Die Überwachung Ihres Kubernetes-Clusters ist entscheidend, um sicherzustellen, dass Ihre Dienste immer verfügbar sind und ausgeführt werden. Und bevor Sie das Internet nach einem Überwachungssystem durchsuchen, warum versuchen Sie es nicht mit Grafana und Prometheus Kubernetes Cluster Monitoring?
In diesem Leitfaden erfahren Sie, wie Sie Ihren Kubernetes-Cluster überwachen und interne Statusmetriken mit einem Prometheus- und Grafana-Dashboard anzeigen.
Lesen Sie weiter, damit Sie Ihre Ressourcen genau im Auge behalten können!
Voraussetzungen
- Ein Linux-Rechner mit installiertem Docker – Dieses Tutorial verwendet einen Ubuntu 20.04 LTS-Rechner mit Docker-Version 20.10.7. So installieren Sie Ubuntu.
- Ein Kubernetes-Cluster mit einem Knoten.
- Helm Package Manager installiert – Zur Bereitstellung des Prometheus-Operators.
- Die Kubectl-Befehlszeilenschnittstelle ist installiert und für Ihren Cluster konfiguriert.
Bereitstellen des Kube-Prometheus-Stack-Helm-Diagramms
Die Grafana- und Prometheus-Kubernetes-Cluster-Überwachung bietet Informationen zu potenziellen Leistungsengpässen, Clusterzustand und Leistungskennzahlen. Visualisieren Sie gleichzeitig die Netzwerknutzung, Ressourcennutzungsmuster von Pods und einen allgemeinen Überblick darüber, was in Ihrem Cluster vor sich geht.
Bevor Sie jedoch ein Überwachungssystem mit Grafana und Prometheus einrichten, stellen Sie zunächst das kube-prometheus-Stack-Helm-Diagramm bereit. Der Stapel enthält Prometheus, Grafana, Alertmanager, Prometheus-Operator und andere Überwachungsressourcen.
1. SSH in Ihren Ubuntu 20.04-Rechner (wenn Sie auf einem Cloud-Server laufen) oder melden Sie sich einfach bei Ihrem lokal installierten Ubuntu 20.04-Rechner an, um zu beginnen.
2. Führen Sie als Nächstes kubectl create aus Befehl unten, um eine namespace zu erstellen mit dem Namen monitoring für alle Bereitstellungen im Zusammenhang mit Prometheus und Grafana.
kubectl create namespace monitoring
3. Führen Sie den folgenden helm repo aus Befehle zum Hinzufügen der (prometheus-community ) Helm-Repository und aktualisieren Sie Ihr Helm-Repository.
# Add prometheus-community repo
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
# Update helm repo
helm repo update
4. Führen Sie nach dem Hinzufügen des Helm-Repositorys helm install aus Befehl unten, um das kube-prometheus-Stack-Helm-Diagramm bereitzustellen. Ersetzen Sie prometheus mit Ihrem gewünschten Release-Namen.
Dieses Helm-Diagramm richtet einen vollständigen Prometheus-Kubernetes-Überwachungsstapel ein, indem es auf der Grundlage einer Reihe von benutzerdefinierten Ressourcendefinitionen (CRDs) agiert.
helm install prometheus prometheus-community/kube-prometheus-stack --namespace monitoringSobald die Bereitstellung abgeschlossen ist, erhalten Sie die folgende Ausgabe.
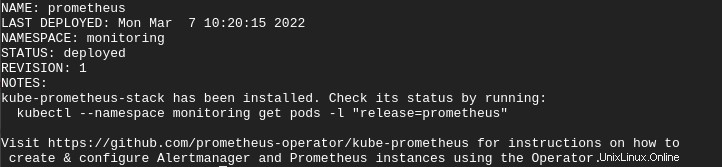
5. Führen Sie abschließend den folgenden Befehl aus, um Ihre kube-prometheus-Stack-Bereitstellung zu bestätigen.
kubectl get pods -n monitoringDie folgende Ausgabe zeigt die Bereitstellung des kube-prometheus-Stacks. Wie Sie sehen können, wird jede Komponente im Stack in Ihrem Cluster ausgeführt.

Zugriff auf die Prometheus-Instanz
Sie haben Ihre Prometheus-Instanz erfolgreich auf Ihrem Cluster bereitgestellt und sind fast bereit, Ihren Kubernetes-Cluster zu überwachen. Aber wie greifen Sie auf Ihre Prometheus-Instanz zu? Sie leiten einen lokalen Port 9090 weiter zu Ihrem Cluster über Ihren Prometheus-Dienst mit dem kubectl port-forward Befehl.
1. Führen Sie kubectl get aus Befehl unten, um alle Dienste im Überwachungs-Namespace anzuzeigen und nach Ihrem Prometheus-Dienst zu suchen.
kubectl get svc -n monitoringAlle im Monitoring-Namespace bereitgestellten Dienste werden unten angezeigt, einschließlich des Prometheus-Dienstes. Sie verwenden den Prometheus-Dienst, um die Portweiterleitung einzurichten, sodass auf Ihre Prometheus-Instanz außerhalb Ihres Clusters zugegriffen werden kann.

2. Führen Sie als Nächstes den folgenden kubectl port-forward aus Befehl zum Weiterleiten des lokalen Ports 9090 zu Ihrem Cluster über den Prometheus-Dienst (svc/prometheus-kube-prometheus-prometheus ).
kubectl port-forward svc/prometheus-kube-prometheus-prometheus -n monitoring 9090Wenn Sie jedoch einen Kubernetes-Cluster mit einem Knoten auf einem Cloud-Server ausführen, führen Sie stattdessen den folgenden Befehl aus.
kuebctl port-forward --address 0.0.0.0 svc/prometheus-kube-prometheus-prometheus -n monitoring 9090 Um den Befehl kubectl port-forward als Hintergrundprozess auszuführen und Ihr Terminal für die weitere Verwendung freizugeben, hängen Sie das &-Symbol am Ende des Befehls an. Drücken Sie anschließend die Tastenkombination Strg+C, um den Port-Weiterleitungs-Vordergrundprozess zu stoppen (dies hat keinen Einfluss auf den Port-Weiterleitungs-Hintergrundprozess).
3. Öffnen Sie Ihren bevorzugten Webbrowser und navigieren Sie zu einer der folgenden URLs, um auf Ihre Prometheus-Instanz zuzugreifen.
- Navigieren Sie zu http://localhost:9090 wenn Sie mit einem lokalen Ubuntu-Rechner folgen
- Navigieren Sie zur IP-Adresse Ihres Servers, gefolgt von Port 9090 (d. h. http://YOUR_SERVER_IP:9090) wenn Sie einen Cloud-Server verwenden.
Für dieses Tutorial wird Prometheus auf einem Cloud-Server ausgeführt.
Wenn Ihr Prometheus-Dienst funktioniert, erhalten Sie die folgende Seite in Ihrem Webbrowser.
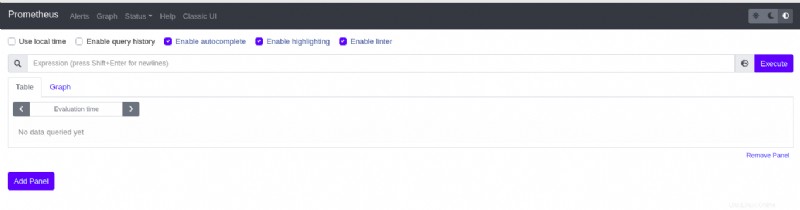
4. Drücken Sie abschließend auf Ihrem Terminal die Tastenkombination Strg+C, um den Portweiterleitungsprozess zu schließen. Dadurch wird Prometheus in Ihrem Browser unzugänglich.
Metriken zum internen Zustand des Prometheus Kubernetes-Clusters anzeigen
Das Anzeigen der internen Zustandsmetriken Ihres Kubernetes-Clusters wird mit dem Kube-State-Metrics (KSM)-Tool ermöglicht. Mit dem KSM-Tool können Sie den Zustand und die Nutzung Ihrer Ressourcen sowie interne Zustandsobjekte verfolgen. Einige der Datenpunkte, die möglicherweise über KSM angezeigt werden können, sind:Knotenmetriken, Bereitstellungsmetriken und Pod-Metriken.
Das KSM-Tool ist im kube-prometheus-Stack vorinstalliert und wird automatisch mit den übrigen Überwachungskomponenten bereitgestellt.
Sie leiten einen lokalen Port über kube-state-metrics an Ihren Cluster weiter Service. Dadurch kann KSM die internen Systemmetriken Ihres Clusters kratzen und eine Liste mit Abfragen und Werten ausgeben. Überprüfen Sie jedoch vor der Portweiterleitung zuerst Ihren KSM Kubernetes-Dienst.
1. Führen Sie den folgenden Befehl aus, um nach Ihrem kube-state-metrics zu suchen Kubernetes-Dienst.
kubectl get svc -n monitoring | grep kube-state-metricsUnten sehen Sie den Namen des KSM Kubernetes-Dienstes (prometheus-kube-state-metrics) zusammen mit der ClusterIP. Notieren Sie sich den Namen des KSM Kubernetes-Dienstes, da Sie ihn für die Portweiterleitung im nächsten Schritt benötigen.

2. Führen Sie als Nächstes den folgenden Befehl zu port-forward aus die prometheus-kube-state-metrics Dienst an Port 8080 .
kubectl port-forward svc/prometheus-kube-state-metrics -n monitoring 8080 Wenn Sie dieses Tutorial mit einem Ubuntu 20.04-Rechner befolgen, der von einem Cloud-Anbieter gehostet wird, fügen Sie das Flag (–address 0.0.0.0) zum Befehl kubectl port-forward hinzu. Dadurch wird der externe Zugriff auf den lokalen Port über die öffentliche IP-Adresse Ihres Servers ermöglicht.
3. Navigieren Sie schließlich in Ihrem Webbrowser zu einer der folgenden URLs, um die Seite Kube Metrics anzuzeigen, wie unten gezeigt.
- Navigieren Sie zu http://localhost:8080 wenn Sie sich auf einem lokalen Ubuntu-Rechner befinden
- Navigieren Sie zur IP-Adresse Ihres Servers, gefolgt von Port 8080 (d. h. http://YOUR_SERVER_IP:8080) wenn Sie einen Cloud-Server verwenden.
Klicken Sie auf den Metriklink, um auf die internen Zustandsmetriken Ihres Clusters zuzugreifen.

Unten sehen Sie Metriken für den internen Status eines Clusters, die Ihren ähnlich sind.
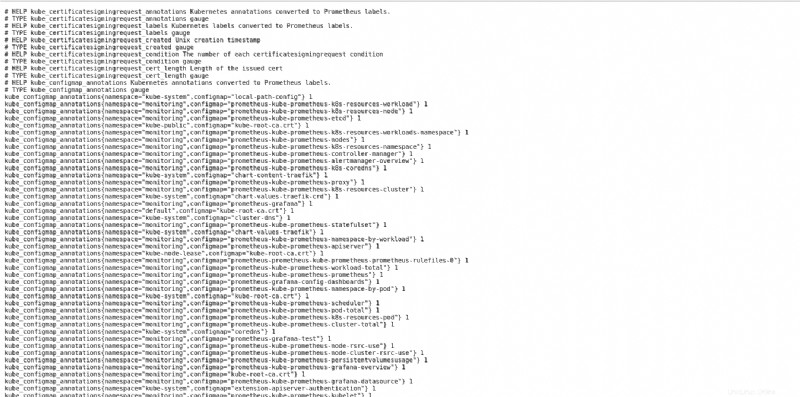
Visualisierung der internen Zustandsmetrik eines Clusters auf Prometheus
Sie haben die Helm-Chart-Bereitstellung, das Scraping von Kube-State-Metrics und Prometheus-Auftragskonfigurationen erfolgreich durchgeführt. Infolgedessen wurden CoreDNS, Kube-API-Server, Prometheus-Operator und andere Kubernetes-Komponenten automatisch als Ziele auf Prometheus eingerichtet.
1. Navigieren Sie entweder zu http://localhost:9090/targets oder http://
Durch den Zugriff auf den Endpunkt können Sie auch überprüfen, ob Prometheus seine Metriken auswertet und die Daten in einer Time-Series Database (TSDB) speichert,
Denken Sie daran, Prometheus wie im Abschnitt „Zugriff auf die Prometheus-Instanz“ in Schritt 2 gezeigt weiterzuleiten, bevor Sie zum Endpunkt navigieren. Sie können es auch als Hintergrundprozess ausführen.
Wie Sie unten sehen können, werden verschiedene interne Kubernetes-Komponenten und Überwachungskomponenten als Ziele auf Prometheus konfiguriert.
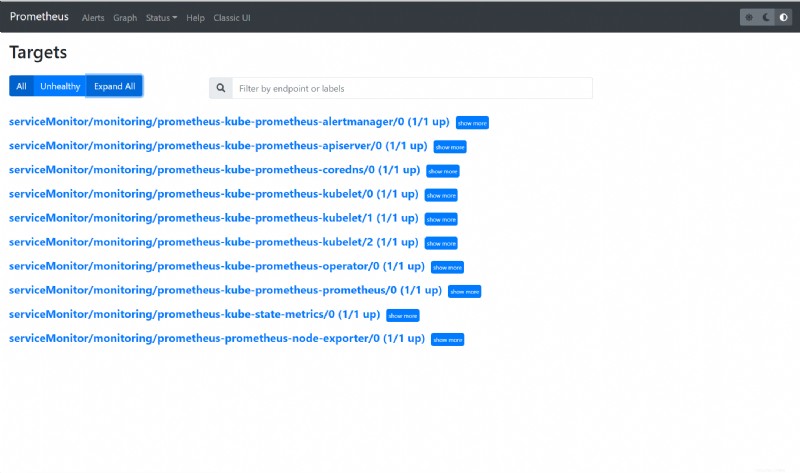
2. Klicken Sie auf das Diagramm Menü, um zu einer Seite zu gelangen, auf der Sie eine PromQL-Abfrage (Prometheus Query Language) ausführen.

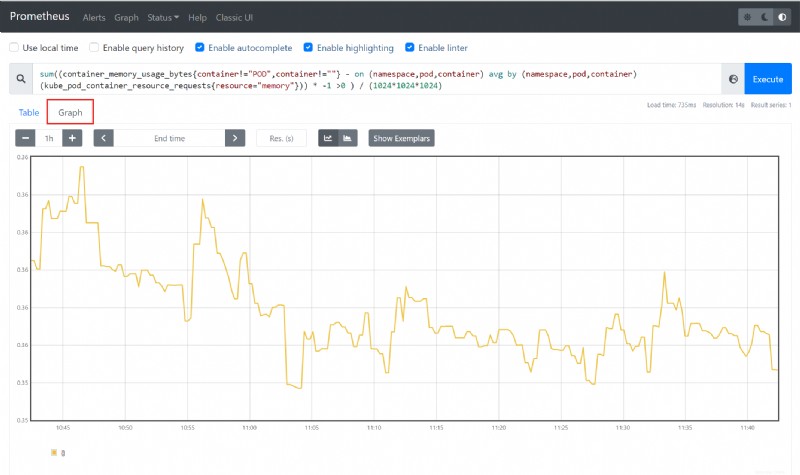
3. Fügen Sie das PromQL-Beispiel (Prometheus Query Language) ein Abfrage unten in den dafür vorgesehenen Ausdrucksbereich ein und klicken Sie dann auf Ausführen. Die Abfrage gibt die Gesamtmenge des ungenutzten Speichers in Ihrem Cluster zurück.
sum((container_memory_usage_bytes{container!="POD",container!=""} - on (namespace,pod,container) avg by (namespace,pod,container)(kube_pod_container_resource_requests{resource="memory"})) * -1 >0 ) / (1024*1024*1024)
4. Um die Ergebnisse der in Schritt 3 ausgeführten PromQL-Abfrage in einem grafischen Format anzuzeigen, klicken Sie auf Grafik . Dieses Diagramm zeigt die Gesamtmenge des ungenutzten Arbeitsspeichers in Ihrem Cluster zu einem bestimmten Zeitpunkt an.
Wenn alles richtig eingerichtet ist, sollte der Beispiel-Cluster-Messwert ähnlich wie in der Grafik unten aussehen.
Zugriff auf das Grafana-Dashboard
Sie haben vielleicht bemerkt, dass die Visualisierungsmöglichkeiten von Prometheus begrenzt sind, da Sie nur mit einem Diagramm festsitzen Möglichkeit. Prometheus eignet sich hervorragend zum Scrapen von Metriken von Zielen, die als Jobs konfiguriert sind, zum Aggregieren dieser Metriken und zum Speichern in einer TSDB lokal auf dem Ubuntu-Computer. Aber wenn es um die Standard-Ressourcenüberwachung geht, sind Prometheus und Grafana ein großartiges Duo.
Prometheus aggregiert die von den Serverkomponenten wie Node-Exporter, CoreDNS usw. exportierten Metriken. Grafana, dessen Stärke in der Visualisierung liegt, erhält diese Metriken von Prometheus und zeigt sie über zahlreiche Visualisierungsoptionen an.
Während der kube-prometheus-Stack-Helm-Bereitstellung wurde Grafana automatisch installiert und konfiguriert, sodass Sie den Zugriff auf Grafana in Ihrem Cluster konfigurieren können.
Um auf Ihr Grafana-Dashboard zuzugreifen, müssen Sie zuerst Ihren Benutzernamen und Ihr Passwort abrufen, die als Secrets gespeichert sind, die automatisch standardmäßig in Ihrem Kubernetes-Cluster erstellt werden.
1. Führen Sie den folgenden kubectl aus Befehl zum Anzeigen von Daten, die als secret gespeichert sind in Ihrem Kubernetes-Cluster (prometheus-grafana ) im YAML-Format (-o yaml ).
kubectl get secret -n monitoring prometheus-grafana -o yamlWie Sie unten sehen, sind der Benutzername und das Passwort für den Zugriff auf Ihr Grafana-Dashboard in base64 codiert. Notieren Sie sich die Werte von Admin-Passwort und Admin-Benutzer Geheimnisse, da Sie sie im nächsten Schritt entschlüsseln müssen.
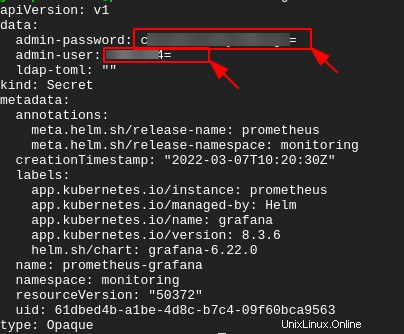
2. Führen Sie als Nächstes jeden der folgenden Befehle zu --decode aus beide Geheimnisse (admin-password und admin-user ). Ersetzen Sie YOUR_USERNAME , und YOUR_PASSWORD mit dem admin-password und admin-user geheime Werte, die Sie in Schritt eins notiert haben.
Dieses Tutorial hat aus Sicherheitsgründen keine Ausgabe für jeden Befehl.
# Decode and print the username
echo YOUR_USERNAME | base64 --decode
# Decode and print the password
echo YOUR_PASSWORD | base64 --decode
3. Führen Sie kubectl aus Befehl unten an port-forward zu einem lokalen Port unter 3000 durch Binden des Grafana-Ports 80 an Port 3000 . Dadurch erhalten Sie Zugriff auf die Web-Benutzeroberfläche von Grafana in Ihrem Browser.
kubectl port-forward svc/prometheus-grafana -n monitoring 3000:80Fügen Sie das Flag –address 0.0.0.0 hinzu, wenn Sie weiterhin einen von einem Cloud-Anbieter gehosteten Ubuntu 20.04-Computer verwenden.
4. Navigieren Sie schließlich in Ihrem Browser zu einem der folgenden Endpunkte, je nach Konfiguration Ihres Computers:
- http://localhost:3000 (lokal)
- oder http://
:3000 (Wolke)
Geben Sie Ihren entschlüsselten geheimen Wert für Admin-Benutzer und Admin-Passwort in den Benutzernamen und das Passwort in das dafür vorgesehene Feld ein.
Sobald Sie angemeldet sind, erhalten Sie das Grafana-Dashboard, wie unten gezeigt.
Interaktion mit Grafana
Standardmäßig stellt der Kube-Prometheus-Stack Grafana mit einigen vorkonfigurierten Dashboards für jedes in Prometheus konfigurierte Ziel bereit. Mit diesen vorkonfigurierten Dashboards müssen Sie kein Dashboard manuell einrichten, um jede von Prometheus aggregierte Metrik zu visualisieren.
Klicken Sie auf das Dashboard-Symbol —> Durchsuchen und Ihr Browser leitet zu einer Seite weiter, auf der Sie eine Liste mit Dashboards sehen (Schritt zwei).
Klicken Sie auf eines der vorkonfigurierten Dashboards unten, um seine visuelle Rechenressource anzuzeigen. Aber für diese Anleitung klicken Sie auf Kubernetes/Compute-Ressourcen/Namespace (Pods) Dashboard.
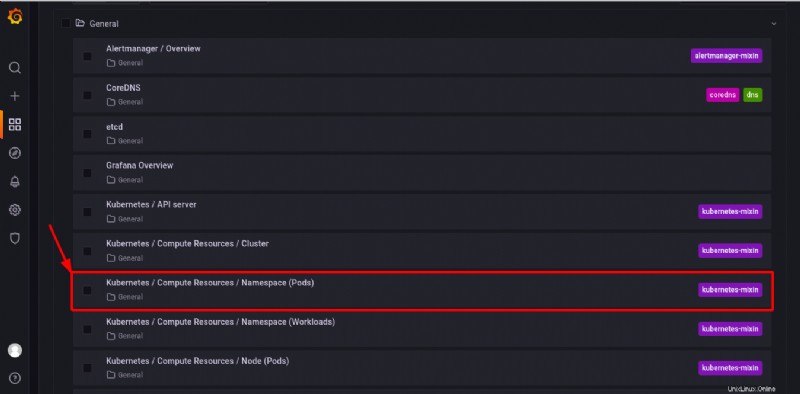
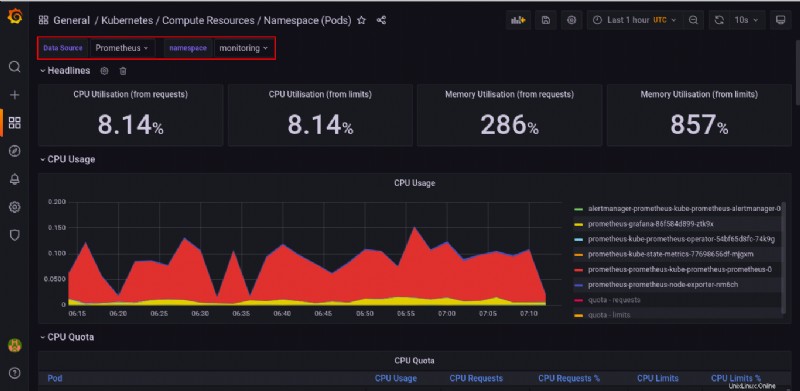
Unten finden Sie ein Beispiel für ein vorkonfiguriertes Dashboard zur Visualisierung der Rechenressourcennutzung durch Pods in einem der verfügbaren Namespaces.
Für diese Anleitung die Datenquelle wurde auf Prometheus gesetzt und der Namespace für die Visualisierung ist auf Überwachung eingestellt .
Schlussfolgerung
In diesem Tutorial haben Sie gelernt, wie Sie den Prometheus-Operator mithilfe von Helm bereitstellen und Ihre Cluster-internen Zustandsmetriken angezeigt haben, um Ihren Kubernetes-Cluster zu überwachen. Sie haben auch Grafana konfiguriert und Ihre Cluster-Metriken angezeigt, indem Sie Ihr Grafana-Dashboard konfiguriert haben.
Zu diesem Zeitpunkt verfügen Sie bereits über ein voll funktionsfähiges Kubernetes-Cluster-Monitoring. Aber Sie können dieses neu gewonnene Wissen persönlich verbessern, indem Sie beispielsweise Alertmanager mit Slack konfigurieren, um Echtzeit-Warnungen zu erhalten.