ist auch in der Lage, den Inhalt einer ORC-Datei von einer Desktop-Anwendung anzuzeigen, die unter Linux ausgeführt wird.
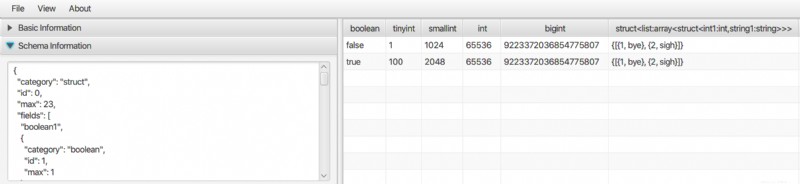
Es gibt eine Desktop-Anwendung, um Parquet und auch andere Binärformatdaten wie ORC und AVRO anzuzeigen. Es ist eine reine Java-Anwendung, die unter Linux, Mac und auch Windows ausgeführt werden kann. Weitere Informationen finden Sie im Bigdata File Viewer.
Es unterstützt komplexe Datentypen wie Array, Map, Struct usw.
Es gibt jetzt auch eine native ausführbare Datei für Linux und MacOS, die den Inhalt der orc-Datei in JSON druckt. Sehen Sie sich das ORC-Projekt (http://orc.apache.org/) an und erstellen Sie die C++-Tools.
% orc-contents examples/TestOrcFile.test1.orc
Es gibt auch ein natives Metadaten-Tool:
% orc-metadata ../examples/TestOrcFile.test1.orc
Das ORC-Projekt hat auch ein eigenständiges Uber-Jar, das dasselbe von Java aus tun kann.
% java -jar orc-tools-1.2.3-uber.jar data myfile.orc