Elastic Kubernetes Service (EKS) ist ein verwalteter Kubernetes-Service, der auf AWS gehostet wird.
Der Hauptgrund für die Verwendung von EKS besteht darin, die Last der Verwaltung von Pods, Knoten usw. zu verringern. Der Betrieb von Kubernetes in AWS erfordert derzeit viel technisches Fachwissen und fällt oft außerhalb des Steuerhauses vieler Organisationen. Bei EKS wird die erforderliche Infrastruktur vom „hausinternen“ Team von Amazon verwaltet, sodass Benutzern eine vollständig verwaltete Kubernetes-Engine zur Verfügung steht, die entweder über eine API oder standardmäßige kubectl-Tools verwendet werden kann.
EKS unterstützt alle Kubernetes-Funktionen, einschließlich Namespaces, Sicherheitseinstellungen, Ressourcenkontingente und -toleranzen, Bereitstellungsstrategien, Autoscaler und mehr. EKS ermöglicht es Ihnen, Ihre eigene Steuerungsebene auszuführen, lässt sich aber auch in AWS IAM integrieren, sodass Sie Ihre eigene Zugriffskontrolle auf die API beibehalten können.
EKS wurde auf der bestehenden „Kubernetes-as-a-Service“-Lösung von Amazon namens Elastic Container Service for Kubernetes (EKS) aufgebaut und ist ein von AWS verwalteter Service, der die Bereitstellung, Verwaltung und den Betrieb von Kubernetes-Clustern in der AWS Cloud vereinfacht.
Wenn Sie Kubernetes auf AWS ausführen, sind Sie für die Verwaltung der Steuerungsebene (d. h. Master-Knoten und Worker-Knoten) verantwortlich. Sie müssen auch sicherstellen, dass api-server hochverfügbar und fehlertolerant ist usw.
EKS hat Ihnen die Last der Verwaltung der Steuerungsebene abgenommen, sodass Sie sich jetzt auf die Ausführung Ihrer Kubernetes-Workloads konzentrieren können. Es wird am häufigsten für zustandslose Anwendungen wie Microservices verwendet, da die Steuerungsebene von Amazon (EKS) verwaltet wird.
In diesem Leitfaden erfahren Sie, wie Sie mit EKS einen Kubernetes-Cluster auf AWS erstellen. Sie erfahren, wie Sie einen administrativen Benutzer für Ihren Kubernetes-Cluster erstellen. Außerdem erfahren Sie, wie Sie eine App im Cluster bereitstellen. Abschließend testen Sie Ihren Cluster, um sicherzustellen, dass alles ordnungsgemäß funktioniert.
Fangen wir an!
Voraussetzungen
- Ein AWS-Konto.
- Der Artikel setzt voraus, dass Sie mit Kubernetes und AWS vertraut sind. Wenn dies nicht der Fall ist, nehmen Sie sich bitte etwas Zeit, um die Dokumentation zu beiden durchzugehen, bevor Sie mit dieser Anleitung beginnen.
Erstellen eines Admin-Benutzers mit Berechtigungen
Beginnen wir mit der Erstellung eines Admin-Nutzers für Ihren Cluster.
1. Melden Sie sich bei Ihrer AWS-Konsole an und gehen Sie zu IAM. Klicken Sie auf Nutzer> Benutzer hinzufügen.
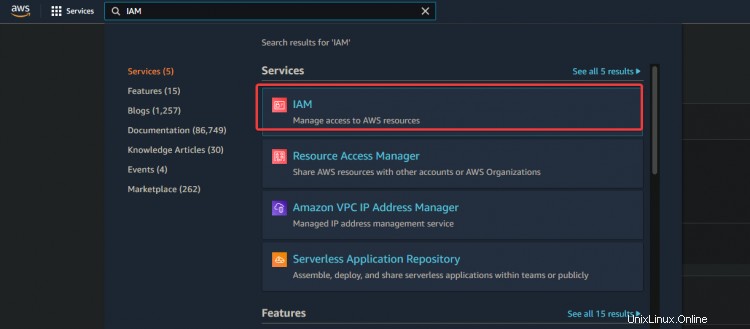

2. Geben Sie auf dem nächsten Bildschirm einen Benutzernamen wie admin ein . Wählen Sie Zugriffsschlüssel – Programmgesteuerter Zugriff aus. Klicken Sie auf Weiter :Berechtigungen
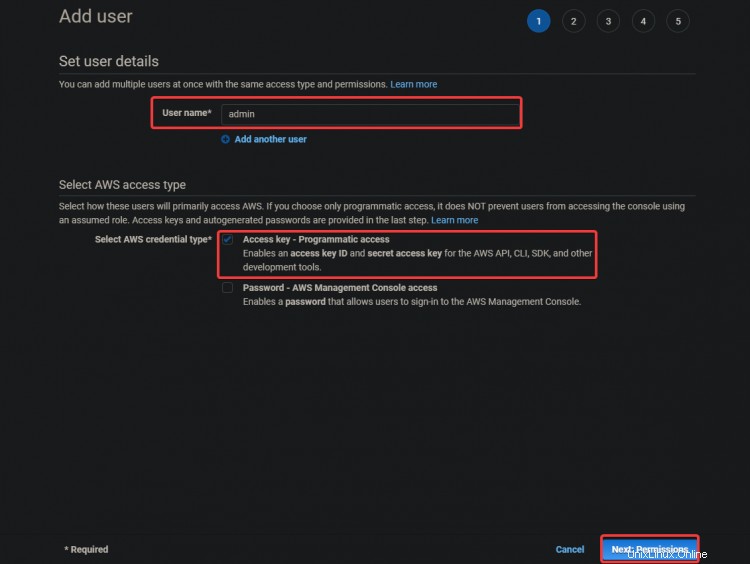
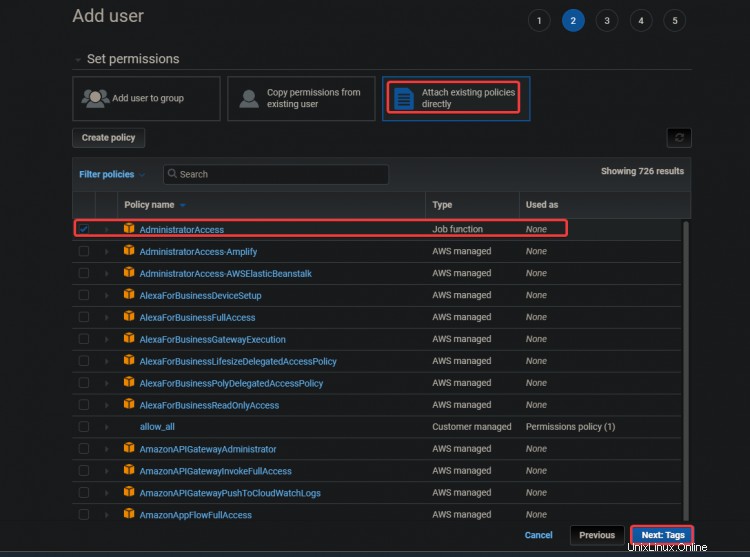
3. Wählen Sie auf dem nächsten Bildschirm Vorhandene Richtlinien direkt anhängen aus . Klicken Sie auf Administratorzugriff . Klicken Sie auf Weiter :Tags .
Der AdministratorAccess Richtlinie ist eine integrierte Richtlinie mit Amazon Elastic Container Service (ECS). Es bietet vollen Zugriff auf alle ECS-Ressourcen und alle Aktionen in der ECS-Konsole. Der Hauptvorteil dieser Richtlinie besteht darin, dass wir keinen zusätzlichen Benutzer mit zusätzlichen Berechtigungen für den Zugriff auf den AWS EKS-Service erstellen oder verwalten müssen.
Ihr Admin-Benutzer kann EC2-Instanzen, CloudFormation-Stacks, S3-Buckets usw. erstellen. Sie sollten sehr vorsichtig sein, wem Sie diese Art von Zugriff gewähren.
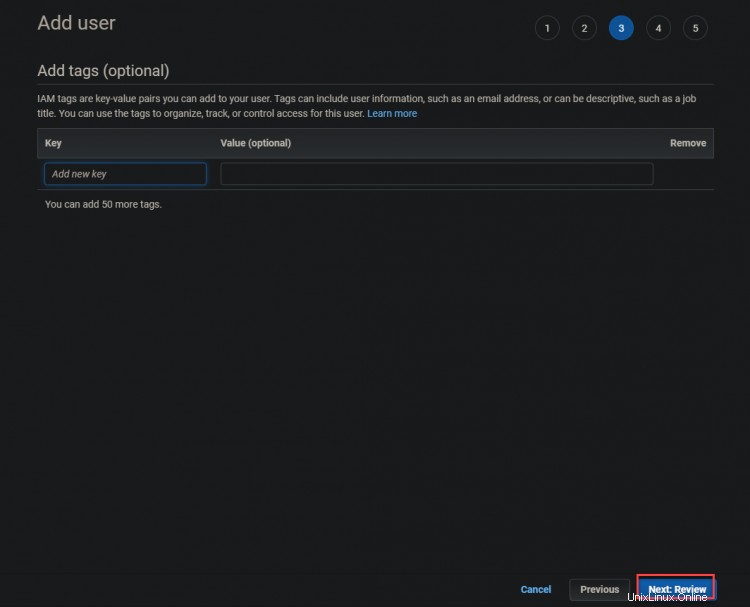
3. Klicken Sie auf dem nächsten Bildschirm auf Weiter :Überprüfung
4. Klicken Sie auf dem nächsten Bildschirm auf Erstellen Benutzer .
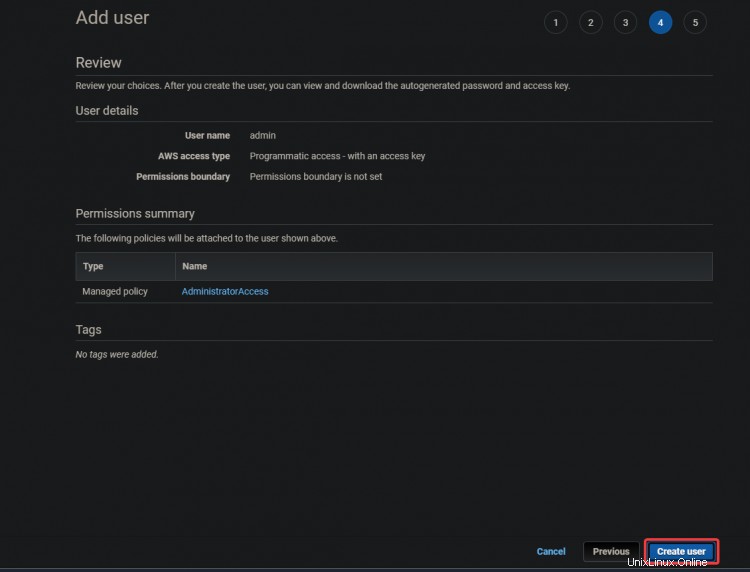
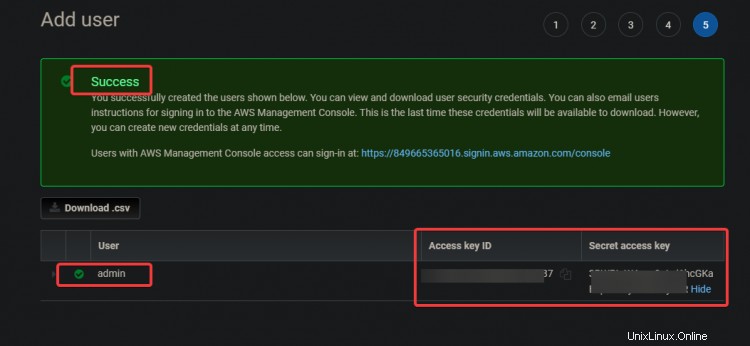
5. Auf dem nächsten Bildschirm erhalten Sie einen grünen Erfolg Nachricht. Die Zugriffsschlüssel-ID und
Geheime Zugriffsschlüssel werden ebenfalls in diesem Bildschirm angezeigt. Sie benötigen diese Schlüssel später, um Ihre CLI-Tools zu konfigurieren, also notieren Sie sich diese Schlüssel woanders.
Erstellen einer EC2-Instanz
Nachdem Sie nun den administrativen Benutzer erstellt haben, erstellen wir eine EC2-Instance, die Sie als Ihren Kubernetes-Master-Knoten verwenden.
1. Geben Sie EC2 in das Suchfeld ein. Klicken Sie auf den EC2-Link. Klicken Sie auf Instanz starten .


2. Wählen Sie Amazon Linux 2 AMI (HVM) aus für Ihre EC2-Instance. Wir werden dieses Amazon Linux AMI verwenden, um die spätere Installation von Kubernetes und anderen benötigten Tools zu vereinfachen, wie z. B.:kubectl!, Docker usw.
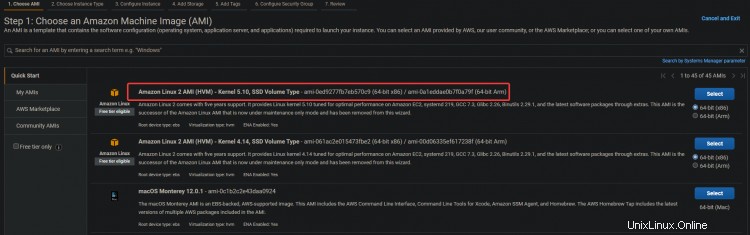
3. Klicken Sie auf dem nächsten Bildschirm auf Weiter :Instanz konfigurieren Einzelheiten .

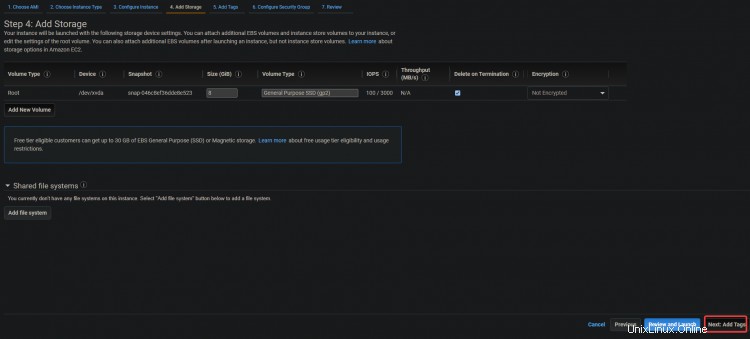
3. Aktivieren Sie auf dem nächsten Bildschirm die Option Öffentliche IP automatisch zuweisen Möglichkeit. Da sich der Server in einem privaten Subnetz befindet, ist er von außen nicht zugänglich. Sie können Ihren Servern öffentliche IP-Adressen zuweisen, indem Sie der Instance eine Elastic IP-Adresse zuweisen. Auf diese Weise ist Ihr EC2 und ELK zugänglich. Klicken Sie auf Weiter :Speicherung .
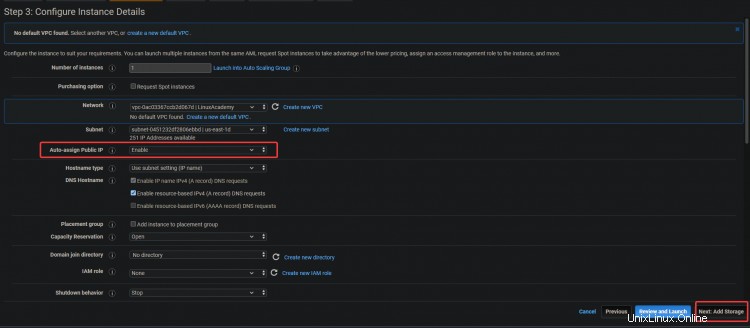
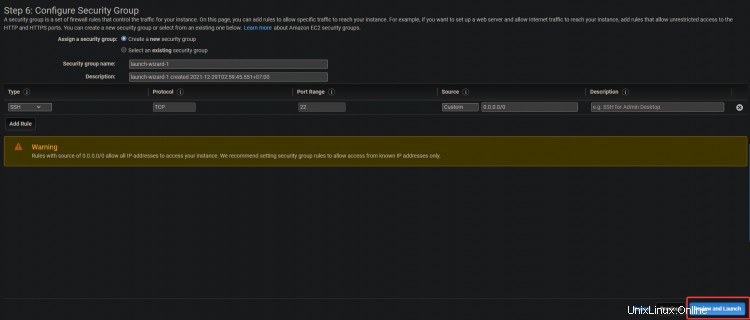
3. Klicken Sie im nächsten Bildschirm auf Weiter:Tags hinzufügen> Weiter:Sicherheitsgruppe konfigurieren .
4. Klicken Sie auf dem nächsten Bildschirm auf Überprüfen und starten> Starten .
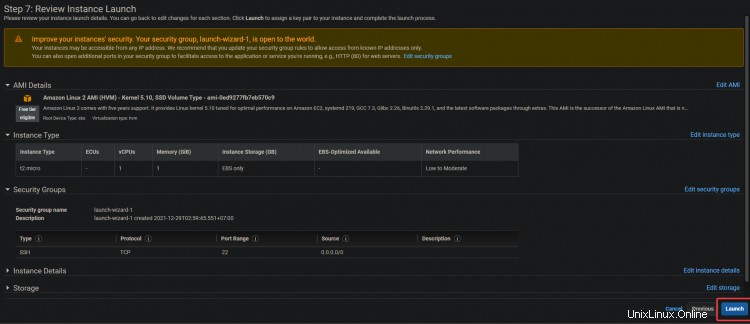
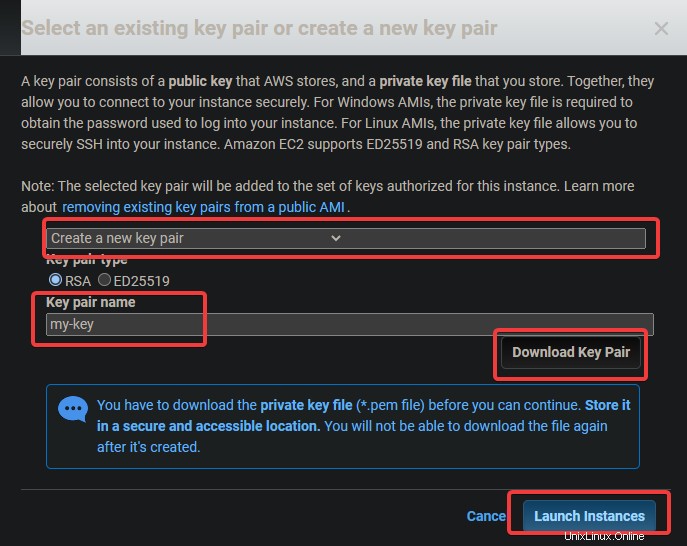
5. Ein Schlüsselpaar-Dialogfeld wird angezeigt. Klicken Sie auf Neues Schlüsselpaar erstellen . Geben Sie ihm einen Namen, laden Sie die .pem-Datei herunter und speichern Sie sie an einem sicheren Ort. Klicken Sie auf Starten Instanz .
Konfigurieren der Befehlszeilentools
Nachdem Sie eine EC2-Instance erstellt haben, müssen Sie den Client dafür installieren. In AWS-Begriffen ist ein Client ein Befehlszeilentool, mit dem Sie Cloud-Objekte verwalten können. In diesem Abschnitt erfahren Sie, wie Sie die Tools der Befehlszeilenschnittstelle (CLI) konfigurieren.
1. Navigieren Sie zu Ihrem EC2-Dashboard. Sie sollten sehen, dass Ihre neue EC2-Instance ausgeführt wird. Wenn dies nicht der Fall ist, nimmt Ihre Instanz möglicherweise ihren ersten Start vor, warten Sie 5 Minuten und versuchen Sie es erneut. Sobald Ihre Instanz ausgeführt wird, klicken Sie auf Verbinden .

2. Klicken Sie im nächsten Bildschirm auf Verbinden .

Sie werden zu einer interaktiven SSH-Sitzung in Ihrem Browser weitergeleitet. Mit SSH können Sie sich sicher mit einem Remote-Server verbinden und darauf arbeiten. Über die interaktive SSH-Sitzung können wir die Befehlszeilentools für EKS und Kubernetes direkt auf Ihrer EC2-Instanz installieren.

Nachdem Sie sich bei der SSH-Sitzung angemeldet haben, müssen Sie als Erstes nach Ihrer aws-cli-Version suchen. Damit stellen Sie sicher, dass Sie die neueste Version von AWS CLI verwenden. Die AWS CLI wird zum Konfigurieren, Verwalten und Arbeiten mit Ihrem Cluster verwendet.
Wenn Ihre Version veraltet ist, können während des Cluster-Erstellungsprozesses einige Probleme und Fehler auftreten. Wenn Ihre Version unter 2.0 liegt, müssen Sie sie aktualisieren.
3. Führen Sie den folgenden Befehl aus, um Ihre CLI-Version zu überprüfen.
aws --version
Wie Sie in der Ausgabe unten sehen können, führen wir Version 1.18.147 aus von aws-cli , was sehr veraltet ist. Lassen Sie uns die CLI auf die neueste verfügbare Version aktualisieren, die zum Zeitpunkt des Schreibens dieses Artikels v2+ ist.

4. Führen Sie den folgenden Befehl aus, um die neueste verfügbare Version der AWS CLI auf Ihre EC2-Instance herunterzuladen. curl lädt Ihre Datei von der angegebenen URL herunter, -o benennt sie nach Ihren Wünschen und „awscli-exe-linux-x86_64.zip“ ist die herunterzuladende Datei
curl "https://awscli.amazonaws.com/awscli-exe-linux-x86_64.zip" -o "awscliv2.zip"

5. Führen Sie nach Abschluss des Downloads den folgenden Befehl aus, um den Inhalt Ihrer heruntergeladenen Datei in das aktuelle Verzeichnis zu extrahieren.
unzip awscliv2.zip
6. Führen Sie als Nächstes den which aws-Befehl aus, um Ihren Link für die neueste Version von AWS CLI festzulegen. Dieser Befehl teilt Ihnen mit, wo er im PATH Ihrer Umgebung zu finden ist, sodass Sie ihn von jedem Verzeichnis aus ausführen können.
which aws
Wie Sie in der Ausgabe unten sehen können, befindet sich die veraltete AWS CLI unter /usr/bin/aws .

7. Jetzt müssen Sie Ihre aws-cli konfigurieren, indem Sie einen Update-Befehl mit einigen Parametern ausführen. Der erste Parameter ./aws/install hilft uns bei der Installation von AWS CLI im aktuellen Verzeichnis. Der zweite Parameter --bin-dir gibt an, wo sich die AWS CLI im PATH Ihrer Umgebung befindet, und der dritte Parameter --install-dir ist ein Pfad relativ zu bin-dir. Dieser Befehl stellt sicher, dass alle Ihre Pfade auf dem neuesten Stand sind.
sudo ./aws/install --bin-dir /usr/bin --install-dir /usr/bin/aws-cli --update
8. Führen Sie den Befehl aws --version erneut aus, um sicherzustellen, dass Sie die neueste Version verwenden.
aws --version
Sie sollten die aktuell installierte AWS CLI-Version sehen. Wie Sie in der Ausgabe unten sehen können, verwenden wir jetzt v2.4.7 von AWS CLI. Dies ist die neueste Version und wird Ihnen bei der Konfiguration der nächsten Schritte keine Probleme bereiten.

9. Nachdem Ihre Umgebung nun ordnungsgemäß konfiguriert ist, müssen Sie konfigurieren, mit welchem AWS-Konto Sie über die AWS CLI kommunizieren möchten. Führen Sie den folgenden Befehl aus, um Ihre derzeit konfigurierten Kontoumgebungsvariablen mit dem Alias aufzulisten, den Sie verwenden möchten.
aws configure
Dadurch werden Ihnen alle Umgebungsvariablen Ihres AWS-Kontos angezeigt, die derzeit konfiguriert sind. Sie sollten so etwas in der Ausgabe unten sehen. Sie müssen einige Konfigurationsparameter einrichten, damit die AWS CLI mit Ihren erforderlichen Konten kommunizieren kann. Führen Sie den folgenden Befehl aus, der Sie durch einen Konfigurationsassistenten führt, um Ihr AWS-Konto einzurichten.
- AWS-Zugriffsschlüssel-ID [Keine]:Geben Sie den zuvor notierten AWS-Zugriffsschlüssel ein.
- Geheimer AWS-Zugriffsschlüssel [Keiner]:Geben Sie den zuvor notierten geheimen AWS-Zugriffsschlüssel ein.
- Sie müssen auch den Namen der Standardregion angeben, in der sich Ihr EKS-Cluster befinden wird. Sie sollten eine AWS-Region auswählen, in der sich Ihr gewünschter EKS-Cluster befinden wird und die Ihnen am nächsten liegt. In diesem Tutorial haben wir us-east-1 aufgrund seiner geografischen Lage in unserer Nähe und der einfachen Verwendung für die nächsten Schritte im Tutorial ausgewählt.
- Standardausgabeformat [Keine]:Geben Sie json als Ihr Standardausgabeformat ein, da es für uns sehr nützlich sein wird, die Konfigurationsdateien später anzuzeigen.

Jetzt, da Sie Ihre AWS CLI-Tools eingerichtet haben. Es ist an der Zeit, das Kubernetes CLI-Tool namens kubectl in Ihrer Umgebung zu konfigurieren, damit Sie mit Ihrem EKS-Cluster interagieren können.
Kubectl ist die Befehlszeilenschnittstelle für Kubernetes. Mit Kubectl können Sie Anwendungen verwalten, die auf Kubernetes-Clustern ausgeführt werden. Kubectl wird nicht standardmäßig auf Linux- und MacOS-Systemen installiert. Sie können Kubectl auf anderen Systemen installieren, indem Sie den Anweisungen auf der Kubernetes-Website folgen.
10. Führen Sie den folgenden Befehl aus, um die kubectl-Binärdatei herunterzuladen. Eine Binärdatei ist eine Computerdatei mit der Erweiterung ".bin", die nur auf bestimmten Computertypen ausführbar ist. Es ist eine einfache Möglichkeit für unterschiedliche Computertypen, Dateien gemeinsam zu nutzen. Wir verwenden die kubectl-Binärdatei, weil die kubectl-Binärdatei plattformunabhängig ist. Es funktioniert auf jedem System, auf dem ein Unix-ähnliches Betriebssystem ausgeführt werden kann, einschließlich Linux und Mac OS.
curl -o kubectl https://amazon-eks.s3.us-west-2.amazonaws.com/1.16.8/2020-04-16/bin/linux/amd64/kubectl
11. Führen Sie den folgenden chmod-Befehl aus, um die kubectl-Binärdatei ausführbar zu machen. Der Befehl chmod ist ein Unix- und Linux-Befehl, der zum Ändern von Datei- oder Verzeichniszugriffsberechtigungen verwendet wird. Der Linux-Befehl chmod verwendet das Oktalzahlensystem, um die Berechtigungen für jeden Benutzer anzugeben. Kubectl kann jetzt auf Ihrem lokalen Rechner verwendet werden.
chmod +x ./kubectl
12. Führen Sie den folgenden Befehl aus, um ein kubectl-Verzeichnis in Ihrem $HOME/bin-Ordner zu erstellen, und kopieren Sie die kubectl-Binärdatei dorthin. Der Befehl mkdir -p $HOME/bin erstellt ein bin-Unterverzeichnis in Ihrem Home-Verzeichnis. Der Befehl mkdir wird verwendet, um neue Verzeichnisse oder Ordner zu erstellen. Die Option -p weist den Befehl mkdir an, automatisch alle erforderlichen übergeordneten Verzeichnisse für das neue Verzeichnis zu erstellen. $HOME/bin ist eine Umgebungsvariable, die Ihren Home-Verzeichnispfad speichert. Jeder Linux-Benutzer hat das Verzeichnis $HOME/bin in seinem Dateisystem. Das Konstrukt &&wird als logischer UND-Operator bezeichnet. Es wird verwendet, um Befehle zu gruppieren, sodass mehr als ein Befehl gleichzeitig ausgeführt werden kann. Das Konstrukt &&ist nicht erforderlich, damit dieser Befehl funktioniert, aber es ist eine bewährte Vorgehensweise.
Der Befehl cp ./kubectl $HOME/bin/kubectl kopiert die lokale kubectl-Binärdatei in Ihr kubectl-Verzeichnis und benennt die Datei in kubectl um. Schließlich macht der Exportbefehl, was er sagt – er exportiert eine Umgebungsvariable in den Speicher der Shell, sodass sie von jedem Programm verwendet werden kann, das von dieser Shell ausgeführt wird. In unserem Fall müssen wir kubectl mitteilen, wo sich unser kubectl-Verzeichnis befindet, damit es die kubectl-Binärdatei finden kann.
mkdir -p $HOME/bin && cp ./kubectl $HOME/bin/kubectl && export PATH=$PATH:$HOME/bin
13. Führen Sie den folgenden Befehl kubectl version aus, um zu überprüfen, ob kubectl korrekt installiert ist. Der Befehl kubectl version --short --client gibt eine verkürzte Version der kubectl-Version in einer gut formatierten, für Menschen lesbaren Kubernetes-REST-API-Antwort aus. Die Option --client lässt kubectl die formatierte Version der REST-API-Antwort von Kubernetes drucken, die über Versionen hinweg konsistent ist.
Die Option --short weist kubectl an, grundlegende Informationen in kompakter Form mit einer Dezimalstelle für Floats und einem abgekürzten Zeitformat bereitzustellen, das dem von --format entspricht. Sie sollten eine Ausgabe wie die folgende sehen. Diese Ausgabe teilt uns mit, dass wir kubectl erfolgreich installiert haben und die richtige Version verwendet wird.

Das Letzte, was Sie in diesem Abschnitt tun müssen, ist das eksctl-CLI-Tool für die Verwendung Ihres Amazon EKS-Clusters zu konfigurieren. Das eksctl-CLI-Tool ist eine Befehlszeilenschnittstelle, die Amazon EKS-Cluster verwalten kann. Es kann Cluster-Anmeldeinformationen generieren, die Cluster-Spezifikation aktualisieren, Worker-Knoten erstellen oder löschen und viele andere Aufgaben ausführen.
14. Führen Sie die folgenden Befehle aus, um das eksctl-CLI-Tool zu installieren und seine Version zu überprüfen.
curl --silent --location "https://github.com/weaveworks/eksctl/releases/latest/download/eksctl_$(uname -s)_amd64.tar.gz" | tar xz -C /tmp && sudo mv /tmp/eksctl /usr/bin
eksctl version

Stellen Sie einen EKS-Cluster bereit
Nachdem Sie nun Ihr EC2 und die AWS CLI-Tools haben, können Sie jetzt Ihren ersten EKS-Cluster bereitstellen.
1. Führen Sie den folgenden Befehl eksctl create cluster aus, um einen Cluster namens dev in der Region us-east-1 mit einem Master- und drei Core-Knoten bereitzustellen.
eksctl create cluster --name dev --version 1.21 --region us-east-1 --nodegroup-name standard-workers --node-type t3.micro --nodes 3 --nodes-min 1 --nodes-max 4 --managed
Der Befehl eksctl create cluster erstellt einen EKS-Cluster in der Region us-east-1 unter Verwendung der von Amazon für diese spezifische Konfiguration empfohlenen Standardwerte und übergibt alle Argumente entsprechend in Anführungszeichen ( " ) oder als Variablen ( ${ } ).
Der Namensparameter wird verwendet, um den Namen dieses EKS-Clusters zu definieren, und es ist nur eine benutzerfreundliche Bezeichnung für Ihre Bequemlichkeit. version ist die Version, die der Cluster verwenden soll. In diesem Beispiel bleiben wir bei Kubernetes v1.21.2, können aber auch andere Optionen prüfen.
nodegroup-name ist der Name einer Knotengruppe, die dieser Cluster verwenden soll, um Worker-Knoten zu verwalten. In diesem Beispiel halten Sie es einfach und verwenden nur Standard-Worker, was bedeutet, dass Ihre Worker-Knoten standardmäßig über eine vCPU und 3 GB Arbeitsspeicher verfügen.
nodes ist die Gesamtzahl der Core-Worker-Knoten, die Sie in Ihrem Cluster haben möchten. In diesem Beispiel werden drei Knoten angefordert. nodes-min und nodes-max steuern die minimale und maximale Anzahl von Knoten, die in Ihrem Cluster zulässig sind. In diesem Beispiel werden mindestens ein, aber nicht mehr als vier Worker-Knoten erstellt.
2. Sie können zu Ihrer CloudFormation-Konsole navigieren, um den Bereitstellungsfortschritt zu überwachen.
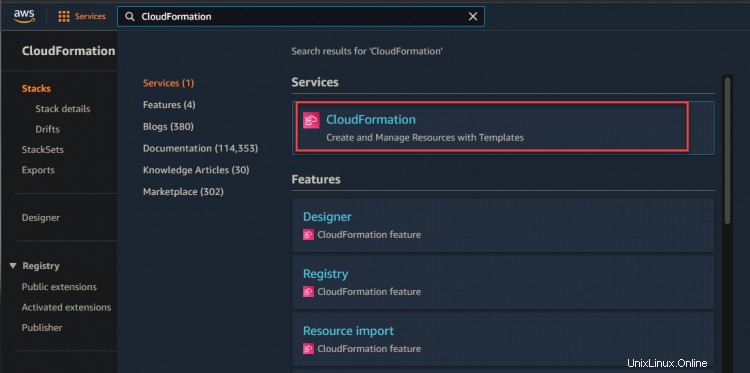
Wie unten gezeigt, können Sie sehen, dass Ihr Dev-Stack erstellt wird.

3. Klicken Sie auf den Dev-Stack-Hyperlink> Ereignis. Sie sehen eine Liste von Ereignissen im Zusammenhang mit dem Erstellungsprozess. Warten Sie, bis der Bereitstellungsprozess abgeschlossen ist – dies kann je nach Ihren spezifischen Umständen bis zu 15 Minuten dauern – und überprüfen Sie den Status des Stacks in der CloudFormation-Konsole.

4. Nachdem Sie darauf gewartet haben, dass der Stack die Bereitstellung abgeschlossen hat, navigieren Sie zu Ihrer CloudFormation-Konsole, Sie sehen Ihren Dev-Stack-Status von CREATE_COMPLETE.

Navigieren Sie nun zu Ihrer EC2-Konsole. Im EC2-Dashboard sehen Sie einen Master-Knoten und drei Kernknoten. Diese Ausgabe bestätigt, dass Sie den EKS-Cluster erfolgreich eingerichtet haben.

5. Führen Sie den folgenden eksctl-Befehl aus, um die Details des Entwicklungsclusters abzurufen, z. B. Cluster-ID und Region.
eksctl get cluster

6. Führen Sie den folgenden Befehl aws eks update aus, um die Anmeldeinformationen für den Remote-Worker-Knoten abzurufen. Dieser Befehl muss auf jedem Computer ausgeführt werden, den Sie mit dem Cluster verbinden möchten. Es lädt Anmeldeinformationen für Ihr kubectl herunter, um remote auf den EKS Kubernetes-Cluster zuzugreifen, ohne AWS Access-Zugriffsschlüssel zu verwenden.
aws eks update-kubeconfig --name dev --region us-east-1

Bereitstellen Ihrer Anwendung auf dem EKS-Cluster
Nachdem Sie Ihren EKS-Cluster bereitgestellt haben. Lassen Sie uns Ihre erste Anwendung auf Ihrem EKS-Cluster bereitstellen. In diesem Abschnitt erfahren Sie, wie Sie einen Nginx-Webserver zusammen mit einem Load Balancer als Beispielanwendung bereitstellen.
1. Führen Sie den folgenden Befehl aus, um Git auf Ihrem System zu installieren. Sie benötigen git, um den nginx-Webservercode von GitHub zu klonen.
sudo yum install -y git
2. Führen Sie den folgenden git clone-Befehl aus, um den nginx-Webserver-Code von github in Ihr aktuelles Verzeichnis zu klonen.
git clone https://github.com/ata-aws-iam/htf-elk.git
3. Führen Sie den Befehl cd htf-elk aus, um das Arbeitsverzeichnis in das Verzeichnis der nginx-Konfigurationsdateien zu ändern.
cd htf-elk
4. Führen Sie den Befehl ls aus, um Dateien im aktuellen Verzeichnis aufzulisten.
ls
Sie werden die folgenden Dateien in Ihrem nginx-Verzeichnis sehen.

5. Führen Sie den untenstehenden cat-Befehl aus, um die Datei nginx-deployment.yaml zu öffnen, und Sie werden die folgenden Inhalte in dieser Datei sehen.
cat nginx-deployment.yaml

- apiVersion:apps/v1 ist die zentrale Kubernetes-API
- kind:Deployment ist die Art von Ressource, die für diese Datei erstellt wird. In einer Bereitstellung wird pro Container ein Pod erstellt.
- Metadaten:gibt Metadatenwerte an, die beim Erstellen eines Objekts verwendet werden sollen
- name:nginx-deployment ist der Name oder die Bezeichnung für diese Bereitstellung. Wenn es keinen Wert hat, wird der Bereitstellungsname aus dem Verzeichnisnamen genommen.
- labels:stellt Labels zur Anwendung bereit. In diesem Fall wird es für das Service-Routing über Elastic Load Balancing (ELB) verwendet
- env:dev beschreibt eine Umgebungsvariable, die durch einen String-Wert definiert ist. So können Sie Ihrem Container dynamische Konfigurationsdaten bereitstellen.
- spec:Hier definieren Sie, wie viele Replikate erstellt werden sollen. Sie können die Eigenschaften angeben, auf denen jede Replik basieren soll.
- replicas:3 erstellt drei Replikanten dieses Pods auf Ihrem Cluster. Diese werden auf die verfügbaren Worker-Knoten verteilt, die mit dem Label-Selektor . übereinstimmen
- containerPort:80 ordnet einen Port des Containers einem Port auf dem Host zu. In diesem Fall wird Port 80 auf dem Container Port 30000 Ihres lokalen Rechners zugeordnet.
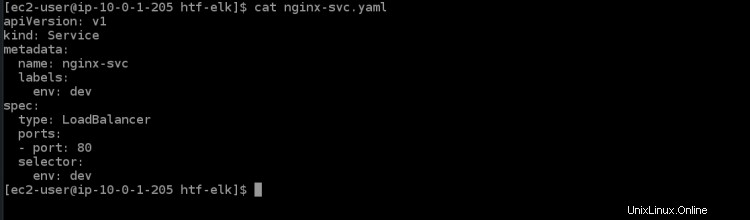
6. Führen Sie den folgenden cat-Befehl aus, um die Dienstdatei nginx-svc.yaml zu öffnen. Sie werden die folgenden Inhalte in dieser Datei sehen.
cat nginx-svc.yaml
7. Führen Sie den folgenden Befehl kubectl apply aus, um den nginx-Dienst in Ihrem Kubernetes-Cluster zu erstellen. Es dauert einige Minuten, bis der EKS-Cluster ELB für diesen Dienst bereitstellt.
kubectl apply -f ./nginx-svc.yaml

8. Führen Sie den kubectl get-Dienst unten aus, um die Details über den gerade erstellten nginx-Dienst abzurufen.
kubectl get service
Sie erhalten die folgende Ausgabe. ClusterIP ist die diesem Dienst zugewiesene interne Kubernetes-IP. Der LoadBalancer-ELB-Name ist eine eindeutige Kennung für diesen Dienst. Es erstellt automatisch einen ELB auf AWS und stellt einen öffentlichen Endpunkt für diesen Dienst bereit, der von Diensten Ihrer Wahl wie Webbrowser (Domänenname) oder API-Clients erreicht werden kann. Es ist über eine IP-Adresse Ihrer Wahl zugänglich.
Load Balancer ELB mit dem Namen a6f8c3cf0fe3a468d8828db6059ef05e-953361268.us-east-1.elb.amazonaws.com hat Port 32406, der dem Container-Port 80 zugeordnet wird. Notieren Sie sich den DNS-Hostnamen des Load Balancer ELB aus der Ausgabe; Sie benötigen sie später für den Zugriff auf den Dienst.

9. Führen Sie den folgenden kubectl apply-Befehl aus, um die Bereitstellung für Ihren Cluster anzuwenden.
kubectl apply -f ./nginx-deployment.yaml

10. Führen Sie die kubectl get-Bereitstellung aus, um die Details über die soeben erstellte nginx-Bereitstellung abzurufen.
kubectl get deployment

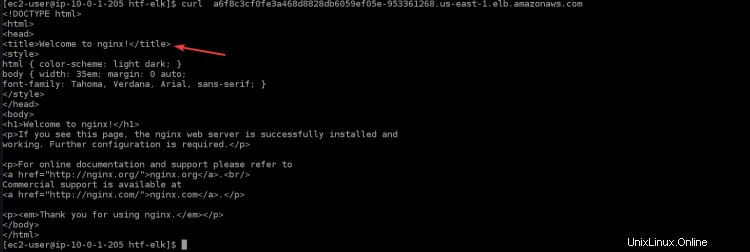
11. Führen Sie den folgenden Befehl aus, um über den Load Balancer auf Ihre nginx-Anwendung zuzugreifen. Sie sehen die Willkommensseite von nginx in Ihrem Terminal/Ihrer Konsole, die bestätigt, dass Ihre nginx-Anwendung wie erwartet funktioniert. Ersetzen Sie
curl "<LOAD_BALANCER_DNS_HOSTNAME>"
12. Sie können auch über den Browser auf Ihre nginx-Anwendung zugreifen, indem Sie den DNS-Hostnamen des Load Balancers kopieren und in den Browser einfügen.
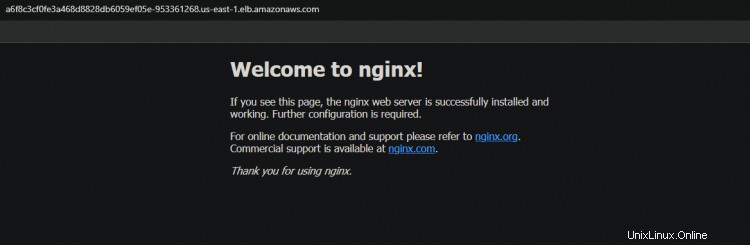
Verifizieren der Hochverfügbarkeitsfunktion (HA) für Ihren Cluster
Nachdem Sie Ihren Cluster erfolgreich erstellt haben, können Sie die HA-Funktion testen, um sicherzustellen, dass sie wie erwartet funktioniert.
Kubernetes unterstützt Bereitstellungen mit mehreren Knoten durch die Verwendung spezieller Controller, die zusammenarbeiten, um replizierte Pods oder Dienste zu erstellen und zu verwalten. Einige dieser Controller sind Deployments, ReplicationController, Job und DaemonSet.
Ein Deployment Controller wird verwendet, um die Replikation auf Pod- oder Dienstebene zu steuern. Wenn Ihr Pod keine Ressourcen mehr hat, löscht er alle Pods dieses Replikationscontrollers (mit Ausnahme desjenigen, der auf dem Master-Knoten ausgeführt wird) und erstellt neue Repliken dieses Pods. Dadurch erhalten Sie eine sehr hohe Betriebszeit für Ihre Anwendungen.
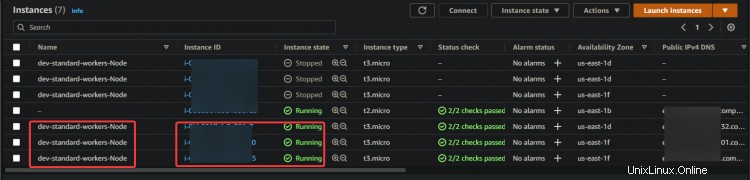
1. Navigieren Sie zu Ihrem EC2-Dashboard und stoppen Sie alle drei Worker-Knoten.

2. Führen Sie den folgenden Befehl aus, um den Status Ihrer Pods zu überprüfen. Sie erhalten verschiedene Status:Beendigung , Läuft , und Ausstehend für alle Ihre Schoten. Denn sobald Sie alle Worker-Knoten beendet haben, versucht EKS, alle Worker-Knoten und Pods erneut zu starten. Sie können auch einige neue Knoten sehen, die Sie anhand ihres Alters identifizieren können (50 Jahre ).
kubectl get pod

Das Hochfahren der neuen EC2-Instance und der Pods dauert einige Zeit. Sobald alle Worker-Knoten hochgefahren sind, sehen Sie, dass alle neuen EC2-Instances wieder Ausgeführt werden Status.
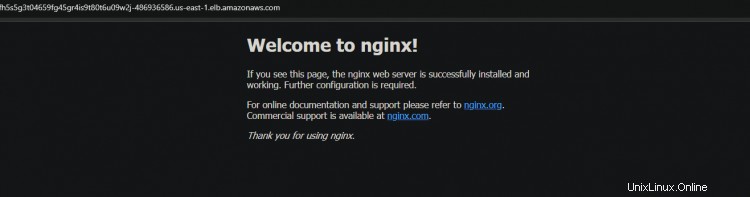
3. Führen Sie den kubectl-get-Dienst noch einmal aus. Sie können sehen, dass ESK einen neuen nginx-Dienst und einen neuen DNS-Namen für Ihren Load Balancer erstellt.
kubectl get service

Kopieren Sie das neue DNS und fügen Sie es in Ihren Browser ein. Sie erhalten erneut die Begrüßung von der Nginx-Seite. Diese Ausgabe bestätigt, dass Ihre Hochverfügbarkeit wie beabsichtigt funktioniert.
Schlussfolgerung
In diesem Artikel haben Sie gelernt, wie Sie Ihren EKS-Cluster einrichten. Sie haben auch überprüft, ob die Hochverfügbarkeitsfunktion funktioniert, indem Sie alle Ihre Worker-Knoten gestoppt und den Status Ihrer Pods überprüft haben. Sie sollten nun in der Lage sein, EKS-Cluster mit kubectl zu erstellen und zu verwalten.