In diesem Handbuch beschreiben wir die Zeichencodierung und behandeln einige Beispiele für die Konvertierung von Dateien von einer Zeichencodierung in eine andere mithilfe eines Befehlszeilentools. Zum Schluss schauen wir uns an, wie man mehrere Dateien aus einem beliebigen Zeichensatz (charset ) in UTF-8 Codierung unter Linux.
Wie Sie vielleicht schon wissen, versteht oder speichert ein Computer keine Buchstaben, Zahlen oder irgendetwas anderes, was wir als Menschen wahrnehmen können, außer Bits. Ein Bit hat nur zwei mögliche Werte, also entweder eine 0 oder 1 , true oder false , yes oder no . Alle anderen Dinge wie Buchstaben, Zahlen und Bilder müssen in Bits dargestellt werden, damit ein Computer sie verarbeiten kann.
Einfach ausgedrückt, Zeichenkodierung ist eine Möglichkeit, einem Computer mitzuteilen, wie er rohe Nullen und Einsen in tatsächliche Zeichen interpretieren soll, wobei ein Zeichen durch eine Reihe von Zahlen dargestellt wird. Wenn wir Text in eine Datei eingeben, werden die Wörter und Sätze, die wir bilden, aus verschiedenen Zeichen zusammengesetzt, und die Zeichen werden in einem Zeichensatz organisiert .
Es gibt verschiedene Kodierungsschemata wie ASCII , ANSI , Unicode unter anderen. Unten sehen Sie ein Beispiel für ASCII Codierung.
Character bits A 01000001 B 01000010
Unter Linux ist das iconv Befehlszeilentool wird verwendet, um Text von einer Form der Kodierung in eine andere zu konvertieren.
Sie können die Codierung einer Datei mit der Datei überprüfen Befehl, indem Sie den -i verwenden oder --mime Flag, das das Drucken von Mime-Type-Strings wie in den folgenden Beispielen ermöglicht:
$ file -i Car.java $ file -i CarDriver.java


Die Syntax für die Verwendung von iconv lautet wie folgt:
$ iconv option $ iconv options -f from-encoding -t to-encoding inputfile(s) -o outputfile
Wobei -f oder --from-code bedeutet Eingabekodierung und -t oder --to-encoding gibt die Ausgabecodierung an.
Führen Sie den folgenden Befehl aus, um alle bekannten codierten Zeichensätze aufzulisten:
$ iconv -l
Dateien von UTF-8 in ASCII-Kodierung konvertieren
Als nächstes lernen wir, wie man von einem Codierungsschema in ein anderes konvertiert. Der folgende Befehl konvertiert von ISO-8859-1 zu UTF-8 Codierung.
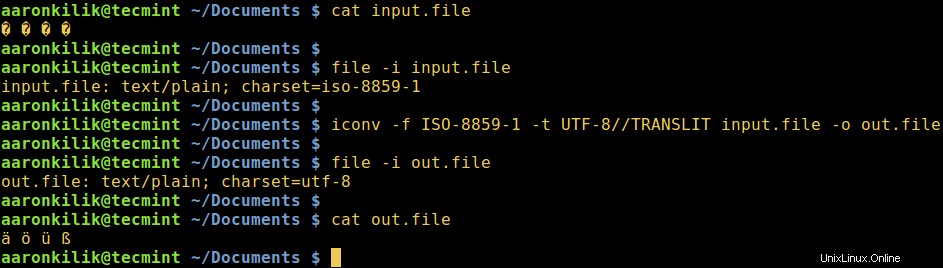
Stellen Sie sich eine Datei mit dem Namen input.file vor die die Zeichen enthält:
� � � �
Lassen Sie uns zunächst die Codierung der Zeichen in der Datei überprüfen und dann den Dateiinhalt anzeigen. Genau genommen können wir alle Zeichen in ASCII umwandeln Codierung.
Nach dem Ausführen des iconv Befehl, überprüfen wir dann den Inhalt der Ausgabedatei und die neue Kodierung der Zeichen wie unten.
$ file -i input.file $ cat input.file $ iconv -f ISO-8859-1 -t UTF-8//TRANSLIT input.file -o out.file $ cat out.file $ file -i out.file
Hinweis :Falls die Zeichenfolge //IGNORE wird zur Kodierung hinzugefügt, Zeichen, die nicht konvertiert werden können, und nach der Konvertierung wird ein Fehler angezeigt.
Nehmen wir wieder den String //TRANSLIT an wird wie im obigen Beispiel zur To-Kodierung hinzugefügt (ASCII//TRANSLIT ), konvertierte Zeichen werden nach Bedarf und nach Möglichkeit transkribiert. Das bedeutet, falls ein Zeichen im Zielzeichensatz nicht dargestellt werden kann, kann es durch ein oder mehrere ähnlich aussehende Zeichen angenähert werden.
Folglich wird jedes Zeichen, das nicht transliteriert werden kann und nicht im Zielzeichensatz enthalten ist, durch ein Fragezeichen (?) ersetzt in der Ausgabe.
Mehrere Dateien in UTF-8-Kodierung umwandeln
Zurück zu unserem Hauptthema:Um mehrere oder alle Dateien in einem Verzeichnis in UTF-8-Codierung zu konvertieren, können Sie ein kleines Shell-Skript namens encoding.sh schreiben wie folgt:
#!/bin/bash
#enter input encoding here
FROM_ENCODING="value_here"
#output encoding(UTF-8)
TO_ENCODING="UTF-8"
#convert
CONVERT=" iconv -f $FROM_ENCODING -t $TO_ENCODING"
#loop to convert multiple files
for file in *.txt; do
$CONVERT "$file" -o "${file%.txt}.utf8.converted"
done
exit 0
Speichern Sie die Datei und machen Sie das Skript dann ausführbar. Führen Sie es aus dem Verzeichnis aus, in dem Ihre Dateien (*.txt ) befinden.
$ chmod +x encoding.sh $ ./encoding.sh
Wichtig Hinweis:Sie können dieses Skript auch für die allgemeine Konvertierung mehrerer Dateien von einer bestimmten Kodierung in eine andere verwenden, spielen Sie einfach mit den Werten von FROM_ENCODING herum und TO_ENCODING Variable, nicht zu vergessen der Name der Ausgabedatei "${file%.txt}.utf8.converted" .
Weitere Informationen finden Sie unter iconv Manpage.
$ man iconv
Zusammenfassend lässt sich sagen, dass das Verstehen der Codierung und das Konvertieren von einem Zeichencodierungsschema in ein anderes für jeden Computerbenutzer und insbesondere für Programmierer im Umgang mit Text ein notwendiges Wissen ist.
Zu guter Letzt können Sie sich mit uns in Verbindung setzen, indem Sie den Kommentarbereich unten für Fragen oder Feedback verwenden.