Das Erstellen statistischer Diagramme in Python kann mühsam sein, besonders wenn Sie sie manuell generieren. Aber mit Hilfe der Datenvisualisierungsbibliothek von Seaborn Python können Sie Ihre Arbeit vereinfachen und schnell und mit weniger Codezeilen schöne Diagramme erstellen.
Mit Seaborn ist das Erstellen schöner statistischer Diagramme für Ihre Daten ein Kinderspiel. Dieser Leitfaden zeigt Ihnen anhand von realen Beispielen, wie Sie diese leistungsstarke Bibliothek verwenden.
Voraussetzungen
Dieses Tutorial wird eine praktische Demonstration sein. Wenn Sie mitmachen möchten, stellen Sie sicher, dass Sie Folgendes haben:
- Ein Windows- oder Linux-Computer, auf dem Python und Anaconda installiert sind. Dieses Tutorial verwendet Anaconda 2021.11 mit Python 3.9 auf einem Windows 10-PC.
Was ist die Seaborn Python Library?
Die Seaborn Python-Bibliothek ist eine Python-Datenvisualisierungsbibliothek, die auf der Matplotlib-Bibliothek aufbaut. Seaborn bietet eine große Auswahl an High-Level-Tools zum Erstellen von statistischen Diagrammen und Diagrammen. Die Fähigkeit von Seaborn zur Integration mit Pandas Dataframe-Objekten ermöglicht Ihnen die schnelle Visualisierung von Daten.
Ein DataFrame stellt tabellarische Daten dar, wie Sie sie in einer Tabelle, einem Arbeitsblatt oder einer CSV-Datei mit kommagetrennten Werten finden würden.
Seaborn arbeitet mit Pandas DataFrames und wandelt Daten unter der Haube in Code um, den Matplotlib verstehen kann.
Obwohl viele qualitativ hochwertige Plots verfügbar sind, lernen Sie in diesem Tutorial die drei gängigsten integrierten Seaborn-Plot-Familien kennen, um Ihnen den Einstieg zu erleichtern.
- Relationale Diagramme.
- Verteilungsdiagramme.
- Kategoriale Diagramme.
Seaborn enthält viele weitere Plots, und dieses Tutorial kann nicht alle abdecken. Die Seaborn-API-Dokumentation und das Tutorial sind hervorragende Ausgangspunkte, um die verschiedenen Arten von Seaborn-Plots kennenzulernen.
Einrichten einer neuen JupyterLab- und Seaborn-Python-Umgebung
Bevor Sie Ihre Seaborn-Reise beginnen, müssen Sie zunächst eine Jupyter Lab-Umgebung einrichten. Aus Gründen der Konsistenz mit den Beispielen arbeiten Sie außerdem zusammen mit diesem Tutorial an einem bestimmten Datensatz.
JupyterLab ist eine Webanwendung, mit der Sie Code, Rich-Text, Diagramme und andere Medien in einem einzigen Dokument kombinieren können. Sie können Notizbücher auch online mit anderen teilen oder sie als ausführbare Dokumente verwenden.
Führen Sie die folgenden Schritte aus, um mit der Einrichtung Ihrer Umgebung zu beginnen.
1. Öffnen Sie das Anaconda Navigato r auf Ihrem Computer.
a. Auf einem Windows-Computer:Klicken Sie auf Start —> Anakonda3 —> Anaconda-Navigator .
b. Auf einem Linux-Computer:Führen Sie anaconda-navigator aus Befehl auf dem Terminal.
2. Suchen Sie im Anaconda Navigator nach JupyterLab Anwendung und klicken Sie auf Starten . Dadurch wird eine Instanz von JupyterLab in einem Webbrowser geöffnet.

3. Öffnen Sie nach dem Start von JypyterLab die Seitenleiste des Dateibrowsers und erstellen Sie einen neuen Ordner namens ATA_Seaborn unter Ihrem Profil oder Home-Verzeichnis. Dieser neue Ordner wird Ihr Projektverzeichnis sein.
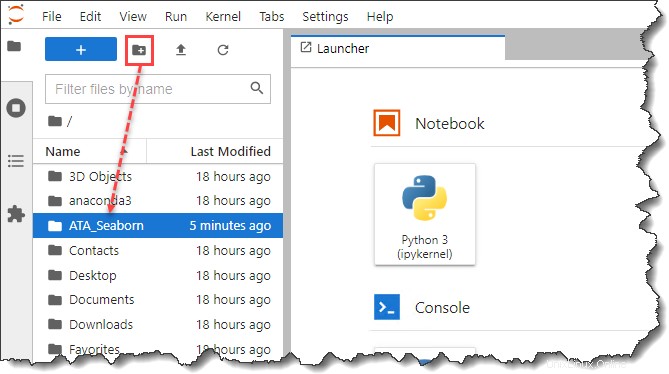
4. Öffnen Sie als Nächstes einen neuen Browser-Tab und laden Sie das Pokémon herunter Datensatz. Stellen Sie sicher, dass Sie die ata_pokemon.csv speichern Datei in das von Ihnen erstellte Projektverzeichnis, in diesem Beispiel ATA_Seaborn .
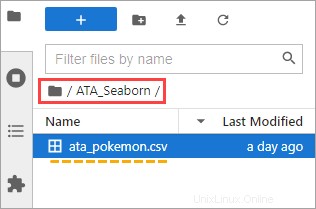
5. Doppelklicken Sie im JupyterLab auf ATA_Seaborn Mappe. Sie sollten jetzt die Datei ata_pokemon.csv sehen unter diesem Ordner.
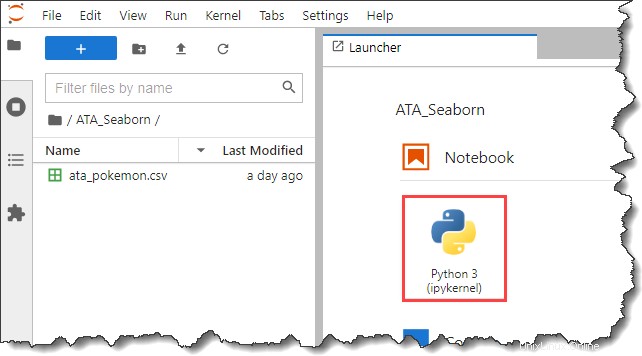
6. Klicken Sie nun auf Python 3 Schaltfläche unter dem Notizbuch Abschnitt im Launcher Registerkarte, um ein neues Notizbuch zu erstellen.
7. Klicken Sie nun auf das neue Notizbuch Untitled.ipynb und drücken Sie F2 um die Datei umzubenennen. Ändern Sie den Dateinamen in ata_pokemon.ipynb .

8. Fügen Sie als Nächstes einen Titel zu Ihrem Notizbuch hinzu. Dieser Schritt ist optional, wird aber empfohlen, um Ihr Projekt besser identifizierbar zu machen.
Klicken Sie in der Symbolleiste Ihrer Notizbücher auf das Dropdown-Menü Code und klicken Sie auf Markdown.
9. Geben Sie den Text „# Pokemon Data Visualization“ in die Markdown-Zelle ein und drücken Sie die Tasten Umschalt + Eingabe.
Die Zelltypauswahl ändert sich automatisch zu Code, und das Notizbuch trägt den Titel Pokemon Data Visualization oben.
10. Speichern Sie abschließend Ihre Arbeit, indem Sie die Tastenkombination Strg + S drücken.
Stellen Sie sicher, dass Sie Ihre Arbeit regelmäßig speichern. Sie sollten Ihre Arbeit oft speichern, um bei Problemen mit der Internetverbindung nichts zu verlieren. Immer wenn Sie eine Änderung vornehmen, drücken Sie
CTRL+Sum Ihren Fortschritt zu speichern. Sie können auch auf die Schaltfläche Speichern in der Symbolleiste klicken.
Importieren der Pandas- und Seaborn-Python-Bibliotheken
Python-Code beginnt normalerweise mit dem Importieren der erforderlichen Bibliotheken. Und in diesem Projekt arbeiten Sie mit den Pandas- und Seaborn-Python-Bibliotheken.
Kopieren Sie zum Importieren von Pandas und Seaborn den folgenden Code und fügen Sie ihn in die Befehlszelle Ihres Notebooks ein.
Denken Sie daran:Um den Code oder die Befehle in der Befehlszelle auszuführen, drücken Sie die Umschalttaste + Eingabetaste.
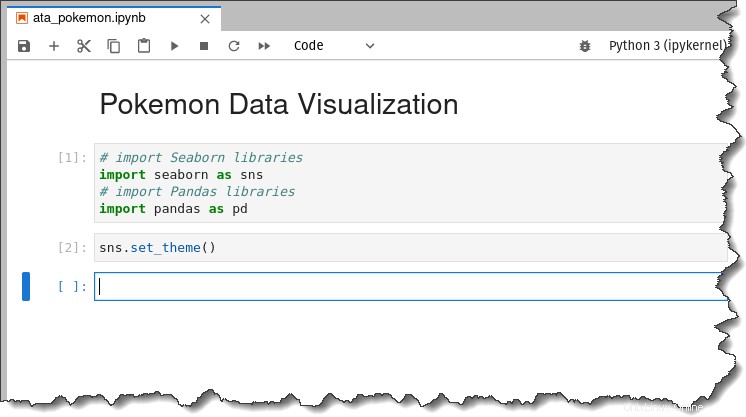
# import Seaborn libraries
import seaborn as sns
# import Pandas libraries
import pandas as pdFühren Sie als Nächstes den folgenden Befehl aus, um die Seaborn-Standarddesign-Ästhetik auf die zu erstellenden Plots anzuwenden.
sns.set_theme()
Seaborn verfügt über fünf integrierte Designs. Sie sind darkgrid (Standard), whitegrid , dark , white , und ticks .
Importieren des Beispieldatensatzes
Nachdem Sie nun Ihre JupyterLab-Umgebung eingerichtet haben, importieren wir die Daten aus dem Dataset in Ihre Jupyter-Umgebung.
1. Führen Sie pd.read_csv() aus Befehl in der Zelle, um die Daten zu importieren. Der Dateiname des Datensatzes muss in Klammern stehen, um die zu importierende Datei in doppelten Anführungszeichen einzuschließen.
Der folgende Befehl importiert die ata_pokemon.csv und speichern Sie den Datensatz auf pokemon Variable.
pokemon = pd.read_csv("ata_pokemon.csv")
2. Führen Sie pokemon.head() aus Befehl, um eine Vorschau der ersten fünf Zeilen des importierten Datensatzes anzuzeigen.
pokemon.head()Sie erhalten die folgende Ausgabe.
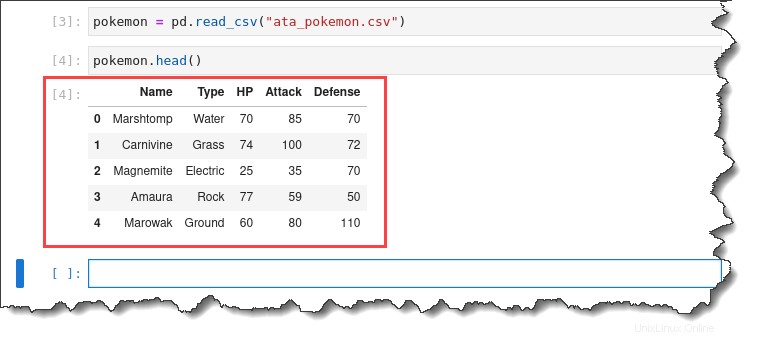
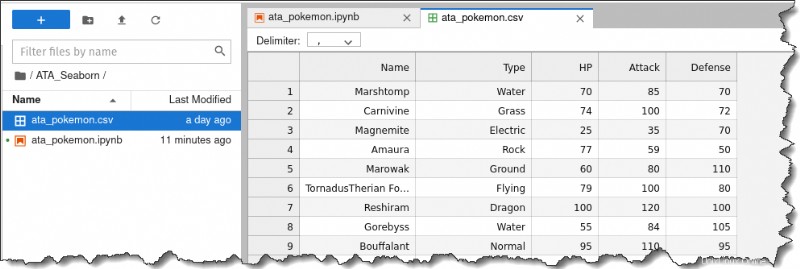
3. Doppelklicken Sie auf ata_pokemon.csv Datei auf der linken Seite, um jede einzelne Zeile zu inspizieren. Sie erhalten die folgende Ausgabe.
Wie Sie sehen können, lässt sich mit diesem Datensatz ganz bequem arbeiten, da er jede Beobachtung zeilenweise auflistet und alle numerischen Informationen in separaten Spalten stehen.
Lassen Sie uns nun einige Fragen zum Datensatz stellen, um die Analyse zu unterstützen.
- Wie ist die Beziehung zwischen Angriff und HP?
- Was ist die Verteilung von Attack?
- Welche Beziehung besteht zwischen Angriff und Typ?
- Wie ist die Angriffsverteilung für jeden Typ?
- Was ist der durchschnittliche oder mittlere Angriff für jeden Typ?
- Und wie hoch ist die Anzahl der Pokémon für jeden Typ?
Beachten Sie, dass sich viele dieser Fragen auf numerische und kategorische Datenbeziehungen konzentrieren. Kategoriale Daten sind nicht numerische Daten, die in diesem Beispieldatensatz der Pokémon-Typ sind.
Im Gegensatz zu Matplotlib, das für die Erstellung von Diagrammen mit rein numerischen Daten optimiert ist, können Sie mit Seaborn Daten analysieren, die sowohl kategoriale als auch numerische Daten enthalten.
Erstellen von Beziehungsdiagrammen
Sie haben also einen Datensatz importiert. Was kommt als nächstes? Jetzt verwenden Sie Ihre importierten Daten und erstellen daraus statistische Diagramme. Beginnen wir mit dem Erstellen von Beziehungs- oder Beziehungsdiagrammen, um die Beziehung zwischen HP zu ermitteln und Angriff Daten.
Die Darstellung von Beziehungen ist praktisch, wenn Sie mögliche Beziehungen zwischen Variablen in Ihrem Datensatz identifizieren möchten. Seaborn verfügt über zwei Diagramme zum Darstellen von Beziehungen:Streudiagramme und Liniendiagramme.
Liniendarstellung
Zum Erstellen eines Liniendiagramms müssen Sie Seaborn Python lineplot() aufrufen Funktion. Diese Funktion benötigt drei Parameter — data= , x=' , und y=' ‘.
Kopieren Sie den folgenden Befehl und führen Sie ihn in Ihrer Jupyter-Befehlszelle aus. Dieser Befehl verwendet den pokemon Objekt als zuvor importierte Datenquelle, die HP Spaltendaten für die x-Achse und die Attack Daten für die y-Achse.
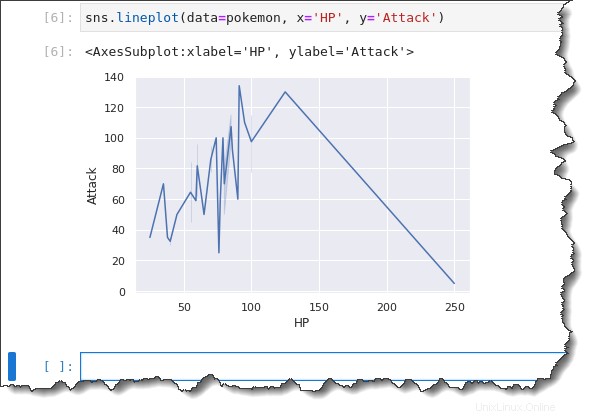
sns.lineplot(data=pokemon, x='HP', y='Attack')Wie Sie unten sehen können, leistet das Liniendiagramm keine gute Arbeit, um Ihnen die Informationen zu zeigen, die Sie schnell analysieren können. Ein Liniendiagramm zeigt besser eine X-Achse an, die einer kontinuierlichen Variablen wie der Zeit folgt.
In diesem Beispiel zeichnen Sie eine diskrete Variable HP. Was also passiert, ist, dass der Linienplot überall hingeht. Und es ist schwieriger, auf einen Trend zu schließen.
Scatter-Plotting
Ein Teil der explorativen Datenanalyse besteht darin, verschiedene Dinge auszuprobieren, um zu sehen, was gut funktioniert. Und dabei werden Sie lernen, dass einige Diagramme Ihnen bessere Erkenntnisse liefern können als andere.
Was macht dann ein besseres Beziehungsdiagramm aus als Liniendiagramme? — Streudiagramme.
Um ein Scatterplot zu erstellen, rufen Sie die Scatterplot-Funktion sns.scatterplot auf , und übergeben Sie drei Parameter: data=pokemon , x=HP , und y=Attack .
Führen Sie den folgenden Befehl aus, um ein Streudiagramm für den Pokémon-Datensatz zu erstellen.
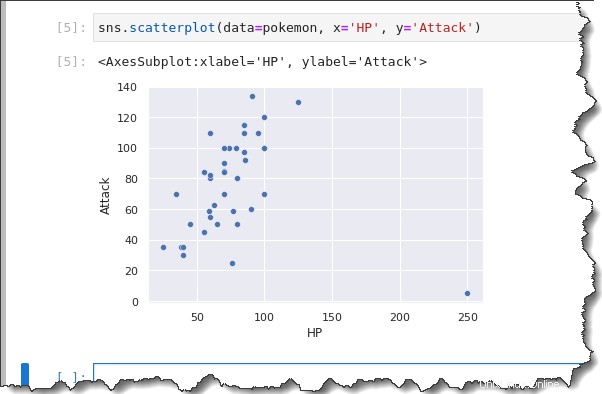
sns.scatterplot(data=pokemon, x='HP', y='Attack')Wie Sie im folgenden Ergebnis sehen können, zeigt Ihnen das Streudiagramm, dass es eine allgemeine positive Korrelation zwischen HP geben kann (x-Achse) und Angriff (y-Achse), mit einem Ausreißer.
Im Allgemeinen gilt, dass der Angriff mit zunehmender HP ebenfalls zunimmt. Pokémon mit größeren Gesundheitspunkten sind tendenziell stärker.
Streudiagramm mit Legenden
Während das Streudiagramm bereits eine sinnvollere Datenvisualisierung darstellte, können Sie das Diagramm noch weiter verbessern, indem Sie die Typverteilung mit einer Legende aufschlüsseln.
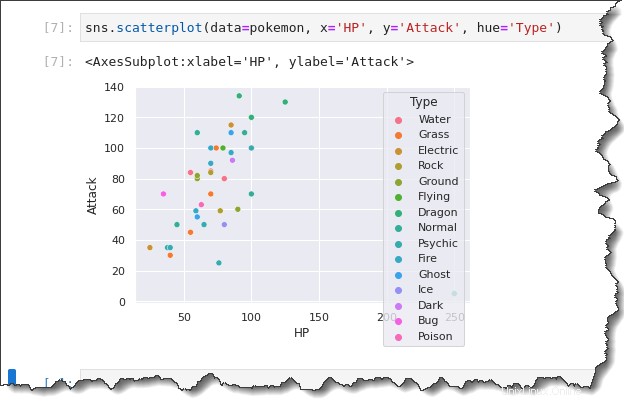
Führen Sie sns.scatterplot() aus Funktion wieder im folgenden Beispiel. Hängen Sie dieses Mal jedoch den hue='Type' an Schlüsselwort, das eine Legende erstellt, die die verschiedenen Pokemon-Typen zeigt. Führen Sie auf Ihrer Jupyter-Notebook-Registerkarte den folgenden Befehl aus.
sns.scatterplot(data=pokemon, x='HP', y='Attack', hue='Type')Beachten Sie beim Ergebnis unten, dass das Streudiagramm jetzt unterschiedliche Farben hat. Die Analyse der kategorialen Aspekte Ihrer Daten ist jetzt viel besser aufgrund der visuellen Unterscheidungen, die die Legende bietet.
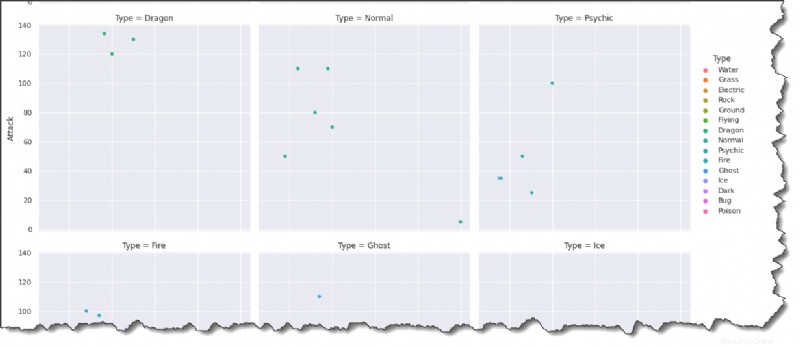
Noch besser ist, dass Sie die Handlung noch weiter aufschlüsseln können, indem Sie sns.relplot() verwenden Funktion mit dem col=Type und col_wrap Schlüsselwortargumente.
Führen Sie den folgenden Befehl in Jupyter aus, um ein Diagramm für jeden Pokémon-Typ in einem Rasterformat mit mehreren Diagrammen zu erstellen.
sns.relplot(data=pokemon, x='HP', y='Attack', hue='Type', col='Type', col_wrap=3)Wenn Sie sich das Ergebnis unten ansehen, können Sie schließen, dass HP und Angriff im Allgemeinen etwas positiv korrelieren. Pokémon mit mehr HP sind tendenziell stärker.
Würden Sie zustimmen, dass das Hinzufügen von Farben und Legenden das Plotten interessanter macht?
Verteilungsdiagramme erstellen
Im vorherigen Abschnitt haben Sie ein Streudiagramm erstellt. Lassen Sie uns dieses Mal ein Verteilungsdiagramm verwenden, um Einblicke in die Verteilung von Angriff und HP für jeden Pokémon-Typ zu erhalten.
Histogrammdarstellung
Sie können das Histogramm verwenden, um die Verteilung einer Variablen zu visualisieren. In Ihrem Beispieldatensatz ist die Variable der Angriff des Pokémon.
Um ein Histogrammdiagramm zu erstellen, führen Sie sns.histplot() aus Funktion unten. Diese Funktion benötigt zwei Parameter:data=pokemon und x='Attack' . Kopieren Sie den folgenden Befehl und führen Sie ihn in Jupyter aus.
sns.histplot(data=pokemon, x='Attack')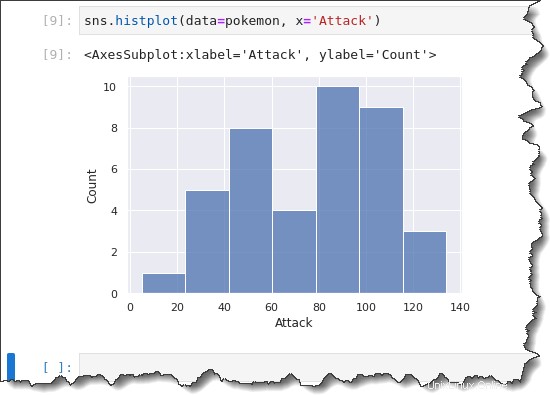
Beim Erstellen eines Histogramms wählt Seaborn automatisch eine optimale Bin-Größe für Sie aus. Möglicherweise möchten Sie die Bin-Größe ändern, um die Datenverteilung in unterschiedlich geformten Gruppierungen zu beobachten.
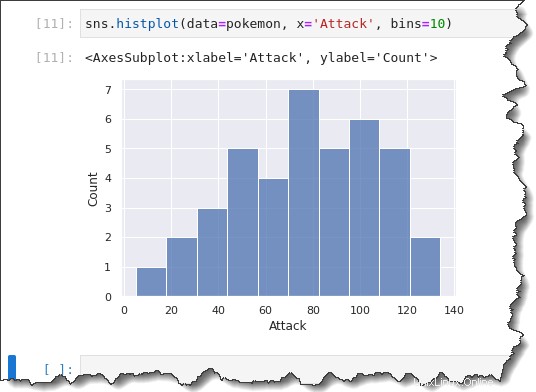
Um eine feste oder benutzerdefinierte Bin-Größe anzugeben, hängen Sie den bins=x an Argument für den Befehl, wobei x ist die benutzerdefinierte Bin-Größe. Führen Sie den folgenden Befehl aus, um ein Histogramm mit einer Bin-Größe von 10 zu erstellen.
sns.histplot(data=pokemon, x='Attack', bins=10)Im vorherigen Histogramm, das Sie erstellt haben, scheint der Pokemon-Angriff eine bimodale Verteilung zu haben (zwei große Höcker.)
Aber wenn Sie sich Ihre Bin-Größe von 10 ansehen, werden die Gruppierungen stärker segmentiert. Sie können sehen, dass es eher eine unimodale Verteilung mit einer Neigung nach rechts gibt.
Kernel Density Estimation (KDE) Plotting
Eine andere Möglichkeit, die Verteilung zu visualisieren, ist das Plotten der Kerndichteschätzung. KDE ist im Wesentlichen wie ein Histogramm, aber mit Kurven statt Säulen.
Der Vorteil der Verwendung eines KDE-Diagramms besteht darin, dass Sie aufgrund der Wahrscheinlichkeitskurve schneller Rückschlüsse auf die Verteilung der Daten ziehen können, die Merkmale wie zentrale Tendenz, Modalität und Schiefe zeigt.
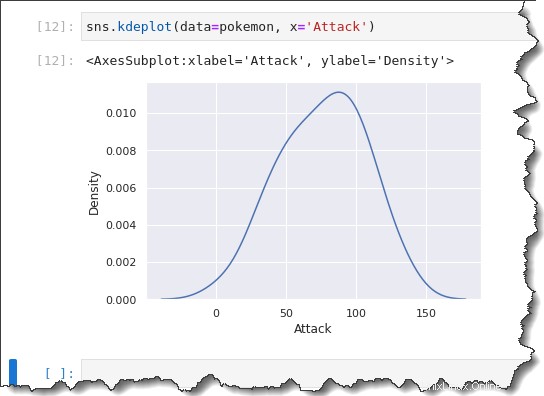
Um einen KDE-Plot zu erstellen, rufen Sie sns.kdeplot() auf Funktion und übergeben Sie denselben data=pokemon , x='Attack' als Argumente. Führen Sie den folgenden Code in Jupyter aus, um den KDE-Plot in Aktion zu sehen.
sns.kdeplot(data=pokemon, x='Attack')Wie Sie unten sehen können, ist das KDE-Diagramm ähnlich schief wie das Histogramm mit einer Bin-Größe von 10.
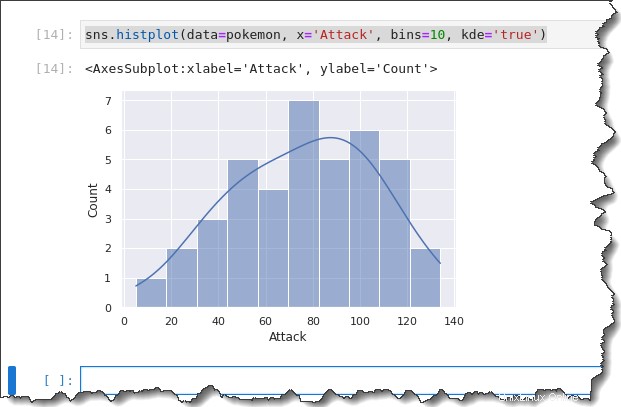
Da das Histogramm und KDE ähnlich sind, warum sie nicht zusammen verwenden? Mit Seaborn können Sie das KDE über ein Histogramm legen, indem Sie das Schlüsselwort kde='true' hinzufügen Argument für den vorherigen Befehl, wie Sie unten sehen können.
sns.histplot(data=pokemon, x='Attack', bins=10, kde='true')Sie erhalten die folgende Ausgabe. Gemäß dem Histogramm unten haben die meisten Pokémon einen Angriffspunkt, der zwischen 50 und 120 verteilt ist. Ist das nicht eine schöne Streuung!
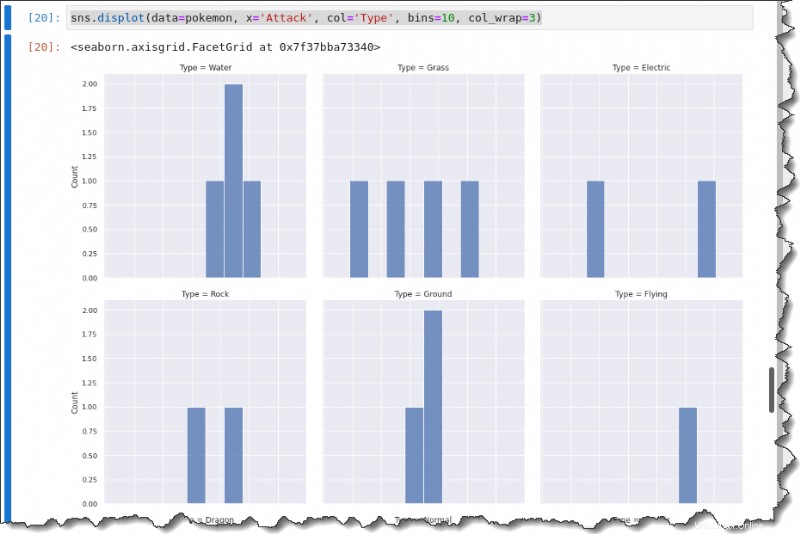
Um jede Angriffsverteilung nach Typ aufzuschlüsseln, rufen Sie displot() auf Funktion mit dem col Schlüsselwort unten, um ein Diagramm mit mehreren Gittern zu erstellen, das jeden Typ zeigt.
sns.displot(data=pokemon, x='Attack', col='Type', bins=10, col_wrap=3)Sie erhalten die folgende Ausgabe.
Generieren von kategorialen Diagrammen
Es ist schön, separate Histogramme basierend auf der Typkategorie zu erstellen. Aber Histogramme zeichnen möglicherweise kein klares Bild für Sie. Lassen Sie uns also einige von Seaborns kategorischen Diagrammen verwenden, um Ihnen zu helfen, weiter in die Analyse der Angriffsdaten basierend auf Pokémon-Typen einzutauchen.
Streifenplotten
In den vorherigen Streudiagrammen und Histogrammen haben Sie versucht, die Angriffsdaten gemäß einer kategorialen Variablen (Type ). Dieses Mal erstellen Sie ein Streifendiagramm, eine Reihe von Streudiagrammen, die nach Kategorien gruppiert sind.
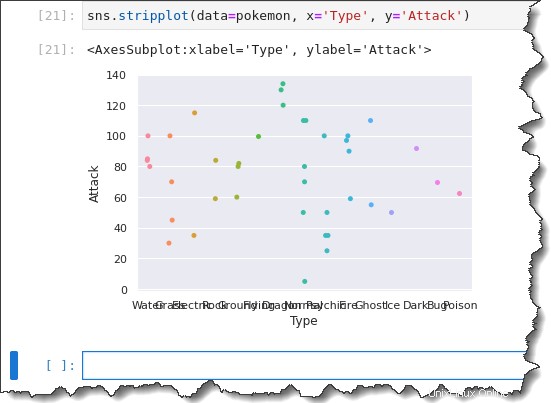
Rufen Sie zum Erstellen Ihres kategorialen Streifendiagramms sns.stripplot() auf Funktion und übergeben Sie drei Argumente:data=pokemon , x='Type' und y='Attack' . Führen Sie den folgenden Code in Jupyter aus, um das kategoriale Streifendiagramm zu generieren.
sns.stripplot(data=pokemon, x='Type', y='Attack')Jetzt haben Sie ein Streifendiagramm mit allen Beobachtungen, die nach Typ gruppiert sind. Aber beachten Sie, wie die X-Achsen-Beschriftungen alle zusammengedrückt werden? Nicht so hilfreich, oder?
Um die X-Achsen-Beschriftungen zu korrigieren, müssen Sie eine andere Funktion namens catplot() verwenden .
Führen Sie in der Befehlszelle Ihres Jupyter-Notebooks sns.catplot() aus Funktion und übergeben Sie fünf Argumentekind='strip' , data=pokemon , x='Type' , y='Attack' , undaspect=2 , wie unten gezeigt.
sns.catplot(kind='strip', data=pokemon, x='Type', y='Attack', aspect=2)Dieses Mal zeigt der resultierende Topf die X-Achsenbeschriftungen in voller Breite, was Ihre Analyse bequemer macht.
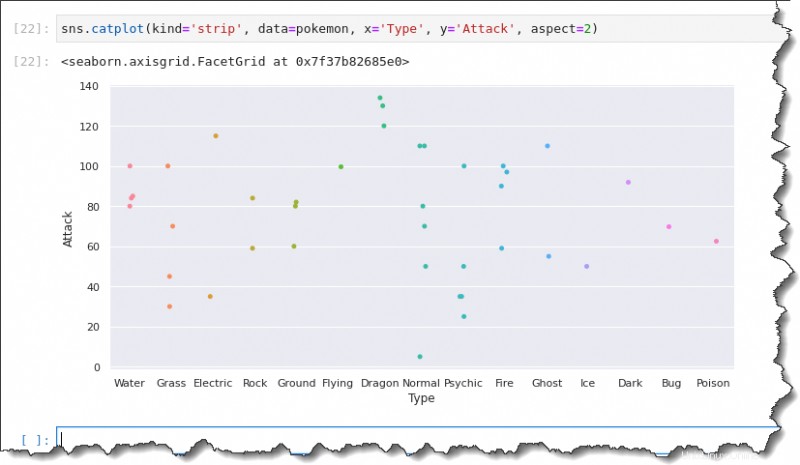
Box-Plotting
Der catplot() -Funktion hat eine weitere Unterfamilie von Diagrammen, die Ihnen helfen, die Datenverteilung mit einer kategorialen Variablen zu visualisieren. Einer davon ist der Boxplot.
Um einen Boxplot zu erstellen, führen Sie sns.catplot() aus Funktion mit den folgenden Argumenten:data=pokemon , kind='box' , x='Type' , y='Attack' , und aspect=2 .
Der aspect -Argument steuert den Abstand zwischen den Beschriftungen der x-Achse. Ein höherer Wert bedeutet eine breitere Streuung.
sns.catplot(data=pokemon, kind='box', x='Type', y='Attack', aspect=2)
Diese Ausgabe gibt Ihnen eine Zusammenfassung der Datenverteilung. Verwenden Sie den catplot() Funktion können Sie Daten für jeden Pokémon-Typ auf einem Diagramm verteilen.
Beachten Sie, dass die schwarzen Rautenmarkierungen Ausreißer darstellen. Anstelle eines Boxplots bedeutet eine Linie in der Mitte, dass es nur eine Beobachtung für diesen Pokémon-Typ gibt.
Sie haben für jedes dieser Box- und Whisker-Diagramme eine Zusammenfassung aus fünf Zahlen. Die Linie in der Mitte des Kästchens stellt den Medianwert oder ihre zentrale Tendenz von Angriffspunkten dar.
Sie haben auch das erste und dritte Quartil und die Schnurrhaare, die die Höchst- und Mindestwerte darstellen.
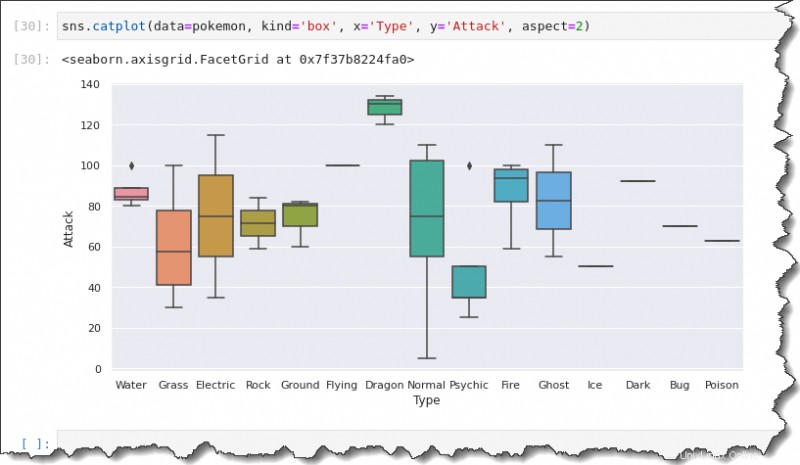
Geigenplotting
Eine andere Möglichkeit, die Verteilung zu visualisieren, ist die Verwendung des Geigendiagramms. Der Geigenplot ist wie ein Boxplot und ein KDE-Mix. Violin-Plots sind analog zu Box-Plots.
Um einen Geigenplot zu erstellen, ersetzen Sie kind Wert auf violin , während der Rest derselbe ist wie beim Ausführen des Box-Plotting-Befehls. Führen Sie den folgenden Code aus, um ein Geigendiagramm zu erstellen.
sns.catplot(kind='violin', data=pokemon, x='Type', y='Attack', aspect=2)Als Ergebnis können Sie sehen, dass das Geigendiagramm den Median, das erste und das dritte Quartil enthält. Der Violinplot bietet eine ähnliche Zusammenfassung der Datenverteilung wie der Boxplot.
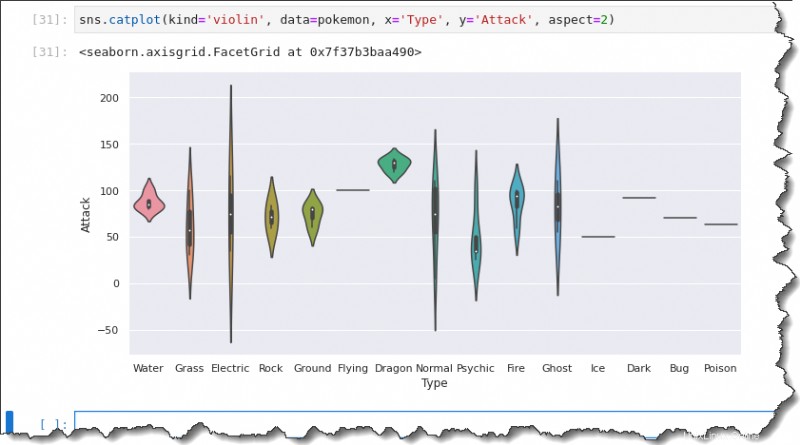
Nochmal zur Frage:Was ist die Angriffsverteilung für jeden Pokémon-Typ?
Das Boxplot zeigt, dass die minimalen Angriffspunkte zwischen 0 und 10 liegen, während das Maximum bis zu 110 geht.
Die mittleren Angriffspunkte für Pokémon vom Typ Normal scheinen etwa 75 zu sein. Das erste und dritte Quartil scheinen etwa 55 und 105 zu sein.
Balkendarstellung
Das Balkendiagramm ist ein Mitglied der kategorialen Schätzungsfamilie von Seaborn, das die Mittel- oder Durchschnittswerte jeder Datenkategorie anzeigt.
Um ein Balkendiagramm zu erstellen, führen Sie sns.catplot() aus Funktion in Jupyter und geben Sie sechs Argumente an:kind='bar' , data=pokemon , x='Type' , y='Attack' und aspect=2 , wie unten gezeigt.
sns.catplot(kind='bar',data=pokemon,x='Type',y='Attack',aspect=2)Die schwarzen Linien auf jedem Balken sind Fehlerbalken, die Unsicherheit darstellen, wie Ausreißer in den Beobachtungen. Wie Sie unten sehen können, sind die Mittelwerte:
- Ungefähr 90 für das Wasser-Pokémon.
- Ungefähr 60 für Gras .
- Elektrisch liegt ungefähr bei 75.
- Rock vielleicht 70.
- Der Boden innerhalb von 75.
- Und so weiter.
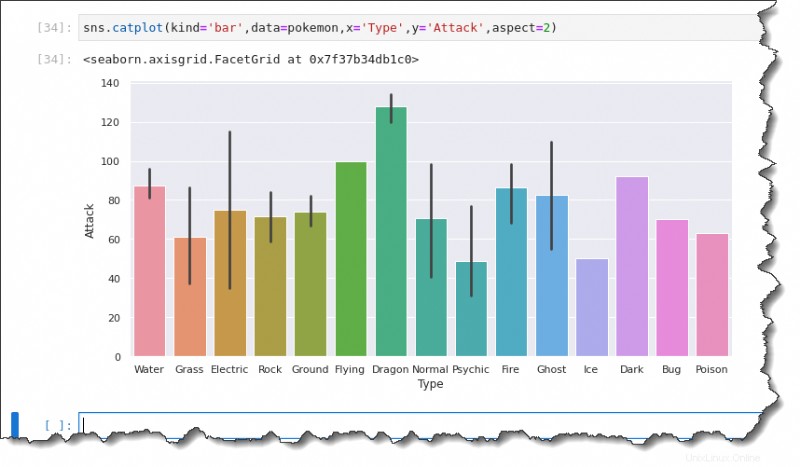
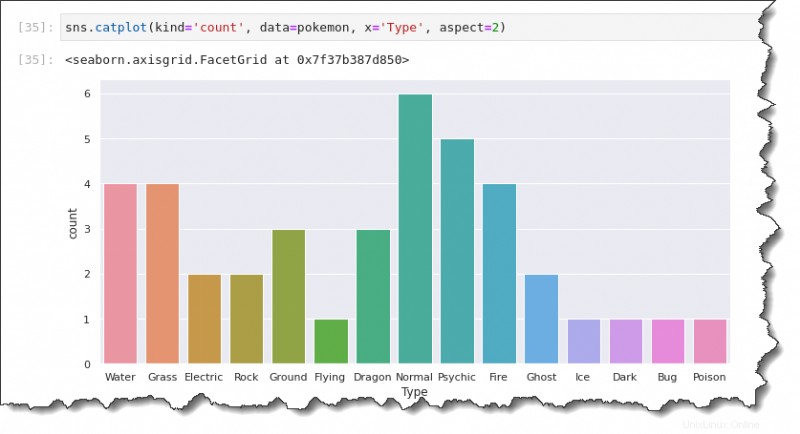
Plotting der Anzahl
Was ist, wenn Sie die Anzahl der Pokémon anstelle der mittleren/durchschnittlichen Daten darstellen möchten? Mit dem Zähldiagramm können Sie dies mit der Seaborn-Python-Bibliothek tun.
Um ein Zähldiagramm zu erstellen, ersetzen Sie kind Wert mit count , wie im folgenden Code gezeigt. Im Gegensatz zum Balkendiagramm benötigt das Zähldiagramm nur eine Datenachse. Geben Sie abhängig von der Plotausrichtung, die Sie erstellen möchten, entweder nur die x-Achse oder nur die y-Achse an.
Der folgende Befehl erstellt das Zählungsdiagramm, das die Typvariable auf der x-Achse zeigt.
sns.catplot(kind='count', data=pokemon, x='Type', aspect=2)Sie erhalten ein Zähldiagramm, das wie das folgende aussieht. Wie Sie sehen können, sind die häufigsten Pokémon-Typen:
- Normal (6).
- Mensch (5).
- Wasser (4).
- Gras (4).
- Und so weiter.
Schlussfolgerung
In diesem Lernprogramm haben Sie gelernt, wie Sie statistische Diagramme programmgesteuert mit der Seaborn Python-Bibliothek erstellen. Welche Darstellungsmethode ist Ihrer Meinung nach für Ihren Datensatz am besten geeignet?
Nachdem Sie nun Beispiele durchgearbeitet und das Erstellen von Plots mit Seaborn geübt haben, warum beginnen Sie nicht selbst mit der Arbeit an neuen Plots? Vielleicht können Sie mit dem Iris-Datensatz beginnen oder Ihre Beispieldaten sammeln?
Und wenn Sie schon dabei sind, probieren Sie auch einige der anderen in Seaborn integrierten Vorlagen und Farbpaletten aus! Vielen Dank fürs Lesen und viel Spaß!